about sdsoc.pdf
发现几个月不看不用居然基本都忘记完了。现将需要使用的部分简略记下来,以后就直接来这里看就会很快。ug1027主要是介绍Sdx IDE软件界面的一些功能让人熟悉使用方式;ug1233主要是介绍xfopencv的一些API;ug1253主要介绍Sdx的一些优化指令以及使用方式;ug1235主要是介绍SDSOC编码优化方式和方法策略。
一、ug1253
Sdsoc就是一个利用HLS将可综合C/C++函数编译诚可编程逻辑的平台。通过使用Sdsoc IDE或者Sdscc/sds++命令行,用户可以从源代码中选择要在PL端执行的函数、指定加速器和系统时钟并选择数据转换模式。
Sdsoc编译器会自动会数据传输选择最合适最好的系统端口,但用户也可以通过使用优化指令pragmas自己规定在PL端执行的函数实参的输出方式,同时可以控制PL和PS端数据转换的数量。Sdsoc环境中所有的优化指令都是以#pragma SDS开头直接加在源代码中要加速的地方,比如在函数声明的前面。
#pragma SDS data access_pattern(in_a:SEQENTIAL, out_b:SEQUENTIAL)
void f1(int in_a[20], int out_b[20]);
SDS优化指令类型:数据访问模式pragma SDS data access_pattern,数据传输大小(原大小复制pragma SDS data copy和零拷贝复制pragma SDS data zero_copy(这个很像以前学的OpenCL加速,也涉及过零拷贝)),内存选项pragma SDS data mem_attribute,数据传输类型pragma SDS data data_mover,数据对外接口pragma SDS data sys_port,硬件缓冲深度pragma SDS data buffer_depth,函数异步pragma SDS async等待与响应pragma SDS wait,指定绑定资源pragma SDS resource,硬件/软件追踪pragma SDS trace
一、pragma SDS async
#pragma SDS async(
...
#pragma SDS wait(ID)
这两条指令必须一一对应的出现在源代码中,就像if-else一样。这个优化指令主要是用来人为控制函数的运行:async指定异步后,wait要求CPU必须等待硬件函数线程执行结束。
例子:
for (int i = 0; i < pipeline_depth; i++)
{
#pragma SDS async(1)
mmult_accel(A[i%NUM_MAT], B[i%NUM_MAT], C[i%NUM_MAT]);
}
for (int i = pipeline_depth; i < NUM_TESTS; i++)
{
#pragma SDS wait(1)
#pragma SDS async(1)
mmult_accel(A[i%NUM_MAT], B[i%NUM_MAT], C[i%NUM_MAT]);
}
for (int i = 0; i < pipeline_depth; i++)
{
#pragma SDS wait(1)
}
所谓流水处理方式就是在此次循环还没执行结束时下一次循环的数据已经传到加速器了,而不是像CPU那样一定要等待此次循环结束,下次循环的数据才会传到加速器从而开始下一次的循环。
二、pragma SDS data access_pattern
#pragma SDS data access_pattern(ArrayName:
这个优化指令必须加在函数声明之前,它是指定硬件函数的数据访问模式,SDSOC会自动检查这个优化指令来决定硬件函数综合成什么样的接口。SEQUENTIAL代表流接口如ap_fifo,即只支持一次性访问;RANDOM(默认)代表RAM接口,可以访问多次。
例子1:
#pragma SDS data access_pattern(A:SEQUENTIAL)
void foo(int A[1024], int B[1024])
例子2:
#pragma SDS data access_pattern(A:SEQUENTIAL)
#pragma SDS data copy(A[0:1024])
void foo(int *A, int B[1024])
此优化指令常常与拷贝指令同时使用,是为了防止被综合成寄存器。一般不会与#pragma SDS data zero_copy一起使用,因为zero_copy会被综合成流接口,所以功能会重复。
三、pragma SDS data buffer_depth
#pragma SDS data buffer_depth(ArrayName:
这个优化指令必须加在函数声明之前。这个优化指令只能用户被映射为BRAM和FIFO接口的数组的优化!
• BRAM: 1 ≤
• FIFO:
四、pragma SDS data copy(默认) | zero_copy(引用和指针) (不可同时使用,一个对象如果是copy就不能再是zero-copy)
1、一维数组的拷贝
#pragma SDS data copy|zero_copy(ArrayName[
2、多维数组的拷贝
pragma SDS data copy(ArrayName[offset_dim1:length1]
[offset_dim2:length2])
此优化指令必须在函数声明之前使用。pragma SDS data copy表示PS端到PL端的显式拷贝;pragma SDS data zero_copy表示硬件函数直接从共享内存区域通过AXI总线接口访问数据。函数声明与定义时的各种形参名最好一样,否则优化指令无法真正使用。
五、pragma SDS data data_mover
#pragma SDS data data_mover(ArrayName:DataMover[:id(正数)])
此优化指令建议平常别用,仅用在编译器产生的数据输出类型与我们的要求不符合时。此优化指令在使用时必须加在函数声明之前。一般情况下Sdsoc编译器会自动通过分析代码选择合适的数据传输类型,如果使用此优化指令可以修改编译器的结果。此优化指令会指定AXIFIFO, AXIDMA_SG, or AXIDMA_SIMPLE三种数据传输方式,如果要使用AXIDMA_SIMPLE这种传输方式,那数组必须是sds_alloc()这样分配内存的数组才行。
六、pragma SDS data mem_attribute
#pragma SDS data mem_attribute(ArrayName:contiguity)
此优化指令必须加在函数声明之前。此优化指令主要是用来告诉编译器该参数是否分配了连续的物理内存,从而编译器好自主选择合适的数据传输方式。contiguity有两种:PHYSICAL_CONTIGUOUS(由sds_alloc分配的内存)和NON_PHYSICAL_CONTIGUOUS(默认)(由malloc或堆上的一个变量)。
七、pragma SDS data sys_port
#pragma SDS data sys_port(ArrayName:port)
此优化指令必须加在函数声明之前。此优化指令会盖过编译器为我们自动选择的内存端口。
port: Must be ACP, AFI, or HPC.
1、The Zynq ® -7000 SoC provides a cache coherent interface (S_AXI_ACP) between
programmable logic and external memory, and high-performance ports (S_AXI_HP) for non-
cache coherent access (AFI).
2、The Zynq UltraScale+ MPSoC provides a cache coherent interface (S_AXI_HPCn_FPD), and
non-cache coherent interface called (S_AXI_HPn_FPD).
