面经:数据结构与算法
文章目录
- 一、排序算法
-
- 1. 冒泡排序 ****
- 2. 选择排序 *
- 3. 插入排序 *
- 4. 希尔排序 **
- 5. 归并排序 *****
- 6. 快速排序 ****
-
- 6.1 理论
- 6.2 代码实现
- 7. 堆排序 *****
-
- 7.1 代码实现
- 7.2 性能分析
- 8. 计数排序 ***
- 9. 桶排序 ***
- 10. 基数排序
- 二、 堆
-
- 1. 定义及分类
- 2. 存储
- 3. 堆的操作
-
- 3.1 插入
- 3.2 删除
- 三.红黑树
-
- 1.为什么要用红黑树?
- 2. 红黑树除了具有二叉查找树的特点,还有哪些特点?
- 3. 如何调整一棵红黑树?
- 4. 红黑树的应用
- 5. 时间复杂度和最大深度
- 四. 二叉树
-
- 1. 满二叉树
- 2. 完全二叉树
- 3. 平衡二叉树
- 4. 二叉查找树BST
- 5. AVL树 (平衡二叉搜索树)
- 6. 总结 ****
- 五. 线性数据结构
-
- 1. 数组
- 2. 链表
- 3. 栈
- 4. 队列
-
- 4.1 单队列
- 4.2 循环队列
- 4.3 应用场景
- 5. 图
-
- 5.1 定义
- 5.2 图中如何找环
- 六.哈希
-
- 1. 如何解决hash冲突
- 七. 常见算法
-
- 1. 迪杰斯特拉算法
一、排序算法

算法稳定性分析
1. 冒泡排序 ****
比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤 1~3,直到排序完成。
import java.util.Scanner;
/**
* 冒泡排序算法
*/
public class Solution14 {
public static void main(String[] args) {
int[] arr = new int[]{5,1,3,2,4};
bubbleSort(arr);
for (int i : arr) {
System.out.print(i+" ");
}
}
public static int[] bubbleSort(int[] arr){
for(int i=0;i<arr.length;i++){
for(int j=0;j<arr.length-1;j++){
if(arr[j]>arr[j+1]){
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
return arr;
}
}
//稳定性:稳定
//时间复杂度 :最佳:O(n) ,最差:O(n2), 平均:O(n2)
//空间复杂度 :O(1)
//排序方式 :In-place
2. 选择排序 *
public static int[] selectedSort(int[] arr){
for(int i=0;i<arr.length-1;i++){
int minIndex = i;
for(int j=i+1;j<arr.length;j++){
if(arr[j]<arr[minIndex]){
minIndex = j;
}
}
if(minIndex!=i){
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
return arr;
}
//首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
//再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
//重复第 2 步,直到所有元素均排序完毕
3. 插入排序 *
public static int[] insertedSort(int[] arr){
for(int i=1;i<arr.length;i++){
int preIndex = i-1;
int current = arr[i];
while(preIndex>=0 && current<arr[preIndex]){
arr[preIndex+1] = arr[preIndex];
preIndex--;
}
arr[preIndex+1] = current;
}
return arr;
}
//从第一个元素开始,该元素可以认为已经被排序;
//取出下一个元素,在已经排序的元素序列中从后向前扫描;
//如果该元素(已排序)大于新元素,将该元素移到下一位置;
//重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置;
//将新元素插入到该位置后;重复步骤 2~5
4. 希尔排序 **
递减增量排序算法,分组进行插入排序

