缺陷检测文献
AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models
中科院
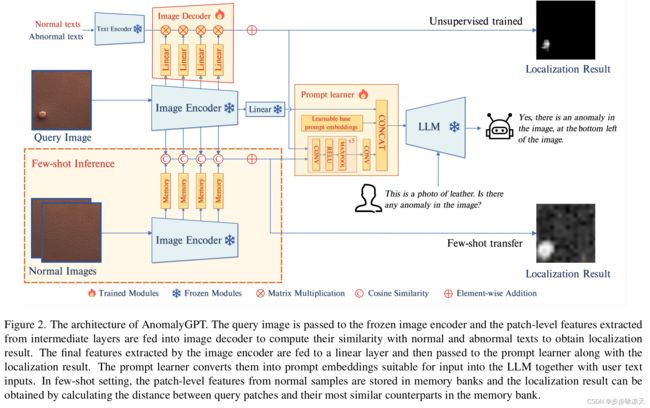
Large Vision-Language Models (LVLMs) such as MiniGPT-4 and LLaVA have demonstrated the capability of understanding images and achieved remarkable performance in various visual tasks. Despite their strong abilities in recognizing common objects due to extensive training datasets, they lack specific domain knowledge and have a weaker understanding of localized details within objects, which hinders their effectiveness in the Industrial Anomaly Detection (IAD) task. On the other hand, most existing IAD methods only provide anomaly scores and necessitate the manual setting of thresholds to distinguish between normal and abnormal samples, which restricts their practical implementation. In this paper, we explore the utilization of LVLM to address the IAD problem and propose AnomalyGPT, a novel IAD approach based on LVLM. We generate training data by simulating anomalous images and producing corresponding textual descriptions for each image. We also employ an image decoder to provide fine-grained semantic and design a prompt learner to fine-tune the LVLM using prompt embeddings. Our AnomalyGPT eliminates the need for manual threshold adjustments, thus directly assesses the presence and locations of anomalies. Additionally, AnomalyGPT supports multi-turn dialogues and exhibits impressive few-shot in-context learning capabilities. With only one normal shot, AnomalyGPT achieves the state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset. Code is available at https://github.com/CASIA-IVA-Lab/AnomalyGPT.
REB: Reducing Biases in Representation for Industrial Anomaly Detection
202308
香港理工大学
Existing K-nearest neighbor (KNN) retrieval-based methods usually conduct industrial anomaly detection in two stages: obtain feature representations with a pre-trained CNN model and perform distance measures for defect detection. However, the features are not fully exploited as they ignore domain bias and the difference of local density in feature space, which limits the detection performance. In this paper, we propose Reducing Biases (REB) in representation by considering the domain bias of the pre-trained model and building a self-supervised learning task for better domain adaption with a defect generation strategy (DefectMaker) imitating the natural defects. Additionally, we propose a local density KNN (LDKNN) to reduce the local density bias and obtain effective anomaly detection. We achieve a promising result of 99.5% AUROC on the widely used MVTec AD benchmark. We also achieve 88.0% AUROC on the challenging MVTec LOCO AD dataset and bring an improvement of 4.7% AUROC to the state-of-the-art result. All results are obtained with smaller backbone networks such as Vgg11 and Resnet18, which indicates the effectiveness and efficiency of REB for practical industrial applications.
Random Word Data Augmentation with CLIP for Zero-Shot Anomaly Detection
Big Data Analytics Solutions Lab Hitachi America, Ltd.
20230822
This paper presents a novel method that leverages a visual-language model, CLIP, as a data source for zero-shot anomaly detection. Tremendous efforts have been put towards developing anomaly detectors due to their potential industrial applications. Considering the difficulty in acquiring various anomalous samples for training, most existing methods train models with only normal samples and measure discrepancies from the distribution of normal samples during inference, which requires training a model for each object cat-egory. The problem of this inefficient training requirement has been tackled by designing a CLIP-based anomaly detector that applies prompt-guided classification to each part o fan image in a sliding window manner. However, the method still suffers from the labor of careful prompt ensembling with known object categories. To overcome the issues above,we propose leveraging CLIP as a data source for training. Our method generates texte mbeddings with the text encoder in CLIP with typical prompts that include words of normal and anomaly. In addition to these words, we insert several randomly generated words into prompts, which enables the encoder to generate a diverse set of normal and anomalous samples. Using the generated embeddings as training data, a feed-forward neural network learns to extract features of normal and anomaly from CLIP’s embed-dings, and as a result, a category-agnostic anomaly detector can be obtained without any training images. Experimental results demonstrate that our method achieves state-of-the-art performance without laborious prompt ensembling in zero-shot setups.
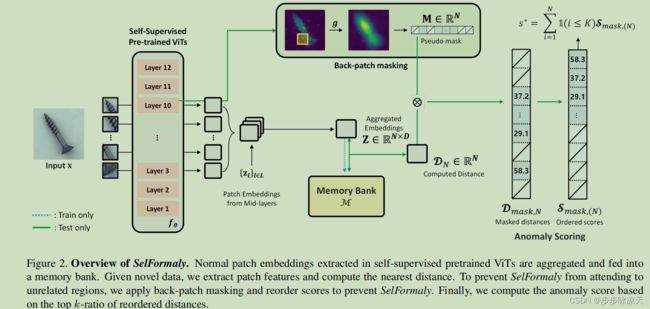
SelFormaly: Towards Task-Agnostic Unified Anomaly Detection
2023.7
Yonsei University
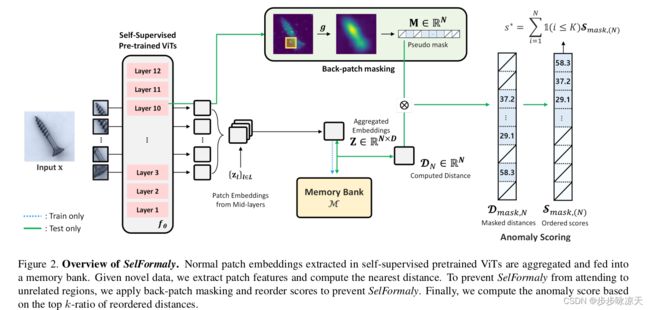
The core idea of visual anomaly detection is to learn the normality from normal images, but previous works have been developed specifically for certain tasks, leading to fragmentation among various tasks: defect detection, semantic anomaly detection, multi-class anomaly detection, and anomaly clustering. This one-task-one-model approach is resource-intensive and incurs high maintenance costs as the number of tasks increases. This paper presents SelFormaly, a universal and powerful anomaly detection framework. We emphasize the necessity of our off-the-shelf approach by pointing out a suboptimal issue with fluctuating performance in previous online encoder-based methods. In addition, we question the effectiveness of using ConvNets as previously employed in the literature and confirm that self-supervised ViTs are suitable for unified anomaly detection. We introduce back-patch masking and discover the new role of top k-ratio feature matching to achieve unified and powerful anomaly detection. Back-patch masking eliminates irrelevant regions that possibly hinder target-centric detection with representations of the scene layout. The top k-ratio feature matching unifies various anomaly levels and tasks. Finally, SelFormaly achieves state-of-the-art results across various datasets for all the aforementioned tasks.
Focus the Discrepancy: Intra- and Inter-Correlation Learning for Image Anomaly Detection
ICCV2023
上海交大
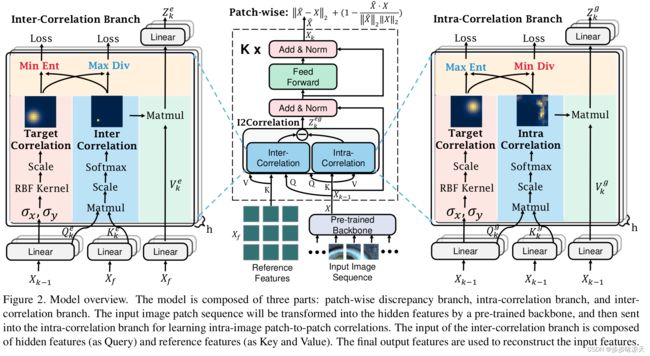
Humans recognize anomalies through two aspects: larger patch-wise representation discrepancies and weaker patch-to-normal-patch correlations. However, the previous AD methods didn’t sufficiently combine the two complementary aspects to design AD models. To this end, we find that Transformer can ideally satisfy the two aspects as its great power in the unified modeling of patch-wise representations and patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can simultaneously spot the patch-wise, intra- and inter-discrepancies of anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to Intra-Inter-Correlation (I2Correlation). The I2Correlation contains a two-branch structure to first explicitly establish intra- and inter-image correlations, and then fuses the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning. Besides, we introduce an entropy constraint strategy to solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability. Extensive experiments on three unsupervised real-world AD benchmarks show the superior performance of our approach. Code will be available at https://github.com/xcyao00/FOD.