八、pragma SDS resource
#pragma SDS resource(
此优化指令必须加在硬件函数被调用之前来指定资源绑定(特定的硬件加速器)。
九、pragma SDS trace
#pragma SDS trace(
此优化指令可以在函数层次或参数层次实现追踪来让用户进行主观的监测调试。当这个优化指令打开追踪功能后,追踪操作就会自动加在源代码中,同时硬件监测器也会在硬件逻辑生成期间被植入到硬件系统中。你可以监测到整个硬件函数或者只观测函数的某个变量。追踪的选项有SW(软件层次)或HW(硬件层次),两者也可以同时使用(默认)。
二、ug1233
一、过程
1、PS端从SD卡读取图像并将其保存到DRAM中
cv::Mat in_gray = cv::imread("./data/im0.jpg", 0);
if (in_gray.data == NULL)
{
fprintf(stderr,"Cannot open image\n");
return 0;
}
2、PL端读取DRAM中的图像(cv::Mat to xF::Mat)
static xf::Mat
#pragma SDS data zero_copy(in_gray.data)
imgInput.copyTo(in_gray.data);
3、PL硬件函数处理并将结果图输出到DRAM中
static xf::Mat
//some hardware function using imgInput...and imgOutput is its result
...
4、PS从DRAM读取结果图并保存进SD卡中 (xF::Mat to cv::Mat)
cv::Mat resultmat(in_gray.rows,in_gray.cols,CV_8UC1);
resultmat.data=imgOutput.copyFrom();
cv::imwrite("cpu_out.jpg",resultmat);
二、xf::Mat
xf::Mat
TYPE:和opencv一样,只是把CV换成XF而已,如CV_8UC1-->XF_8UC1
NPC:一个时钟周期处理的像素个数,有XF_NPPC1和XF_NPPC8
三、API(每个函数前面均有模板)--->ug1233-xilinx-opencv-user-guide.pdf
1、xFabsdiff
两个XF_8UC1类型的xf::Mat之差的绝对值.行和列必须是8的倍数,其它与opencv的这个函数没什么差别。
2、xFaccumulate
求图像之和。输入图像必须是XF_8UC1,输出图像必须是XF_16UC1,行列必须是8的倍数。
3、xFaccumulateSquare
求图像的平方之和。输入图像必须是XF_8UC1,输出图像必须是XF_16UC1,行列必须是8的倍数。
4、xFaccumulateWeighted
图像加权融合。输入图像必须是XF_8UC1,输出图像必须是XF_16UC1,行列必须是8的倍数。
5、xFBilateralFilter
中值滤波。滤波窗口的大小必须是3、5、7。输入输出图像必须都是XF_8UC1,只支持XF_NPPC1。行列必须是8的倍数。
6、xFconvertTo
图像类型转换。
7、xFbitwise_and | xFbitwise_not | xFbitwise_or |xFbitwise_xor
只支持XF_8UC1,行列必须是8的倍数。
8、xFboxfilter
滤波窗口的大小必须是3、5、7,图像类型必须单通道8位或16位。
9、xFcanny
窗口的大小必须是3、5,NORM_TYPE:L1NORM或L2NORM,输入类型只支持XF_8UC1,行列必须是8的倍数。
10、xFEdgeTracing
...
三、ug1027
四、Sdsoc的良好编程要求--->ug1027-sdsoc-user-guide.pdf
1、一般性要求
a、减少资源利用率,提高流数据的并行能力而尽量别将数据直接拷贝进PL端。
b、重复利用PL端的局部变量而不是将数据在有限的DMA传来传去。
c、对于加速函数:高效的数据转换,流处理
d、尽量让更多的加速函数或加速实例并行来提高任务的并行度。
2、对于软件方面的要求
a、良好的内存管理机制,如sds_alloc()/sds_free()这样去创建或释放连续内存。
b、使用系统仿真检验程序的正确性。
c、将硬件函数写在单独的源文件中这样每次改动后不用编译整个工程。
3、对于硬件方面的要求
...
五、SDSOC环境--->ug1027-sdsoc-user-guide.pdf
1、Sdsoc在编译结束后会产生一个sd_card文件夹。里面通常包含启动项BOOT.BIN以及可执行文件(工程名).elf、README.txt、设备树文件image.ub
2、当选择好硬件函数后,需要选择适当的时钟频率,虽然越高的时钟频率能让性能提高,但有的硬件系统时钟频率有上限值,超过这个值了就跑不起来,这时候应该降低时钟频率。在Sdx IDE界面设置时钟频率时,一般应该让硬件函数的时钟频率和Data motion的时钟频率一样。
3、在编译完一个Sdx工程后,建议在Sdx界面使用Sdsoc提供的标准板(such as zc702, zc706,zcu102, zcu104, zcu106)验证一下:点击.sdx将Target选项由Hardware改成Emulation即可。在Emulation模式下可以选择调试或者优化模式,会生成一个报告Data Motion Network Report。更详细的调试机制在p74页(这里写的计算PL端的耗时最好用sds_clock_counter()函数,xfopencv的例子中有这个函数,可是实际使用的却是perf_counter.start()? perf_counter.stop()? perf_counter.avg_cpu_cycles()??)。
4、在验证过后,选择最后的编译,Debug或Release都支持。
六、Sdsoc上的优化--->ug1027-sdsoc-user-guide.pdf
1、主要分为两大部分的优化:PS端和PL端
2、用户可能比较熟悉纯CPU代码的优化,但对于FPGA用户需要有算法并行、数据转换,内存使用和消耗以及硬件逻辑的意识。必须明确哪些部分是可以放在FPGA部分加速的,哪些部分又无法加速只能在CPU端执行,host端两大模块的规划及交互设计很大程度上决定了整个工程的性能。在数据转化传输时尽量不要让PL或PS端空等。
3、优化完的结果可以在HLS Report, and Data Motion Network Report中看到.
