Java学习:从入门到精通week4
一.File类、递归
1.File类
1.1 概述
java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。
file-->文件
directory-->文件夹/目录
path-->路径
方法
1.2静态方法


 路径描述:
路径描述: 
1.3构造方法
1)第一种


2)第二种

3) 第三种

1.4常用方法
1)获取:
获取绝对路径
获取路径

获取路径结尾

获取文件长度


文件夹没有该文件,返回0:

2)判断



3)创建和删除

public class FileCreateDelete {
public static void main(String[] args) throws IOException {
// 文件的创建
File f = new File("aaa.txt");
System.out.println("是否存在:"+f.exists()); // false
System.out.println("是否创建:"+f.createNewFile()); // true
System.out.println("是否存在:"+f.exists()); // true
// 目录的创建
File f2= new File("newDir");
System.out.println("是否存在:"+f2.exists());// false
System.out.println("是否创建:"+f2.mkdir()); // true
System.out.println("是否存在:"+f2.exists());// true
// 创建多级目录
File f3= new File("newDira\\newDirb");
System.out.println(f3.mkdir());// false
File f4= new File("newDira\\newDirb");
System.out.println(f4.mkdirs());// true
// 文件的删除
System.out.println(f.delete());// true
// 目录的删除
System.out.println(f2.delete());// true
System.out.println(f4.delete());// false
}
}1.5目录的遍历

public class FileFor {
public static void main(String[] args) {
File dir = new File("d:\\java_code");
//获取当前目录下的文件以及文件夹的名称。
String[] names = dir.list();
for(String name : names){
System.out.println(name);
}
//获取当前目录下的文件以及文件夹对象,只要拿到了文件对象,那么就可以获取更多信息
File[] files = dir.listFiles();
for (File file : files) {
System.out.println(file);
}
}
}打印结果( 隐藏的文件也会被打印出来,如下已经把博客.txt隐藏):