public static int[] shellSort(int[] arr){
int len = arr.length;
int gap = len/2;
while(gap>0){
//进行插入排序
for(int i=gap;i<len;i++){
int cur = arr[i];
int preIndex = i - gap;
while(preIndex>=0 && arr[preIndex]>cur){
arr[preIndex+gap] = arr[preIndex];
preIndex -= gap;
}
arr[preIndex+gap] = cur;
}
gap /= 2;
}
return arr;
}
5. 归并排序 *****
-
描述:
该算法是采用分治法 (Divide and Conquer) 的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为 2 - 路归并。 -
流程
如果输入内只有一个元素,则直接返回,否则将长度为 n 的输入序列分成两个长度为 n/2 的子序列;
分别对这两个子序列进行归并排序,使子序列变为有序状态;
设定两个指针,分别指向两个已经排序子序列的起始位置;
比较两个指针所指向的元素,选择相对小的元素放入到合并空间(用于存放排序结果),并移动指针到下一位置;
重复步骤 3 ~4 直到某一指针达到序列尾;将另一序列剩下的所有元素直接复制到合并序列尾
见添加链接描述
public static void mergeSort(int[] nums,int left,int right){
if(left<right){
int mid = (left+right)/2;
mergeSort(nums,left,mid);
mergeSort(nums,mid+1,right);
merge(nums,left,mid,right);
}
}
public static void merge(int[] nums,int start,int mid,int end){
int[] res = new int[end-start+1];
int p1 = start;
int p2 = mid+1;
int index = 0;
while(p1<=mid&&p2<=end){
if(nums[p1]<nums[p2]){
res[index++] = nums[p1++];
}else{
res[index++] = nums[p2++];
}
}
while (p1<=mid){
res[index++] = nums[p1++];
}
while(p2<=end){
res[index++] = nums[p2++];
}
for(int i=0;i<res.length;i++){
nums[i+start]=res[i];
}
}
6. 快速排序 ****
6.1 理论
详解
快速排序是一种基于分而治之的排序算法,其中:
1、通过从数组中选择一个中心元素将数组划分成两个子数组,在划分数组时,将比中心元素小的元素放在左子数组,将比中心元素大的元素放在右子数组。
2、左子数组和右子数组也使用相同的方法进行划分,这个过程一直持续到每个子数组都包含一个元素为止。
3、最后,将元素组合在一起以形成排序的数组。
6.2 代码实现
import java.util.Arrays;
/**
* 快速排序
* 稳定性 :不稳定
* 时间复杂度 :最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
* 空间复杂度 :O(nlogn)
*/
public class Solution10 {
public static void main(String[] args){
int[] arr = {1,3,5,6,9,10,3,4,5,6};
quickSort(arr,0,arr.length-1);
System.out.println(Arrays.toString(arr));
}
private static void quickSort(int[] nums,int left,int right){
if(left<right){
//分而之治的思想: AA X BB 然后再对 AA 和BB 进行相同的处理 直到无法处理
int midIndex = partition(nums,left,right);
quickSort(nums,left,midIndex-1);
quickSort(nums,midIndex+1,right);
}
}
/**
* 处理一次的逻辑,最终得到的是 XX A YYY数组,X比A小,Y比A大,获得A的坐标
* @param nums
* @param left
* @param right
* @return
*/
private static int partition(int[] nums,int left,int right){
int mid = nums[right];//取最后一个元素作为中心元素
int pointer = left;//指向比中心元素大的坐标,初始化为第一个元素
for(int i = left;i<right;i++){
if(nums[i]<nums[right]){
// 将比中心元素小的元素和指针指向的元素交换位置
// 如果第一个元素比中心元素小,这里就是自己和自己交换位置,指针和索引都向下一位移动
// 如果元素比中心元素大,索引向下移动,指针指向这个较大的元素,直到找到比中心元素小的元素,并交换位置,指针向下移动
int temp = nums[i];
nums[i] = nums[pointer];
nums[pointer] = temp;
pointer++;
}
}
//处理中心元素:与指针指向的元素交换位置,得到的是中心元素左边的都比它小,右边的都比它大
int temp = nums[pointer];
nums[pointer] = mid;
nums[right] = temp;
return pointer;
}
}
7. 堆排序 *****
先对原来的数组构造一个大顶堆或者小顶堆
然后取出堆顶元素,此时堆会被破坏掉,就重新构造一个
依次操作,进行排序
7.1 代码实现
/**
* 手撕堆排序算法总结
*/
public class Solution9 {
public static void main(String[] args) {
int[] nums = new int[]{5,1,3,23,1,4,2};
heapSort(nums);
for (int num : nums) {
System.out.println(num);
}
}
/**
* 堆排序核心逻辑:构造最大堆、排序
* @param nums
* @return
*/
private static int[] heapSort(int[] nums){
int n = nums.length;
//1.构造最大堆,将其想象为一棵完全二叉树 左孩子i*2+1,右孩子i*2+2
//nums最后一个元素的父节点,无论最后一个是左孩子还是右孩子,取整后都能得到其父节点的索引(画图看一下)
for(int i=(n-1-1)/2;i>=0;i--){
sink(nums,i,n-1);
}
//2.排序
for(int i=n-1;i>=1;i--){
int temp = nums[i];//nums[0]是最大的元素
nums[i] = nums[0];//取出最大元素放到数组最后
nums[0] = temp;
sink(nums,0,i-1);//取出元素后,破坏了堆,进行下沉操作
}
return nums;
}
/**
* 自上而下的堆化
* @param nums
* @param parent 需要下沉的元素的索引
* @param size 最大索引,后边排序之后,每次都会取最大元素放到数组最后,因此该参数需要修改
*/
private static void sink(int[] nums,int parent,int size){
int temp = nums[parent];//需要下沉的元素
int child = 2*parent+1;//定义左孩子的索引
while(child<=size){//下沉就必须一直比较,直到达到树的最底部