四、ug1235
七、Sdsoc编码优化具体策略--->ug1235-sdsoc-optimization-guide.pdf
1、一般情况下,Sdsoc编译产生bitstream文件是需要很长时间的。我们预估性能有时却不想等待太久,于是可以勾选Estimate performance。这个选项虽不会综合成bitstream但依旧可以估算出硬件函数的耗时以及数据传输时间。如果发现系统的耗时达不到我们的要求,就需要进行优化。提高系统的性能主要从:硬件函数内部如何最大程度并行化、提高系统并发度、提高可编程逻辑到外部内存的访问效率、理解并高效利用默认数据模式或自定义数据模式。
3、提高系统的并行度
主要有两种方法:在硬件函数之间让数据流"direct connection"而不是在硬件函数之间联系(p21页有例子,没看懂写法上有什么区别??);另一种方法是通过优化指令#pragma SDS resource(
#pragma SDS resource(1)
mmult(A, B, C); // instance 1
#pragma SDS resource(2)
mmult(D, E, F); // instance 2
4、数据传输过程(PS端)
在PS和PL端每一次的联系都会涉及到数据传输,往往是库里面的函数来完成。比如AXI_DMA_SG,AXI_DMA_SIMPLE, AXI_FIFO,zero_copy (accelerator-mastered AXI4 bus), or AXI_LITE。如#pragma SDS data data_mover(A:AXI_DMA_SIMPLE)
axi_lite主要是利用AXI4_Lite总线来传输Scalar类型的变量;
数组的传输需要考虑到数组的大小和是否连续:32MB以下的内存连续(malloc()或new()分配的堆内存就不是物理连续的内存)的数组可以选择高效的axi_dma_simple来传输、300Bytes以下的可以选择很慢但占资源很少的axi_fifo来传输、 axi_dma_sg不限制大小但速度较慢占资源较多同时要求数组内存最好连续。
结构体或类对象的传输需要根据拷贝、引用或指针、数组传递方式的不一样来参考p25页的表格来选择数据传输方式。
zero_copy相对其它四种传输方式更独特一些,zero_copy意味着在PL端是AXI_MASTER方式来获取PS端的数据。如果要使用这种传输方式,要求数据内存必须连续如使用sds_alloc分配的就可以。
5、加速器接口(PL端)
加速器的接口主要取决于参数的数据类型。Scalar类型的参数用寄存器接口;数组用RAM接口(PL端存储了整个数组然后在PL端是随机访问)或流接口(不需要PL端存储整个数组,可以流水化处理数组元素。但必须是连续访问)。Sdsoc为数组默认RAM接口类型(数组默认是随机访问),但用户可以通过优化指令修改 #pragma SDS data access_pattern(function_argument:pattern)(不能和zero_copy数据传输方式同时使用)。如果是结构体或者类可以参考p25页表格。
6、系统端口设置
#pragma SDS data sys_port(arg:port)
所谓端口就是PS端与数据传输通信的口子,它可以是ACP/AFI/MIG/stream port。
2、硬件函数内部如何最大程度并行化
硬件函数的并行化用另一句话讲就是如何写出高效的能交叉编译为可编程逻辑的代码。其实要将源代码变成可编程逻辑,Sdsoc是利用了HLS来完成的,其实这里最好去看ug902.pdf。
a、对于顶层函数请尽量使用C99标准数据类型,不要使用bool类型的数组也不要使用hls::stream类型(虽然HLS中可以);对于顶层函数前面不要使用HLS优化指令#pragma HLS interface,因为当我们使用#pragma SDS data zero_copy()和#pragma SDS data access_pattern(argument:SEQUENTIAL)时,sdcc/sds++就会自动产生合适的HLS指令。
b、使用HLS的库函数
当我们写好了代码编译过后看到report中的性能达不到我们的要求时,先检查以下几点再进行代码的优化:
a、Project Settings → Data Motion Network Clock Frequency降低数据传输的频率,看是否是因为频率超出了系统的限制导致编译时间不正常达不到预期。(这里有点不懂啊,降低以后报告出来时间更长,那也不知道之前的时钟频率是否合适啊??)
b、检查II指标(硬件函数的总耗时),但这里没看懂啊??p32页。
c、检查loop II指标(循环次数)
d、latency
e、loop iteration latency一次循环所耗时钟
f、资源占用率
看完这些指标,然后就有了优化的方向。优化主要思路分为:仿真验证函数正确性-->综合(定义接口类型和循环上限-->增加流水优化指令-->拆分大数组和修改不必要的依赖关系-->(optional)指定要满足的时间要求-->(optional)优化资源占用)。
A、LOOP_TRIPCOUNT确定循环上限
不过这个对综合并没有影响,只是影响report而已。当循环的上限不是常数,而是一个变量时,用LOOP_TRIPCOUNT优化,对硬件实现并没有影响,只是让report方便看而已。
B、函数、循环、操作的Pipelining
Pipelining有4种方式可以选择:PIPELINE/DATAFLOW/RESOURCE/Config Compile。以下几点需要注意:
子函数必须是pipelined,否则如果被调用的地方运用了pilelined,那没pipelined的子函数会拉低性能;有子循环(多层循环)的函数或者循环内如果应用了pileline,那所有的循环都会自动展开unroll从而产生很多逻辑,建议直接在子循环里pipeline;因为当循环的上限是个变量时(不会展开),所以建议对于循环上限是变量的循环使用pipeline并且使用DATAFLOW确保让所有的pipelined的循环。另外也可以不要将上限用变量而是用一个条件语句,超过最大上限时跳出循环。(以前见过这种例子)
多个算术操作可以应用RESOURCE流水化优化(我一直以为RESOURCE是解决资源占用问题,也表示流水处理??)
