基于pytorch的文本情感识别(LSTM,CNN)
文章目录
- 前言
- 一、数据处理与Word2vec词向量训练
- 二、创建神经网络的输入batch
- 三、神经网络模型
-
- 1.LSTM
- 2.CNN
- 四、训练与测试
- 六、实验结果
- 七、完整代码
-
- 1.LSTM
- 2.CNN
前言
本文使用pytorch,利用两种神经网络(lstm,cnn)实现中文的文本情感识别。代码都有详细的注释说明。使用的是谭松波酒店评价语料库,其中包含3000条负面评价,7000条正面评价。
一、数据处理与Word2vec词向量训练
原始的语料数据如下图

通过txt进行处理,将文本前的1与空格去除,得到结果如下图,将其作为程序的输入

将输入的文本进行预处理,利用jieba函数库进行分词
def del_stop_words(text): #分词
word_ls = jieba.lcut(text)
#word_ls = [i for i in word_ls if i not in stopwords]
return word_ls
with open("F:/python_data/practice/tansongbo/neg.txt", "r", encoding='UTF-8') as e: # 加载负面语料
neg_data1 = e.readlines()
with open("F:/python_data/practice/tansongbo/pos.txt", "r", encoding='UTF-8') as s: # 加载正面语料
pos_data1 = s.readlines()
neg_data = sorted(set(neg_data1), key=neg_data1.index) #列表去重 保持原来的顺序
pos_data = sorted(set(pos_data1), key=pos_data1.index)
neg_data = [del_stop_words(data.replace("\n", "")) for data in neg_data] # 处理负面语料
pos_data = [del_stop_words(data.replace("\n", "")) for data in pos_data]
all_sentences = neg_data + pos_data # 全部语料 用于训练word2vec
训练词向量,创建词向量词典
####训练过一次后可以不再训练词向量模型####
####用于训练词向量模型###
model = Word2Vec(all_sentences, # 上文处理过的全部语料
size=100, # 词向量维度 默认100维
min_count=1, # 词频阈值 词出现的频率 小于这个频率的词 将不予保存
window=5 # 窗口大小 表示当前词与预测词在一个句子中的最大距离是多少
)
model.save('f.model') # 保存模型
#加载模型,提取出词索引和词向量
def create_dictionaries(model):
gensim_dict = Dictionary() # 创建词语词典
gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True)
w2indx = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号
w2vec = {word: model[word] for word in w2indx.keys()} # 词语的词向量
return w2indx, w2vec
model = Word2Vec.load('F:/python_data/practice/tansongbo/f.model') # 加载模型
index_dict, word_vectors= create_dictionaries(model) # 索引字典、词向量字典
#使用pickle进行字典索引与词向量的存储
output = open('F:/python_data/practice/tansongbo/dict.txt' + ".pkl", 'wb')
pickle.dump(index_dict, output) # 索引字典
pickle.dump(word_vectors, output) # 词向量字典
output.close()
二、创建神经网络的输入batch
将文本句子转换为词向量的多维矩阵,并创建输入到神经网络中的batch#参数设置
vocab_dim = 100 # 向量维度
maxlen = 28 # 文本保留的最大长度
n_epoch = 10 # 迭代次数
batch_size = 64 #每次送入网络的句子数
#加载词向量数据,填充词向量矩阵
f = open("F:/python_data/practice/tansongbo/dict.txt.pkl", 'rb') # 预先训练好的
index_dict = pickle.load(f) # 索引字典,{单词: 索引数字}
word_vectors = pickle.load(f) # 词向量, {单词: 词向量(100维长的数组)}
n_symbols = len(index_dict) + 1 # 索引数字的个数,因为有的词语索引为0,所以+1
embedding_weights = np.zeros((n_symbols, vocab_dim)) # 创建一个n_symbols * 100的0矩阵
for w, index in index_dict.items(): # 从索引为1的词语开始,用词向量填充矩阵
embedding_weights[index, :] = word_vectors[w] # 词向量矩阵,第一行是0向量(没有索引为0的词语,未被填充)
#将文本数据映射成数字(是某个词的编号,不是词向量)
def text_to_index_array(p_new_dic, p_sen):
##文本或列表转换为索引数字
if type(p_sen) == list:
new_sentences = []
for sen in p_sen:
new_sen = []
for word in sen:
try:
new_sen.append(p_new_dic[word]) # 单词转索引数字
except:
new_sen.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(new_sen)
return np.array(new_sentences) # 转numpy数组
else:
new_sentences = []
sentences = []
p_sen = p_sen.split(" ")
for word in p_sen:
try:
sentences.append(p_new_dic[word]) # 单词转索引数字
except:
sentences.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(sentences)
return new_sentences
#将数据切割成一样的指定长度
def text_cut_to_same_long(sents):
data_num = len(sents)
new_sents = np.zeros((data_num,maxlen)) #构建一个矩阵来装修剪好的数据
se = []
for i in range(len(sents)):
new_sents[i,:] = sents[i,:maxlen]
new_sents = np.array(new_sents)
return new_sents
#将每个句子的序号矩阵替换成词向量矩阵
def creat_wordvec_tensor(embedding_weights,X_T):
X_tt = np.zeros((len(X_T),maxlen,vocab_dim))
num1 = 0
num2 = 0
for j in X_T:
for i in j:
X_tt[num1,num2,:] = embedding_weights[int(i),:]
num2 = num2+1
num1 = num1+1
num2 = 0
return X_tt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print ('正在使用计算的是:%s'%device)
data = all_sentences #获取之前分好词的数据
# 读取语料类别标签
label_list = ([0] * len(neg_data) + [1] * len(pos_data))
# 划分训练集和测试集,此时都是list列表
X_train_l, X_test_l, y_train_l, y_test_l = train_test_split(data, label_list, test_size=0.2)
#print (X_train_l[0])
# 转为数字索引形式
# token = Tokenizer(num_words=3000) #字典数量
# token.fit_on_texts(train_text)
X_train = text_to_index_array(index_dict, X_train_l)
X_test = text_to_index_array(index_dict, X_test_l)
#print("训练集shape: ", X_train[0])
y_train = np.array(y_train_l) # 转numpy数组
y_test = np.array(y_test_l)
##将数据切割成一样的指定长度
from torch.nn.utils.rnn import pad_sequence
#将数据补长变成和最长的一样长
X_train = pad_sequence([torch.from_numpy(np.array(x)) for x in X_train],batch_first=True).float()
X_test = pad_sequence([torch.from_numpy(np.array(x)) for x in X_test],batch_first=True).float()
#将数据切割成需要的样子
X_train = text_cut_to_same_long(X_train)
X_test = text_cut_to_same_long(X_test)
#将词向量字典序号转换为词向量矩阵
X_train = creat_wordvec_tensor(embedding_weights,X_train)
X_test = creat_wordvec_tensor(embedding_weights,X_test)
#print("训练集shape: ", X_train.shape)
#print("测试集shape: ", X_test.shape)
####Datloader和创建batch####
from torch.utils.data import TensorDataset, DataLoader
# 创建Tensor datasets
train_data = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
test_data = TensorDataset(torch.from_numpy(X_test), torch.from_numpy(y_test))
# shuffle是打乱数据顺序
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)
三、神经网络模型
1.LSTM
class lstm(nn.Module):
def __init__(self):
super(lstm, self).__init__()
self.lstm = nn.LSTM(
input_size=vocab_dim,
hidden_size=128,
batch_first=True) #batch_first 是因为DataLoader所读取的数据与lstm所需的输入input格式是不同的,
#所在的位置不同,故通过batch_first进行修改
self.fc = nn.Linear(128, 2)#连接层的输入维数是hidden_size的大小
def forward(self, x):
out, (h_0, c_0) = self.lstm(x)
out = out[:, -1, :]
out = self.fc(out)
out = F.softmax(out, dim= 1)
return out, h_0
model = lstm()
optimizer = torch.optim.Adam(model.parameters())
model = model.to(device) #将模型放入GPU
2.CNN
class CNN(nn.Module):
def __init__(self, embedding_dim, n_filters, filter_sizes, dropout):
super(CNN, self).__init__()
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes]) #.ModuleList将模块放入一个列表
self.fc = nn.Linear(n_filters * len(filter_sizes), 2)
self.dropout = nn.Dropout(dropout) #防止过拟合
def forward(self, text):
# text = [batch_size, sent_len, emb_dim]
embedded = text.unsqueeze(1)
# embedded = [batch_size, 1, sent_len, emb_dim]
convd = [conv(embedded).squeeze(3) for conv in self.convs]
# conv_n = [batch_size, n_filters, sent_len - fs + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in convd]
# pooled_n = [batch_size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1)) #torch.cat使张量进行拼接
# cat = [batch_size, n_filters * len(filter_sizes)]
return self.fc(cat)
n_filters = 100
filter_sizes = [2, 3, 4]
dropout = 0.5
model = CNN(vocab_dim, n_filters, filter_sizes, dropout)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
四、训练与测试
下面代码展示的是LSTM模型的代码,CNN基本也相同,主要差别在于输出结果,具体不同可以查看最后的完整代码。
####训练train data####
from sklearn.metrics import accuracy_score, classification_report
print ('————————进行训练集训练————————')
for epoch in range(n_epoch):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
optimizer.zero_grad()
data,target = data.cuda(),target.cuda() #将数据放入GPU
output, h_state = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)
####进行测试集验证####