SelFormaly: Towards Task-Agnostic Unified Anomaly Detection
2023.7
The core idea of visual anomaly detection is to learn the normality from normal images, but previous works have been developed specifically for certain tasks, leading to fragmentation among various tasks: defect detection, semantic anomaly detection, multi-class anomaly detection, and anomaly clustering. This one-task-one-model approach is resource-intensive and incurs high maintenance costs as the number of tasks increases. This paper presents SelFormaly, a universal and powerful anomaly detection framework. We emphasize the necessity of our off-the-shelf approach by pointing out a suboptimal issue with fluctuating performance in previous online encoder-based methods. In addition, we question the effectiveness of using ConvNets as previously employed in the literature and confirm that self-supervised ViTs are suitable for unified anomaly detection. We introduce back-patch masking and discover the new role of top k-ratio feature matching to achieve unified and powerful anomaly detection. Back-patch masking eliminates irrelevant regions that possibly hinder target-centric detection with representations of the scene layout. The top k-ratio feature matching unifies various anomaly levels and tasks. Finally, SelFormaly achieves state-of-the-art results across various datasets for all the aforementioned tasks.
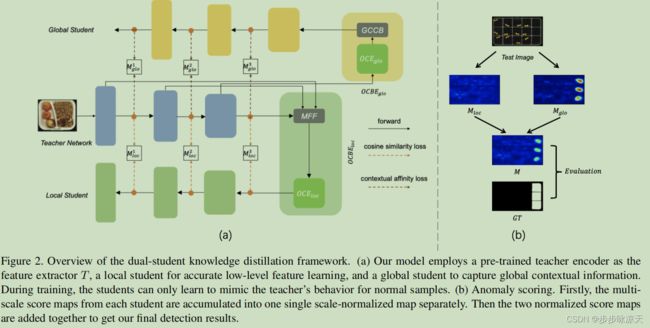
Contextual Affinity Distillation for Image Anomaly Detection
http://export.arxiv.org/abs/2307.03101
Tohoku University
Previous works on unsupervised industrial anomaly detection mainly focus on local structural anomalies such as cracks and color contamination. While achieving significantly high detection performance on this kind of anomaly, they are faced with logical anomalies that violate the long-range dependencies such as a normal object placed in the wrong position. In this paper, based on previous knowledge distillation works, we propose to use two students (local and global) to better mimic the teacher’s behavior. The local student, which is used in previous studies mainly focuses on structural anomaly detection while the global student pays attention to logical anomalies. To further encourage the global student’s learning to capture long-range dependencies, we design the global context condensing block (GCCB) and propose a contextual affinity loss for the student training and anomaly scoring. Experimental results show the proposed method doesn’t need cumbersome training techniques and achieves a new state-of-the-art performance on the MVTec LOCO AD dataset.
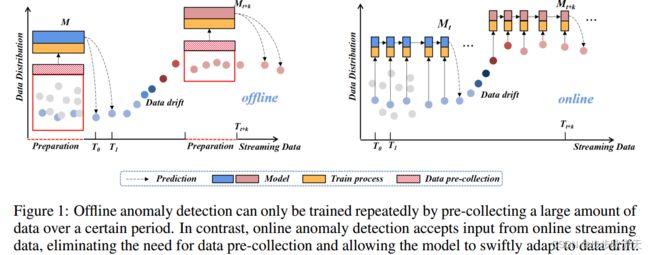
Towards Total Online Unsupervised Anomaly Detection and Localization in Industrial Vision
中国科学院自动化研究所智能工业视觉工程实验室
https://arxiv.org/abs/2305.15652
Although existing image anomaly detection methods yield impressive results, they are mostly an offline learning paradigm that requires excessive data pre-collection, limiting their adaptability in industrial scenarios with online streaming data. Online learning-based image anomaly detection methods are more compatible with industrial online streaming data but are rarely noticed. For the first time, this paper presents a fully online learning image anomaly detection method, namely LeMO, learning memory for online image anomaly detection. LeMO leverages learnable memory initialized with orthogonal random noise, eliminating the need for excessive data in memory initialization and circumventing the inefficiencies of offline data collection. Moreover, a contrastive learning-based loss function for anomaly detection is designed to enable online joint optimization of memory and image target-oriented features. The presented method is simple and highly effective. Extensive experiments demonstrate the superior performance of LeMO in the online setting. Additionally, in the offline setting, LeMO is also competitive with the current state-of-the-art methods and achieves excellent performance in few-shot scenarios.
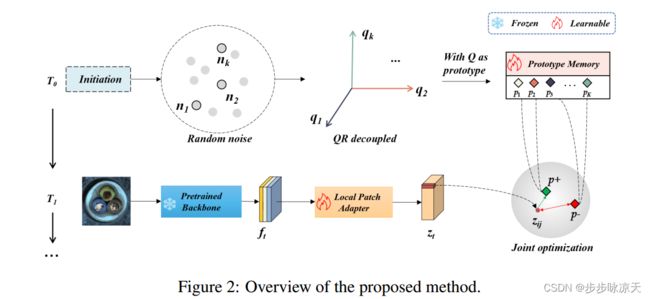
NCE loss https://www.kdnuggets.com/2019/07/introduction-noise-contrastive-estimation.html
AnoOnly: Semi-Supervised Anomaly Detection without Loss on Normal Data
电子科技大学
https://arxiv.org/abs/2305.18798
Semi-supervised anomaly detection (SSAD) methods have demonstrated their effectiveness in enhancing unsupervised anomaly detection (UAD) by leveraging few-shot but instructive abnormal instances. However, the dominance of homogeneous normal data over anomalies biases the SSAD models against effectively perceiving anomalies. To address this issue and achieve balanced supervision between heavily imbalanced normal and abnormal data, we develop a novel framework called AnoOnly (Anomaly Only). Unlike existing SSAD methods that resort to strict loss supervision, AnoOnly suspends it and introduces a form of weak supervision for normal data. This weak supervision is instantiated through the utilization of batch normalization, which implicitly performs cluster learning on normal data. When integrated into existing SSAD methods, the proposed AnoOnly demonstrates remarkable performance enhancements across various models and datasets, achieving new state-of-the-art performance. Additionally, our AnoOnly is natively robust to label noise when suffering from data contamination.
DSR – A dual subspace re-projection network for surface anomaly detection
ECCV 2022 (DRAEM 同组工作)
The state-of-the-art in discriminative unsupervised surface anomaly detection relies on external datasets for synthesizing anomaly-augmented training images. Such approaches are prone to failure on near-in-distribution anomalies since these are difficult to be synthesized realistically due to their similarity to anomaly-free regions. We propose an architecture based on quantized feature space representation with dual decoders, DSR, that avoids the image-level anomaly synthesis requirement. Without making any assumptions about the visual properties of anomalies, DSR generates the anomalies at the feature level by sampling the learned quantized feature space, which allows a controlled generation of near-in-distribution anomalies. DSR achieves state-of-the-art results on the KSDD2 and MVTec anomaly detection datasets. The experiments on the challenging real-world KSDD2 dataset show that DSR significantly outperforms other unsupervised surface anomaly detection methods, improving the previous top-performing methods by 10%
AP in anomaly detection and 35%

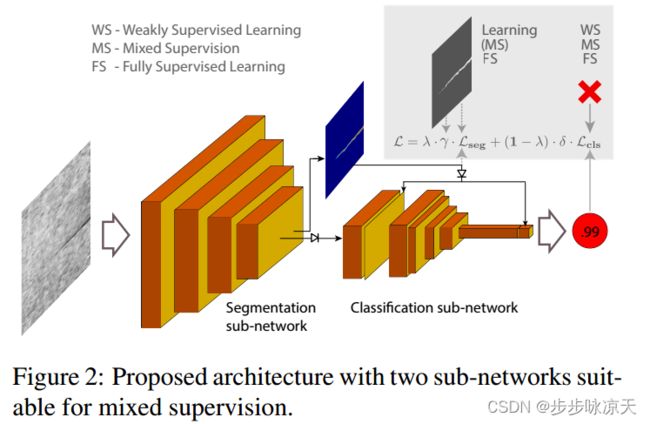
Mixed supervision for surface-defect detection: from weakly to fully supervised learning
Computers in Industry (sci 2区) 2021
Deep-learning methods have recently started being employed for addressing surface-defect detection problems in industrial quality control. However, with a large amount of data needed for learning, often requiring high-precision labels, many industrial problems cannot be easily solved, or the cost of the solutions would significantly increase due to the annotation requirements. In this work, we relax heavy requirements of fully supervised learning methods and reduce the need for highly detailed annotations. By proposing a deep-learning architecture, we explore the use of annotations of different details ranging from weak (image-level) labels through mixed supervision to full (pixel-level) annotations on the task of surface-defect detection. The proposed end-to-end architecture is composed of two sub-networks yielding defect segmentation and classification results. The proposed method is evaluated on several datasets for industrial quality inspection: KolektorSDD, DAGM and Severstal Steel Defect. We also present a new dataset termed KolektorSDD2 with over 3000 images containing several types of defects, obtained while addressing a real-world industrial problem. We demonstrate state-of-the-art results on all four datasets. The proposed method outperforms all related approaches in fully supervised settings and also outperforms weakly-supervised methods when only image-level labels are available. We also show that mixed supervision with only a handful of fully annotated samples added to weakly labelled training images can result in performance comparable to the fully supervised model’s performance but at a significantly lower annotation cost.