函数pipeline优化:因为函数主要有2种C/C++模式:框架式和sample式:
框架式的函数通常是处理一些图像数据或视频流、数组或指针,常常需要用到多层循环。这种C++模式可以将pipeline加在函数、第一层loop(图像行)、第二层loop(图像某个像素点)、第三层loop(图像像素点每个bit)...理想情况下是在loop2时加入pipeline。
sample式的函数往往有一个共同标志即含有静态变量用作累加器或计数器,这种函数直接在函数层次pipeline即可。虽然这样会令内部的loops都展开,但这是无法避免的。另外这种函数内部不建议应用partition优化数组。
C、...太多了第4章的内容,与ug902上是重复的。直接去看ug902吧,更详细。
D、内存访问优化
改善PS和PL之间的内存访问以及数据传输速度对于提高性能也非常重要。数据通常都存储在外部DDR中,直接访问速度很慢。好在FPGA提供了局部cache、局部小型中型数据模块来存储数据从而进行快速访问,所以这也是为什么在FPGA中局部内存会被广泛使用的原因。
a、数据传输优化
内存的分配:请尽量使用sds_lib的一些函数来分配内存:sds_alloc(size_t size)、
sds_mmap(void *paddr, size_t size, void *vaddr)、sds_register_dmabuf(void *vaddr, int fd)这三个函数分配的内存都是物理连续的。当然如果编译器无法准确推断出这三个函数分配内存的连续性,用户可以自己用优化指令明确告诉编译器#pragma SDS data mem_attribute (A:PHYSICAL_CONTIGUOUS)。
拷贝和共享内存:因为外部PL与DDR之间的数据拷贝比其与CPU之间的耗时更长。使用zero_copy优化指令来从共享内存读写数据效率并不高,更高效的方法使用memcpy将整个数据读或写进来然后存在局部内存中!另一种比使用copy和zero_copy更好的方法是用流数据#pragma SDS data access_pattern(A:SEQUENTIAL)从DDR到PL端得到数据然后将其存在硬件函数的局部变量中,这样无法你想怎么访问就怎么访问!关于拷贝copy,当一个数组用指针作为形参参数时,有时编译器会不知道它的大小而发出警告,这时可以显示告诉编译器#pragma SDS data copy(p[0:
b、数据访问模式的优化
虽然提起数据访问,更多的是关注PL端的读或写,但硬件函数内部的数据访问也对性能有很大影响。这里书上又举了那个卷积的例子p64,从动态内存分配、局部变量的大小和初始化方式上明确指出了传统卷积写法如何拉低了硬件性能。总所周知PS和PL之间的访问越少性能越高,所以尽量只从PS端读取一次数据然后将数据存在小型或中型局部数组中以便多次访问才是上上策。从这个例子可以看到FPGA上写代码的一些禁忌。反过来想,就是一些FPGA上如何编写高效代码的准则:
保持数据的流动性,任何会阻碍数据连续流动的行为尽量别使用;
硬件函数的输入参数最好只读一次,不要重复读,如果要重复尽量使用局部高效缓冲区;
硬件函数的输出参数最好只写一次,不要重复写,尽量使用局部高效缓冲区;
少访问数组,特别是大数组。虽然有PARTITION优化但是这个优化会消耗很多寄存器,所以最好还是使用local cache。
在pipeline优化下使用条件分支而不是直接用条件分支分配任务!在FPGA上是个不错的选择;
我们先看书上卷积的传统写法然后看下面的FPGA的水平卷积优化写法:
template
static void convolution_strm(int width,int height,
T src[TEST_IMG_ROWS][TEST_IMG_COLS],T dst[TEST_IMG_ROWS][TEST_IMG_COLS],const T *hcoeff,const T *vcoeff)
{
T hconv_buffer[MAX_IMG_COLS*MAX_IMG_ROWS];
T vconv_buffer[MAX_IMG_COLS*MAX_IMG_ROWS];
T *phconv, *pvconv;
// These assertions let HLS know the upper bounds of loops
assert(height < MAX_IMG_ROWS);
assert(width < MAX_IMG_COLS);
assert(vconv_xlim < MAX_IMG_COLS - (K - 1));
// Horizontal convolution
phconv=hconv_buffer; // set / reset pointer to start of buffer
HConvH:for(int col = 0; col < height; col++)
{
HConvW:for(int row = 0; row < width; row++)
{
#pragma HLS PIPELINE
T in_val = *src++;
// Reset pixel value on-the-fly - eliminates an O(height*width) loop
T out_val = 0;
HConv:for(int i = 0; i < K; i++) {
hwin[i] = i < K - 1 ? hwin[i + 1] : in_val;
out_val += hwin[i] * hcoeff[i];
}
if (row >= K - 1) {
*phconv++=out_val;
}
}
}
//...
}
从这个例子可以看到使用了TRIP_COUNTER优化、pipeline的确用在了loop2、使用了局部cache、没有再像传统CPU编程一样对很大的局部结果清零现在只用清零out_val、对原图src的访问遵循了流的方式(严格按照Z字形按Mat.data排列访问,没有再随机访问而打破流)!但hwin[i] = i < K - 1 ? hwin[i + 1] : in_val;这句我之前我没理解,后来经过网友HLS大神ggqhit的点拨我明白了,原来自己在理解时一直将if(row>=K-1)当成if(i>=K-1)且在第三个循环里面去理解了,我也不知道自己为什么以前都是那样可能眼瞎了。其实就是对于src[0]也就是第一次进二级循环时,srd[0](存了一份在hwin[4]中)对着1X5窗口的最后一个元素hcoeff[4],这样的结果是无效的;接着窗口向src[1]移动,hwin[4]将src[0]抛给hwin[3]保存且hwin[3]对着hcoeff[3],自己去保存src[1]且对着hcoeff[4].....如此类推。
我们看完了传统的垂直方向卷积写法,再看下面的FPGA的垂直卷积写法。总所周知,因为水平卷积还可以遵循流的方式(Z字形),但垂直卷积无法严格按Z字形来。所以这里会使用“line buffer”!
// Vertical convolution
phconv=hconv_buffer; // set/reset pointer to start of buffer
pvconv=vconv_buffer; // set/reset pointer to start of buffer
VConvH:for(int col = 0; col < height; col++)
{
VConvW:for(int row = 0; row < vconv_xlim; row++)
{
#pragma HLS DEPENDENCE variable=linebuf inter false
#pragma HLS PIPELINE
T in_val = *phconv++;
T out_val = 0;
VConv:for(int i = 0; i < K; i++)
{
T vwin_val = i < K - 1 ? linebuf[i][row] : in_val;
out_val += vwin_val * vcoeff[i];
if (i > 0)
linebuf[i - 1][row] = vwin_val;
}
if (col >= K - 1) {
*pvconv++ = out_val;
}
}
}
从这个例子可以看到使用了TRIP_COUNTER优化、使用了DEPENDENCE优化、pipeline的确用在了loop2、使用了局部linebuffer、没有再像传统CPU编程一样对很大的局部结果清零现在只用清零out_val、对上一步的结果即水平卷积phconv的访问遵循了流的方式(严格按照Z字形顺序访问,没有再随机访问而打破流)对结果的写出也是流的方式!p74页
E、使用AXI性能监视器(APM)衡量性能
书上用一个实例告诉我们如何使用APM在p77页。可是按照书上的步骤到第10步时在windows--perspective下没找到performance analysis选项啊?!
