论文阅读:SegFormer: Simple and Efficient Design for SemanticSegmentation with Transformers
来源:nips2021
GitHub - NVlabs/SegFormer: Official PyTorch implementation of SegFormer
0、Abstract
摘要本文提出了一种简单、高效、强大的语义分割框架SegFormer,它将transformer与轻量级多层感知器(MLP)解码器结合在一起。SegFormer有两个吸引人的特点:1)SegFormer包含了一个新的分层结构的变压器编码器,可以输出多尺度特征。该算法不需要位置编码,避免了在测试分辨率与训练分辨率不同时对位置码进行插值导致性能下降的问题。2) SegFormer避免了复杂的解码器。提出的MLP解码器聚集了来自不同层的信息,从而结合了局部关注和全局关注来呈现强大的表示。我们表明,这种简单和轻量级的设计是有效分割变压器的关键。我们将我们的方法进行了扩展,获得了从SegFormer-B0到SegFormer-B5的一系列模型,与之前的同行相比,获得了更好的性能和效率。例如,SegFormer-B4在64M参数的ADE20K上实现了50.3%的mIoU,比之前的最佳方法小5倍,好2.2%。我们的最佳模型segfer - b5在cityscape验证集上获得了84.0%的mIoU,并在cityscape - c上显示了出色的零拍鲁棒性。代码将在github.com/NVlabs/SegFormer发布。
1 Introduction
语义切分是计算机视觉中的一项基本任务,可以实现许多下游应用。它与图像分类有关,因为它产生逐像素的类别预测,而不是图像级预测。在一项开创性的工作[1]中,作者指出并系统地研究了这种关系,其中作者使用全卷积网络(fns)进行语义分割任务。此后,FCN激发了许多后续作品,成为密集预测的主要设计选择。
由于分类和语义分割之间存在着密切的关系,许多最先进的语义分割框架都是ImageNet上流行的图像分类体系结构的变体。因此,设计骨干架构仍然是语义分割的一个活跃领域。的确,从早期使用VGGs的方法[1,2],到最新的骨干网[3]的深度和功能显著增强的方法,骨干网的进化极大地推动了语义分割的性能边界。除了主干架构之外,另一项工作是将语义分割作为结构化预测问题来制定,并专注于设计模块和操作符,以有效地捕获上下文信息。这个领域的一个典型例子是扩张卷积[4,5],它通过用孔洞“膨胀”核来增加接收域。
目睹了自然语言处理(NLP)的巨大成功,最近人们对将变形金刚引入视觉任务产生了浓厚的兴趣。Dosovitskiy等人[6]提出了用于图像分类的vision Transformer (ViT)。按照NLP中的Transformer设计,作者将图像分割为多个线性嵌入的补丁,并将它们输入具有位置嵌入(PE)的标准Transformer中,从而在ImageNet上获得了令人印象深刻的性能。在语义分割方面,Zheng等人[7]提出SETR来证明在这个任务中使用transformer的可行性。
SETR采用ViT作为主干,并加入几个CNN解码器来扩大特征分辨率。尽管ViT性能良好,但也存在一些局限性:1)ViT输出的是单尺度的低分辨率特征,而不是多尺度的低分辨率特征。2)对于较大的图像,计算成本较高。为了解决这些局限性,Wang et al.[8]提出了一种金字塔视觉转换器(PVT),它是ViT的一种自然扩展,具有金字塔结构,用于密集预测。PVT在对象检测和语义分割上比ResNet对等物有相当大的改进。但是,与Swin Transformer[9]和Twins[10]等其他新兴方法相比,这些方法主要考虑的是Transformer编码器的设计,而忽略了解码器对进一步改进的贡献。
本文介绍了SegFormer,一种前沿的Transformer语义分割框架,它综合考虑了效率、准确性和鲁棒性。与以前的方法相比,我们的框架重新设计了编码器和解码器。我们的方法的主要创新点是:
•一种新型的无位置编码和分级变压器编码器。
•轻量级全mlp解码器设计,无需复杂和计算要求模块,即可实现强大的表示。
•如图1所示,SegFormer在三个公开可用的语义分割数据集上,在效率、准确性和鲁棒性方面设置了最新的技术水平。

首先,该编码器在对不同分辨率的图像进行推理时避免了插入位置码。因此,我们的编码器可以很容易地适应任意测试分辨率,而不会影响性能。此外,分层部分使编码器可以生成高分辨率的精细特征和低分辨率的粗特征,而ViT只能生成固定分辨率的单个低分辨率特征图。其次,我们提出了一种轻量级的MLP解码器,其关键思想是利用变压器感应的特性,即较低层的注意倾向于停留在局部,而最高层的注意则高度非局部。通过聚合来自不同层的信息,MLP解码器结合了局部和全局关注。因此,我们得到了一个简单而直接的解码器,它可以呈现强大的表示。
