全面的中文大语言模型评测来啦!香港中文大学研究团队发布
来自:量子位
进NLP群—>加入NLP交流群
ChatGPT 的一声号角吹响了2023年全球大语言模型的竞赛。
2023年初以来,来自工业界和研究机构的各种大语言模型层出不穷,特别值得一提的是,中文大语言模型也如雨后春笋般,在过去的半年里不断涌现。
与此同时,和如何训练大语言模型相比,另一些核心的难题同时出现在学术界和产业界的面前:究竟应该如何理解和评价中文大语言模型的能力?在中文和英文大模型的理解和评测上又应该有什么联系与区别?
带着问题的思考,我们发现,近期的一系列中文大模型的评测研究陆续呈现,尽管极大地推进了中文大语言模型理解,但仍然有一些关键的研究问题需要关注和讨论。
想要准确全面地理解和评测中文大语言模型,这些问题亟须解决:
评测数据与指标的选择需要更加全面。传统的自动评测工作往往基于数量有限的考试题或部分开源数据集,采用的评测指标大多只关注广义的准确率。数据的选择不够丰富多样,指标上也忽视了鲁棒性、公平性等在模型应用中很重要的其他维度。而人工评测大模型因高昂的人力成本,在数据与指标的选择上更受制约。
不一致的评测过程容易损害评测结果的可比性。提示(prompt)模板、超参数、数据预处理等环节都会对模型最终的结果有直接影响。
难以避免的数据污染(data contamination)风险让评测对比难上加难。随着训练语料不断扩大,模型在训练过程中见过考试题和开源数据集的可能性也不断升高。
针对这些挑战,有研究团队已经给出了自己的探索与方案。
近日,EMNLP 2023的论文结果公布。来自香港中文大学计算机科学与工程学系的王历伟助理教授研究团队的CLEVA: Chinese Language Models EVAluation Platform 被EMNLP 2023 System Demonstrations 录取。
据CLEVA项目负责人王历伟教授介绍,CLEVA是其带领的港中文语言和视觉实验室(CUHK LaVi Lab)联合上海人工智能实验室合作研究的全面的中文大语言模型评测方法。
值得一提的是,CLEVA目前已经被全球前沿的英文大语言模型评测体系-斯坦福大学的HELM 评测体系认可和接入!
目前,用户已经可以通过斯坦福的HELM评测平台来调用和测试CLEVA的中文大模型评测。“能得到国际前沿大模型评测研究团队的认可,是对我们研究工作的极大鼓励。” LaVi实验室的同学自豪地说。
CLEVA:全面的中文评测
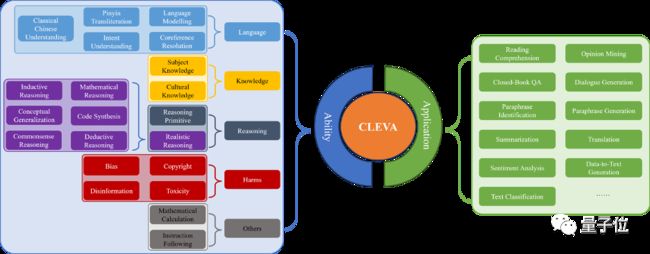
全面的大语言模型评测离不开海量的数据和完整的评测指标。CLEVA目前覆盖 31个任务(11个应用评估+20个能力评测),囊括目前最多的来自84个数据集的370K个中文测试样本。中文测试样本数是过往同类工作最大值的四倍,让大语言模型在不同任务上的能力都完整地呈现出来。
指标上,CLEVA不仅关注过往评测中大家最在乎的准确性(Accuracy),还借鉴了HELM在英文评测中的做法,针对中文评测设计了鲁棒性(Robustness)、公平性(Fairness)、效率(Efficiency)、校准与不确定性(Calibration and Uncertainty)、偏见与刻板印象(Bias and Stereotypes)和毒性(Toxicity)的指标。另外,CLEVA还引入了多样性(Diversity)和隐私性(Privacy)评测,帮助人们做出综合的判断。这对大模型应用至关重要。
标准的评测流程
在使用大模型时,人们经常发现大模型对提示等细节变化不够鲁棒。不同的提示模版会带来较明显的差异。过往的大模型评测很多只提供了评测数据,并没有提供或只提供了一两个提示模版,而这直接导致不同工作得到的评测结果不直接可比。
CLEVA为每一个评测任务准备了一组多个提示模版。所有模型用同样一组提示模版进行统一评测,不仅可以更公平比较模型能力,还可以通过不同模版带来的性能差异分析一个模型对提示模版的敏感程度,指导模型的下游应用。
更可信的评测结果
随着大模型训练用的语料越来越庞大,数据污染的风险也与日俱增。数据污染会使模型测试结果不可信,很难公平地体现出模型的能力。如何尽量减轻数据污染的问题,之前的中文评测工作还没有针对这一问题给出充分的探索和方案。
CLEVA通过多种方法在评测开始之前就主动降低数据污染带来的风险。从源头上,33.98%的测试数据是CLEVA新采集构造的。更关键的是,CLEVA基于规模最大的中文测试数据,在每轮评测时都会通过不重复采样得到一个全新的测试集。每一轮测试集在经过多种数据增强策略的调整后,才用来评测大模型,进一步缓解数据污染的风险。
如何进行CLEVA 评测?