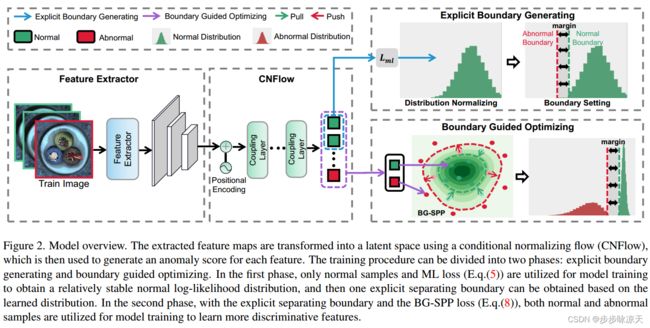
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection
CVPR 2023 上海交通大学
Most anomaly detection (AD) models are learned using only normal samples in an unsupervised way, which may result in ambiguous decision boundary and insufficient discriminability. In fact, a few anomaly samples are often available in real-world applications, the valuable knowledge of known anomalies should also be effectively exploited. However, utilizing a few known anomalies during training may cause another issue that the model may be biased by those known anomalies and fail to generalize to unseen anomalies. In this paper, we tackle supervised anomaly detection, i.e., we learn AD models using a few available anomalies with the objective to detect both the seen and unseen anomalies. We propose a novel explicit boundary guided semi-push-pull contrastive learning mechanism, which can enhance model’s discriminability while mitigating the bias issue. Our approach is based on two core designs: First, we find an explicit and compact separating boundary as the guidance for further feature learning. As the boundary only relies on the normal feature distribution, the bias problem caused by a few known anomalies can be alleviated. Second, a boundary guided semipush-pull loss is developed to only pull the normal features together while pushing the abnormal features apart from the separating boundary beyond a certain margin region. In this way, our model can form a more explicit and discriminative decision boundary to distinguish known and also unseen anomalies from normal samples more effectively.
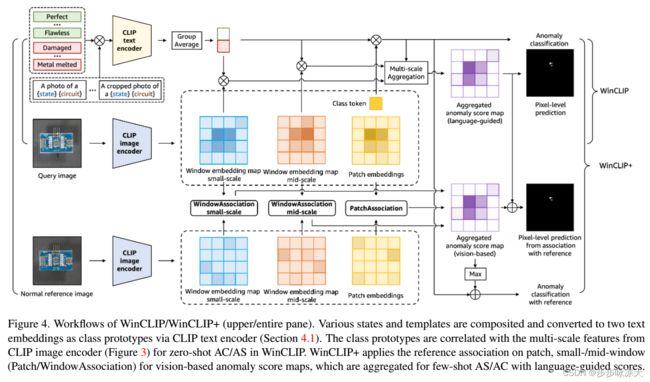
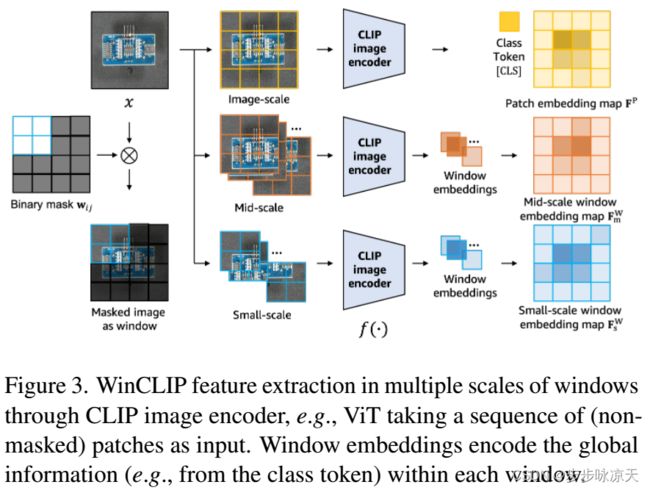
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
CVPR 2023
AWS AI Labs
Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
Diversity-Measurable Anomaly Detection
CVPR 2023 中科院
存在问题:在测试集找阈值.
Few-Shot Defect Image Generation via Defect-Aware Feature Manipulation
AAAI 2023 上海交通大学
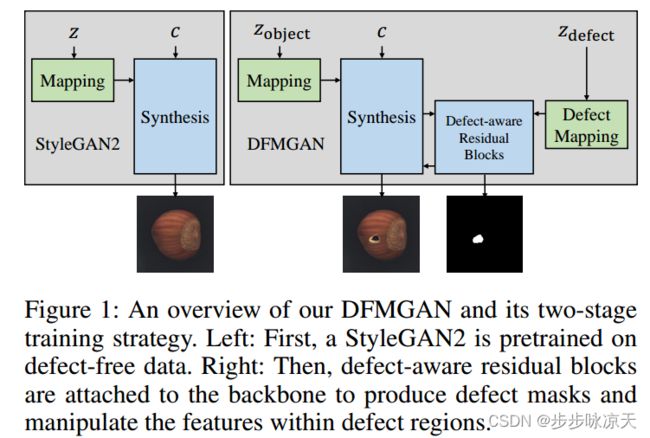
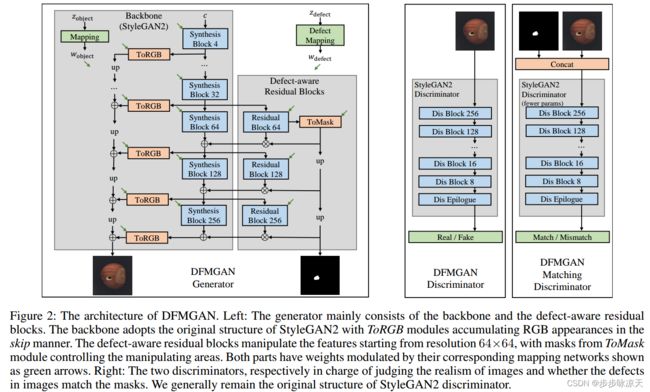
The performances of defect inspection have been severely hindered by insufficient defect images in industries, which can be alleviated by generating more samples as data augmentation. We propose the first defect image generation method in the challenging few-shot cases. Given just a handful of defect images and relatively more defect-free ones, our goal is to augment the dataset with new defect images. Our method consists of two training stages. First, we train a data-efficient StyleGAN2 on defect-free images as the backbone. Second, we attach defect-aware residual blocks to the backbone, which learn to produce reasonable defect masks and accordingly manipulate the features within the masked regions by training the added modules on limited defect images. Extensive experiments on MVTec AD dataset not only validate the effectiveness of our method in generating realistic and diverse defect images, but also manifest the benefits it brings to downstream defect inspection tasks.