我们在三个公开的数据集上展示了SegFormer在模型大小、运行时间和准确性方面的优势:ADE20K、cityscape和COCO-Stuff。在Citysapces上,我们的轻量级模型segfer - b0,在没有TensorRT等加速实现的情况下,在48帧FPS下产生71.9%的mIoU,与ICNet[11]相比,延迟和性能分别提高了60%和4.2%。我们最大的模型segfer - b5的收益率为84.0% mIoU,这代表了相对1.8%的mIoU改进,同时比SETR[7]快5倍。在ADE20K上,该模型达到了51.8% mIoU的最新技术水平,比SETR小4倍。此外,与现有方法相比,我们的方法对常见的错误和扰动具有更强的鲁棒性,因此适用于安全关键的应用程序。代码将公开提供。
2 Related Work
Semantic Segmentation
语义分割可以看作是图像分类从图像级到像素级的扩展。在深度学习时代[12-16],FCN[1]是语义分割的基础工作,它是一个端到端进行像素到像素分类的全卷积网络。之后,研究人员从不同方面对FCN进行了改进,如:扩大感受野[17 - 19,5,2,4,20];提炼语境信息[21 - 29];引入边界信息[30-37];设计各种注意模块[38-46];或使用AutoML技术[47-51]。这些方法显著地提高了语义分词的性能,但却引入了大量的经验模块,使得生成的框架计算量大且复杂。最近的一些方法已经证明了基于transformer的体系结构对于语义分割的有效性[7,46]。然而,这些方法仍然需要大量的计算。
Transformer backbones
ViT[6]是第一个证明纯Transformer在图像分类方面可以达到最先进的性能的作品。ViT将每个图像视为标记序列,然后将它们提供给多个Transformer层进行分类。随后,DeiT[52]进一步探索了数据高效的ViT培训策略和精馏方法。最近的方法如T2T ViT[53]、CPVT[54]、TNT[55]、CrossViT[56]和LocalViT[57]对ViT进行了定制化的修改,进一步提高了图像分类性能。
除了分类之外,PVT[8]是在Transformer中引入金字塔结构的第一个作品,它展示了与CNN相比,纯Transformer主干网在密集预测任务中的潜力。之后,Swin[9]、CvT[58]、CoaT[59]、LeViT[60]、Twins[10]等方法增强了特征的局部连续性,去除固定尺寸的位置嵌入,提高了transformer在密集预测任务中的性能。
Transformers for specific tasks
DETR[52]是第一个使用transformer构建端到端对象检测框架而没有非最大抑制(NMS)的工作。其他作品也将transformer用于各种任务,如跟踪[61,62]、超分辨率[63]、ReID[64]、着色[65]、检索[66]和多模态学习[67,68]。在语义分割方面,SETR[7]采用了ViT[6]作为主干提取特征,取得了良好的性能。然而,这些基于变压器的方法效率非常低,因此很难部署在实时应用程序中。
3 Method
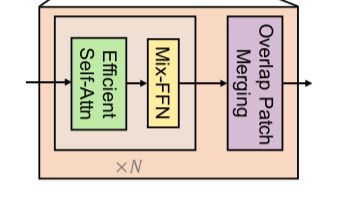
本节介绍SegFormer,我们的高效、健壮和强大的分割框架,无需手工制作和计算要求的模块。如图2所示,SegFormer包含两个主要模块:(1)一个分层的Transformer编码器,生成高分辨率的粗特征和低分辨率的细特征 (2)一个轻量级的All-MLP解码器,融合这些多级特征,生成最终的语义分割掩码。

提出的SegFormer框架由两个主要模块组成:一个分层的Transformer编码器,用于提取粗、细特征;以及一个轻量级的All-MLP解码器,直接融合这些多级特征并预测语义分割掩码。“FFN”表示前馈网络。
给定一张大小为H ×W× 3的图像,我们首先将其划分为大小为4 × 4的patches。与ViT使用大小为16 × 16的patch不同,使用较小的patch有利于密集的预测任务。然后将这些patch作为输入到分层的Transformer编码器中,获得原始图像分辨率为{1/4,1/8,1/ 16,1 /32}的多级特征。然后,我们将这些多级特征传递给All-MLP解码器,以预测在H/4 × W/4 ×Ncls分辨率下的分割掩码,其中Ncls是类别的数量。在本节的其余部分中,我们将详细介绍提出的编码器和解码器设计,并总结我们的方法和SETR之间的主要区别。
3.1 Hierarchical Transformer Encoder
我们设计了一系列混合变压器编码器(MiT), MiT- b0到MiT- b5,具有相同的结构但不同的尺寸。MiT-B0是我们用于快速推理的轻量级模型,而MiT-B5是用于最佳性能的最大模型。我们为MiT设计的部分灵感来自于ViT,但为语义分割量身定制和优化。