CLEVA已经评测了23个中文大模型,还会持续用更多的数据和指标,评测更多的模型。对大模型评测感兴趣的研究团队,可以通过CLEVA网站提交和对接评测后续的进展。详细的教程请参考CLEVA官方网页或GitHub repo。
对于CLEVA已经具有的评测需求,CLEVA还提供了清晰好用的网络界面进行操作。用户可以用可交互的可视化工具,仔细对比不同模型在不同任务和评测指标上的差异。在申请权限后,用户可以让自己感兴趣的模型通过网络接口跟CLEVA进行交互,只需按几次鼠标即可开始一次全面评测,十分便利。
“团队很努力地做了很久的CLEVA,不仅仅是研究上的理解加深,细节上也在不断打磨,不断优化。在此过程中,非常感谢上海人工智能实验室的合作与支持。” CLEVA 团队在提起打造这个研究工作的时候,能感觉出来研究积累的力量。
大模型能力的认知和评测需要学术界和工业界的共同关注
笔者也了解到,学术界和工业界对大模型能力评测关注的角度也有一些区别与联系。
王历伟教授,在2020年加入香港中文大学任助理教授之前,已经在北美有数年的工业界工作经验。他也曾作为商汤科技大语言模型“商量SenseChat”的技术总负责人,带领团队于2023年4月,发布最早的国内中文大语言模型的代表之一,“商量SenseChat”。

△王历伟
当他提起学术界和工业界关注大模型评测的角度的区别和联系的时候,说道:“工业界的大模型会不仅仅关注模型的基本通用能力,还会关注大模型如何服务垂直场景和垂直产业,所以评测能力会更加在场景中具象化;而学校或者研究机构则更适合从基本的模型理解能力、认知能力、通用智能等角度来理解和评测大模型。”
针对大模型评测领域的许多开放问题,王历伟教授提到,短期内他的港中文研究团队会持续关注的几点:
“第一,就是进一步优化解决数据污染的办法。CLEVA 通过增加新数据和采样的方式减少数据污染的可能。但是未来应该可以通过新的数据生成范式来构造更多的评测数据。”
“第二,就是目前评测工作还存在很多需要提高的方面,比如应该如何定义推理(reasoning)?应该如何评价推理的过程,而不仅仅是简单地看推理的结果?再比如,针对什么是智能的理解问题上,应该如何跨学科地合作,来设计新的问题,来检验大模型的智能。当然还有很多方面,比如AI 安全问题,如何评价幻觉问题,等等。”
“第三,多模态场景下的涌现能力和纯语言学习下有哪些不同?我们有十年左右的vision+language 研究经验和积累。CUHK LaVi Lab在不断加强大语言模型和多模态大模型的各个课题研究的同时,也会不断探索多模态场景下的大模型的能力认知和评测。”
“对大模型能力认知和评测的研究本身,也一定会帮助研究团队理解和加强持续提高大模型的能力。”
参考链接:
[1] CLEVA论文地址:
https://arxiv.org/abs/2308.04813
[2] CLEVA GitHub Repo:
https://github.com/LaVi-Lab/CLEVA
[3] CLEVA官方网页:
http://www.lavicleva.com
[4] 斯坦福大学HELM官方网页:
https://crfm.stanford.edu/helm/latest/
*本文系量子位获授权刊载,观点仅为作者所有。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