PyramidFlow: High-Resolution Defect Contrastive Localization using Pyramid Normalizing Flow
CVPR 2023 浙江大学
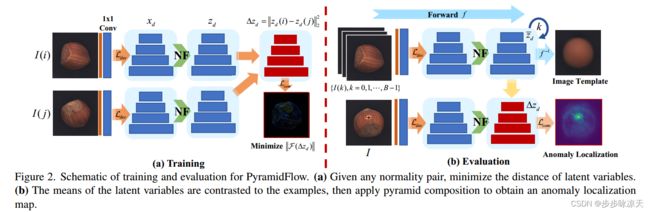
During industrial processing, unforeseen defects may arise in products due to uncontrollable factors. Although unsupervised methods have been successful in defect localization, the usual use of pre-trained models results in low resolution outputs, which damages visual performance. To address this issue, we propose PyramidFlow, the first fully normalizing flow method without pre-trained models that enables high-resolution defect localization. Specifically, we propose a latent template-based defect contrastive localization paradigm to reduce intra-class variance, as the pre-trained models do. In addition, PyramidFlow utilizes pyramid-like normalizing flows for multi-scale fusing and volume normalization to help generalization. Our comprehensive studies on MVTecAD demonstrate the proposed method outperforms the comparable algorithms that do not use external priors, even achieving state-of-the-art performance in more challenging BTAD scenarios.
Collaborative Discrepancy Optimization for Reliable Image Anomaly Localization
IEEE Transactions on Industrial Informatics 2023 华中科技大学
https://arxiv.org/pdf/2302.08769v1.pdf
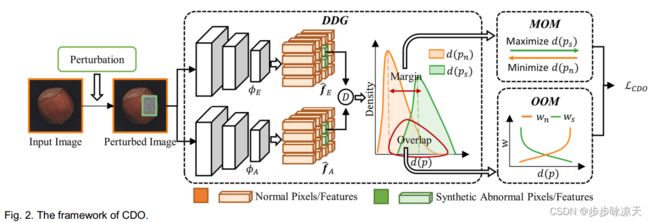
Most unsupervised image anomaly localization methods suffer from overgeneralization because of the high generalization abilities of convolutional neural networks, leading to unreliable predictions. To mitigate the overgeneralization, this study proposes to collaboratively optimize normal and abnormal feature distributions with the assistance of synthetic anomalies, namely collaborative discrepancy optimization (CDO). CDO introduces a margin optimization module and an overlap optimization module to optimize the two key factors determining the localization performance, i.e., the margin and the overlap between the discrepancy distributions (DDs) of normal and abnormal samples. With CDO, a large margin and a small overlap between normal and abnormal DDs are obtained, and the prediction reliability is boosted. Experiments on MVTec2D and MVTec3D show that CDO effectively mitigates the overgeneralization and achieves great anomaly localization performance with real-time computation efficiency. A realworld automotive plastic parts inspection application further demonstrates the capability of the proposed CDO. Code is available on https://github.com/caoyunkang/CDO.

Pushing the Limits of Fewshot Anomaly Detection in Industry Vision: Graphcore
20230128 ICLR 2023 东南大学
https://arxiv.org/abs/2301.12082
In the area of fewshot anomaly detection (FSAD), efficient visual feature plays an essential role in memory bank M-based methods. However, these methods do not account for the relationship between the visual feature and its rotated visual feature, drastically limiting the anomaly detection performance. To push the limits, we reveal that rotation-invariant feature property has a significant impact in industrial-based FSAD. Specifically, we utilize graph representation in FSAD and provide a novel visual isometric invariant feature (VIIF) as anomaly measurement feature. As a result, VIIF can robustly improve the anomaly discriminating ability and can further reduce the size of redundant features stored in M by a large amount. Besides, we provide a novel model GraphCore via VIIFs that can fast implement unsupervised FSAD training and can improve the performance of anomaly detection. A comprehensive evaluation is provided for comparing GraphCore and other SOTA anomaly detection models under our proposed fewshot anomaly detection setting, which shows GraphCore can increase average AUC by 5.8%, 4.1%, 3.4%, and 1.6% on MVTec AD and by 25.5%, 22.0%, 16.9%, and 14.1% on MPDD for 1, 2, 4, and 8-shot cases, respectively.
Adapting the Hypersphere Loss Function from Anomaly Detection to Anomaly Segmentation
2023-01-23 国立巴黎高等矿业学院
We propose an incremental improvement to Fully Convolutional Data Description (FCDD), an adaptation of the one-class classification approach from anomaly detection to image anomaly segmentation (a.k.a. anomaly localization). We analyze its original loss function and propose a substitute that better resembles its predecessor, the Hypersphere Classifier (HSC). Both are compared on the MVTec Anomaly Detection Dataset (MVTec-AD) – training images are flawless objects/textures and the goal is to segment unseen defects – showing that consistent improvement is achieved by better designing the pixel-wise supervision.
PRN
CVPR 2023
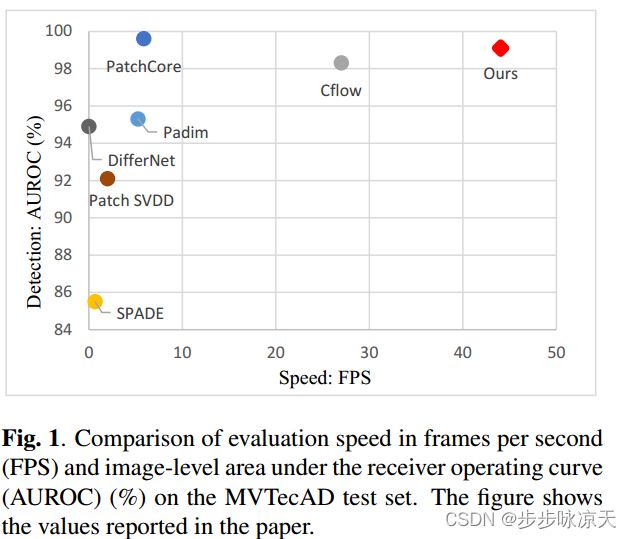
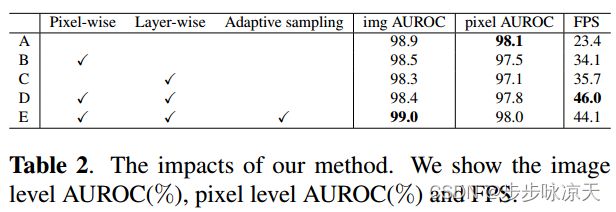
Prototypical Residual Networks for Anomaly Detection and Localization
2022-12-05
复旦大学
Anomaly detection and localization are widely used in industrial manufacturing for its effciency and effectiveness. Anomalies are rare and hard to collect and supervised models easily overfit to these seen anomalies with a handful of abnormal samples, producing unsatisfactory performance. On the other hand, anomalies are typically subtle, hard to discern, and of various appearance, making it difficult to detect anomalies and let alone locate anomalous regions. To address these issues, we propose a framework called Prototypical Residual Network (PRN), which learns feature residuals of varying scales and sizes between anomalous and normal patterns to accurately reconstruct the segmentation maps of anomalous regions. PRN mainly consists of two parts: multi-scale prototypes that explicitly represent the residual features of anomalies to normal patterns; a multisize self-attention mechanism that enables variable-sized anomalous feature learning. Besides, we present a variety of anomaly generation strategies that consider both seen and unseen appearance variance to enlarge and diversify anomalies. Extensive experiments on the challenging and widely used MVTec AD benchmark show that PRN outperforms current state-of-the-art unsupervised and supervised methods. We further report SOTA results on three additional datasets to demonstrate the effectiveness and generalizability of PRN.
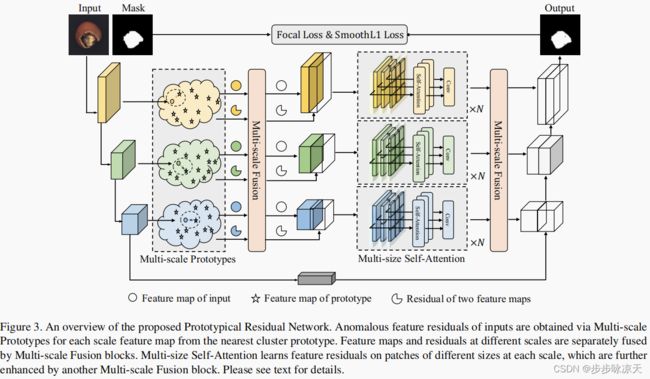
- 无监督方法缺点
However, these methods are opaque to genuine anomalies, resulting in implicit decisions that may induce many false negatives and false positives. Besides, unsupervised methods rely heavily on the quality of normal samples, and thus are not robust enough and perform poorly on uncalibrated or noisy datasets.