因为很久以前在另一篇记录里我尝试过在ubuntu下在开发板上跑程序,但始终跑不起来始终进入zynq> 始终提示找不到命令!所以后来我是在windows上使用的。今天终于可以了,无意中翻到了这位大神的:https://www.cnblogs.com/jadeny/p/7674313.html
参考他的这个步骤:

打开我自己的minicom,原来我以前竟然装过这个!看到自己的配置是:
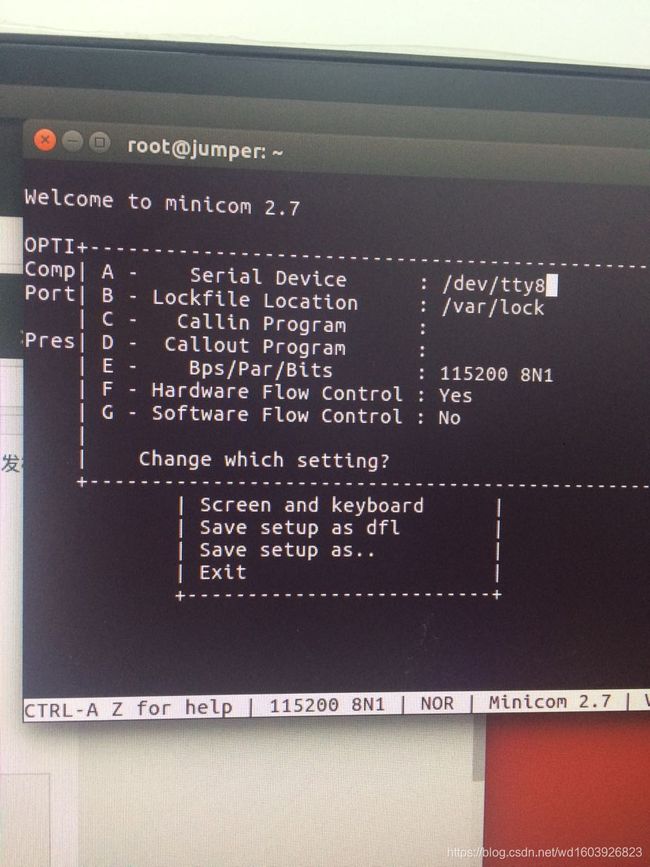 然后修改成那个人的样子。重新打开终端,Enter然后就可以进入命令行了:
然后修改成那个人的样子。重新打开终端,Enter然后就可以进入命令行了:

 已经可以正确输出程序信息了!
已经可以正确输出程序信息了!
但是我想像p82页一样调试时,参考书上的步骤以及https://www.cnblogs.com/jiandahao/p/5702733.html 设置TCF然后:
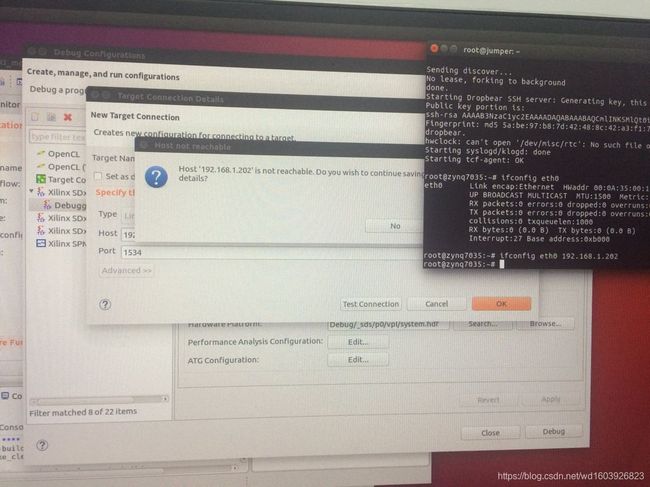 但是不知道为什么连接不上,然后我将开发板重启重新配置ifconfig eth0不知道为什么就可以了
但是不知道为什么连接不上,然后我将开发板重启重新配置ifconfig eth0不知道为什么就可以了
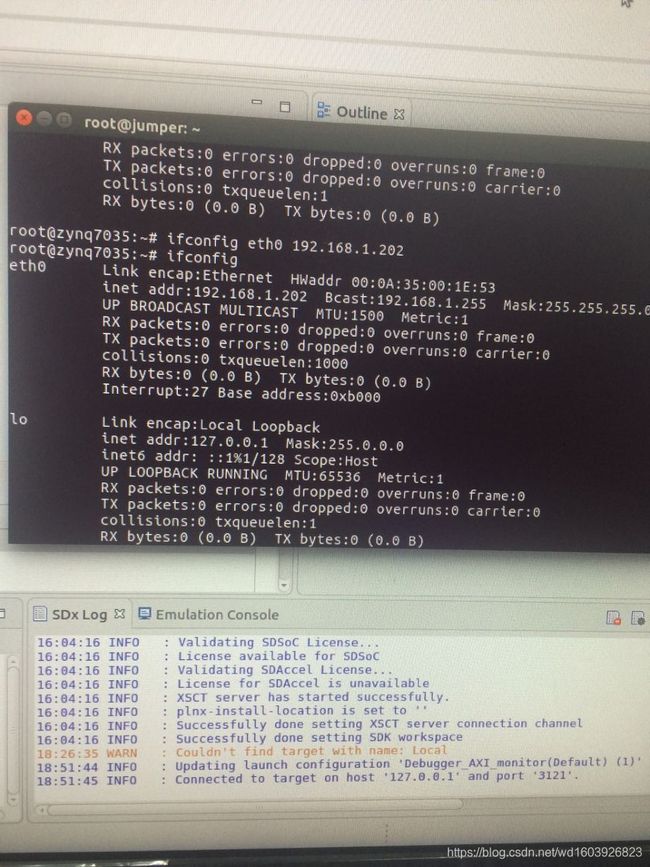 这个显示已经连接上了开发板和端口!但是我在窗口下面没找到Performance Analysis的窗口啊??!!为什么没有呢?
这个显示已经连接上了开发板和端口!但是我在窗口下面没找到Performance Analysis的窗口啊??!!为什么没有呢?
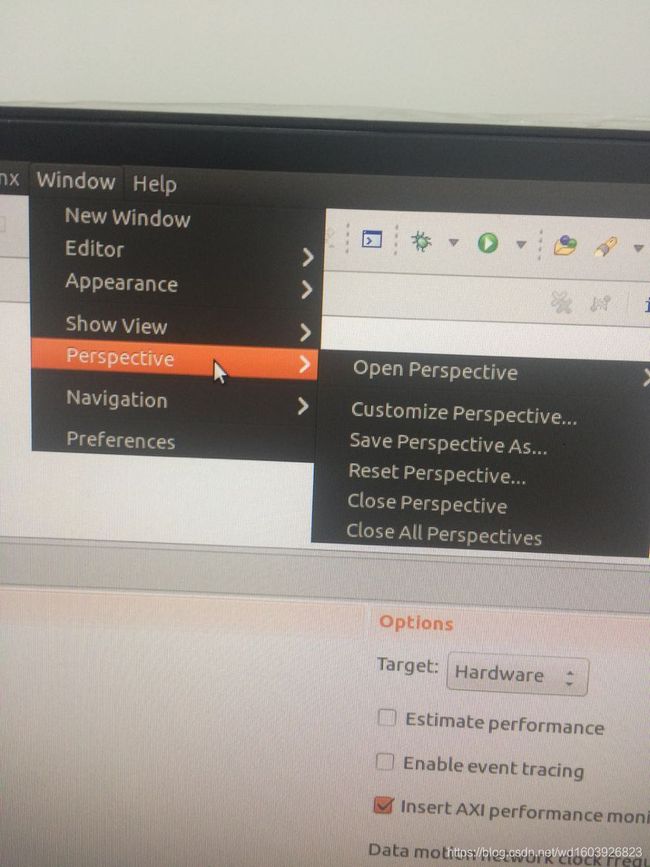
所以我无法进行后面的操作真正Debug起来!!!??
