事件知识图谱综述10.17+10.18 弃
事件知识图谱综述
- 摘要
- 介绍
- 2 什么是事件知识图谱:历史视角
-
- 2.1 EKG的简要历史
- 2.2 EKG的定义
- 什么是EKG:本体视角
-
- 3.1 事件架构归纳

摘要
除了以实体为中心的知识,通常以知识图谱(KG)的形式组织外,事件也是世界上一种重要的知识类型,这促使了以事件为中心的知识表示形式的出现,如事件知识图谱(EKG)。它在许多下游应用中扮演着越来越重要的角色,例如搜索、问答、推荐、金融量化投资和文本生成。本文全面调研了EKG的历史、本体、实例和应用视角。具体而言,为了全面描述EKG,我们关注其历史、定义、模式归纳、获取、相关代表性图谱/系统以及应用。文中还研究了EKG的发展过程和趋势。进一步总结了未来EKG研究的前景方向,以促进未来的研究。
介绍
知识图谱(Knowledge Graph,KG)是Google在2012年提出的一种流行的知识表示形式。它关注实体及其关系,因此代表了静态知识。然而,世界上存在大量的事件信息,它传递动态和过程性知识。因此,以事件为中心的知识表示形式,如 事件知识图谱(Event KG,EKG) ,也是至关重要的。它在搜索、问答、推荐、金融量化投资和文本生成等许多下游应用中发挥了重要作用。
事件知识图谱
是一种基于图谱的知识表示形式,用于描述和组织事件的相关信息和关系。
在事件知识图谱中,事件被作为图谱的核心元素,以节点的形式表示。每个事件节点包含了事件的属性、特征和关系,例如事件类型、参与者、时间、地点、结果等。事件之间的关系通过边连接表示,可以表达事件之间的因果关系、时序关系、参与者关系等。
例如关于美国独立战争的知识图谱
节点:
事件:美国独立战争
时间:1775年 - 1783年
参与者:美国大陆军、大不列颠王国军队、法国军队
地点:美国东海岸、加拿大、大西洋
战役:列克星敦和康科德战役、萨拉托加战役、瓦尔科战役、约克敦战役、约克敦围城等
领导人:乔治·华盛顿、托马斯·杰斐逊、本杰明·富兰克林、查尔斯·康沃利斯等
关系:
发生于:美国独立战争发生于1775年至1783年之间
包含战役:美国独立战争包含了列克星敦和康科德战役、萨拉托加战役等战役
参与者:美国大陆军是美国独立战争的参与者之一
领导人:乔治·华盛顿是美国独立战争期间的美国大陆军总司令
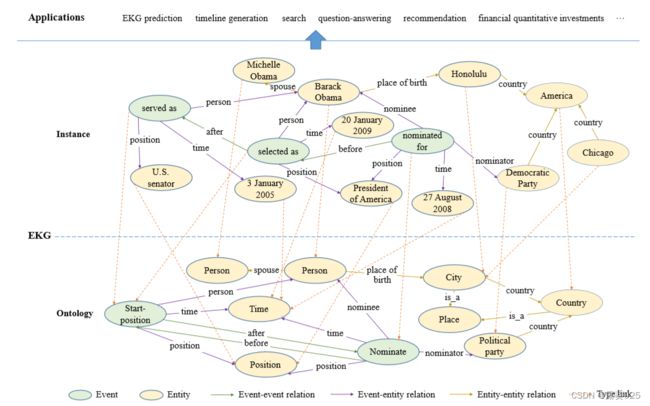
本文深入探讨了EKG的概念及其发展。为了全面介绍EKG,从历史、本体、实例和应用的视角来理解它。如图1所示,本体和实例部分相互合作形成EKG,并且EKG进一步支持许多应用。
具体而言:
- 从历史视角出发,介绍了EKG的简要历史和本文提出的定义(见第2节)。
- 从本体视角出发,研究了与EKG相关的基本概念,以及其中的任务和方法,包括事件模式、脚本和EKG模式归纳(见第3节)。
- 从实例视角出发,详细阐述了事件获取和与EKG相关的代表性图谱/系统(见第4节)。
- 从应用视角出发,介绍了EKG的一些基本和深层应用(见第5节)。
- 还全面研究了相关任务的发展过程和趋势。未来的研究方向在第6节中指出,最后在第7节进行总结。
此外,还有一些关于EKG部分内容的调研,重点关注事件抽取、事件建模和挖掘、事件和事件关系抽取以及事件共指消解等方面。然而,缺乏对EKG进行全面深入调研的工作。实际上,事件在世界上是重要且不可忽视的。每天都发生许多事件,反映了世界的状态。因此,深入研究事件是必要的。因此,对EKG进行全面调研具有重要意义。
2 什么是事件知识图谱:历史视角
2.1 EKG的简要历史
EKG并非突然出现,而是自然语言处理(NLP)和人工智能发展的结果。如图2所示,EKG的历史可以分为四个阶段,从事件、事件抽取、事件关系抽取等方面开始。

第一阶段:
事件构成研究的早期阶段。从1950年代开始,人们广泛研究事件及其组成部分。例如,Davidson试图得到关于动作的句子的逻辑形式,他描述了这些句子中单词的逻辑或语法角色。Mourelatos 和Pustejovsky 探讨了事件并提出了它们的基本定义。1978年,Mourelatos 将事件定义为固有可计数的发生。1991年,Pustejovsky 认为事件为语言分析提供了不同的表示形式,涉及动词的时态特性、副词范围、论元角色以及从词汇到句法的映射。
第二阶段:
事件元素抽取的标准形成和有序的事件结构出现。1989年,MUC(Message Understanding Conference)评估提出了事件模板填充,由海军海洋系统中心发起,旨在促进军事文本消息的自动分析。根据事件的描述,参与者需要为每个事件填写一个模板。随着网络具有无限的信息潜力,自动内容提取(ACE)项目开始开发其中的含义提取能力。从2004年开始,它增加了事件抽取,即提取事件触发词和论元,更符合现实情况。事件触发词是最清晰地表达事件的单词或片段,即指示事件类型的词语,而论元则是在事件中扮演特定角色的实体或片段。意识到识别文本中描述的事件并将其定位在时间上的重要性后,2007年,语义评估(SemEval)提出了时间关系抽取任务TempEval,用于从文本中提取事件的时间关系。此后,对事件和事件关系抽取的研究通常遵循ACE和TempEval的任务定义。由于理解篇章的时间流动对于文本理解至关重要,从2006年开始,人们尝试从文本中构建有序的事件结构,如时间图和事件时间线。
第三阶段:
知识图谱和事件图谱的出现。值得注意的是,2012年,为了增强Google搜索结果的返回效果,Google提出了知识图谱,其中包含语义网络中收集到的实体和关系的所有知识。自那以后,知识图谱在各个领域引起了广泛关注。然而,知识图谱关注的是实体及其关系,即静态知识,无法优雅地处理事件。这在某种程度上引发了关于事件及其关系的知识表示形式的出现。2014年,Glavas和Snajder提出了事件图谱,用于结构化文本中关于事件的信息,以满足对事件相关信息的高效检索和呈现的需求。在这个事件图谱中,节点是由触发词和论元(主语、宾语、时间和位置)组成的事件,边表示事件的时间关系。2015年,Glavas和Snajder 进一步添加了事件的共指关系。为了描述世界的变化,2016年,Rospocher等人提出了以事件为中心的知识图谱,其中节点是由URI和实体标识的事件,边表示事件之间的关系、事件与实体之间的关系以及有关实体的一般事实。事件之间的关系包括时间关系和因果关系。事件与实体之间的关系考虑了行动、参与者、时间和位置,捕捉了“是什么、谁、何时、在哪里”的信息。
第四阶段:
事件逻辑图的出现。最近,随着许多现实世界应用的发展,如事件预测、决策和对话系统的场景设计,对于理解事件的演化和发展有着极大的需求。因此,2017年,Li等人提出了事件演化图。它类似于事件图谱,但其事件节点是抽象、概括和语义完整的动词短语。它进一步考虑了事件之间的因果关系,并揭示了事件的演化模式和发展逻辑。然后,2018年,Gottschalk和Demidova 提出了以事件为中心的时间知识图谱,其中事件、实体和关系都是节点,以便进行对Web、新闻和社交媒体中的当代和历史事件的语义分析。其中的事件具有主题、时间和地理信息,并与参与事件的实体相连接。他们还考虑了子事件、前事件和后事件之间的关系,以及实体之间的关系。2019年,事件演化图演变为事件逻辑图,其中节点是抽象、概括和语义完整的事件元组(s,p,o),s是动作/主语,p是动作/谓词(即事件触发器),o是对象。此外,还考虑了两种事件关系:条件关系和上位词-下位词关系。
总的来说