调用listFiles方法的File对象,表示的必须是实际存在的目录,否则返回null,无法进行遍历。
2.递归
2.1概述
-
递归:指在当前方法内调用自己的这种现象。
-
递归的分类:
-
递归分为两种,直接递归和间接递归。
-
直接递归称为方法自身调用自己。
-
间接递归可以A方法调用B方法,B方法调用C方法,C方法调用A方法。
-
-
注意事项:
-
递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出。
-
在递归中虽然有限定条件,但是递归次数不能太多。否则也会发生栈内存溢出。
-
构造方法,禁止递归
-
2.2 递归累加求和
计算1 ~ n的和
分析:num的累和 = num + (num-1)的累和,所以可以把累和的操作定义成一个方法,递归调用。
代码实现:
public class DiGuiDemo {
public static void main(String[] args) {
//计算1~num的和,使用递归完成
int num = 5;
// 调用求和的方法
int sum = getSum(num);
// 输出结果
System.out.println(sum);
}
/*
通过递归算法实现.
参数列表:int
返回值类型: int
*/
public static int getSum(int num) {
/*
num为1时,方法返回1,
相当于是方法的出口,num总有是1的情况
*/
if(num == 1){
return 1;
}
/*
num不为1时,方法返回 num +(num-1)的累和
递归调用getSum方法
*/
return num + getSum(num-1);
}
}2.3递归求阶乘
求n!
分析:这与累和类似,只不过换成了乘法运算,学员可以自己练习,需要注意阶乘值符合int类型的范围。
代码实现:
public static void main(String[] args) {
int n = 3;
// 调用求阶乘的方法
int value = getValue(n);
// 输出结果
System.out.println("阶乘为:"+ value);
}
/*
通过递归算法实现.
参数列表:int
返回值类型: int
*/
public static int getValue(int n) {
// 1的阶乘为1
if (n == 1) {
return 1;
}
/*
n不为1时,方法返回 n! = n*(n-1)!
递归调用getValue方法
*/
return n * getValue(n - 1);
}当返回值超过基础类型的范围时,返回0。
2.4递归打印多级目录
分析:多级目录的打印,就是当目录的嵌套。遍历之前,无从知道到底有多少级目录,所以我们还是要使用递归实现。
代码实现:
public class DiGuiDemo2 {
public static void main(String[] args) {
// 创建File对象
File dir = new File("D:\\aaa");
// 调用打印目录方法
printDir(dir);
}
public static void printDir(File dir) {
// 获取子文件和目录
File[] files = dir.listFiles();
// 循环打印
/*
判断:
当是文件时,打印绝对路径.
当是目录时,继续调用打印目录的方法,形成递归调用.
*/
for (File file : files) {
// 判断
if (file.isFile()) {
// 是文件,输出文件绝对路径
System.out.println("文件名:"+ file.getAbsolutePath());
} else {
// 是目录,输出目录绝对路径
System.out.println("目录:"+file.getAbsolutePath());
// 继续遍历,调用printDir,形成递归
printDir(file);
}
}
}
}3.文件过滤器 和Lambda优化
3.1 文件搜索
搜索D:\aaa 目录中的.java 文件。
分析:
-
目录搜索,无法判断多少级目录,所以使用递归,遍历所有目录。
-
遍历目录时,获取的子文件,通过文件名称,判断是否符合条件。
代码实现:
public class DiGuiDemo3 {
public static void main(String[] args) {
// 创建File对象
File dir = new File("D:\\aaa");
// 调用打印目录方法
printDir(dir);
}
public static void printDir(File dir) {
// 获取子文件和目录
File[] files = dir.listFiles();
// 循环打印
for (File file : files) {
if (file.isFile()) {
// 是文件,判断文件名并输出文件绝对路径
if (file.getName().endsWith(".java")) {
System.out.println("文件名:" + file.getAbsolutePath());
}
} else {
// 是目录,继续遍历,形成递归
printDir(file);
}
}
}
}3.2文件过滤器优化
java.io.FileFilter是一个接口,是File的过滤器。 该接口的对象可以传递给File类的listFiles(FileFilter) 作为参数, 接口中只有一个方法。
boolean accept(File pathname) :测试pathname是否应该包含在当前File目录中,符合则返回true。
分析:
-
接口作为参数,需要传递子类对象,重写其中方法。我们选择匿名内部类方式,比较简单。
-
accept方法,参数为File,表示当前File下所有的子文件和子目录。保留住则返回true,过滤掉则返回false。保留规则:-
要么是.java文件。
-
要么是目录,用于继续遍历。
-
-
通过过滤器的作用,
listFiles(FileFilter)返回的数组元素中,子文件对象都是符合条件的,可以直接打印。
代码实现:
public class DiGuiDemo4 {
public static void main(String[] args) {
File dir = new File("D:\\aaa");
printDir2(dir);
}
public static void printDir2(File dir) {
// 匿名内部类方式,创建过滤器子类对象
File[] files = dir.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".java")||pathname.isDirectory();
}
});
// 循环打印
for (File file : files) {
if (file.isFile()) {
System.out.println("文件名:" + file.getAbsolutePath());
} else {
printDir2(file);
}
}
}
} 
3.3Lambda优化
public static void printDir3(File dir) {
// lambda的改写
File[] files = dir.listFiles(f ->{
return f.getName().endsWith(".java") || f.isDirectory();
});
// 循环打印
for (File file : files) {
if (file.isFile()) {
System.out.println("文件名:" + file.getAbsolutePath());
} else {
printDir3(file);
}
}
}二.IO、字节流、字符流
1.IO
1.1概述
生活中,你肯定经历过这样的场景。当你编辑一个文本文件,忘记了ctrl+s ,可能文件就白白编辑了。当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里。那么数据都是在哪些设备上的呢?键盘、内存、硬盘、外接设备等等。
我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为输入input 和输出output ,即流向内存是输入流,流出内存的输出流。
Java中I/O操作主要是指使用java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。

1.2 IO的分类
根据数据的流向分为:输入流和输出流。
-
输入流 :把数据从
其他设备上读取到内存中的流。 -
输出流 :把数据从
内存中写出到其他设备上的流。
格局数据的类型分为:字节流和字符流。
-
字节流 :以字节为单位,读写数据的流。
-
字符流 :以字符为单位,读写数据的流。
2.字节流
2.1 一切皆为字节
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
2.2 字节输出流【OutputStream】
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
共性成员方法:
-
public void close():关闭此输出流并释放与此流相关联的任何系统资源。 -
public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。 -
public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。 -
public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。 -
public abstract void write(int b):将指定的字节输出流。
close方法,当完成流的操作时,必须调用此方法,释放系统资源
构造方法:

-
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。 -
public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。