Hierarchical Feature Representation
与只能生成单分辨率特征图的ViT不同,该模块的目标是,给定一个输入图像,生成类似cnn的多级特征。这些特征提供了高分辨率的粗特征和低分辨率的细粒度特征,通常可以提高语义分割的性能。更准确地说,给定一个分辨率为H×W× 3的输入图像,我们通过patch merge得到一个分辨率为![]() 的分层特征映射Fi,其中i∈{1,2,3,4},且Ci+1大于Ci。
的分层特征映射Fi,其中i∈{1,2,3,4},且Ci+1大于Ci。
Overlapped Patch Merging
给定一个图像patch, ViT中使用的patch合并过程将一个N × N × 3 patch统一为一个1 × 1 × C向量。这可以很容易地扩展到将一个2 × 2 ×Ci的特征路径统一为一个1 × 1 ×Ci+1向量来获得分层特征映射。使用这种方法,我们可以将层次特征从![]() 缩小到
缩小到![]() ,然后迭代层次结构中的任何其他特征地图。这个过程最初被设计用来组合不重叠的图像或特征块。因此,它不能保持这些patch周围的局部连续性。相反,我们使用重叠的补丁合并过程。为此,我们定义K、S和P,其中K为patch大小,S为相邻两个patch之间的跨度,P为padding大小。在我们的实验中,我们设置K = 7, S = 4, P = 3, K = 3, S = 2, P = 1进行重叠patch合并,得到与不重叠过程相同大小的特征。
,然后迭代层次结构中的任何其他特征地图。这个过程最初被设计用来组合不重叠的图像或特征块。因此,它不能保持这些patch周围的局部连续性。相反,我们使用重叠的补丁合并过程。为此,我们定义K、S和P,其中K为patch大小,S为相邻两个patch之间的跨度,P为padding大小。在我们的实验中,我们设置K = 7, S = 4, P = 3, K = 3, S = 2, P = 1进行重叠patch合并,得到与不重叠过程相同大小的特征。
Efficient Self-Attention.
编码器的主要计算瓶颈是自注意层。在原多头自我注意过程中,每个头Q、K、V具有相同的维数N ×C,其中N = H ×W为序列长度,估计自我注意为:

这一过程的计算复杂度为O(N2),这对于大分辨率的图像来说是不允许的。相反,我们使用[8]中引入的序列约简过程。该过程使用比例R对序列的长度进行约简,如下所示:

其中K为原始序列(N ×C),把K重塑为![]() 形状的序列,线性(Cin, Cout)(·)表示以一个Cin维张量为输入,生成一个Cout维张量为输出的线性层。因此,新K的维数为
形状的序列,线性(Cin, Cout)(·)表示以一个Cin维张量为输入,生成一个Cout维张量为输出的线性层。因此,新K的维数为![]() ,自注意机制的复杂性由O(N2)降低到O(N2/R)。在实验中,从阶段1到阶段4,我们设置R为[64,16,4,1]。
,自注意机制的复杂性由O(N2)降低到O(N2/R)。在实验中,从阶段1到阶段4,我们设置R为[64,16,4,1]。
(这是强行压缩?相当于用一个线性层把维度缩小R倍率,物理意义怎么解释呢)
Mix-FFN
ViT使用位置编码(PE)来引入位置信息。但是PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,需要对位置码进行插值,这往往会导致精度下降。为了解决这个问题,CPVT[54]与PE一起使用3 × 3 Conv来实现数据驱动PE。我们认为位置编码实际上对于语义分割是不必要的。相反,我们引入Mix-FFN,它考虑了零填充对泄漏位置信息的影响[69],直接在前馈网络(FFN)中使用3 × 3 Conv。Mix-FFN可以表示为:
![]()
3.2 Lightweight All-MLP Decoder
SegFormer集成了一个只包含MLP层的轻量级解码器,这就避免了通常在其他方法中使用的手工制作和计算要求高的组件。实现这种简单解码器的关键在于,我们的分层Transformer编码器比传统CNN编码器具有更大的有效接收域(ERF)。
提出的全mlp解码器包括四个主要步骤。首先,从MiT编码器得到的多级特征Fi通过一个MLP层来统一信道尺寸。然后,在第二步中,特征上采样到1/4,并连接在一起。第三,采用MLP层融合拼接的特征f。最后,另一MLP层利用融合的特征预测分割掩码M,其分辨率为![]() ,其中Ncls为类别数。这让我们可以将解码器表述为:
,其中Ncls为类别数。这让我们可以将解码器表述为:

式中,M为预测掩模,Linear(Cin, Cout)(·)为分别以Cin和Cout为输入向量维数和输出向量维数的线性层。
Effective Receptive Field Analysis.
