友好的可视化工具——trelliscope
众所周知,R的一个为人称道之处是它的可视化工具体系,以ggplot为代表的可视化语法自诞生之日起在数据科学领域流行至今。不过,ggplot主要专长于建立静态的可视化效果,可交互性略显不足。对于取值较多的类别变量,尽管使用ggplot中的分面语法facet_wrap或facet_grid也能呈现结果,但可以想象这样的结果会缺乏可读性,因为屏幕上会呈现大量分面图,让人眼花缭乱。实际上,本章开篇就描述了一个大型数据集可视化的典型场景,在探索性分析时需要使用大量的分面去呈现结果,这是当前ggplot语法未能很好解决的问题。对此,trelliscope应运而生。可视化是数据处理和探索的重要一环,在本章中,我们将简要介绍trelliscope的基本使用方法。
5.1 实现交互式大型分面可视化
trelliscope是一种基于“化整为零”思路和网格显示方法的可视化技术,数据被分割成多组,每组生成一个图,排列在网格中。这种方法非常简洁,被认为是展示大取值范围数据的优秀解决方案。trelliscope通过基于统计汇总的、具有交互性的筛选器,将数据展示变得非常生动。
trelliscope的可视化技术通过R的trelliscopejs库实现[1]。trelliscopejs库能创建网格展示并很好地整合传统的可视化、分析工作流,如可以使用ggplot2或者tidyverse的工作流创建网格可视化图像。trelliscopejs库的核心是一个名为trelliscopejs-lib的JavaScript库,提供了交互操作的界面。另外,该库由htmlwidget整合,可以很容易地将结果嵌入R Markdown、R Notebook等环境中,或者简单地将结果的html文件共享给其他人或发送到web上。
trelliscope交互式的可视化模式特别适合用于探索多个类别下不同变量的关系。为此,一个常用的函数是facet_trelliscope()。facet_trelliscope()与facet_wrap()类似,但会以一个更友好的交互界面呈现分析结果。
让我们看一个简单的例子。现在我们希望观察2018年中每天每时(0时~23时)green类别出租车的载客量变化情况。先载入本章需要的第三方库:
# 载入相关库
library(trelliscopejs)
library(ggplot2)
library(lubridate)
library(readr)
library(pryr)
library(dplyr)我们先通过dplyr的语法生成相关的变量date(日期)和hour(时点),对每天的每个时点的载客量进行汇总,然后,利用ggplot进行可视化,但不同的是,为了获取trelliscope的交互分面可视化结果,我们使用facet_trelliscope()代替ggplot原有的facet_wrap(),并以date作为分面的依据:
# 读取数据
path <- "D:/K/DATA EXERCISE/big data/TLC Trip Record Data"
green_file <- "green_2018.csv"
path_green_file <- file.path(path, green_file)
green_2018 <- read_csv(path_green_file)
# 每一天每小时载客记录总和
green_2018 %>%
mutate(hour = hour(lpep_pickup_datetime),
date = date(lpep_pickup_datetime)) %>%
group_by(date, hour) %>%
summarise(n = n()) %>%
filter(year(date) == 2018) %>%
ggplot(aes(hour, n)) +
geom_point() +
geom_line() +
facet_trelliscope(~ date, scales = "free_y")在RStudio中,可以单击Zoom将Viewer菜单中的可视化结果显示在一个独立的窗口中,更有利于观察结果。窗口的右侧是可视化的结果,左侧是菜单栏,右上角主要是翻页的操作按钮。菜单栏包括以下选项。
- Grid:设置交互界面中每一页图像的行列数和排列方式(分面的行列数也可以在代码中设置)。如图5-1所示,为了方便观看,我们将可视化部分手动设置为2行×4列,且根据日期(date)按行从左至右排列。

图5-1 trelliscope结果呈现的行列设定
- Labels:在交互界面的每个分面图中显示各个变量的基本统计量,包括最小值、最大值、均值、中位数和方差。如图5-2所示,我们在每个分面图下方加入当天载客量的最大值、中位数和最小值数据标签。