1)写入流
 2)一次写入多个字节
2)一次写入多个字节


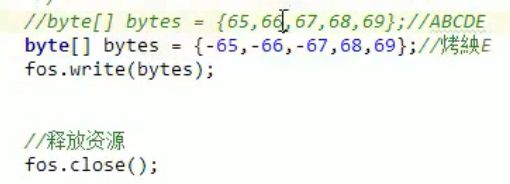
把字节数组的某一长度写入文件:

写入字符:

3)续写
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能继续添加新数据呢?
-
public FileOutputStream(File file, boolean append): 创建文件输出流以写入由指定的 File对象表示的文件。 -
public FileOutputStream(String name, boolean append): 创建文件输出流以指定的名称写入文件。
这两个构造方法,参数中都需要传入一个boolean类型的值,`true` 表示追加数据,`false` 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了。

4)换行
-
回车符
\r和换行符\n:-
回车符:回到一行的开头(return)。
-
换行符:下一行(newline)。
-
-
系统中的换行:
-
Windows系统里,每行结尾是
回车+换行,即\r\n; -
Unix系统里,每行结尾只有
换行,即\n; -
Mac系统里,每行结尾是
回车,即\r。从 Mac OS X开始与Linux统一。
-
2.4字节输入流【InputStream】
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
共性成员方法:
-
public void close():关闭此输入流并释放与此流相关联的任何系统资源。 -
public abstract int read(): 从输入流读取数据的下一个字节。 -
public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
构造方法:

-
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。 -
FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出FileNotFoundException 。
1)读取字节:



每读取一次,往后移动一位,下一次将会读取对于位数的字节
可以用循环来表示。
2)读取多个字节(数组)


文本为 ABCDE

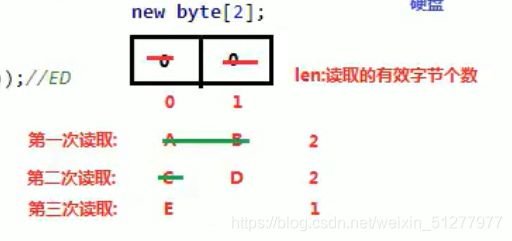
分析:
读取第一次A和D,返回值为字节个数2:
读取第二次C和D,返回值为字节个数2;
读取第三次E,第二个覆盖了前面的D,此时返回值为他的真实字节个数1;
如果读取第四次的话,会打印出ED,此时返回值为-1.
注意:读取单个字节的read()返回值为读取字节的表示数字的10进制数字,而读取一个字节数组的返回值是字节的个数,也就是数组的单元个数。

2.5文件复制练习
public class Copy {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 指定数据源
FileInputStream fis = new FileInputStream("D:\\test.jpg");
// 1.2 指定目的地
FileOutputStream fos = new FileOutputStream("test_copy.jpg");
// 2.读写数据
// 2.1 定义数组
byte[] b = new byte[1024];
// 2.2 定义长度
int len;
// 2.3 循环读取
while ((len = fis.read(b))!=-1) {
// 2.4 写出数据
fos.write(b, 0 , len);
}
// 3.关闭资源
fos.close();
fis.close();
//先关写再关读
}
}3.字符流
当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
3.1 字符输入流【Reader】
`java.io.Reader`抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
共性成员方法:
-
public void close():关闭此流并释放与此流相关联的任何系统资源。 -
public int read(): 从输入流读取一个字符。 -
public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。
构造方法:

-
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。 -
FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于FileInputStream
1)读取单个字符:

2) 读取多个字符:

3.3 字符输出流【Writer】
`java.io.Writer `抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
共性成员方法:
-
void write(int c)写入单个字符。 -
void write(char[] cbuf)写入字符数组。 -
abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。 -
void write(String str)写入字符串。 -
void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。 -
void flush()刷新该流的缓冲。 -
void close()关闭此流,但要先刷新它。
构造方法:

-
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。 -
FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。
1)写入单个字符

注意:
close和flush都有刷新数据的功能,在字节流中不使用也会刷新,但在字符流中不使用数据不会被写入,会停留在内存缓冲区中。
close关闭后,流已经从内存消失,无法再对文件对象读写,但flush缓冲可以。
2)写入多个字符

3)续写(与字节流大同小异)
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("黑马");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("程序员");
// 关闭资源
fw.close();
}
}
输出结果:
黑马
程序员4.IO异常的处理__tyy-catch-finally处理
4.1JDK.1.7之前的处理