对于语义分割,保持较大的接受域以包含上下文信息一直是一个中心问题[5,19,20]。在这里,我们使用有效接受域(ERF)[70]作为一个工具包来形化和解释为什么我们的MLP译码器设计在变压器上如此有效。在图3中,我们可视化了DeepLabv3+和SegFormer的四个编码器阶段的erf和解码器头。我们可以得出以下结论:

•DeepLabv3+的ERF相对较小,即使是在阶段4,即最深阶段。
•SegFormer的编码器自然会产生类似于较低阶段的卷积的局部注意,而能够输出高度非局部注意,从而有效捕获阶段4的上下文。
•如图3中放大补丁所示,MLP头部(蓝框)的ERF与Stage-4(红框)不同,除了非局部注意外,局部注意显著增强。
CNN的接收域有限,需要借助ASPP[18]等上下文模块来扩大接收域,但不可避免地会变得沉重。我们的解码器设计受益于变压器的非局部关注,并导致更大的接收域而不复杂。然而,同样的解码器设计在CNN主干网上并不能很好地工作,因为在Stage-4的整体接受域的上限是有限的,我们将在稍后的表1d中验证这一点,
更重要的是,我们的解码器设计本质上利用了Transformer诱导的特性,该特性同时产生高度局部和非局部关注。通过统一它们,我们的MLP解码器通过添加少量参数来呈现互补和强大的表示。这是推动我们设计的另一个关键原因。单从阶段4获得非本地关注不足以产生良好的结果,如表1d所示。
3.3 Relationship to SETR
与SETR[7]相比,SegFormer包含多个更高效、更强大的设计:
•我们只使用ImageNet-1K进行预训练。在SETR中的ViT是在更大的ImageNet-22K上预先训练的。•SegFormer的编码器具有层次结构,比ViT更小,可以捕获高分辨率粗和低分辨率精细特性。相比之下,SETR的ViT编码器只能生成单一的低分辨率特征图。
•我们去除编码器中的位置嵌入,而SETR使用固定形状的位置嵌入,当推理分辨率与训练分辨率不一致时,会降低精度。
•我们的MLP解码器比SETR更紧凑,计算要求更少。这导致可以忽略不计的计算开销。相反,SETR需要大量的解码器和多个3×3卷积。
4 Experiments
4.1 Experimental Settings
数据集:我们使用了三个公开可用的数据集:cityscape [71], ADE20K[72]和COCOStuff[73]。ADE20K是一个包含150个细粒度语义概念的场景解析数据集,包含20210张图像。城市景观是由5000幅高分辨率图像组成的19个类别的语义分割驱动数据集。COCO-Stuff涵盖172个标签,包含164k图像:118k用于培训,5k用于验证,20k用于测试开发,20k用于测试挑战。
实现细节:我们使用了mmsegmentation1代码库,并在8特斯拉V100服务器上进行培训。我们在Imagenet-1K数据集上预训练编码器,并随机初始化解码器。在训练过程中,我们分别对ADE20K、cityscape和COCO-Stuff进行了以0.5-2.0比例随机调整大小、随机水平翻转、随机裁剪至512 × 512、1024×1024、512 × 512的数据增强。在[9]之后,我们为我们最大的模型B5在ADE20K上设置作物尺寸为640 × 640。我们使用AdamW优化器对模型进行训练,在ADE20K、cityscape上进行160K次迭代,在COCO-Stuff上进行80K次迭代。在消融研究中,我们对模型进行了40K迭代训练。我们对ADE20K和COCO-Stuff使用16个批量,对城市景观使用8个批量。学习速率被设置为初始值0.00006,然后使用默认系数为1.0的“poly”LR调度。为了简单起见,我们没有采用广泛使用的技巧,如OHEM、辅助损失或类平衡损失。在评估过程中,我们对图像的短边进行缩放以训练裁剪尺寸,并保持ADE20K和COCO-Stuff的宽高比。对于城市景观,我们通过裁剪1024×1024窗口来使用滑动窗口测试进行推理。我们报告了使用平均相交于联合(mIoU)的语义分割性能。
4.2 Ablation Studies