有许多与EKG相关的概念。如表1所示,事件演化图和事件逻辑图仅关注于模式级别的事件知识。事件图谱和事件逻辑图中的节点都是复合结构,难以处理。此外,这些EKG相关概念都只考虑了特定且有限的事件关系和论证角色。实际上,存在许多事件关系。此外,事件有自己的组成部分,每个组成部分由论证和论证在事件中所扮演的角色组成。

2.2 EKG的定义
正如在2.1节中介绍的,存在一些具有缺陷的与EKG相关的概念。沿着这个思路,但引入了更丰富的内容,如下所示。
以事件为中心的EKG具有两种类型的节点,即事件和实体,以及三种类型的有向边,表示事件-事件、事件-实体和实体-实体之间的关系。如图1所示,第一类关系包括事件之间的许多种关系,如时间关系、因果关系、条件关系、主题关系等。第二类关系表示事件的论证,即边表示实体与链接事件之间的论证角色。第三类描述实体之间的关系,如配偶关系、出生地、国家等。
形式上,
定义1. EKG G = {(s, p, o)|{s, p} ∈ N, p ∈ E, N = Nevt∪Nent, E = Eevt-evt∪Eevt-ent∪Eent-ent} 是一个由事件节点Nevt、实体节点Nent和它们的关系E组成的图,其中Eevt-evt、Eevt-ent和Eent-ent分别表示事件之间的关系、事件与实体之间的关系以及实体之间的关系。
通过这种方式,事件可以轻松地通过共同的论证实体进行连接,反之亦然。因此,知识图谱是EKG的一种特殊情况,只有实体节点和实体-实体关系。
什么是EKG:本体视角
从本体视角来看,我们将研究架构和相关任务。如图1底部所示,EKG架构描述了构成EKG的基本概念,包括事件类型、参数角色和事件关系。前两者构成了事件架构。至于最后一个,典型的脚本[31]通过一些事件关系组织了一组事件,共同描述了常见的情景。在介绍EKG架构归纳之前,让我们从本节开始介绍事件架构和脚本归纳。
3.1 事件架构归纳
事件架构可以手动设计,例如典型的ACE事件架构,和FrameNet框架。由于手动设计的事件架构覆盖率低且难以进行领域适应,研究人员开始关注事件架构归纳。它可以从文本中自动提取事件类型和它们的参数角色。形式上,定义2. 事件架构归纳:给定一组文本{T0,T1,…,Tl},它识别出事件架构,包括所有事件类型{tp0,…,tpτ}和每个事件类型tpi(0≤i≤τ)的所有参数角色{rli 0,…,rli ρ}。例如,示例1. 输入:T0:巴拉克·奥巴马曾于2005年1月3日担任美国参议员。然后,他于2009年1月20日被选为美国总统。T1:在赢得总统选举之前,奥巴马于2008年8月27日被提名为美国总统。
定义2: 事件框架归纳:给出一组文本{T0, T1, …, Tl},定义了事件框架,包括所有的事件类型{tp0, tp1, … ,tpT}。和对于每个一事件类型tpi(0<= i <= T)的所有参数角色(argument roles) {rli0,…,rliρ}。
“argument roles”(参数角色)是指在给定的句子或语境中,与谓词相关的不同成分或实体扮演的不同角色。谓词是一个动词或动词短语,它描述了一个动作或状态。参数角色描述了与谓词相关的实体在句子中扮演的不同角色,例如主语、宾语、施事者、受事者等。
参数角色的例子可以是:
主语(Agent):执行或控制动作的实体。
宾语(Patient):动作的承受者或受影响的实体。
施事者(Experiencer):感知或经历动作或状态的实体。
受事者(Theme):被动作所作用或影响的实体。
工具(Instrument):执行动作所使用的工具或手段。
地点(Location):动作发生的地点。
时间(Time):动作发生的时间。
例如,
案例1
输入:
T0:奥巴马曾于2005年1月3日担任美国参议员。然后,他于2009年5月20日当选美国总统。
T1: 在赢得总统大选之前,奥巴马于2008年27日被提名为美国总统。