4.2JDK7的新特性/处理(了解)


不需要再去finally内镶嵌try-catch,这样用起来就很爽了。
4.3JDK9的新特性/处理(了解)


5.属性集
5.1 概述
java.util.Properties 继承于Hashtable ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。该类也被许多Java类使用,比如获取系统属性时,System.getProperties 方法就是返回一个Properties对象。
5.2 Properties类

注意:

1)数据储存和遍历


2)把集合数据写入硬盘



执行结果:

把集合中的数据写到fw文件中,并添加注释save date,时间为自动添加的内容。
3)从字节输入流中读取键值对



一般只用于字符流,使用字节流可能出现乱码。
二.缓冲流、转换流、序列化流、打印流
1.缓冲流
1.1概述
缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类:
-
字节缓冲流:
BufferedInputStream,BufferedOutputStream -
字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
1.2 字节缓冲流
构造方法
-
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。 -
public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
1)输出流:



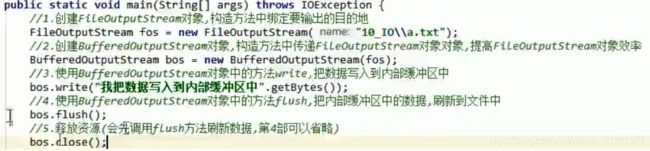 2)输入流
2)输入流



读取单个字节:
读取多个字节: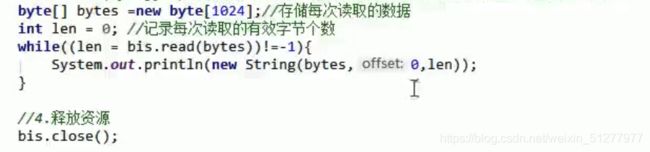
1.3 字符缓冲流
构造方法
-
public BufferedReader(Reader in):创建一个 新的缓冲输入流。 -
public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
1)输出流


特有的成员方法:



2)输入流


特有成员方法:
需要注意的是返回值达到末尾时不是返回-1而是null。
使用特有读取一行字符:


也可以循环:
1.4文本排序案例
请将文本信息恢复顺序。
3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必得裨补阙漏,有所广益。
8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
4.将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
9.今当远离,临表涕零,不知所言。
6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。案例分析:
代码实现:
public class BufferedTest {
public static void main(String[] args) throws IOException {
// 创建map集合,保存文本数据,键为序号,值为文字
HashMap lineMap = new HashMap<>();
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 读取数据
String line = null;
while ((line = br.readLine())!=null) {
// 解析文本
String[] split = line.split("\\.");
// 保存到集合
lineMap.put(split[0],split[1]);
}
// 释放资源
br.close();
// 遍历map集合
for (int i = 1; i <= lineMap.size(); i++) {
String key = String.valueOf(i);
// 获取map中文本
String value = lineMap.get(key);
// 写出拼接文本
bw.write(key+"."+value);
// 写出换行
bw.newLine();
}
// 释放资源
bw.close();
}
} 2.转换流
2.1 字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)--字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
-
字符编码
Character Encoding: 就是一套自然语言的字符与二进制数之间的对应规则。编码表:生活中文字和计算机中二进制的对应规则
字符集
-
字符集
Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
-
ASCII字符集 :
-
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
-
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
-
-
ISO-8859-1字符集:
-
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
-
ISO-8859-1使用单字节编码,兼容ASCII编码。
-
-
GBxxx字符集:
-
GB就是国标的意思,是为了显示中文而设计的一套字符集。
-
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
-
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
-
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
-
-
Unicode字符集 :
-
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
-
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
-
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
-
128个US-ASCII字符,只需一个字节编码。
-
拉丁文等字符,需要二个字节编码。
-
大部分常用字(含中文),使用三个字节编码。
-
其他极少使用的Unicode辅助字符,使用四字节编码。
-
-
2.2编码引出的问题
在IDEA中,使用FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("E:\\File_GBK.txt");
int read;
while ((read = fileReader.read()) != -1) {
System.out.print((char)read);
}
fileReader.close();
}
}
输出结果:
���2.3 InputStreamReader类(字节-->字符的桥梁)
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
共性成员方法大同小异。
构造方法
-
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。 -
InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。

