MySQL CDC技术方案梳理
本篇主要探讨MySQL数据同步的各类常见技术方案及优劣势对比分析,从而更加深层次的理解方案,进而在后续的实际业务中,更好的选择方案。
1 CDC概念
CDC即Change Data Capture,变更数据捕获,即当数据发生变更时,能够实时或准实时的捕获到数据的变化,以MySQL为例,产生数据变更的操作有insert,update,delete。CDC技术就时在数据变更时,能够以安全、可靠的方式同步给其他服务、存储,如mongodb、es、kafka、redis、clickhouse等。
2 CDC原理分类
目前一些常用的组件有alibaba canal,apache flink,go-mysql-transfer等。CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
2.1 基于查询的 CDC
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
2.2 基于日志的 CDC
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
3 开源方案对比
| flink cdc | Debezium | Canal | Sqoop | Kettle | Oracle Goldengate | Go-mysql-transfer |
|
|---|---|---|---|---|---|---|---|
| CDC机制 | 日志 | 日志 | 日志 | 查询 | 查询 | 日志 | 日志 |
| 增量同步 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| 全量同步 | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
| 断点续传 | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ |
| 全量 + 增量 | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ | ✅ |
| 架构 | 分布式 | 单机 | 单机 | 分布式 | 分布式 | 分布式 | 单机 |
| Transformation | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️ | ⭐️ | ⭐️⭐️⭐️⭐️ |
| 生态 | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ |
如上图所示,需要根据实际业务场景,决定使用哪一种开源方案。
4 使用场景
cdc,顾名思义,就是数据变更捕获,其本质是实时获取MySQL数据变更(增删改),进而同步其他服务或者业务方。因此其使用场景主要分为:
- 数据分发:将一个数据源的数据分发给多个下游业务系统,常用于业务解耦、微服务系统。
- 数据采集:面向数据仓库、数据湖的ETL数据集成,消除数据孤岛,便于后续的分析。
- 数据同步:常用于数据备份、容灾等。
5 MySQL配置
5.1 开启MySQL的binlog
[mysqld]
default-storage-engine=INNODB
server-id = 100 (`唯一`)
port = 3306
log-bin=mysql-bin (`开启`)
binlog_format = ROW (`注意要设置为行模式`)
开启之后,在MySQL的数据目录(/usr/local/mysql-8.0.32-macos13-arm64/data),就会生成相应的binlog文件
-rw-r----- 1 _mysql _mysql 1867 6 12 00:03 mysql-bin.000001
-rw-r----- 1 _mysql _mysql 5740 6 18 20:55 mysql-bin.000002
-rw-r----- 1 _mysql _mysql 38 6 12 00:03 mysql-bin.index
5.2 创建canal同步账户及权限设置
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, SHOW VIEW, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql> FLUSH PRIVILEGES;
6 Canal配置
6.1 canal同步kafka原理
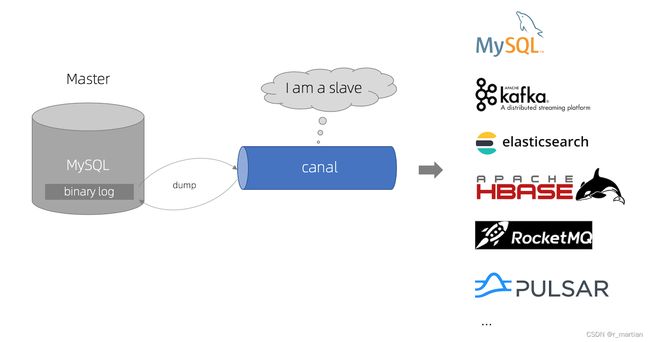
原理等同于MySQL的主从复制,具体流程:
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
6.2 canal安装与配置
具体配置请参考文章 https://www.cnblogs.com/Clera-tea/p/16517424.html
6.2.1 配置文件
/canal/conf/canal.properties
6.2.2 同步kafka配置
canal.serverMode = kafka
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092 (本机kafka服务)
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
6.2.3 binlog过滤设置
# binlog filter config
canal.instance.filter.druid.ddl = false(注意这里true 改成 false)
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
6.2.4 同步destinations设置
canal.destinations = example,mytopic(多个逗号分隔)
6.2.5 每个topic都有各自的实例配置
路径/conf/topicname/instance.properties
设置监听mysql地址
canal.instance.master.address=127.0.0.1:3306