//比较之前需要先看下右孩,右孩子大就必须是以右孩子为标准
if(child+1<=size && nums[child] < nums[child+1]){
child++;
}
//TUOD:最小堆
// if(child+1<=size && nums[child] > nums[child+1]){
// child++;
// }
if(temp >= nums[child]) break;//父节点大,不需要下沉
//TUOD:最小堆
// if(temp <= nums[child]) break;
//下沉
nums[parent] = nums[child];
parent = child;//此时还需要继续比较,比如 5- 9 - 7 ,假如第一次交换得到了 9-5-7 ,此时5与7还需要继续比较
child = 2*parent+1;
}
nums[parent] = temp;
}
}
7.2 性能分析
稳定性 :不稳定
时间复杂度 :最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
空间复杂度 :O(1)
8. 计数排序 ***
一定要反向填充
/**
* 计数排序:所谓的数就是比当前元素大的元素的个数,该数也是元素在结果数组中的索引下标
*/
public class Solution15 {
public static void main(String[] args) {
int[] arr = new int[]{5,5,2,4,1,6,8,7};
//1.先获取最大最小值
int maxValue = arr[0];
int minValue = arr[0];
for(int i=0;i<arr.length;i++){
if(arr[i]>maxValue){
maxValue = arr[i];
}
}
for(int i=0;i<arr.length;i++){
if(arr[i]<minValue){
minValue = arr[i];
}
}
//2.计数:计算比当前元素大的有多少个元素
int[] count = new int[maxValue-minValue+1];
//count的下标索引就是arr[i]的值
for(int i=0;i<arr.length;i++){
count[arr[i]-minValue] += 1;//当前元素有多少个
}
for(int i=1;i<count.length;i++){
count[i] = count[i-1] + count[i];//比当前元素大/等于的有多少个
}
//3.还原数组
int[] res = new int[arr.length];
for(int i=arr.length-1;i>=0;i--){//此处一定要从后往前遍历
int index = count[arr[i]-minValue] - 1;
res[index] = arr[i];
count[arr[i]-minValue] -= 1;
}
for (int re : res) {
System.out.print(re+" ");
}
}
}
//找出数组中的最大值 max、最小值 min;
//创建一个新数组 C,其长度是 max-min+1,其元素默认值都为 0;
//遍历原数组 A 中的元素 A[i],以 A[i]-min 作为 C 数组的索引,以 A[i] 的值在 A 中元素出现次数作为 C[A[i]-min] 的值;
//对 C 数组变形,新元素的值是该元素与前一个元素值的和,即当 i>1 时 C[i] = C[i] + C[i-1];
//创建结果数组 R,长度和原始数组一样。
//从后向前遍历原始数组 A 中的元素 A[i],使用 A[i] 减去最小值 min 作为索引,在计数数组 C 中找到对应的值 C[A[i]-min],C[A[i]-min]-1 就是 A[i] 在结果数组 R 中的位置,做完上述这些操作,将 count[A[i]-min] 减小 1
9. 桶排序 ***
桶排序的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Solution16 {
public static void main(String[] args) {
int[] nums = new int[]{12,3,20,4,5,6,2};
// quickSort(nums,0,nums.length-1);
// heapSort(nums);
// System.out.println(Arrays.toString(nums));
List<Integer> arr = Arrays.stream(nums).boxed().collect(Collectors.toList());
List<Integer> res = bucketSort(arr,2);
for (Integer i : res) {
System.out.print(i+" ");
}
}
/**
* 获取数组中的最大值和最小值
* @param arr
* @return
*/
private static int[] getMinAndMax(List<Integer> arr) {
int maxValue = arr.get(0);
int minValue = arr.get(0);
for (int i : arr) {
if (i > maxValue) {
maxValue = i;
} else if (i < minValue) {
minValue = i;
}
}
return new int[] { minValue, maxValue };
}
/**
* Bucket Sort
* @param arr
* @return
*/
public static List<Integer> bucketSort(List<Integer> arr, int bucket_size) {
if (arr.size() < 2 || bucket_size == 0) {
return arr;
}
//获取最值,为桶排序做准备
int[] extremum = getMinAndMax(arr);
int minValue = extremum[0];
int maxValue = extremum[1];
//桶的数量
int bucket_cnt = (maxValue - minValue) / bucket_size + 1;
//创建桶
List<List<Integer>> buckets = new ArrayList<>();
for (int i = 0; i < bucket_cnt; i++) {
buckets.add(new ArrayList<Integer>());//根据桶的个数初始化一堆空桶
}
//计算每个元素在哪个桶 并进行填充
for (int element : arr) {
int idx = (element - minValue) / bucket_size;
buckets.get(idx).add(element);
}
//分别对每个桶进行排序
for (int i = 0; i < buckets.size(); i++) {
if (buckets.get(i).size() > 1) {//set方法更新指定桶 排序
buckets.set(i, bucketSort(buckets.get(i), bucket_size / 2));
}
}
//存放结果
ArrayList<Integer> result = new ArrayList<>();
for (List<Integer> bucket : buckets) {
for (int element : bucket) {
result.add(element);
}
}
return result;
}
10. 基数排序
二、 堆
1. 定义及分类
- 堆是一种满足以下条件的树:
堆中的每一个节点值都**大于等于(或小于等于)**子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。 - 分类
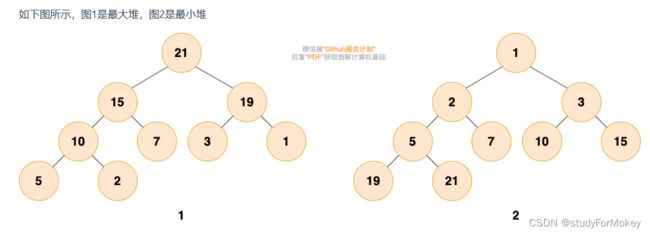
2. 存储