指定码表读取:
public class ReaderDemo2 {
public static void main(String[] args) throws IOException {
// 定义文件路径,文件为gbk编码
String FileName = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK");
// 定义变量,保存字符
int read;
// 使用默认编码字符流读取,乱码
while ((read = isr.read()) != -1) {
System.out.print((char)read); // ��Һ�
}
isr.close();
// 使用指定编码字符流读取,正常解析
while ((read = isr2.read()) != -1) {
System.out.print((char)read);// 大家好
}
isr2.close();
}
}2.4OutputStreamWriter类(字符-->字节的桥梁)
转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
-
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。 -
OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。

指定码表写出:
public class OutputDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}3. 序列化
3.1 概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。
图解序列化和反序列化:
3.2 ObjectOutputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
构造方法
-
public ObjectOutputStream(OutputStream out): 创建一个指定OutputStream的ObjectOutputStream。
 序列化:
序列化:
先定义一个自定义类:

在使用之前,先了解:
所以要让Person类先实现Serializable接口(为一个标记型接口)。 
打开文件(为二进制文本):
3.3 ObjectInputStream类
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
构造方法
-
public ObjectInputStream(InputStream in): 创建一个指定InputStream的ObjectInputStream。

反序列化:

3.4transient关键字(瞬态关键字)
被静态关键字static和瞬态关键字transient修饰成员变量无法序列化。
用于方式成员变量被(反)序列化。
3.5序列化集合案例
-
将存有多个自定义对象的集合序列化操作,保存到
list.txt文件中。 -
反序列化
list.txt,并遍历集合,打印对象信息。

代码实现:
public class SerTest {
public static void main(String[] args) throws Exception {
// 创建 学生对象
Student student = new Student("老王", "laow");
Student student2 = new Student("老张", "laoz");
Student student3 = new Student("老李", "laol");
ArrayList arrayList = new ArrayList<>();
arrayList.add(student);
arrayList.add(student2);
arrayList.add(student3);
// 序列化操作
// serializ(arrayList);
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("list.txt"));
// 读取对象,强转为ArrayList类型
ArrayList list = (ArrayList)ois.readObject();
for (int i = 0; i < list.size(); i++ ){
Student s = list.get(i);
System.out.println(s.getName()+"--"+ s.getPwd());
}
}
private static void serializ(ArrayList arrayList) throws Exception {
// 创建 序列化流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("list.txt"));
// 写出对象
oos.writeObject(arrayList);
// 释放资源
oos.close();
}
} 4. 打印流
4.1 概述
平时我们在控制台打印输出,是调用print方法和println方法完成的,这两个方法都来自于java.io.PrintStream类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
4.2 PrintStream类
构造方法
-
public PrintStream(String fileName): 使用指定的文件名创建一个新的打印流。

构造举例,代码如下:
PrintStream ps = new PrintStream("ps.txt");


改变打印流向:

在控制台会打印出“我是在控制台输出”,在文件内打印出“我在打印流目的地中输出”。
四.网络编程
1.网络编程入门
1.1软件结构


1.2 网络通信协议
-
网络通信协议:通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。
-
TCP/IP协议: 传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),是Internet最基本、最广泛的协议。它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。它的内部包含一系列的用于处理数据通信的协议,并采用了4层的分层模型,每一层都呼叫它的下一层所提供的协议来完成自己的需求
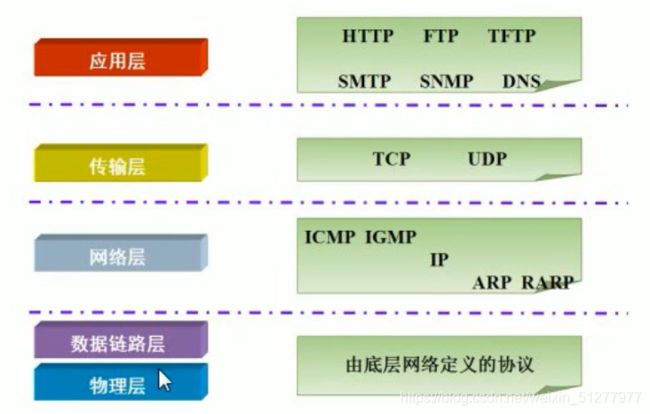
上图中,TCP/IP协议中的四层分别是应用层、传输层、网络层和链路层,每层分别负责不同的通信功能。 链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。 网络层:网络层是整个TCP/IP协议的核心,它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。 运输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。 应用层:主要负责应用程序的协议,例如HTTP协议、FTP协议等。
1.3 协议分类
通信的协议还是比较复杂的,java.net 包中包含的类和接口,它们提供低层次的通信细节。我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节。
java.net 包中提供了两种常见的网络协议的支持:
-
UDP:用户数据报协议(User Datagram Protocol)。UDP是无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输例如视频会议都使用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议。UDP的交换过程如下图所示。