配置mysql账户
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
配置canal同步到kafka topic信息
canal.mq.topic=mytopic
6.2.6 kafka数据接收
1 mysql
2 zkServer start
3 kafka-server-start /opt/homebrew/etc/kafka/server.properties
4 canal/bin/startup.sh
kafka 消费者收到的消息如下
{
"data":[
{
"id":"22",
"url":"1",
"source":"d",
"status":"1",
"created_at":"2023-06-29 00:10:31",
"updated_at":"2023-06-29 00:10:31"
}
],
"database":"finance",
"es":1687968631000,
"id":2,
"isDdl":false,
"mysqlType":{
"id":"int unsigned",
"url":"varchar(2048)",
"source":"varchar(32)",
"status":"tinyint",
"created_at":"datetime",
"updated_at":"datetime"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"url":12,
"source":12,
"status":-6,
"created_at":93,
"updated_at":93
},
"table":"f_collect",
"ts":1687968631537,
"type":"INSERT"
}
{
"data":[
{
"id":"22",
"url":"1",
"source":"d",
"status":"100",
"created_at":"2023-06-29 00:10:31",
"updated_at":"2023-06-29 00:31:39"
}
],
"database":"finance",
"es":1687969899000,
"id":3,
"isDdl":false,
"mysqlType":{
"id":"int unsigned",
"url":"varchar(2048)",
"source":"varchar(32)",
"status":"tinyint",
"created_at":"datetime",
"updated_at":"datetime"
},
"old":[
{
"status":"1",
"updated_at":"2023-06-29 00:10:31"
}
],
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"url":12,
"source":12,
"status":-6,
"created_at":93,
"updated_at":93
},
"table":"f_collect",
"ts":1687969899293,
"type":"UPDATE"
}
{
"data":[
{
"id":"22",
"url":"1",
"source":"d",
"status":"100",
"created_at":"2023-06-29 00:10:31",
"updated_at":"2023-06-29 00:31:39"
}
],
"database":"finance",
"es":1687969946000,
"id":4,
"isDdl":false,
"mysqlType":{
"id":"int unsigned",
"url":"varchar(2048)",
"source":"varchar(32)",
"status":"tinyint",
"created_at":"datetime",
"updated_at":"datetime"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"url":12,
"source":12,
"status":-6,
"created_at":93,
"updated_at":93
},
"table":"f_collect",
"ts":1687969946443,
"type":"DELETE"
}
7 go-mysql-transfer配置
7.1 基本说明
项目github地址:go-mysql-transfer
- 简单,不依赖其它组件,一键部署
- 集成多种接收端,如:Redis、MongoDB、Elasticsearch、RocketMQ、Kafka、RabbitMQ、HTTP API等,无需编写客户端,开箱即用
- 内置丰富的数据解析、消息生成规则、模板语法
- 支持Lua脚本扩展,可处理复杂逻辑
- 集成Prometheus客户端,支持监控告警
- 集成Web Admin监控页面
- 支持高可用集群部署
- 数据同步失败重试
- 支持全量数据初始化
7.2 原理
- 将自己伪装为MySQL的
Slave监听binlog,获取binlog的变更数据 - 根据规则或者
lua脚本解析数据,生成指定格式的消息 - 将生成的消息批量发送给接收端
7.3 安装
1、依赖Golang 1.14 及以上版本
2、设置' GO111MODULE=on '
3、拉取源码 ' git clone https://github.com/wj596/go-mysql-transfer.git '
4、进入目录,执行 ' go build ' 编译
7.4 全量数据同步
./go-mysql-transfer -stock
7.5 配置文件app.yaml
都能看懂,不做详细说明,主要配置项
1. mysql
2. target (kafka)
3. kafka配置
4. rule
4.1 数据库,表,字段
4.2 lua_file_path: lua/sync.lua 可以只配置基本的数据格式,也可以配置lua脚本来调整数据格式
4.3 kafka topic
# mysql配置
addr: 127.0.0.1:3306