图5-2 trelliscope结果呈现的数据标签设定
- Filter:使用不同的变量和范围筛选,根据分析需要,减少交互界面中呈现的分面图数量,例如只看某个时间段内的结果,或者当天最小载客量大于某个值的日期的载客情况。如图5-3所示,我们筛选了2018年7月载客数据中载客数中位数位于500~1000的日期,可以看到符合条件的日期共有7个。
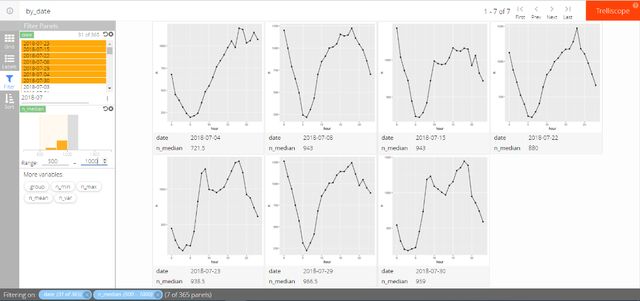
图5-3 trelliscope结果呈现的条件筛选
- Sort:根据不同的变量进行排序,重新组织所有分面图。如图5-4所示,我们根据每天的最大载客量来对日期进行排序,可以看到2018年2月2日当天的最大载客量是全年最高的,为2718人,其次为2018年1月26日,为2508人。
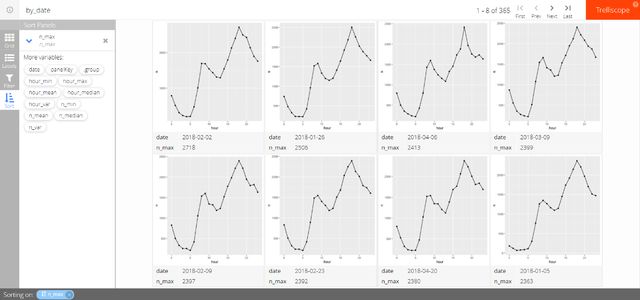
图5-4 trelliscope结果呈现的条件筛选
若已经安装另一个比较有名的交互可视化库plotly,则可以在trelliscope的基础上进一步使用plotly的交互可视化功能,只需在facet_trelliscope()中设置as_plotly = TRUE:
# 每天每时载客记录总和:结合plotly实现交互
green_2018 %>%
mutate(hour = hour(lpep_pickup_datetime),
date = date(lpep_pickup_datetime)) %>%
group_by(date, hour) %>%
summarise(n = n()) %>%
filter(year(date) == 2018) %>%
ggplot(aes(hour, n)) +
geom_point() +
geom_line() +
facet_trelliscope(~ date, scales = "free_y", as_plotly = TRUE)![]()
需要先安装plotly库。
使用plotly可以支持更加精细的交互可视化操作,如图5-5所示,可以看到每个分面图上方多了一个plotly的工具栏。
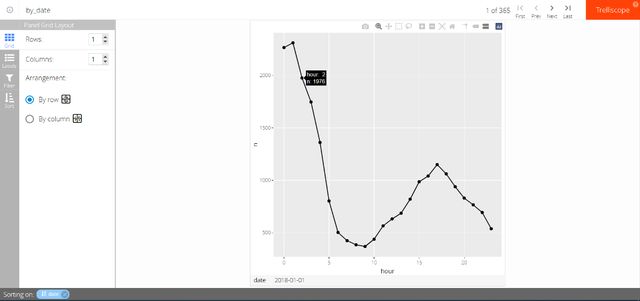
图5-5 trelliscope和plotly结合的结果呈现
以下例子中,我们分析每个区域在一年内每天乘客到达次数趋势。在这里我们加入auto_cog参数并将其设定为TRUE,这样在结果中会加入一系列的统计学指标,如相关系数(correlation):
# 每个区域在一年内每天出车次数趋势
green_2018 %>%
mutate(date = date(lpep_pickup_datetime)) %>%
group_by(PULocationID, date) %>%
summarise(n = n()) %>%
filter(year(date) == 2018) %>%
ggplot(aes(date, n)) +
geom_point() +
geom_line() +
facet_trelliscope(~ PULocationID, scales = "free_y", auto_cog = TRUE)我们可以进一步按时间和载客记录数量的相关系数进行排序(如图5-6和图5-7所示),这样能够看出哪些区域在2018年内随着时间推移被越来越多人选择为目的地,这些地区很可能会有越来越多的居住人口或者发展得越来越快。相反地,越来越少人去的地区则可能面临发展速度变缓的挑战,逐渐变为缺乏人气的状态。
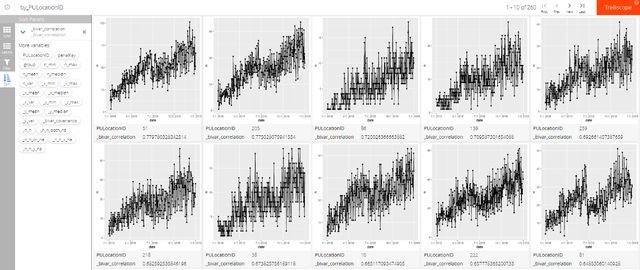
图5-6 越来越多人去的10个地区
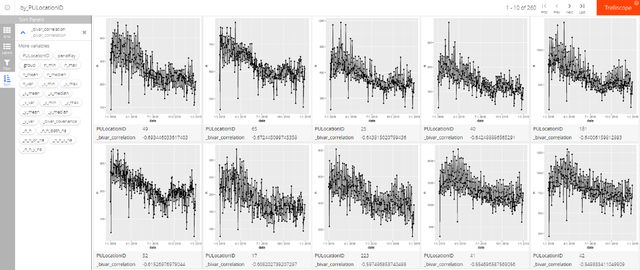
图5-7 越来越少人去的10个地区
5.2 本章小结
本章简单介绍trelliscope的基本使用方法,内容并不多。trelliscope和ggplot已经有非常好的整合,相信熟悉ggplot的用户都能很畅顺地上手trelliscope。不论是用于为他人进行数据分析后的结果报告还是自己在探索性数据分析中观察结果,trelliscope都能很好地满足需求。此外,trelliscope还能实现更多高层次的可视化效果。更重要的是,对于这类交互式的可视化工具,仅仅用文字和图片很难展现出它的强大能力,因此建议读者自己亲自动手实践一下。
本文摘自《R语言高效能实战:更多数据和更快速度》

本书将目标设定为“在一台笔记本电脑上使用R语言处理较大的数据集”,从单机大型数据集处理策略、提升计算性能、其他工具和技巧3个方面介绍了使用R语言处理数据时的实用方法,包括减少数据占用空间、善用data.table处理数据、数据分块处理、提升硬盘资源使用效率、并行编程技术、提升机器学习性能,以及其他资源管理和提高性能的实用策略,以帮助读者处理较大的数据集、挖掘R的开发潜能。