特点:数据被限制在64kb以内,超出这个范围就不能发送了。
数据报(Datagram):网络传输的基本单位
-
TCP:传输控制协议 (Transmission Control Protocol)。TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。
在TCP连接中必须要明确客户端与服务器端,由客户端向服务端发出连接请求,每次连接的创建都需要经过“三次握手”。
-
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
-
第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
-
第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
-
第三次握手,客户端再次向服务器端发送确认信息,确认连接。整个交互过程如下图所示。
-
-

完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等。
1.4 网络编程三要素
协议
-
协议:计算机网络通信必须遵守的规则,已经介绍过了,不再赘述。
IP地址
-
IP地址:指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给一个网络中的计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”。
IP地址分类
-
IPv4:是一个32位的二进制数,通常被分为4个字节,表示成
a.b.c.d的形式,例如192.168.65.100。其中a、b、c、d都是0~255之间的十进制整数,那么最多可以表示42亿个。 -
IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得IP的分配越发紧张。
为了扩大地址空间,拟通过IPv6重新定义地址空间,采用128位地址长度,每16个字节一组,分成8组十六进制数,表示成
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,号称可以为全世界的每一粒沙子编上一个网址,这样就解决了网络地址资源数量不够的问题。
常用命令
-
查看本机IP地址,在控制台输入:
ipconfig-
检查网络是否连通,在控制台输入:
ping 空格 IP地址
ping 220.181.57.216特殊的IP地址
-
本机IP地址:
127.0.0.1、localhost。
端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了。
-
端口号:用两个字节表示的整数,它的取值范围是0~65535。其中,0~1023之间的端口号用于一些知名的网络服务和应用,普通的应用程序需要使用1024以上的端口号。如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败。
利用协议+IP地址+端口号 三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互。

2.TCP通信程序
2.1 概述
TCP通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端(Client)与服务端(Server)。
两端通信时步骤:
-
服务端程序,需要事先启动,等待客户端的连接。
-
客户端主动连接服务器端,连接成功才能通信。服务端不可以主动连接客户端.

在Java中,提供了两个类用于实现TCP通信程序:
-
客户端:
java.net.Socket类表示。创建Socket对象,向服务端发出连接请求,服务端响应请求,两者建立连接开始通信。 -
服务端:
java.net.ServerSocket类表示。创建ServerSocket对象,相当于开启一个服务,并等待客户端的连接。



2.2 Socket类
Socket 类:该类实现客户端套接字,套接字指的是两台设备之间通讯的端点。
构造方法
-
public Socket(String host, int port):创建套接字对象并将其连接到指定主机上的指定端口号。如果指定的host是null ,则相当于指定地址为回送地址。小贴士:回送地址(127.x.x.x) 是本机回送地址(Loopback Address),主要用于网络软件测试以及本地机进程间通信,无论什么程序,一旦使用回送地址发送数据,立即返回,不进行任何网络传输。
成员方法
-
public InputStream getInputStream(): 返回此套接字的输入流。-
如果此Scoket具有相关联的通道,则生成的InputStream 的所有操作也关联该通道。
-
关闭生成的InputStream也将关闭相关的Socket。
-
-
public OutputStream getOutputStream(): 返回此套接字的输出流。-
如果此Scoket具有相关联的通道,则生成的OutputStream 的所有操作也关联该通道。
-
关闭生成的OutputStream也将关闭相关的Socket。
-
-
public void close():关闭此套接字。-
一旦一个socket被关闭,它不可再使用。
-
关闭此socket也将关闭相关的InputStream和OutputStream 。
-
-
public void shutdownOutput(): 禁用此套接字的输出流。-
任何先前写出的数据将被发送,随后终止输出流。
-