user: #mysql用户名
pass: #mysql密码
charset : utf8
slave_id: 1001 #slave ID
flavor: mysql #mysql or mariadb,默认mysql
#系统相关配置
#data_dir: D:\\transfer #应用产生的数据存放地址,包括日志、缓存数据等,默认当前运行目录下store文件夹
#logger:
# level: info #日志级别;支持:debug|info|warn|error,默认info
#maxprocs: 50 #并发协(线)程数量,默认为: CPU核数*2;一般情况下不需要设置此项
#bulk_size: 1000 #每批处理数量,不写默认100,可以根据带宽、机器性能等调整;如果是全量数据初始化时redis建议设为1000,其他接收端酌情调大
#prometheus相关配置
#enable_exporter: true #是否启用prometheus exporter,默认false
#exporter_addr: 9595 #prometheus exporter端口,默认9595
#web admin相关配置
enable_web_admin: true #是否启用web admin,默认false
web_admin_port: 8060 #web监控端口,默认8060
#cluster: # 集群相关配置
#name: myTransfer #集群名称,具有相同name的节点放入同一个集群
#bind_ip: 127.0.0.1 # 绑定的IP,如果机器有多张网卡(包含虚拟网卡)会有多个IP,使用这个属性绑定一个
#ZooKeeper地址,多个用逗号风格
#zk_addrs: 192.168.1.10:2181,192.168.1.11:2182,192.168.1.12:2183
#zk_authentication: 123456 #digest类型的访问秘钥,如:user:password,默认为空
#etcd_addrs: 127.0.0.1:2379 #etcd连接地址,多个用逗号分隔
#etcd_user: test #etcd用户名
#etcd_password: 123456 #etcd密码
#目标类型
target: kafka # 支持redis、mongodb、elasticsearch、rocketmq、kafka、rabbitmq
#redis连接配置
#redis_addrs: 127.0.0.1:6379 #redis地址,多个用逗号分隔
#redis_group_type: cluster # 集群类型 sentinel或者cluster
#redis_master_name: mymaster # Master节点名称,如果group_type为sentinel则此项不能为空,为cluster此项无效
#redis_pass: 123456 #redis密码
#redis_database: 0 #redis数据库 0-16,默认0。如果group_type为cluster此项无效
#mongodb连接配置
#mongodb_addrs: 127.0.0.1:27017 #mongodb连接地址,多个用逗号分隔
#mongodb_username: #mongodb用户名,默认为空
#mongodb_password: #mongodb密码,默认为空
#elasticsearch连接配置
#es_addrs: 127.0.0.1:9200 #连接地址,多个用逗号分隔
#es_version: 7 # Elasticsearch版本,支持6和7、默认为7
#es_password: # 用户名
#es_version: # 密码
#rocketmq连接配置
#rocketmq_name_servers: 127.0.0.1:9876 #rocketmq命名服务地址,多个用逗号分隔
#rocketmq_group_name: transfer_test_group #rocketmq group name,默认为空
#rocketmq_instance_name: transfer_test_group_ins #rocketmq instance name,默认为空
#rocketmq_access_key: RocketMQ #访问控制 accessKey,默认为空
#rocketmq_secret_key: 12345678 #访问控制 secretKey,默认为空
#kafka连接配置
kafka_addrs: 127.0.0.1:9092 #kafka连接地址,多个用逗号分隔
#kafka_sasl_user: #kafka SASL_PLAINTEXT认证模式 用户名
#kafka_sasl_password: #kafka SASL_PLAINTEXT认证模式 密码
#rabbitmq连接配置
#rabbitmq_addr: amqp://guest:[email protected]:5672/ #连接字符串,如: amqp://guest:guest@localhost:5672/
#规则配置
rule:
-
schema: test #数据库名称
table: score #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
#column_lower_case:false #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
column_underscore_to_camel: false #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
include_columns: ID,name,age,sex
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
#default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
lua_file_path: lua/sync.lua #lua脚本文件,项目目录创建lua目录