模型大小的影响。我们首先分析了增加编码器尺寸对性能和模型效率的影响。图1显示了作为编码器大小的函数,ADE20K的性能和模型效率,表1a总结了三个数据集的结果。这里要观察的第一件事是与编码器相比的解码器的大小。如图所示,对于轻量级模型,解码器只有0.4M参数。对于MiT-B5编码器,解码器只占用模型中总参数数的4%。在性能方面,我们可以观察到,总的来说,增加编码器的大小会对所有数据集产生一致的改进。我们的轻量级模型SegFormer-B0在保持竞争性能的同时紧凑高效,这表明我们的方法对于实时应用非常方便。另一方面,我们的segfer - b5,最大的模型,在所有三个数据集上实现了最先进的结果,显示了我们的Transformer编码器的潜力。


对c、MLP解码器信道尺寸的影响。我们现在分析MLP解码器中信道尺寸C的影响,请参见第3.2节。在表1b中,我们将性能、失败次数和参数作为这个维度的函数。我们可以看到,设置C = 256提供了非常有竞争力的性能和计算成本。性能随着C的增加而增加;然而,它会导致模型更大、效率更低。有趣的是,当通道尺寸大于768时,这种性能趋于稳定。基于这些结果,我们选择C = 256作为实时模型SegFormer-B0, B1作为其他模型,C = 768。
混合ffn与位置编码器(PE)。在本实验中,我们分析了在Transformer编码器中去除位置编码的效果,以支持使用所提出的Mix-FFN。为此,我们用位置编码(PE)和建议的Mix-FFN训练Transformer编码器,并对两种不同的图像分辨率的城市景观进行推断:768×768使用滑动窗口,1024×2048使用整个图像。表1c显示了本次实验的结果。如上所示,对于给定的分辨率,我们使用Mix-FFN的方法明显优于使用位置编码的方法。此外,我们的方法对测试分辨率的差异不太敏感:当使用较低分辨率的位置编码时,准确率下降3.3%。相反,当我们使用建议的Mix-FFN时,性能下降仅为0.7%。从这些结果,我们可以得出结论,使用提出的Mix-FFN产生更好和更鲁棒的编码器比那些使用位置编码。
有效的接受域评估。在第3.2节中,我们论证了我们的MLP解码器受益于与其他CNN模型相比,transformer拥有更大的有效接收域。为了量化这种影响,在本实验中,我们比较了与基于cnn的编码器(如ResNet或ResNeXt)一起使用时,我们的mlp解码器的性能。如表1d所示,与使用Transformer编码器相比,将我们的mlp解码器与基于cnn的编码器耦合在一起的精度要低得多。直观地说,由于CNN的接收域比Transformer小(见第3.2节的分析),所以mlp解码器不足以进行全局推理。相比之下,将Transformer编码器与MLP解码器耦合可以获得最佳性能。此外,对于Transformer编码器,有必要将低级的本地特性和高级的非本地特性结合起来,而不仅仅是高级特性。
4.3 Comparison to state of the art methods
4.4 Robustness to natural corruptions
模型的鲁棒性对于许多安全关键任务非常重要,如自动驾驶[77]。在这个实验中,我们评估了SegFormer对常见的腐败和扰动的鲁棒性。为此,我们遵循[77]并生成cityscape - c,它将cityscape验证集扩展为16种算法生成的错误,这些错误来自噪音、模糊、天气和数字类别。我们将我们的方法与文献[77]中报道的DeeplabV3+和其他方法的变体进行了比较。实验结果如表5所示。
5 Conclusion
在本文中,我们提出了SegFormer,一种简单、干净但功能强大的语义分割方法,它包含了一个无位置编码的、分层的Transformer编码器和一个轻量级的AllMLP解码器。它避免了以往方法中常见的复杂设计,提高了效率和性能。SegFormer不仅在普通数据集上取得了最新的研究成果,而且表现出了很强的零拍鲁棒性。我们希望我们的方法可以作为一个坚实的基线,语义分割和激励进一步的研究。一个限制是,我们最小的3.7M参数模型虽然比已知的CNN模型要小,但在只有100k内存的边缘设备芯片上是否能很好地工作还不清楚。我们把它留给以后的工作。
自己总结:
1、开源了可以一试
2、分层的结构,应该可以无缝换到resnet,不过resnet第一层好像是2倍率,这个是4倍率
3、mixffn 和解码器都很简洁
4、多头注意力不知道怎么实现,如果不是1024*1024的分辨率是否会受影响