该任务的现有方法可分为超监督、半监督和无监督的方法。
早期的研究中应用了监督方法。它们从带有标注的数据中学习,然后从新的文本中归纳出事件模式。例如,第三次MUC评估 中的方法使用了模式匹配(例如正则表达式)、将句法分析与语义和后续处理相结合的句法驱动技术,或将句法驱动技术与模式匹配相结合,以进行事件模式归纳。Chieu等人采用了语义和篇章特征,构建了一个分类器,如最大熵、支持向量机(SVM)、朴素贝叶斯或决策树,来识别每个参数角色。
半监督方法 从少量标注的种子开始归纳事件模式。例如,Patwardhan和Riloff创建了一个自训练的SVM,用于识别与感兴趣领域相关的句子,然后通过语义相关性提取领域相关的事件模式。自训练从种子模式和相关与不相关的文档开始。随后的事件模式提取基于句法分析的启发式规则。提取的结果按照频率基于语义相关性进行排名,以保留前几个结果。Huang和Ji通过利用少量已知类型的注释,发现了未见过的事件类型。他们设计了一个向量量化的变分自编码器,为每个已知或未知的事件类型学习嵌入,并使用已知事件类型进行优化。进一步引入了变分自编码器,以强制在给定事件类型分布的条件下重构每个事件触发器。
第三次Message Understanding Conference(MUC)评估是在1991年举办的一个评测活动,旨在推动和评估自然语言处理系统在信息提取任务上的性能。该评估的任务是从文本中提取出预定义的信息,包括实体(如人名、地名)、关系(如工作关系、拥有关系)和事件(如会议、爆炸事件)。评估方法主要基于评估参与系统的结果和性能指标。在第三次MUC评估中,参与系统采用了不同的方法来识别和提取文本中的实体、关系和事件。其中一些方法使用了模式匹配、句法分析和语义处理等技术来识别和提取信息。例如,某些参与系统使用正则表达式等模式匹配技术来识别特定的实体和关系模式。另一些系统结合了句法分析和语义处理,通过分析句子的结构和语义关系来提取信息。
无监督方法 消除了对带有标注数据的要求,并得到了广泛应用。例如,Chambers和Jurafsky将事件模式归纳视为发现无限制的关系。他们使用点互信息(PMI) 来衡量事件之间的距离,并根据距离对事件进行聚类。然后,他们通过句法关系归纳事件的参数角色。Balasubramanian等人利用(s,p,o)三元组的共现统计数据构建了一个图,其中这些三元组作为节点,边的权重由涉及的三元组对的对称条件概率加权。其中的三元组使用词干化的头词和语义类型进行标准化。他们从高连通性节点开始作为种子。然后,他们应用图分析来找到与种子密切相关的三元组,并合并它们的参数角色以创建事件模式。Chambers提出了第一个类似于 LDA的生成模型用于模式归纳。
点互信息(Pointwise Mutual Information,简称PMI)是一种用于衡量两个事件之间关联程度的统计量。它基于事件的共现频率来计算事件之间的相关性。
在信息论中,点互信息是指事件A和事件B同时发生的概率与事件A和事件B分别独立发生的概率的比值。具体计算公式如下:
PMI(A, B) = log(P(A, B) / (P(A) * P(B)))
其中,P(A, B)表示事件A和事件B同时发生的概率,P(A)和P(B)分别表示事件A和事件B独立发生的概率。
PMI的值可以表示事件A和事件B之间的相关性程度。当PMI的值大于0时,表示事件A和事件B之间存在正相关关系;当PMI的值小于0时,表示事件A和事件B之间存在负相关关系;当PMI的值等于0时,表示事件A和事件B之间不存在关联。
LDA(Latent Dirichlet Allocation)是一种生成模型,用于主题建模和文本分析。它是一种无监督学习方法,可以从文本数据中发现潜在的主题结构。