3. 堆的操作
3.1 插入
- 插到最后

- 比较(自底向上)

3.2 删除
删除堆顶元素后,为了保持堆的性质,需要对堆的结构进行调整,我们将这个过程称之为**“堆化”**,堆化的方法分为两种:一种是自底向上的堆化,上述的插入元素所使用的就是自底向上的堆化,元素从最底部向上移动。另一种是自顶向下堆化,元素由最顶部向下移动。
- 自底向上的堆化(会产生气泡 不建议)



- 自顶向下堆化(推荐)


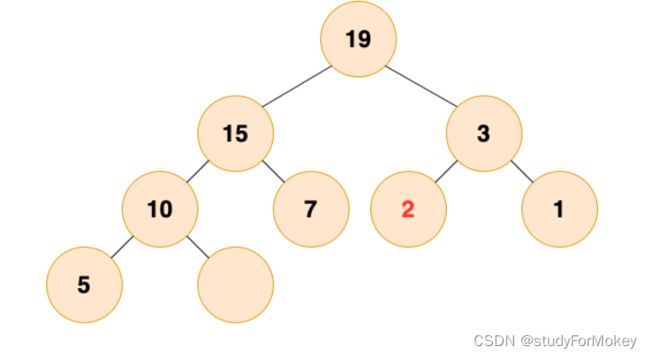
三.红黑树
1.为什么要用红黑树?
通过舍弃严格的平衡和引入红黑节点,解决了平衡二叉树旋转效率过低的问题,但是在磁盘等场景下,树仍然太高,IO 次数太多;
红黑树详细解析
2. 红黑树除了具有二叉查找树的特点,还有哪些特点?
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。