F、两个实例
书上最后讲了两个实例optical_flow 、stereo vision,在看这两个的优化过程中,我看到了一段话:
In general, the DATAFLOW optimization is not required because the SDSoCTM environment
automatically ensures that data is passed from one hardware function to the next as soon as it
becomes available; however, in this example, the functions within stereo_remap_bm are using
a Vivado HLS data type hls::stream which cannot be compiled on the Arm ® processor and
cannot be used in the hardware function interface in the SDSoC environment. 所以我之前尝试使用hls video function & xfopencv function一直失败!!!
这两个例子可以好好看下,但代码不完整,没在网上看到完整的代码啊?!
五、ug1278
八、Sdsoc编码指南--->ug1278-sdsoc-programmers-guide.pdf
Sdsoc其实底层使用了HLS,对于Dataflow可以理解成让每个函数的调用并行,pipeline可以理解为一个时钟内并行的操作。
Sdsoc上的编码主要分为以下几步:
确定哪些函数要放在PL端加速作为硬件函数;
在PS端和PL端分配所需内存;
多个硬件函数任务并行;
验证软件到硬件的转换部分;
1、内存分配
虽然在main函数中,malloc/free也可以使用。但对于要在硬件函数中使用的内存最好使用sds_alloc/sds_free比较好,这会分配物理连续的内存后续会有更快的读写速度。另外对于cacheable/non-cacheable的内存类型选择也很重要,non-cacheable类型意味着不是在PS端使用的内存,速度会更快。必须在调用硬件函数之前就分配好要使用的数据内存。
float *A, *B, *C, *D, *D_sw;
A = (float *)sds_alloc(N * N * sizeof(float));
B = (float *)sds_alloc(N * N * sizeof(float));
C = (float *)sds_alloc(N * N * sizeof(float));
D = (float *)sds_alloc(N * N * sizeof(float));
D_sw = (float *)malloc(N * N * sizeof(float));
if (!A || !B || !C || !D || !D_sw) {
if (A) sds_free(A);
if (B) sds_free(B);
if (C) sds_free(C);
if (D) sds_free(D);
if (D_sw) free(D_sw);
return 2;
}
2、多个硬件函数顺序/并行执行
当只有1个硬件函数时,讨论这个没有意义。当有多个优化函数时,顺序还是并行pragma HLS PIPELINE影响着数据是否共享怎样共享。如果要指定并行执行,还要在硬件函数调用前后加上#pragma SDS async(id) and
#pragma SDS wait(id) !如果硬件函数与别的硬件函数或CPU之间数据不共用,那么non-cacheable物理连续的内存分配会带来最大的性能!但是如果某个硬件函数需要用到上个硬件函数的数据,那么不要使用#pragma SDS async(id) and
#pragma SDS wait(id),因为本来这个硬件函数必须等那个硬件函数运行完毕后去读那个新数据再执行,所以不要加入async指令会导致读到的数据是还未更新的数据!!!书上p19页举了一个例子来阐述顺序和并行执行并比较它们的性能差异。我发现我之前好像见过这个例子,之前不懂的。现在看竟然看懂了。不知道为什么,可能以前太蠢了。
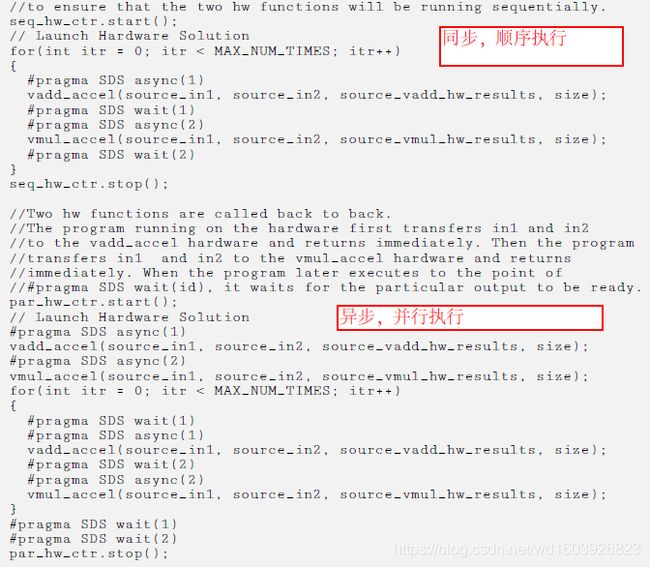 第一段是阐述的顺序执行:严格让这两个硬件函数顺序执行:先执行完加等待返回再执行乘然后等待结果返回;再开始第二个循环执行加等待加的结果返回再执行乘等待乘的结果返回,然后进入下一次循环(其实不加这些指令,编译器也是默认这样做的).....第二段的执行是:同时执行函数1和函数2,其实就相当于同时开了两个线程一样,一个线程看到函数1结束立马执行下一次函数1,另一个线程看到函数2结束立马执行下一次函数2,两个线程并行,互不影响。
第一段是阐述的顺序执行:严格让这两个硬件函数顺序执行:先执行完加等待返回再执行乘然后等待结果返回;再开始第二个循环执行加等待加的结果返回再执行乘等待乘的结果返回,然后进入下一次循环(其实不加这些指令,编译器也是默认这样做的).....第二段的执行是:同时执行函数1和函数2,其实就相当于同时开了两个线程一样,一个线程看到函数1结束立马执行下一次函数1,另一个线程看到函数2结束立马执行下一次函数2,两个线程并行,互不影响。
3、验证硬件函数结果的正确性
用硬件函数对应的传统C函数来验证硬件函数结果的正确性是一个好习惯。即用传统C代码检查各个硬件函数以及整体硬件函数的正确性,最好每个硬件函数写一个对应的C代码进行验证。
4、性能估计
很多例子里都用到了perf_counter类来统计硬件函数和软件函数的始终周期,从而计算FPGA到底比CPU加速多少。
5、硬件函数编程
定义硬件函数接口:输入输出数据类型、数据传输类型;
内存访问方式:DMA、FIFOs;
数据访问方式:连续或非连续;
数据会被如何处理:loops、数组;
硬件函数的数据必须严格遵循:数据大小不能在运行期间改变;数组是static(好像看到例子中有数组不是static?)而且不能重新改变大小!!!
