4.SparkSQL—项目实战—各区域热门商品 Top3—需求简介、需求分析、功能实现 (注: Hive on Spark 用的较多)
本文目录如下:
- 第4章 SparkSQL 项目实战
-
- 4.1 数据准备
-
- 4.1.1 数据库表准备
- 4.1.2 在 IDEA 中 创建数据库表 并 导入数据
- 4.2 需求:各区域热门商品 Top3
-
- 4.2.1 需求简介
- 4.2.2 需求分析
- 4.2.3 功能实现
第4章 SparkSQL 项目实战
注: 本博客中用到的数据源均为
Hive数据源,外部Hive使用请参考 SparkSQL—核心编程—数据的加载和保存 中第3.6小节中的描述。
4.1 数据准备
4.1.1 数据库表准备
- (1) 首先创建一个新的数据库。
0: jdbc:hive2://hadoop100:10000> create database xinge;
- (2) 我们这次
Spark-SQL操作中所有的数据均来自Hive,首先在Hive中创建表,并导入数据。一共有 3 张表: 1 张用户行为表,1 张城市表,1 张产品表。
CREATE TABLE `user_visit_action`(
`date` string,
`user_id` bigint,
`session_id` string,
`page_id` bigint,
`action_time` string,
`search_keyword` string,
`click_category_id` bigint,
`click_product_id` bigint,
`order_category_ids` string,
`order_product_ids` string,
`pay_category_ids` string,
`pay_product_ids` string,
`city_id` bigint)
row format delimited fields terminated by '\t';
load data local inpath 'datas/user_visit_action.txt' into table xinge.user_visit_action;
CREATE TABLE `product_info`(
`product_id` bigint,
`product_name` string,
`extend_info` string)
row format delimited fields terminated by '\t';
load data local inpath 'datas/product_info.txt' into table xinge.product_info;
CREATE TABLE `city_info`(
`city_id` bigint,
`city_name` string,
`area` string)
row format delimited fields terminated by '\t';
load data local inpath 'datas/city_info.txt' into table xinge.city_info;
4.1.2 在 IDEA 中 创建数据库表 并 导入数据
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "xqzhao")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use xinge")
// 准备数据
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t'
""".stripMargin
)
spark.sql(
"""
|load data local inpath 'datas/user_visit_action.txt' into table xinge.user_visit_action
""".stripMargin
)
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t'
""".stripMargin
)
spark.sql(
"""
|load data local inpath 'datas/product_info.txt' into table xinge.product_info
""".stripMargin
)
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t'
""".stripMargin
)
spark.sql(
"""
|load data local inpath 'datas/city_info.txt' into table xinge.city_info
""".stripMargin
)
spark.sql("""select * from city_info""").show
spark.close()
}
}
4.2 需求:各区域热门商品 Top3
4.2.1 需求简介
- 这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。
例如:
| 地区 | 商品名称 | 点击次数 | 城市备注 |
|---|---|---|---|
| 华北 | 商品 A | 100000 | 北京 21.2%,天津 13.2%,其他 65.6% |
| 华北 | 商品 P | 80200 | 北京 63.0%,太原 10%,其他 27.0% |
| 华北 | 商品 M | 40000 | 北京 63.0%,太原 10%,其他 27.0% |
| 东北 | 商品 J | 92000 | 大连 28%,辽宁 17.0%,其他 55.0% |
4.2.2 需求分析
- 查询出来所有的点击记录,并与
city_info表连接,得到每个城市所在的地区,与product_info表连接得到产品名称。 - 按照地区和商品
id分组,统计出每个商品在每个地区的总点击次数。 - 每个地区内按照点击次数降序排列。
- 只取前三名。
- 城市备注需要自定义
UDAF函数。
4.2.3 功能实现
- 连接三张表的数据,获取完整的数据(只有点击)。
- 将数据根据地区,商品名称分组。
- 统计商品点击次数总和,取
Top3。
上面三个步骤可以通过下面的数据库查询语句获得:
select
*
from (
select
*,
rank() over( distribute by area order by clickCnt desc ) as rank
from (
select
area,
product_name,
count(*) as clickCnt
from (
select
a.*,
p.product_name,
c.area,
c.city_name
from user_visit_action a
join product_info p on a.click_product_id = p.product_id