特性
红黑树从根到叶子节点的最长路径不会超过最短路径的2倍。
原因:
当某条路径最短时,这条路径必然都是由黑色节点构成。当某条路径长度最长时,这条路径必然是由红色和黑色节点相间构成(性质4限定了不能出现两个连续的红色节点)。而性质5又限定了从任一节点到其每个叶子节点的所有路径必须包含相同数量的黑色节点。此时,在路径最长的情况下,路径上红色节点数量 = 黑色节点数量。该路径长度为两倍黑色节点数量,也就是最短路径长度的2倍。
3. 如何调整一棵红黑树?
变色
旋转:左旋转和右旋转
4. 红黑树的应用
TreeMap 和TreeSet
5. 时间复杂度和最大深度
Olog(n)
2log2(n+1)
四. 二叉树
1. 满二叉树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是 满二叉树。也就是说,如果一个二叉树的层数为 K,且结点总数是(2^k) -1 ,则它就是 满二叉树。如下图所示:

2. 完全二叉树
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。

3. 平衡二叉树
可以是一棵空树
如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树的常用实现方法有 红黑树、AVL 树、替罪羊树、加权平衡树、伸展树 等。
4. 二叉查找树BST

平衡树是为了解决二叉查找树退化为链表的情况,而红黑树是为了解决平衡树在插入、删除等操作需要频繁调整的情况。
5. AVL树 (平衡二叉搜索树)
平衡树(高度差小于等于1)
搜索树(左小右大)
6. 总结 ****
二叉查找树:解决了排序的基本问题,但是由于无法保证平衡,可能退化为链表;
平衡二叉树:通过旋转解决了平衡的问题,但是旋转操作效率太低;
红黑树:通过舍弃严格的平衡和引入红黑节点,解决了平衡二叉树旋转效率过低的问题,但是在磁盘等场景下,树仍然太高,IO 次数太多;
B 树:通过将二叉树改为多路平衡查找树,解决了树过高的问题;
B+ 树:在 B 树的基础上,将非叶节点改造为不存储数据的纯索引节点,进一步降低了树的高度;此外将叶节点使用指针连接成链表,范围查询更加高效。
五. 线性数据结构
1. 数组
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
数组的特点是:提供随机访问 并且容量有限。
2. 链表
链表(LinkedList 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。

3. 栈
应用场景:
实现浏览器的回退和前进功能
检查符号是否成对出现
反转字符串
4. 队列
队列 是 先进先出( FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue

4.1 单队列
单队列又分为 顺序队列(数组实现) 和 链式队列(链表实现)。
顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。
假设下图是一个顺序队列,我们将前两个元素 1,2 出队,并入队两个元素 7,8。当进行入队、出队操作的时候,front 和 rear 都会持续往后移动,当 rear 移动到最后的时候,我们无法再往队列中添加数据,即使数组中还有空余空间,这种现象就是 ”假溢出“ 。除了假溢出问题之外,如下图所示,当添加元素 8 的时候,rear 指针移动到数组之外(越界)。

4.2 循环队列
用来解决假溢出问题。从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来

- front == rear
顺序队列中,我们说 front==rear 的时候队列为空,循环队列中则不一样,也可能为满 - 解决办法

4.3 应用场景
- 阻塞队列
阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。 - 线程池中的请求/任务队列
线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如 :FixedThreadPool 使用无界队列 LinkedBlockingQueue。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出java.util.concurrent.RejectedExecutionException 异常。
5. 图
讲的很完整的资料
5.1 定义
在线性表中,数据元素之间是被串起来的,仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继。在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关。图是一种较线性表和树更加复杂的数据结构。在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
5.2 图中如何找环
添加链接描述
T207. 课程表(拓扑排序判断是否为有向无环图:邻接表+BFS)
T684. 冗余连接(无向图中找环:邻接表BFS/并查集)
- 拓扑排序
求出图中所有结点的度。
将所有度 <= 1 的结点入队(无向图的是1,有向图是入度=0)。(独立结点的度为 0)
当队列不空时,弹出队首元素,把与队首元素相邻节点的度减一。如果相邻节点的度变为一,则将相邻结点入队。
循环结束时判断已经访问的结点数是否等于 n。等于 n 说明全部结点都被访问过,无环;反之,则有环。 - DFS
使用 DFS 可以判断一个无向图和有向中是否存在环。深度优先遍历图,如果在遍历的过程中,发现某个结点有一条边指向已访问过的结点,并且这个已访问过的结点不是上一步访问的结点,则表示存在环。
我们不能仅仅使用一个 bool 数组来表示结点是否访问过。规定每个结点都拥有三种状态,白、灰、黑。开始时所有结点都是白色,当访问过某个结点后,该结点变为灰色,当该结点的所有邻接点都访问完,该节点变为黑色。
那么我们的算法可以表示为:如果在遍历的过程中,发现某个结点有一条边指向灰色节点,并且这个灰色结点不是上一步访问的结点,那么存在环。 - Union-Find Set
对于无向图来说,在遍历边(u-v)时,如果结点 u 和结点 v 的“父亲”相同,那么结点 u 和结点 v 在同一个环中。
对于有向图来说,在遍历边(u->v)时,如果结点 u 的“父亲”是结点 v,那么结点 u 和结点 v 在同一个环中。
六.哈希
1. 如何解决hash冲突