Image Anomaly Detection and Localization with Position and Neighborhood
2022-11-22
Seoul National University
Anomaly detection and localization are essential in many areas, where collecting enough anomalous samples for training is almost impossible. To overcome this difficulty, many existing methods use a pre-trained network to encode input images and non-parametric modeling to estimate the encoded feature distribution. In the modeling process, however, they overlook that position and neighborhood information affect the distribution of normal features. To use the information, in this paper, the normal distribution is estimated with conditional probability given neighborhood features, which is modeled with a multi-layer perceptron network. At the same time, positional information can be used by building a histogram of representative features at each position. While existing methods simply resize the anomaly map into the resolution of an input image, the proposed method uses an additional refine network that is trained from synthetic anomaly images to perform better interpolation considering the shape and edge of the input image. For the popular industrial dataset, MVTec AD benchmark, the experimental results show 99.52% and 98.91% AUROC scores in anomaly detection and localization, which is state-of-the-art performance.
这篇论文在PatchCore 基础上加入周边信息和位置信息。通过MLP学习周边信息,用直方图统计位置信息,在推断的时候除了根据特征距离计算概率还考虑周边信息和位置信息的条件概率。此外,还提出refine网络,用人造缺陷训练,得到分辨率高的mask。MVTec detection AUROC=99.52%, localization AUROC=98.91%。
FAPM: FAST ADAPTIVE PATCH MEMORY FOR REAL-TIME INDUSTRIAL ANOMALY DETECTION
2022-11
Yonsei University, Seoul, Korea
Feature embedding-based methods have performed exceptionally well in detecting industrial anomalies by comparing the features of the target image and the normal image. However, such approaches do not consider the inference speed, which is as important as accuracy in real-world applications. To relieve this issue, we propose a method called fast adaptive patch memory (FAPM) for real-time industrial anomaly detection. FAPM consists of patch-wise and layer-wise memory banks that save the embedding features of images in patch-level and layer-level, eliminating unnecessary repeated calculations. We also propose patch-wise adaptive coreset sampling for fast and accurate detection. FAPM performs well for both accuracy and speed compared to other state-of the-art methods.
这篇论文在Patch Core基础上做了3点改进, 达到和Patch Core相当的检测精度, 速度提高到Patch Core的2倍. (1) Patch-wise memory: 一张图分为39个patch, 保存ok样本49个位置patch 的特征向量. (2) Layer-wise memory: 提取wideResNet50 第2,3层特征,分别保存, 避免上采样. (3) Patch-wise adaptive Coreset Sampling: 如果采样的结果, 样本点和聚类中心的距离超过阈值,提高采样比例,重新采样.
SSPCAB: Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
CVPR 2022 University Politehnica of Bucharest
Anomaly detection is commonly pursued as a one-class classification problem, where models can only learn from normal training samples, while being evaluated on both normal and abnormal test samples. Among the successful approaches for anomaly detection, a distinguished category of methods relies on predicting masked information (e.g. patches, future frames, etc.) and leveraging the reconstruction error with respect to the masked information as an abnormality score. Different from related methods, we propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods. Our block starts with a convolutional layer with dilated filters, where the center area of the receptive field is masked. The resulting activation maps are passed through a channel attention module. Our block is equipped with a loss that minimizes the reconstruction error with respect to the masked area in the receptive field. We demonstrate the generality of our block by integrating it into several state-of-the-art frameworks for anomaly detection on image and video, providing empirical evidence that shows considerable performance improvements on MVTec AD, Avenue, and ShanghaiTech
DRA
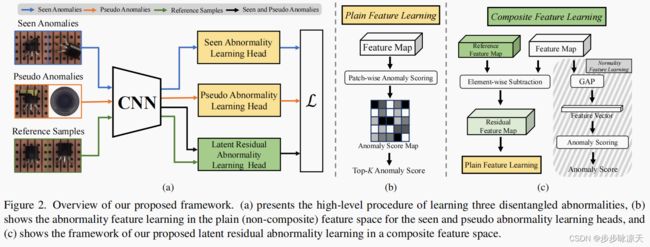
Catching Both Gray and Black Swans: Open-set Supervised Anomaly Detection
CVPR 2022 The University of Adelaide Chunhua Shen
Despite most existing anomaly detection studies assume the availability of normal training samples only, a few labeled anomaly examples are often available in many real-world applications, such as defect samples identified during random quality inspection, lesion images confirmed by radiologists in daily medical screening, etc. These anomaly examples provide valuable knowledge about the application specific abnormality, enabling significantly improved detection of similar anomalies in some recent models. However, those anomalies seen during training often do not illustrate every possible class of anomaly, rendering these models ineffective in generalizing to unseen anomaly classes. This paper tackles open-set supervised anomaly detection, in which we learn detection models using the anomaly examples with the objective to detect both seen anomalies (‘gray swans’) and unseen anomalies (‘black swans’). We propose a novel approach that learns disentangled representations of abnormalities illustrated by seen anomalies, pseudo anomalies, and latent residual anomalies (i.e., samples that have unusual residuals compared to the normal data in a latent space), with the last two abnormalities designed to detect unseen anomalies. Extensive experiments on nine real-world anomaly detection datasets show superior performance of our model in detecting seen and unseen anomalies under diverse settings.
DevNet: Explainable Deep Few-shot Anomaly Detection with Deviation Networks
2021 Chunhua Shen
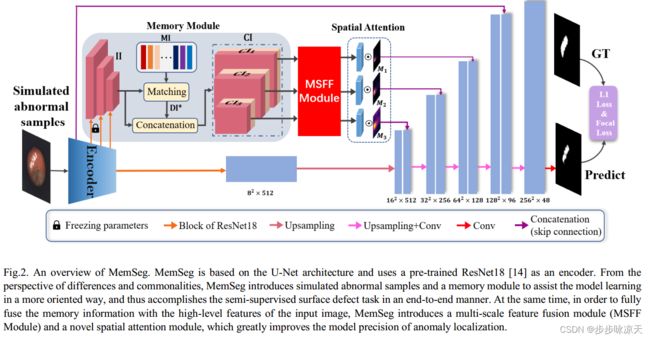
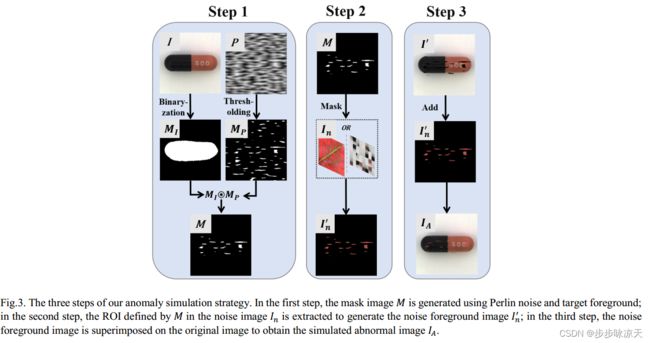
MemSeg: A semi-supervised method for image surface defect detection using differences and commonalities
2022.05
Xidian University
Under the semi-supervised framework, we propose an end-to-end memory-based segmentation network (MemSeg) to detect surface defects on industrial products. Considering the small intra-class variance of products in the same production line, from the perspective of differences and commonalities, MemSeg introduces artificially simulated abnormal samples and memory samples to assist the learning of the network. In the training phase, MemSeg explicitly learns the potential differences between normal and simulated abnormal images to obtain a robust classification hyperplane. At the same time, inspired by the mechanism of human memory, MemSeg uses a memory pool to store the general patterns of normal samples. By comparing the similarities and differences between input samples and memory samples in the memory pool to give effective guesses about abnormal regions; In the inference phase, MemSeg directly determines the abnormal regions of the input image in an end-to-end manner. Through experimental validation, MemSeg achieves the state-of-the-art (SOTA) performance on MVTec AD datasets with AUC scores of 99.56% and 98.84% at the image-level and pixel-level, respectively. In addition, MemSeg also has a significant advantage in inference speed benefiting from the end-to-end and straightforward network structure, which better meets the real-time requirement in industrial scenarios.