join city_info c on a.city_id = c.city_id
where a.click_product_id > -1
) t1 group by area, product_name
) t2
) t3 where rank <= 3
- 实现自定义聚合函数显示备注。
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.Aggregator
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object Spark06_SparkSQL_Test2 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "xqzhao")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use xinge")
// 查询基本数据
spark.sql(
"""
|select
| a.*,
| p.product_name,
| c.area,
| c.city_name
|from user_visit_action a
|join product_info p on a.click_product_id = p.product_id
|join city_info c on a.city_id = c.city_id
|where a.click_product_id > -1
""".stripMargin).createOrReplaceTempView("t1")
// 根据区域、商品进行数据聚合
spark.udf.register("cityRemark", functions.udaf(new CityRemarkUDAF()))
spark.sql(
"""
|select
| area,
| product_name,
| count(*) as clickCnt,
| cityRemark(city_name) as city_remark
|from t1 group by area, product_name
""".stripMargin).createOrReplaceTempView("t2")
// 区域内对点击数量进行排行
spark.sql(
"""
|select
| *,
| rank() over( partition by area order by clickCnt desc ) as rank
|from t2
""".stripMargin).createOrReplaceTempView("t3")
// 取前三名
spark.sql(
"""
|select
| *
|from t3 where rank <= 3
""".stripMargin).show(false)
// truncate = false : 避免因内容过长被截取
spark.close()
}
case class Buffer(var total: Long, var cityMap: mutable.Map[String, Long])
// 自定义聚合函数: 实现城市备注功能
// 1.继承Aggregator,定义泛型
// IN : 城市名称
// BUF :【总点击数量, Map[(city, cnt), (city, cnt)]】
// OUT : 备注信息
// 2.重写方法 (6)
class CityRemarkUDAF extends Aggregator[String, Buffer, String] {
// 缓冲区初始化
override def zero: Buffer = {
Buffer(0, mutable.Map[String, Long]())
}
// 更新缓冲区
override def reduce(buff: Buffer, city: String): Buffer = {
buff.total += 1
val newCount = buff.cityMap.getOrElse(city, 0L)+ 1
buff.cityMap.update(city, newCount)
buff
}
override def merge(buff1: Buffer, buff2: Buffer): Buffer = {
buff1.total += buff2.total
val map1 = buff1.cityMap
val map2 = buff2.cityMap
// buff1.cityMap = map1.foldLeft(map2) {
// case (map, (city, cnt)) => {
// val newCount = map.getOrElse(city, 0L) + cnt
// map.update(city, newCount)
// map
// }
// }
// 上面的写法不太容易看懂,因此换一种合并方法
map2.foreach{
case (city, cnt) => {
val newCount = map1.getOrElse(city, 0L) + cnt
map1.update(city, newCount)
}
}
buff1.cityMap = map1
buff1
}
// 将统计的结果生成字符串信息
override def finish(buff: Buffer): String = {
val remarkList = ListBuffer[String]()
val totalcnt = buff.total
val cityMap = buff.cityMap
// 降序排列
var cityCntList = cityMap.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(2)
val hasMore = cityMap.size > 2
var rsum = 0L
cityCntList.foreach {
case (city, cnt) => {
val r = cnt * 100 / totalcnt
remarkList.append(s"${city} ${r}%")
rsum += r
}
}
if (hasMore) {
remarkList.append(s"其他${100 - rsum}%")
}
remarkList.mkString(",")
}
override def bufferEncoder: Encoder[Buffer] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
}
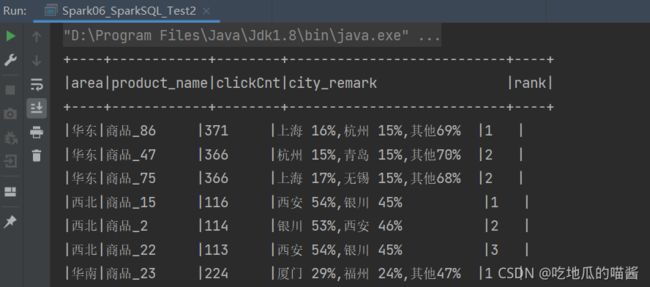
运行结果如下图所示:
声明:本文是学习时记录的笔记,如有侵权请告知删除!
原视频地址:https://www.bilibili.com/video/BV11A411L7CK