2.3 ServerSocket类
ServerSocket类:这个类实现了服务器套接字,该对象等待通过网络的请求。
构造方法
-
public ServerSocket(int port):使用该构造方法在创建ServerSocket对象时,就可以将其绑定到一个指定的端口号上,参数port就是端口号。
构造举例,代码如下:
ServerSocket server = new ServerSocket(6666);成员方法
-
public Socket accept():侦听并接受连接,返回一个新的Socket对象,用于和客户端实现通信。该方法会一直阻塞直到建立连接。


3.文件上传案例
3.1分析




3.2代码实现
1)客户端 
public class FileUPload_Client {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 创建输入流,读取本地文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
// 1.2 创建输出流,写到服务端
Socket socket = new Socket("localhost", 6666);
BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());
//2.写出数据.
byte[] b = new byte[1024 * 8 ];
int len ;
while (( len = bis.read(b))!=-1) {
bos.write(b, 0, len);
bos.flush();
}
System.out.println("文件发送完毕");
// 3.释放资源
bos.close();
socket.close();
bis.close();
System.out.println("文件上传完毕 ");
}
}2)服务器端
public class FileUPload_Client {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 创建输入流,读取本地文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
// 1.2 创建输出流,写到服务端
Socket socket = new Socket("localhost", 6666);
BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());
//2.写出数据.
byte[] b = new byte[1024 * 8 ];
int len ;
while (( len = bis.read(b))!=-1) {
bos.write(b, 0, len);
bos.flush();
}
System.out.println("文件发送完毕");
// 3.释放资源
bos.close();
socket.close();
bis.close();
System.out.println("文件上传完毕 ");
}
}3.3文件上传优化分析
-
文件名称写死的问题
服务端,保存文件的名称如果写死,那么最终导致服务器硬盘,只会保留一个文件,建议使用系统时间优化,保证文件名称唯一,代码如下:
FileOutputStream fis = new FileOutputStream(System.currentTimeMillis()+".jpg") // 文件名称
BufferedOutputStream bos = new BufferedOutputStream(fis);-
循环接收的问题
服务端,指保存一个文件就关闭了,之后的用户无法再上传,这是不符合实际的,使用循环改进,可以不断的接收不同用户的文件,代码如下:
// 每次接收新的连接,创建一个Socket
while(true){
Socket accept = serverSocket.accept();
......
}-
效率问题
服务端,在接收大文件时,可能耗费几秒钟的时间,此时不能接收其他用户上传,所以,使用多线程技术优化,代码如下:
while(true){
Socket accept = serverSocket.accept();
// accept 交给子线程处理.
new Thread(() -> {
......
InputStream bis = accept.getInputStream();
......
}).start();
}优化实现:
public class FileUpload_Server {
public static void main(String[] args) throws IOException {
System.out.println("服务器 启动..... ");
// 1. 创建服务端ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
// 2. 循环接收,建立连接
while (true) {
Socket accept = serverSocket.accept();
/*
3. socket对象交给子线程处理,进行读写操作
Runnable接口中,只有一个run方法,使用lambda表达式简化格式
*/
new Thread(() -> {
try (
//3.1 获取输入流对象
BufferedInputStream bis = new BufferedInputStream(accept.getInputStream());
//3.2 创建输出流对象, 保存到本地 .
FileOutputStream fis = new FileOutputStream(System.currentTimeMillis() + ".jpg");
BufferedOutputStream bos = new BufferedOutputStream(fis);) {
// 3.3 读写数据
byte[] b = new byte[1024 * 8];
int len;
while ((len = bis.read(b)) != -1) {
bos.write(b, 0, len);
}
//4. 关闭 资源
bos.close();
bis.close();
accept.close();
System.out.println("文件上传已保存");
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}
3.4信息回写分析图解
前四步与基本文件上传一致.
-
【服务端】获取输出流,回写数据。
-
【客户端】获取输入流,解析回写数据。
回写实现:
1)服务器端
public class FileUpload_Server {
public static void main(String[] args) throws IOException {
System.out.println("服务器 启动..... ");
// 1. 创建服务端ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
// 2. 循环接收,建立连接
while (true) {
Socket accept = serverSocket.accept();
/*
3. socket对象交给子线程处理,进行读写操作
Runnable接口中,只有一个run方法,使用lambda表达式简化格式
*/
new Thread(() -> {
try (
//3.1 获取输入流对象
BufferedInputStream bis = new BufferedInputStream(accept.getInputStream());
//3.2 创建输出流对象, 保存到本地 .
FileOutputStream fis = new FileOutputStream(System.currentTimeMillis() + ".jpg");
BufferedOutputStream bos = new BufferedOutputStream(fis);
) {
// 3.3 读写数据
byte[] b = new byte[1024 * 8];
int len;
while ((len = bis.read(b)) != -1) {
bos.write(b, 0, len);
}
// 4.=======信息回写===========================
System.out.println("back ........");
OutputStream out = accept.getOutputStream();
out.write("上传成功".getBytes());
out.close();
//================================
//5. 关闭 资源
bos.close();
bis.close();
accept.close();
System.out.println("文件上传已保存");
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}2)客户端
public class FileUpload_Client {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 创建输入流,读取本地文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
// 1.2 创建输出流,写到服务端
Socket socket = new Socket("localhost", 6666);
BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());
//2.写出数据.
byte[] b = new byte[1024 * 8 ];
int len ;
while (( len = bis.read(b))!=-1) {
bos.write(b, 0, len);
}
// 关闭输出流,通知服务端,写出数据完毕
socket.shutdownOutput();
System.out.println("文件发送完毕");
// 3. =====解析回写============
InputStream in = socket.getInputStream();
byte[] back = new byte[20];
in.read(back);
System.out.println(new String(back));
in.close();
// ============================
// 4.释放资源
socket.close();
bis.close();
}
}4.模拟B\S服务器(扩展知识点)
模拟网站服务器,使用浏览器访问自己编写的服务端程序,查看网页效果。


