C++入门——上卷(&引用详解)
C++入门——上卷
- 命名空间的探究
-
- 1,命名空间的定义
- 2,命名空间的使用
- 缺省参数
-
-
- 1.什么是缺省参数
- 2,全缺省与半缺省:
-
- 引用
-
-
- 1,什么是引用
- 2,引用的特性
- 3,常引用
- 4,使用场景
-
-
-
- 1,做参数
- 引用做参数可以减少拷贝,提高效率
-
-
-
- 引用做返回值详解!
-
- 引用与指针的区别
命名空间的探究
注:
命名空间必须是全局定义的
命名空间就是namespace +XXX
为什么要有这个?
在我们后续的学习中,*变量,函数和类的名称将都存在于全局作用域中,由于命名可能是相同的,所以可能会导致冲突,同时假设在日后大型工程的开发中,公司不同的程序员可能会命名相同的变量名,如果没有命名空间就会出错。
理解
命名空间可以理解成一个个独立的空间
eg:namespace+N1
namespace+N2
那么N1与N2都是互不干扰的,他们之间的变量名都是独立存在的,除非把空间打开,他们才可能互相干扰。

1,命名空间的定义
namespace N//N为命名空间的名称,可以自己定义
{
//命名空间中的内容,可以是变量,也可以是函数,也可以嵌套
int b;
int Sub(int a, int b)
{
return a * b;
}
namespace N2
{
int d;
int Add(int x, int y)
{
return x + y;
}
}
}
//同一个工程中允许有相同的命名空间,编译器最后会将他们合并成一个命名空间
//eg
namespace N
{
//这个命名空间与上面的名字相同,编译器在最后会将他们合并成在一起
char arr[] = "abcdefg";
int sq = 0;
}
//相当于是
namespace N
{
char arr[] = "abcdefg";
int sq = 0;
int b;
int Sub(int a, int b)
{
return a * b;
}
namespace N2
{
int d;
int Add(int x, int y)
{
return x + y;
}
}
}
注
*在学习C语言中,我们都知道有局部作用域和全局作用域,一个命名空间就相当于重新定义了一个全新的作用域,只有使用该命名空间,那么其中全新的作用域会部分打开或者全部打开变成全局作用域,具体看我们如何使用命名空间。
2,命名空间的使用
1。加命名作用域及作用域限定符
作用域限定符就是‘::’
2,使用using将命名空间中成员引入
3,使用using+命名空间名称
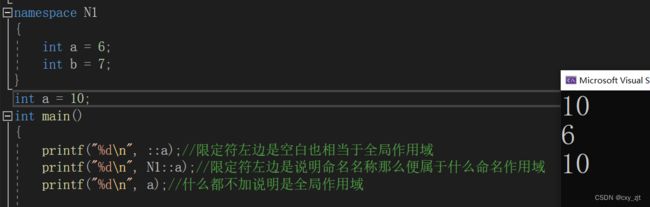
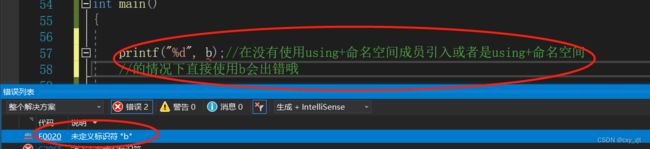


所以
我们写c++的时候前面总是有一个using namespace std
中std是C++标准库中标准函数标准类等都在std中定义
缺省参数
1.什么是缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该时,如果没有指定实参则采用该默认值,否则使用指定的实参
缺省参数中的默认值相当于是一个备胎,如果没有给他传参,那么就用这个备胎,也就是默认值,但如果给他传参的话,就不用备胎,用的就是传的参数了。
eg
void Test(int a = 3)
{
cout<<a<<endl;
}
int main()
{
Test(); // 没有传参时,使用参数的默认值输出3
Test(10); // 传参时,使用指定的实参输出10
}
2,全缺省与半缺省:
全缺省:
void TestF(int a = 5, int b = 10, int c = 20)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
int main()
{
Test();//输出5,10,20
Test(2);//输出2,10,20
Test(2, 9);//输出2,9,20
Test(8, 9, 80);//输出8,9,80;
}
半缺省:
- 半缺省参数必须从右往左依次来给出,不能间隔着给
void Test(int a, int b = 10, int c = 20)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
int main()
{
Test();//报错,因为此时函数为半缺省,第一个参数一定得有
Test(8);//输出8 10 20
Test(2, 9);//输出2,9,20
Test(8, 9, 80);//输出8,9,80;
return 0;
}
//半缺省参数必须从右往左依次来给出,不能间隔着给
void Test(int a = 20, int b , int c = 20)
{//这样定义的半缺省参数是错误的
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
void Test(int a, int b = 10, int c)
{//这样定义的半缺省参数也是错误的
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
2,缺省参数声明和定义不能同时出现
//a.h
void Test(int a = 10);
//a.c
void Test(int a = 20);
防止出现类似这种情况
若要缺省,只能是声明给缺省,定义不给缺省!