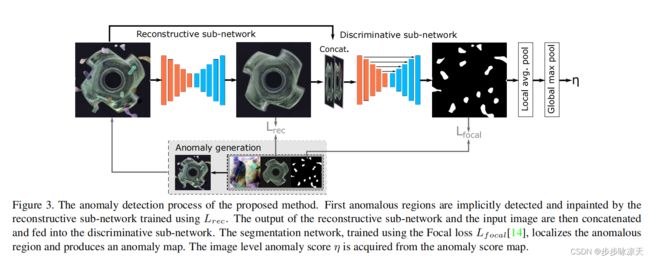
DRÆM – A discriminatively trained reconstruction embedding for surface anomaly detection
ICCV 2021
https://arxiv.org/abs/2108.07610v2
Visual surface anomaly detection aims to detect local image regions that significantly deviate from normal appearance. Recent surface anomaly detection methods rely on generative models to accurately reconstruct the normal areas and to fail on anomalies. These methods are trained only on anomaly-free images, and often require hand-crafted post-processing steps to localize the anomalies, which prohibits optimizing the feature extraction for maximal detection capability. In addition to reconstructive approach, we cast surface anomaly detection primarily as a discriminative problem and propose a discriminatively trained reconstruction anomaly embedding model (DRAEM). The proposed method learns a joint representation of an anomalous image and its anomaly-free reconstruction, while simultaneously learning a decision boundary between normal and anomalous examples. The method enables direct anomaly localization without the need for additional complicated post-processing of the network output and can be trained using simple and general anomaly simulations. On the challenging MVTec anomaly detection dataset, DRAEM outperforms the current state-of-the-art unsupervised methods by a large margin and even delivers detection performance close to the fully-supervised methods on the widely used DAGM surface-defect detection dataset, while substantially outperforming them in localization accuracy.
Registration based Few-Shot Anomaly Detection
ECCV 2022
Shanghai Jiao Tong University, King’s College London, Shanghai Artificial Intelligence Laboratory, National University of Singapore
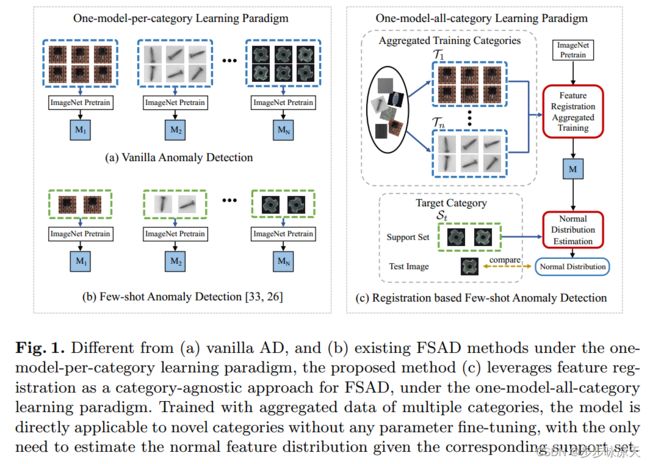
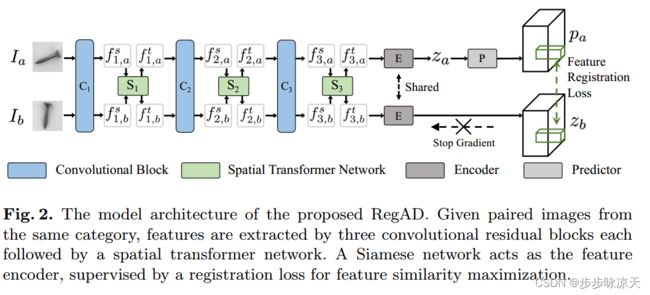
这篇论文通过在多个类别数据上训练一个类别无关的特征配准模型,实现小样本缺陷检测,即测试时提供少量新类别的正常样本,假设这些正常样本的配准特征的patch服从正态,通过统计均值和协方差,然后计算测试样本的马氏距离就可以实现缺陷检测和定位。
1.Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection
WACV 2022 2022-03-08
Leibniz University Hannover, University of British Columbia
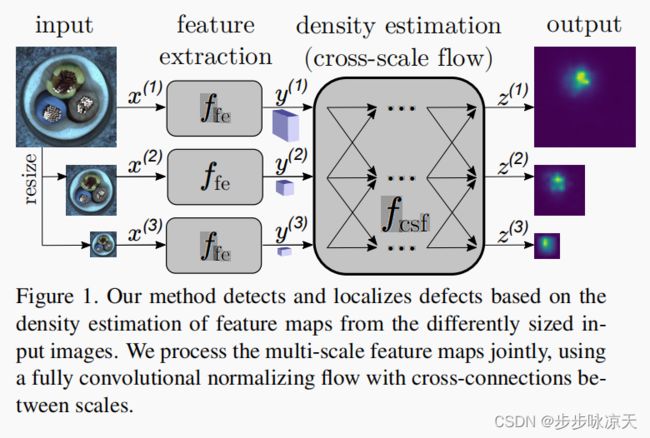
这篇论文利用Normalizing Flow在多尺度特征上实现图片级的缺陷检测。首先在预训练的 EfficientNet-B5上提取不同尺度的特征,然后用改进的Normalizing Flow(CS-Flow)并行处理不同尺度的特征,使其映射到一个多元标准正态分布。
在测试阶段根据CS-Flow输出特征的概率是否大于阈值对图片进行分类,根据CS-Flow输出特征的每个位置的L2范数进行缺陷定位。CS-Flow在Magnetic Tile Defects数据集上AUROC=99.3,在MVtec AD数据集上AUROC=98.7。
CS-Flow的耦合模块是在Real-NVP基础上做的改进,每个模块通过两个卷积子网络实现多尺度特征之间的交互。
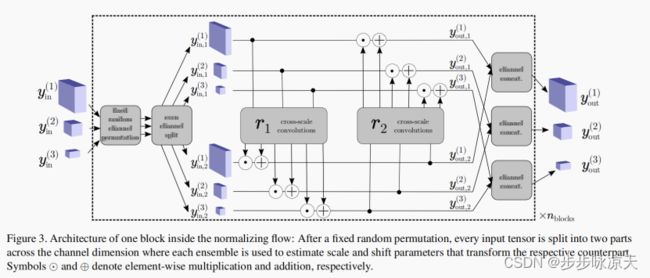
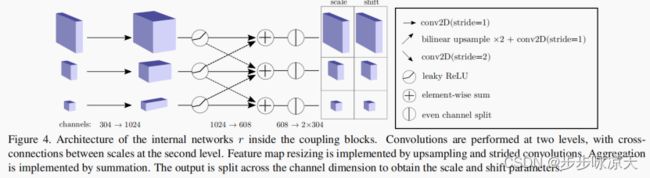
优点:融合了多尺度特征,用较少的训练数据可以得到较好的结果,MVtec AD 使用16个训练样本,得到AUROC=93.5。全卷积保持了空间结构,使输出具有解释性。
缺点:由于特征图较小(24*24),无法实现像素级分割。
Anomaly Detection via Reverse Distillation from One-Class Embedding
CVPR 2022 2022-06
Department of Electrical and Computer Engineering, University of Alberta
这篇论文从知识蒸馏的角度解决缺陷检测和定位问题。知识蒸馏实现缺陷检测是利用提出teacher网络和student网络在ng样本上提取到特征的差异识别缺陷,文中指出teacher和student网络结构和数据流动的相似会使得二者提取到的特征差异变小,导致缺陷检测失败。此文提出反向蒸馏框架,通过设计teacher和student不同的网络结构和数据,提高teacher和student提取缺陷特征的差异。
包括三个模块:预训练的teacher encoder E,可训练的one class embedding模块和student decoder D。
训练过程:首先由在ImageNet预训练的E提取ok样本的多尺度特征并进行特征融合,然后将高维特征投影成低维的embedding,通过D把embedding恢复成E提取的特征,E和D相应特征的余弦距离作为loss。


测试过程:上采样Mk,求和,做高斯滤波,得到anomaly map(AUC=97.8)。anomaly map最大值作为图片的得分(AUC=98.5)。
AltUB: Alternating Training Method to Update Base Distribution of Normalizing Flow for Anomaly Detection
2022-10
KAIST(韩国科学技术院)
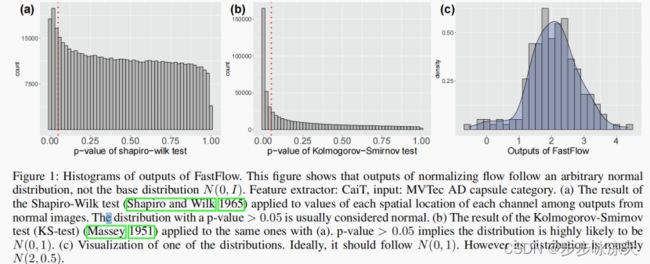
这篇论文指出Normalizing flow正常样本的输出服从正态分布,不是标准正态分布,但推断时计算得分用的还是标准正态分布的参数,因此基于normalizing flow的缺陷检测算法表达能力不够强,训练不是很稳定。本文提出2点改进:
1.可学习的正态分布。
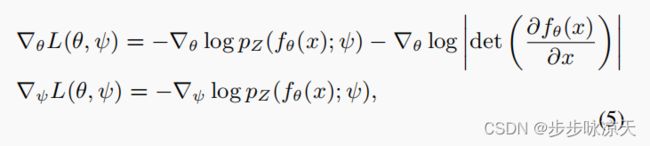
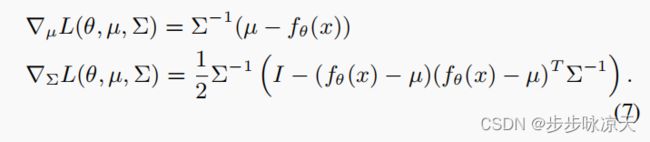
得分计算

2.交替训练方法。
正态分布的均值和方差的梯度很小,设置太大的学习率又不利于normalizing flow的训练。因此先整体训练normalizing flow,在冻住flow参数,用随机梯度下降和另外的学习率训练均值和方差。
实验结果:
在CFLOW-AD上加:检测AUC=98.4,分割AUC=98.7
在FastFlow上加:分割AUC=98.8
CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
WACV 2022
A Unified Model for Multi-class Anomaly Detection
NeurlPS 2022
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an “identical shortcut”, where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%).