具体视频讲解:
链接:https://pan.baidu.com/s/1IV4py_rpmAAqH3xgOUdc7A
提取码:tao2
五.函数式接口
1.函数式接口
1.1概述
函数式接口在Java中是指:有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导。
备注:“语法糖”是指使用更加方便,但是原理不变的代码语法。例如在遍历集合时使用的for-each语法,其实底层的实现原理仍然是迭代器,这便是“语法糖”。从应用层面来讲,Java中的Lambda可以被当做是匿名内部类的“语法糖”,但是二者在原理上是不同的。
1.2格式
只要确保接口中有且仅有一个抽象方法即可:
修饰符 interface 接口名称{
public abstract 返回值类型 方法名称(可选参数信息);
//
其他非抽象方法内容
}1.3@FunctionalInterface注解
与@Override注解的作用类似,Java8中专门为函数式接口引入了一个新的注解:@FunctionalInterface。该注解可用于一个接口的定义上:


1.4函数式接口的使用
一般可作为参数和返回值:

2.函数式编程
2.1Lambda的延迟执行
1)性能浪费的日志案例:

2)使用Lambda优化案例:




2.2使用Lambda作为参数和返回值
1)作为参数
如果抛开实现原理不说,Java中的Lambda表达式可以被当作是匿名内部类的替代品。如果方法的参数是一个函数式接口类型,那么就可以使用Lambda表达式进行替代。使用Lambda表达式作为方法参数,其实就是使用函数式接口作为方法参数。
例如java.lang.Runnable接口就是一个函数式接口,假设有一个startThread方法使用该接口作为参数,那么就可以使用Lambda进行传参。这种情况其实和Thread类的构造方法参数为Runnable没有本质区别。

 优化代码:
优化代码:
2)作为返回值




3.常用的函数式接口
JDK提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在java.util.function包中被提供。下面是最简单的几个接口及使用示例。
3.1Supplier接口


Supplier练习:获取数组元素最大值:
 3.2Consumer接口
3.2Consumer接口
1)抽象方法


 2)默认方法
2)默认方法

抽象方法:
andThen方法(修改自定义方法即可):
Consumer练习: 格式化打印信息


3.3Predicate 接口
1)抽象方法

 2)默认方法
2)默认方法
先了解一下逻辑运算符:

①.and方法


抽象方法:
 默认方法and:
默认方法and:

②or ③negate
以上两者方法用法与and相同,总而言之,三者就是&&、||、!的代码表示。
代码实现:
or:

negate:

3.4Funtion接口
1)抽象方法


2)默认方法
andThen方法:与Consumer接口作用相同
![]()
使用如下:
Funtion练习:自定义函数模型拼接


先将第一个参数传给第二个使用,然后返回值给第三个使用......
小结:get()无参数有返回值,accept(T)有参数无返回值,test(T)有参数有返回值,apply(T)有参数有返回值。
六.Stream流、方法引用