6、硬件函数可以编译成IP核与库函数。将硬件函数编译为库文件:use the sds++/sdscc command with the -shared (which is interpreted as -fPIC for gcc) option to build a shared library when compiling the functions 跟传统的C的共享库编译一样。
A、硬件函数编程概要
硬件函数支持单线程与多线程;
top顶层函数必须是一个全局函数,不能是类成员函数,不能是重载函数;
硬件函数内部不支持异常处理;
硬件函数不能指向被CPU端的函数使用的全局变量!!!?(这个好像没看到过例子)
硬件函数支持scalar即8bit~1024bit。包括double、long long以及结构体类型等;
硬件函数应该至少有一个形参;
硬件函数中scalar类型的输入或输出参数可以被多次写入,但只有最后一次的写入在函数退出前可以被读取???(这个好像没看到过例子)
如果用到#ifdef & #ifndef前后一定要下划线如: #ifdef _MULTI_H_
B、硬件函数参数类型
为了避免接口不兼容导致sds++编译器无法生成正确的接口类型,可以人为通过interface优化指令去指定。虽然在HLS中接受ap_fixed
hls::stream,但是在Sdsoc中是有限制的,总所周知Sdsoc不支持hls::stream类型,虽然支持ap_fix
硬件函数的形参不能是bool类型!!!
指针类型要注意:不能包含在结构体中传给硬件函数!!默认情况下,指针会被编译器当做scalar类型!如果指针要共享(即读又写)那么请用#pragma SDS data zero_copy;
如果要指定是流类型顺序访问,那么请指定
#pragma SDS data copy(p[0:
#pragma SDS data access_pattern(p:SEQUENTIAL) (这两条指令一般是同时使用,表示将数据存在DDR中(数据很大时适合))
如果指针要被随机访问,那么一定要显示地将指针转成同大小的数组!!!
C、硬件函数调用
以下两种情况必须使用sds_alloc(stdlib.h & sds_lib.h同时包含)分配数组内存:
当数组使用zero_copy优化时;
当用优化指令显示地指定数组使用Simple-DMA时;(这个没见过啊?)
之前已经说过,data copy & access_pattern(p:SEQUENTIAL)同时使用一般很适合大数据,因为数据会存在DDR中是以流的方式顺序访问,当然也就是只能从PS端读一次。
如果没有指定data copy而只指定access_pattern(p:SEQUENTIAL),那么数据接口类型是FIFO(这句好像不对?),支持随机访问即RAM接口。
可以用#pragma SDS data mem_attribute告诉编译器内存是否连续,是否为cacheable...可以看ug1235
D、函数体部分
在指定好函数接口类型和数据转换类型以后,函数体部分的宗旨就是要应用能应用的优化指令提高性能,比如请使用任意bit类型代替传统的C类型。
I、任意bit类型--ug902里讲过
#include "ap_int.h"然后使用ap_int
在硬件函数中,使用fixed-point数据类型代替传统的浮点型。#include
III、数组设置
编译器一般会将很大的数组映射到BRAM(最多有2个端口)意味着不能并行访问,一种方法是用ARRAY_PARTITION优化指令来打破2个端口访问的限制。
但当数组维数很多或数组很大时,切分数组是有讲究的。如果选择complete切分,虽然一个时钟内可访问全部元素,但会使用大量的资源;所以合理选择要切分的维度和份数。
int A[3][4];
int B[4][5];
#pragma HLS ARRAY_PARTITION variable=A dim=2 complete
#pragma HLS ARRAY_PARTITION variable=B dim=1 complete
ROW_WISE: for (int i = 0; i < 3; i++) {
COL_WISE : for (int j = 0; j < 5; j++) {
#pragma HLS PIPELINE
int result = 0;
COMPUTE_LOOP: for (int k = 0; k < 4; k++) {
result += A[i ][ k] * B[k ][ j];
}
C[i][ j] = result;
}
}
注意这个例子:PIPELINE的应用意味着ROW_WISE和COL_WISE两个循环会自动FLATTEN,COMPUTE_LOOP会自动完全UNROLLED!!!这个例子因为是A的每行的数据乘以B的每列的数据,所以将A的列完全展开dim=2
将B的行完全展开dim=1.dim如果等于0表示将所有维度完完全全展开成一维数组!!!
int A[3 * 4];
int B[4 * 2];
#pragma HLS ARRAY_PARTITION variable=A dim=1 cyclic factor=4
#pragma HLS ARRAY_PARTITION variable=B dim=1 block factor=4
ROW_WISE: for (int i = 0; i < 3; i++) {
COL_WISE : for (int j = 0; j < 2; j++) {
#pragma HLS PIPELINE
int result = 0;
COMPUTE_LOOP: for (int k = 0; k < 4; k++) {
result += A[i * 4 + k] * B[k * 2 + j];
}
C[i* 2 + j] = result;
}
}
其实ug902也看过这样的例子,但之前没怎么懂。现在理解为下:
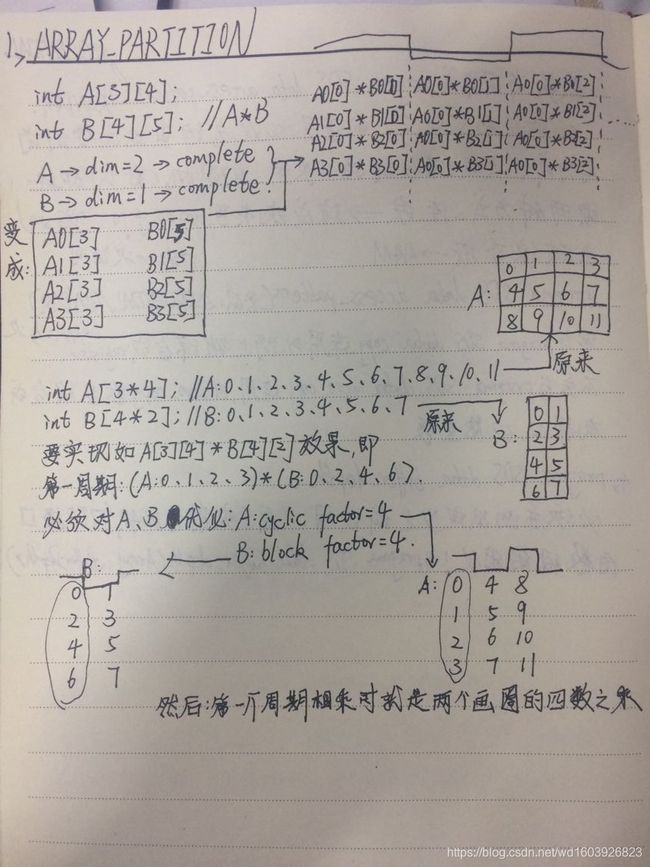
数组访问优化除了ARRAY_PARTITION,还可以使用局部寄存器来缓冲数据而减少所需的访问端口来提高性能。
IV、循环
对于循环的优化要么是PIPELINE要么是UNROLL,默认情况是loop是没有任何优化的。每写一个循环就给其命名是一个好习惯!