#lua_script: #lua 脚本
value_encoder: json #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}' # 值格式化表达式,如:{{.ID}}|{{.USER_NAME}},{{.ID}}表示ID字段的值、{{.USER_NAME}}表示USER_NAME字段的值
#redis相关
redis_structure: string # 数据类型。 支持string、hash、list、set、sortedset类型(与redis的数据类型一致)
#redis_key_prefix: USER_ #key的前缀
#redis_key_column: USER_NAME #使用哪个列的值作为key,不填写默认使用主键
#redis_key_formatter: '{{.ID}}|{{.USER_NAME}}'
#redis_key_value: user #KEY的值(固定值);当redis_structure为hash、list、set、sortedset此值不能为空
#redis_hash_field_prefix: _CARD_ #hash的field前缀,仅redis_structure为hash时起作用
#redis_hash_field_column: Cert_No #使用哪个列的值作为hash的field,仅redis_structure为hash时起作用,不填写默认使用主键
#redis_sorted_set_score_column: id #sortedset的score,当数据类型为sortedset时,此项不能为空,此项的值应为数字类型
#mongodb相关
#mongodb_database: transfer #mongodb database不能为空
#mongodb_collection: transfer_test_topic #mongodb collection,可以为空,默认使用表名称
#elasticsearch相关
#es_index: user_index #Index名称,可以为空,默认使用表(Table)名称
#es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
# -
# column: REMARK #数据库列名称
# field: remark #映射后的ES字段名称
# type: text #ES字段类型
# analyzer: ik_smart #ES分词器,type为text此项有意义
# #format: #日期格式,type为date此项有意义
# -
# column: USER_NAME #数据库列名称
# field: account #映射后的ES字段名称
# type: keyword #ES字段类型
#rocketmq相关
#rocketmq_topic: transfer_test_topic #rocketmq topic,可以为空,默认使用表名称
#kafka相关
kafka_topic: test #rocketmq topic,可以为空,默认使用表名称
#rabbitmq相关
#rabbitmq_queue: user_topic #queue名称,可以为空,默认使用表(Table)名称
#reserve_raw_data: true #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
7.6 项目启动
1. 启动zk(zkServer.sh)
2. 启动kafka (kafka-server-start.sh server.properties)
3. 启动go-mysql-transfer (./go-mysql-transfer)
4. 启动kafka消费者(kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic test)
5. 编写简单的lua脚本,实现数据同步
6. 验证数据同步
go-mysql-transfer/lua/sync.lua脚本内容
local json = require("json") -- 加载json模块
local ops = require("mqOps") --加载mq操作模块
local os = require("os") --加载os模块
local row = ops.rawRow() --当前数据库的一行数据,
local action = ops.rawAction() --当前数据库事件,包括:insert、updare、delete
local id = row["id"] --获取ID列的值
local name = row["name"]
local age = row["age"]
local sex = row["sex"]
local result = {}
local data = {}
result["timestamp"] = os.time()
result["action"] = action
data['id'] = id
data['name'] = name
data['age'] = age
data['sex'] = sex
result["object"] = data
local val = json.encode(result) -- 将result转为json
ops.SEND("test", val) -- 发送消息,参数1:topic(string类型),参数2:消息内容
启动go-mysql-transfer

mysql更新数据

kafka收到的消息

常见问题汇总
- The Cluster ID i0yMUA_eRHuBS60eM1ph9w doesn’t match stored clusterId Some(aH
https://blog.csdn.net/m0_59252007/article/details/119533700
参考文档
1 https://www.kancloud.cn/wj596/go-mysql-transfer/2116628
2 https://www.cnblogs.com/Clera-tea/p/16517424.html