七. 常见算法
1、排序算法:快速排序、归并排序、计数排序
2、搜索算法:回溯、递归、剪枝
3、图论:最短路径、最小生成树、网络流建模
4、动态规划:背包问题、最长子序列、计数问题
5、基础技巧:分治、倍增、二分法、贪心算法
1. 迪杰斯特拉算法
从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。迪杰斯特拉算法采用的是贪心策略,将Graph中的节点集分为最短路径计算完成的节点集S和未计算完成的节点集T,每次将从T中挑选V0->Vt最小的节点Vt加入S,并更新V0经由Vt到T中剩余节点的更短距离,直到T中的节点全部加入S中,它贪心就贪心在每次都选择一个距离源点最近的节点加入最短路径节点集合。迪杰斯特拉算法只支持非负权图,它计算的是单源最短路径,即单个源点到剩余节点的最短路径,时间复杂度为O(n²)。
添加链接描述
import java.util.Scanner;
//求的是起点到其余节点的最短路
public class DijstraAlgorithm {
//不能设置为Integer.MAX_VALUE,否则两个Integer.MAX_VALUE相加会溢出导致出现负权
public static int MaxValue = 100000;
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
//顶点数
int vertex = input.nextInt();
//边数
int edge = input.nextInt();
//邻接矩阵
int[][] matrix = new int[vertex][vertex];
//初始化邻接矩阵
for (int i = 0; i < vertex; i++) {
for (int j = 0; j < vertex; j++) {
matrix[i][j] = MaxValue;
}
}
for (int i = 0; i < edge; i++) {
int source = input.nextInt();
int target = input.nextInt();
int weight = input.nextInt();
matrix[source][target] = weight;
}
//单源最短路径,起点
int source = input.nextInt();
//调用dijstra算法计算最短路径:
dijstra(matrix, source);
}
public static void dijstra(int[][] matrix, int source) {
//最短路径长度
int[] shortest = new int[matrix.length];
//判断该点的最短路径是否求出:1表示访问过,0未访问
int[] visited = new int[matrix.length];
//存储输出路径
String[] path = new String[matrix.length];
//初始化输出路径
for (int i = 0; i < matrix.length; i++) {
path[i] = new String(source + "->" + i);
}
//初始化源节点
shortest[source] = 0;
visited[source] = 1;
for (int i = 1; i < matrix.length; i++) {
int min = Integer.MAX_VALUE;
int index = -1;
for (int j = 0; j < matrix.length; j++) {
//已经求出最短路径的节点不需要再加入计算并判断加入节点后是否存在更短路径
if (visited[j] == 0 && matrix[source][j] < min) {
min = matrix[source][j];
index = j;
}
}
//更新最短路径
shortest[index] = min;
visited[index] = 1;
//更新从index跳到其它节点的较短路径
for (int m = 0; m < matrix.length; m++) {
if (visited[m] == 0 && matrix[source][index] + matrix[index][m] < matrix[source][m]) {
matrix[source][m] = matrix[source][index] + matrix[index][m];
path[m] = path[index] + "->" + m;
}
}
}
//打印最短路径
for (int i = 0; i < matrix.length; i++) {
if (i != source) {
if (shortest[i] == MaxValue) {
System.out.println(source + "到" + i + "不可达");
} else {
System.out.println(source + "到" + i + "的最短路径为:" + path[i] + ",最短距离是:" + shortest[i]);
}
}
}
}
}