loop Pipelining:
对循环PIPELINE时,#pragma HLS PIPELINE指令要放在loop内。II表示下一次循环开始点与上一次循环开始点的时钟差,当使用PIPELINE优化时,编译器默认是用II=1优化。
但是当每次循环之间有依赖时,II=1的可能做不到了。注意之前已经说过PIPELINE时,下一级的循环会自动unroll。
loop Unrolling:
对循环展开可以完全展开(循环上限必须是常数)也可以部分展开(循环上限可以是变量),但展开会耗费硬件资源要权衡。所以通常来说,当循环体操作很少或者循环总次数很少时可以用一下这个优化。
就像循环之间数据依赖性影响Pipeline的II一样,也会影响unroll。
loop Dependencies:
真的会严重影响Pipeline和Unroll优化指令
Nested Loops
嵌套循环中应用pipeline优化时,编译器会自动应用flatten优化。但flatten优化是有条件的:完美型嵌套loop(只有内循环有函数体,内外循环之间没有,且循环上限都是常数)、半完美
型loop(只有内循环有循环体,循环之间没有循环体,内循环上限是常数,外循环上限是变量)(让内层循环上限为常数是一个好的编程习惯)
Sequential Loops
当函数体中有多个循环时(注意不是多层,是多个),默认每个循环之间是顺序执行的。这是可以应用Dataflow优化即让循环不是完完全全等上一个循环结束后再执行。
V、任务并行Dataflow
要让任务(多个硬件函数调用时、多个loops执行时)尽可能并行,可以使用Dataflow优化指令。如果在Dataflow优化范围内,有数组是按顺序访问的,那么可以使用
#pragma HLS STREAM variable= depth=这个优化数组,即表示此数组是流数据,是在FIFO中且depth会让数组所占内存大大减小(所以对hls::stream的局部变量也可以这样优化)。因为默认情况下数组其实是在RAM中随机访问的。
但是这个depth的意义和计算:https://blog.csdn.net/maxwell2ic/article/details/81110963 这个大神写得很通俗易懂。
对于Dataflow优化其实有标准形式的:
对于函数:
a、请在dataflow优化区域对于局部变量要么使用non-static scalar/array/pointer类型或者static hls::strram类型(如P42的例子所示);
b、每个函数必须只能前向传递数据:函数1读数据1产生数据2,函数2读数据2产生数据3,函数3读数据3产生数据4.....
c、数组或者hls::stream变量只能由一个函数产生然后由一个函数使用。(我想因为它们是流,只能被使用一次)
d、大函数的形参变量(即dataflow优化范围外)在dataflow区域要么被读/写,如果读+写,请确保读在写之前发生
e、局部变量(如第二点所述的数据2和数据3)必须确保写在读之前!
对于每个loop:
a、必须初始化为0
b、循环的上限无论是常数还是变量,反正在loop内不能改变这个上限
c、每次递增1
阻碍Dataflow优化效果的绊脚石:
a、数组或hls::stream变量不是一个函数产生然后由一个函数使用,比如两个函数使用了。
b、任务绕行---ug902里有讲
c、任务之间有相互回馈
d、任务之间有条件
e、loop中有很多条件跳出或者很多条件语句(可是我记得哪里讲过要我多用条件语句?)
想起来了:


 这是不是说在没有dataflow优化的地方,在loop中可以多用条件语句来增加访问性能?!
这是不是说在没有dataflow优化的地方,在loop中可以多用条件语句来增加访问性能?!
VI、第4章使用外部I/O口好像我暂时用不到?!P45
VII、导出库
使用Sdx一般是生成elf即sd_card里的那些东西能够在板子上直接跑起来;也可以生成库函数被别的工程调用,但是注意库函数不是线程安全的,所以库函数只能被一个线程调用(这个线程下可以有很多子线程)。
a、共享库
共享库只能在linux系统下可以生成,所以这也是为什么xilinx强烈建议使用linux的原因之一。哈哈还好我没在windows上使用。
参考samples/libmatrix/build这个例子。其它选项和cpu上的生成库函数一样,如PIC,如会生成.so文件。当然sd_card文件夹也会生成。
调用这个库时请这样使用:
b、compiling and linking against a library
c、导出共享库
VIII、Sdsoc自带的API (sds_lib中的)P55
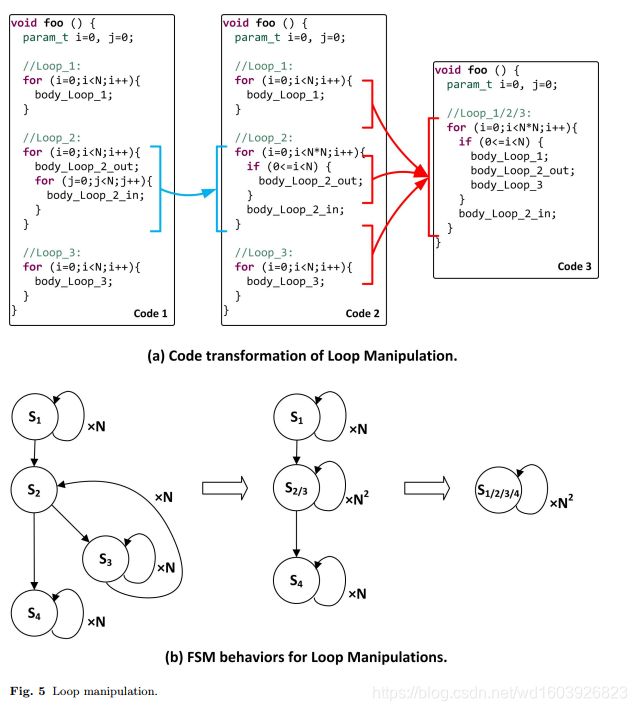
网友问的loop flatten,我觉得用代码更好理解:左边是未优化源码,中间是相当于loop flatten优化,右边是相当于loop merge优化。我找的这个图片很清晰的讲了什么叫loop flatten。