因为先编译阶段编译器就去找声明,定义的话是后面链接的时候才能去找的(大概是这样,hh)
没讲清楚的话就按函数是按先声明后定义的,所以要想该函数有缺省参数,只能在声明上操作,否则如果是定义上缺省,那么声明的时候该函数不是缺省函数,那么定义找到他的时候发现参数错误。所以只能是声明缺省,定义不缺省
具体深究请看下一篇博客,
引用
1,什么是引用
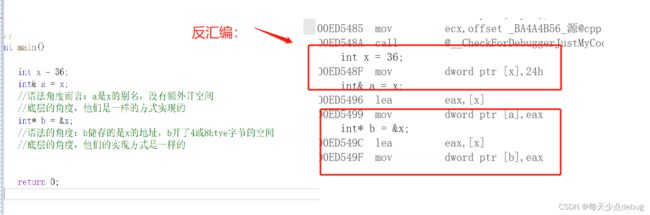
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它
引用的变量共用同一块内存空间。
eg:
int a = 7;
int& c = a;
int& d = a;
printf("%d\n", a);//7
printf("%d\n", c);//7
printf("%d\n", d);//7
printf("%p\n", &a);//008FFE54
printf("%p\n", &c);//008FFE54
printf("%p\n", &d);//008FFE54
c = 6;
printf("%d\n", a);//6
printf("%d\n", c);//6
printf("%d\n", d);//6
return 0;
上述代码中,我们将a取了另外两个名字,c和d,当我们改变c或者d的时候会影响a,因为此时三者本质上是一样的,只是叫法不同
2,引用的特性
- 引用在定义时必须初始化
//int& b;直接这样写会报错 - 一个变量可以有多个引用
就好比一个人在不同的环境中可能是有不同的小名的。 - 引用一旦引用一个实体,再不能引用其他实体
int a = 7;
int c = 8;
int& x = a;
int&x = c;
//这样写也是错误的!
3,常引用
什么是常引用?
也就是与常量有关的引用。
假设此时有
const int a = 7;
int &c = a;
发现会报错,但是改成
const int&c = a;
这个时候就不会报错
同时假设有
int a = 8;
const int&c = a;
这个时候也是不会报错的
经过上述的一些代码,总结一下:
取名原则对原引用变量,权限只能缩小不能发大;
解释一下:
如果只是一个简单的int a = 3;
我们可以理解为此时a是既可以读又可以改写的,但假设我们此时是const int a = 3;
那么我们此时的a是只能读不能改的,如果加了const那么我们便不能改这个值,那么这个时候可以理解为此时的a是一个常量了

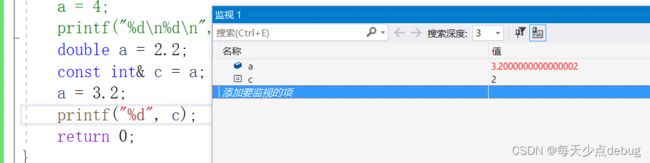
根据vs的调试可以发现,此时就算是改变了a的值,但是c的值也不会改变,因为c此时相当于就是一个常量的名称。(具体用法)以后的博客会更新hh
4,使用场景
1,做参数
eg:
void Swap(int&a,int&b)
之前在语言中如果是用自己的交换函数的话此时我们得用Swap(&c,&d),
必须将a和b的地址传进去才可以交换,否则会出现形参只是实参的一种临时拷贝,形参的改变不影响实参 但此时我们可以直接Swap(c,d),因为我们此时函数的参数是引用,相当于此时a是c的别名b
是d的别名,交换a,b就是直接交换c和d了。
引用做参数可以减少拷贝,提高效率
#include上述代码的输出值:Test1(A)-time:39 Test2A&)-time:0
可以因为引出做参数的时候是不需要额外空间的,只相当于是取了另外一个名字,但是上述第一个函数是每次都需要拷贝几万个字节,所以对比下来引用可以大大的提高效率,但其实如果我们用指针传参的话所消耗的时间跟引用差不多,因为引用的底层和指针是类似的,但是指针没有引用来的直观,对比下来,还是引用传参比较好一点。
引用做返回值详解!