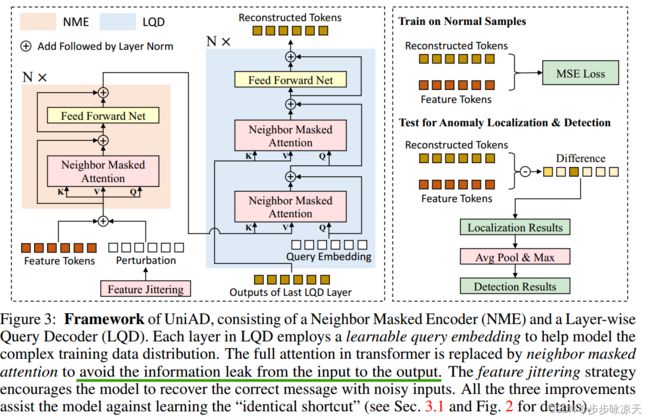
这篇论文指出基于图片(或特征)重建的缺陷检测方法,存在“identity shortcut”的现象,即直接把输入作为输出. 如果多个类别的数据一起训练,由于数据复杂度增加, 这个现象会加剧.
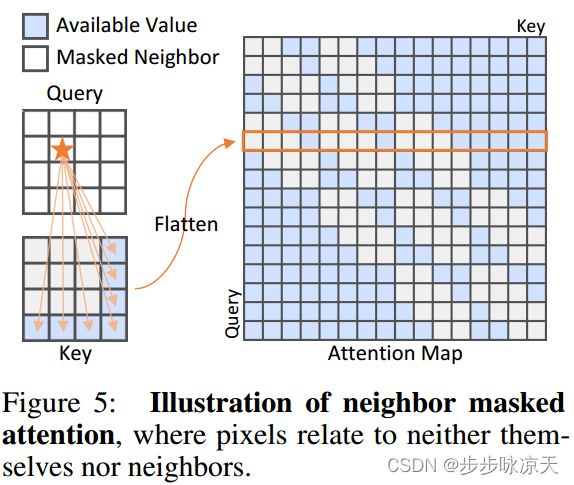
文中分析了MLP, CNN, Transformer分别作为重建网络会造成“identity shortcut”的原因, 提出基于transformer的多类别缺陷检测框架UniAD, 主要实现了三项改进: (1) Layerwise Query Decoder (LQD): 每层decoder加query embedding; (2) Neighbor Masked Attention (NMA): 不和自身和周围token计算attention; (3) Feature Jittering (FJ) strategy : 对输入特征添加高斯噪声.
Explainable Deep One-Class Classification
ICLR 2021 德国凯泽斯劳滕大学
Deep one-class classification variants for anomaly detection learn a mapping that concentrates nominal samples in feature space causing anomalies to be mapped away. Because this transformation is highly non-linear, finding interpretations poses a significant challenge. In this paper we present an explainable deep one-class classification method, Fully Convolutional Data Description (FCDD), where the mapped samples are themselves also an explanation heatmap. FCDD yields competitive detection performance and provides reasonable explanations on common anomaly detection benchmarks with CIFAR-10 and ImageNet. On MVTec-AD, a recent manufacturing dataset offering ground-truth anomaly maps, FCDD sets a new state of the art in the unsupervised setting. Our method can incorporate ground-truth anomaly maps during training and using even a few of these (~5) improves performance significantly. Finally, using FCDD’s explanations we demonstrate the vulnerability of deep one-class classification models to spurious image features such as image watermarks.
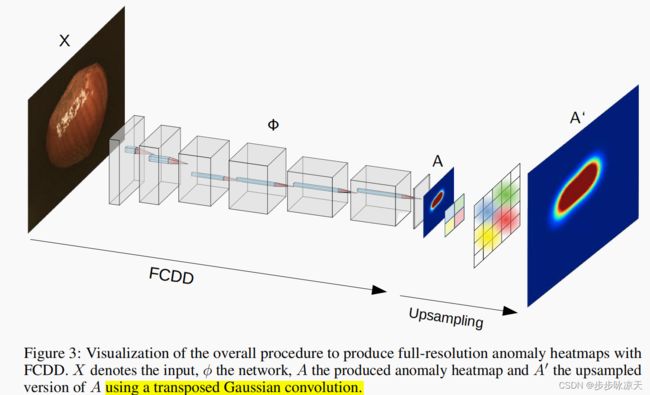
Explanations are needed in industrial applications to meet safety and security requirements (Berkenkamp et al., 2017; Katz et al., 2017; Samek et al., 2020), avoid unfair social biases (Gupta et al., 2018), and support human experts in decision making (Jarrahi, 2018; Montavon et al., 2018; Samek et al., 2020).
KDAD: Multiresolution Knowledge Distillation for Anomaly Detection
M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban and H. R. Rabiee, “Multiresolution Knowledge Distillation for Anomaly Detection,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14897-14907, doi: 10.1109/CVPR46437.2021.01466.
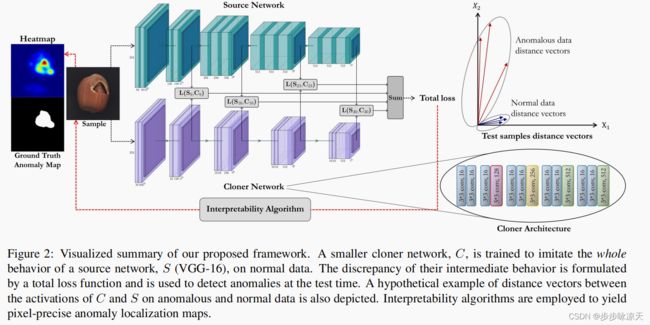
Abstract
Unsupervised representation learning has proved to be a critical component of anomaly detection/localization in images. The challenges to learn such a representation are two-fold. Firstly, the sample size is not often large enough to learn a rich generalizable representation through conventional techniques. Secondly, while only normal samples are available at training, the learned features should be discriminative of normal and anomalous samples. Here, we propose to use the “distillation” of features at various layers of an expert network, which is pre-trained on ImageNet, into a simpler cloner network to tackle both issues. We detect and localize anomalies using the discrepancy between the expert and cloner networks’ intermediate activation values given an input sample. We show that considering multiple intermediate hints in distillation leads to better exploitation of the expert’s knowledge and a more distinctive discrepancy between the two networks, compared to utilizing only the last layer activation values. Notably, previous methods either fail in precise anomaly localization or need expensive region-based training. In contrast, with no need for any special or intensive training procedure, we incorporate interpretability algorithms in our novel framework to localize anomalous regions. Despite the striking difference between some test datasets and ImageNet, we achieve competitive or significantly superior results compared to SOTA on MNIST, F-MNIST, CIFAR-10, MVTecAD, Retinal-OCT, and two other medical datasets on both anomaly detection and localization.