LDA的基本思想是假设每个文档由多个主题组成,而每个主题又由一组词语构成。通过LDA模型,我们可以推断出文档中的主题分布以及每个主题中词语的分布。
LDA模型的输入是一个包含多个文档的语料库,每个文档由一系列词语组成。LDA通过迭代过程来学习主题和词语的分布情况。在每次迭代中,LDA会随机地将每个词语分配给一个主题,并更新主题和词语的分布参数,直到达到收敛状态。
LDA模型的输出包括每个文档的主题分布和每个主题中词语的分布。通过分析这些分布,我们可以了解文档中的主题结构,并从中挖掘出潜在的主题信息。LDA模型可以用于文本聚类、文本分类、主题检索等任务,在文本分析和信息检索领域有广泛的应用。
最近的研究引入了表示学习来无监督地诱导事件模式。例如,Yuan等人提出了一个两步的框架。他们首先通过对新闻文章进行聚类来检测事件类型。然后,他们提出了一个基于图的模型,利用实体共现来学习实体嵌入,并将这些嵌入聚类成论证角色。2019年国际语义评估研讨会上的方法应用了预训练的语言模型,如BERT,来获取词向量。然后,他们将这些嵌入与手工特征进行聚类,并将其对齐到现有事件模式(如FrameNet)的事件类型和论证角色。Yamada等人认为之前的研究过于关注动词事件触发词的表面信息,并提出使用BERT的掩码词嵌入来获得深度上下文化的词嵌入。然后,他们采用了一个两步的聚类方法,根据嵌入将相同动词的实例进行聚类,进一步跨动词进行聚类。最后,每个生成的聚类被视为一个诱导的模式。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型。BERT的主要创新之处在于它采用了双向(bidirectional)的训练方式,能够同时利用左侧和右侧的上下文信息来预测一个词语的表示。
BERT的训练过程分为两个阶段:预训练和微调。在预训练阶段,BERT模型使用大规模的无标签文本数据进行训练,通过掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)等任务来学习词语和句子的表示。预训练过程产生的模型可以被应用于各种下游任务。
在微调阶段,BERT模型通过在特定任务上进行有监督的微调来适应具体的任务,如文本分类、命名实体识别、问答系统等。
假设我们有一个句子:“我喜欢吃冰淇淋,尤其是巧克力口味的。”,我们要预测被掩码的词语。
在传统的单向语言模型中,如果我们只考虑左侧的上下文信息,那么在预测"口味"这个词时,我们只能依赖于前面的词语"巧克力"来进行预测。
但在BERT模型中,它同时利用了左侧和右侧的上下文信息。在预训练阶段,模型可能会将句子处理成类似以下形式的输入:
“[CLS] 我喜欢吃冰淇淋,尤其是 [MASK] 口味的 [SEP]”
其中,"[MASK]“表示被掩码的词语,”[CLS]“和”[SEP]"是特殊的标记。
在这个例子中,BERT模型会根据左侧的上下文"尤其是"和右侧的上下文"的"来预测被掩码的词语。通过同时考虑左侧和右侧的上下文信息,模型可以更好地理解"口味"这个词的语义和语境,从而更准确地预测出正确的词语。
通过对数据进行聚类分析,将数据中相似的项(如文本、实体、事件等)归为一类,形成了不同的聚类群集。每个聚类群集可以被看作是一种诱导出的模式或结构,因为它们代表了数据中的某种共性或相关性。
诱导出的模式或结构可以帮助我们理解数据的组织方式,发现数据中的模式和关联性。这些模式或结构在进一步的分析和应用中可以提供有用的信息,例如进行数据挖掘、特征提取、模式识别等任务。
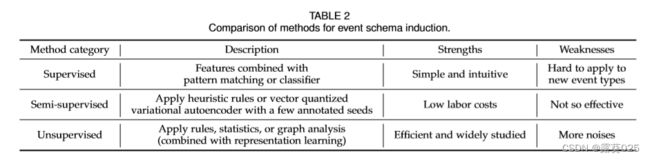
总之,如表2所示,对于有监督的方法,它们很难应用于新的事件类型,这限制了它们的使用。对于半监督和无监督的方法,自动推导的事件模式存在噪声,并且很难对齐。到目前为止,这些技术在构建EKG的事件模式方面仍然不太适用。