先看一串代码
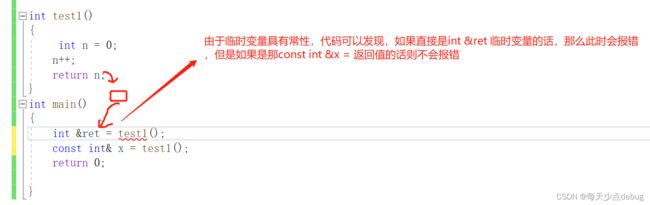
int test1()
{
static int n = 0;
n++;
return n;
}
int main()
{
cout << test1() << endl;
cout << test1() << endl;
cout << test1() << endl;
return 0;
}
上述代码的输出是:1,2,3
因为上述函数用了static int 只有第一次会初始化n,之后不会了
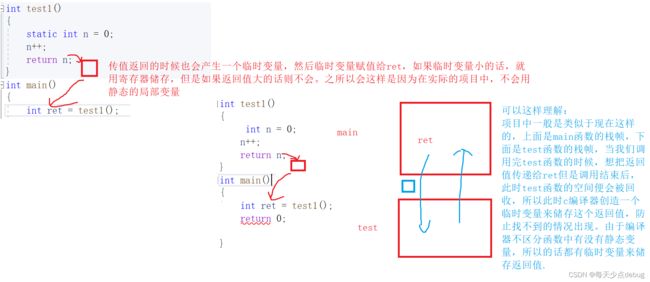
证明一下临时变量的存在:
传值返回差不都了,下面是传引用返回了。
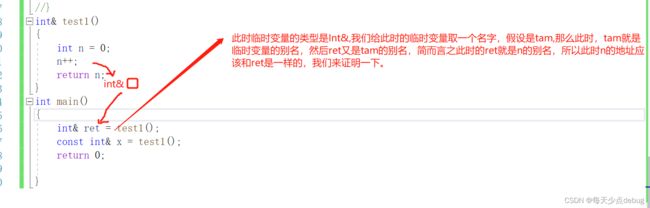
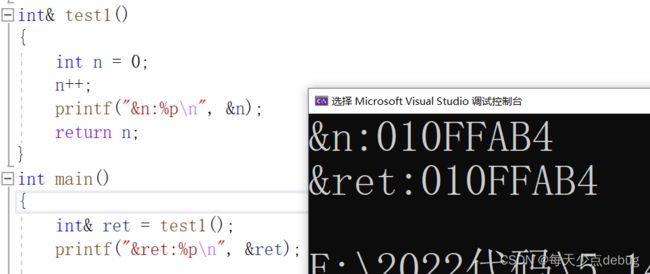
有代码可以发现,结果是正确的。
总结:
1,传值返回:会有一个拷贝
2,传引用返回:函数返回的就是返回变量的别名。
但此时会出现一个大问题!!!
如果是传引用返回的话,是返回对象的别名,但是一般情况下,我们调用结束函数之后,该函数的空间会被系统回收,此时无法在使用原来函数的空间了,同时我们如果在调用完函数后,由调用了其他的函数,那么原来函数的空间便会被覆盖,那么此时返回对象的值便会变成随机值。此时用传引用返回是非常危险的一个行为,上面的函数安全是因为用的是静态变量,返回值n的空间即使调函数后也不会被回收。或者是在调用完函数后没有调用其他函数,函数原来的空间值没改变,此时返回值也不会变的。
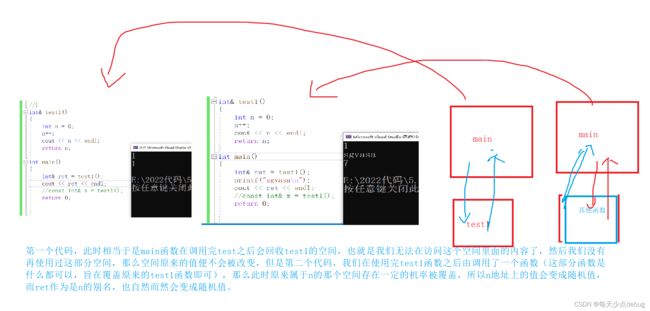

所以有一个规定:
注意:如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已经还给系统了,则必须使用传值返回,否则会出现越界的问题!
引用与指针的区别
引用和指针的不同点:
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全