Note
As CIFAR-10 images are natural images, they have been resized and normalized according to the ImageNet properties.
No normalization and resizing are done for other datasets. ?
Neural Batch Sampling with Reinforcement Learning for Semi-Supervised Anomaly Detection
Chu, Wen-Hsuan & Kitani, Kris. (2020). Neural Batch Sampling with Reinforcement Learning for Semi-supervised Anomaly Detection. 10.1007/978-3-030-58574-7_45.
We are interested in the detection and segmentation of anomalies in images where the anomalies are typically small (i.e., a small tear in woven fabric, broken pin of an IC chip). From a statistical learning point of view, anomalies have low occurrence probability and are not from the main modes of a data distribution. Learning a generative model of anomalous data from a natural distribution of data can be difficult because the data distribution is heavily skewed towards a large amount of non-anomalous data. When training a generative model on such imbalanced data using an iterative learning algorithm like stochastic gradient descent (SGD), we observe an expected yet interesting trend in the loss values (a measure of the learned models performance) after each gradient update across data samples. Naturally, as the model sees more non-anomalous data during training, the loss values over a non-anomalous data sample decreases, while the loss values on an anomalous data sample fluctuates. In this work, our key hypothesis is that this change in loss values during training can be used as a feature to identify anomalous data. In particular, we propose a novel semi-supervised learning algorithm for anomaly detection and segmentation using an anomaly classifier that uses as input the loss profile of a data sample processed through an autoencoder. The loss profile is defined as a sequence of reconstruction loss values produced during iterative training. To amplify the difference in loss profiles between anomalous and non-anomalous data, we also introduce a Reinforcement Learning based meta-algorithm, which we call the neural batch sampler, to strategically sample training batches during autoencoder training. Experimental results on multiple datasets with a high diversity of textures and objects, often with multiple modes of defects within them, demonstrate the capabilities and effectiveness of our method when compared with existing state-of-the-art baselines.
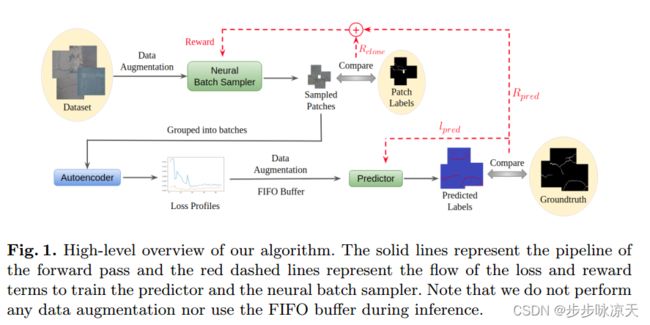
Attribute restoration framework for anomaly detection
F. Ye, C. Huang, J. Cao, M. Li, Y. Zhang and C. Lu, “Attribute Restoration Framework for Anomaly Detection,” in IEEE Transactions on Multimedia, vol. 24, pp. 116-127, 2022, doi: 10.1109/TMM.2020.3046884.
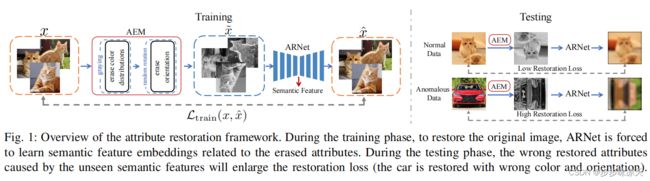
abstract
With the recent advances in deep neural networks, anomaly detection in multimedia has received much attention in the computer vision community. While reconstruction-based methods have recently shown great promise for anomaly detection, the information equivalence among input and supervision for reconstruction tasks can not effectively force the network to learn semantic feature embeddings. We here propose to break this equivalence by erasing selected attributes from the original data and reformulate it as a restoration task, where the normal and the anomalous data are expected to be distinguishable based on restoration errors. Through forcing the network to restore the original image, the semantic feature embeddings related to the erased attributes are learned by the network. During testing phases, because anomalous data are restored with the attribute learned from the normal data, the restoration error is expected to be large. Extensive experiments have demonstrated that the proposed method significantly outperforms several state-of-the-arts on multiple benchmark datasets, especially on ImageNet, increasing the AUROC of the top-performing baseline by 10.1%. We also evaluate our method on a real-world anomaly detection dataset MVTec AD and a video anomaly detection dataset ShanghaiTech
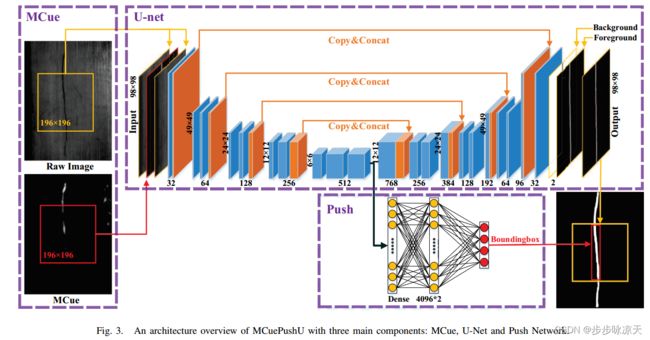
Surface Defect Saliency of Magnetic Tile
[1] Huang Y , Qiu C , Guo Y , et al. Surface Defect Saliency of Magnetic Tile[C]// 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE). IEEE, 2018.
Vision-based detection on surface defects has long postulated in the magnetic tile automation process. In this work, we introduce a real-time and multi-module neural network model called MCuePush U-Net, specifically designed for the image saliency detection of magnetic tile. We show that the model exceeds the state-of-the-art, in which it both effectively and explicitly maps multiple surface defects from low-contrast images. Our model significantly reduces time cost of machinery from 0.5s per image to 0.07s, and enhances saliency accuracy on surface defect detection.
Deep SVDD
[1] Ruff L , Vandermeulen R A , N Görnitz, et al. Deep One-Class Classification[C]// International Conference on Machine Learning. 2018.
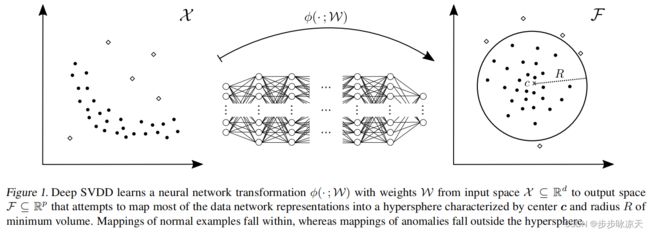
Despite the great advances made by deep learning in many machine learning problems, there is a relative dearth of deep learning approaches for anomaly detection. Those approaches which do exist involve networks trained to perform a task other than anomaly detection, namely generative models or compression, which are in turn adapted for use in anomaly detection; they are not trained on an anomaly detection based objective. In this paper we introduce a new anomaly detection method—Deep Support Vector Data Description—, which is trained on an anomaly detection based objective. The adaptation to the deep regime necessitates that our neural network and training procedure satisfy certain properties, which we demonstrate theoretically. We show the effectiveness of our method on MNIST and CIFAR-10 image benchmark datasets as well as on the detection of adversarial examples of GTSRB stop signs.
Note
AVID: Adversarial Visual Irregularity Detection
[1] Sabokrou M , Pourreza M , Fayyaz M , et al. AVID: Adversarial Visual Irregularity Detection[C]// Asian Conference on Computer Vision. Springer, Cham, 2018.
Real-time detection of irregularities in visual data is very invaluable and useful in many prospective applications including surveillance, patient monitoring systems, etc. With the surge of deep learning methods in the recent years, researchers have tried a wide spectrum of methods for different applications. However, for the case of irregularity or anomaly detection in videos, training an end-to-end model is still an open challenge, since often irregularity is not well-defined and there are not enough irregular samples to use during training. In this paper, inspired by the success of generative adversarial networks (GANs) for training deep models in unsupervised or self-supervised settings, we propose an end-to-end deep network for detection and fine localization of irregularities in videos (and images). Our proposed architecture is composed of two networks, which are trained in competing with each other while collaborating to find the irregularity. One network works as a pixel-level irregularity Inpainter, and the other works as a patch-level Detector. After an adversarial self-supervised training, in which I tries to fool D into accepting its inpainted output as regular (normal), the two networks collaborate to detect and fine-segment the irregularity in any given testing video. Our results on three different datasets show that our method can outperform the state-of-the-art and fine-segment the irregularity.