print ('————————进行测试集验证————————')
for epoch in range(1):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(test_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
data,target = data.cuda(),target.cuda() #将数据放入GPU
optimizer.zero_grad()
output, h_state = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)
六、实验结果
1.LSTM
训练了40个epoch,最终正确率在83%左右

2.CNN
训练了10个epoch,正确率在78%左右
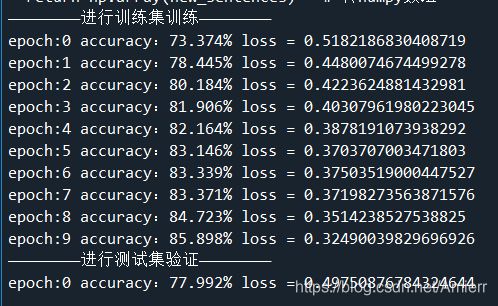
七、完整代码
1.LSTM
# -*- coding: utf-8 -*-
####数据预处理####
#分词
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import jieba
from sklearn.model_selection import train_test_split
#f = open('./stop_words.txt', encoding='utf-8') # 加载停用词
#stopwords = [i.replace("\n", "") for i in f.readlines()] # 停用词表
def del_stop_words(text): #分词
word_ls = jieba.lcut(text)
#word_ls = [i for i in word_ls if i not in stopwords]
return word_ls
with open("F:/python_data/practice/tansongbo/neg.txt", "r", encoding='UTF-8') as e: # 加载负面语料
neg_data1 = e.readlines()
with open("F:/python_data/practice/tansongbo/pos.txt", "r", encoding='UTF-8') as s: # 加载正面语料
pos_data1 = s.readlines()
neg_data = sorted(set(neg_data1), key=neg_data1.index) #列表去重 保持原来的顺序
pos_data = sorted(set(pos_data1), key=pos_data1.index)
neg_data = [del_stop_words(data.replace("\n", "")) for data in neg_data] # 处理负面语料
pos_data = [del_stop_words(data.replace("\n", "")) for data in pos_data]
all_sentences = neg_data + pos_data # 全部语料 用于训练word2vec
####文本向量化####
#创建word2vec词向量模型
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
import pickle
import logging
#logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) # 将日志输出到控制台
####训练过一次后可以不再训练词向量模型####
####用于训练词向量模型###
model = Word2Vec(all_sentences, # 上文处理过的全部语料
size=100, # 词向量维度 默认100维
min_count=1, # 词频阈值 词出现的频率 小于这个频率的词 将不予保存
window=5 # 窗口大小 表示当前词与预测词在一个句子中的最大距离是多少
)
model.save('f.model') # 保存模型
#加载模型,提取出词索引和词向量
def create_dictionaries(model):
gensim_dict = Dictionary() # 创建词语词典
gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True)
w2indx = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号
w2vec = {word: model[word] for word in w2indx.keys()} # 词语的词向量
return w2indx, w2vec
model = Word2Vec.load('F:/python_data/practice/tansongbo/f.model') # 加载模型
index_dict, word_vectors= create_dictionaries(model) # 索引字典、词向量字典
#使用pickle进行字典索引与词向量的存储
output = open('F:/python_data/practice/tansongbo/dict.txt' + ".pkl", 'wb')
pickle.dump(index_dict, output) # 索引字典
pickle.dump(word_vectors, output) # 词向量字典
output.close()
####LSTM训练####
#参数设置
vocab_dim = 100 # 向量维度
maxlen = 50 # 文本保留的最大长度
n_epoch = 40 # 迭代次数
batch_size = 64 #每次送入网络的句子数
#加载词向量数据,填充词向量矩阵
f = open("F:/python_data/practice/tansongbo/dict.txt.pkl", 'rb') # 预先训练好的
index_dict = pickle.load(f) # 索引字典,{单词: 索引数字}
word_vectors = pickle.load(f) # 词向量, {单词: 词向量(100维长的数组)}
n_symbols = len(index_dict) + 1 # 索引数字的个数,因为有的词语索引为0,所以+1
embedding_weights = np.zeros((n_symbols, vocab_dim)) # 创建一个n_symbols * 100的0矩阵
for w, index in index_dict.items(): # 从索引为1的词语开始,用词向量填充矩阵
embedding_weights[index, :] = word_vectors[w] # 词向量矩阵,第一行是0向量(没有索引为0的词语,未被填充)
#将文本数据映射成数字(是某个词的编号,不是词向量)
def text_to_index_array(p_new_dic, p_sen):
##文本或列表转换为索引数字
if type(p_sen) == list:
new_sentences = []
for sen in p_sen:
new_sen = []
for word in sen:
try:
new_sen.append(p_new_dic[word]) # 单词转索引数字
except:
new_sen.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(new_sen)
return np.array(new_sentences) # 转numpy数组
else:
new_sentences = []
sentences = []
p_sen = p_sen.split(" ")
for word in p_sen:
try:
sentences.append(p_new_dic[word]) # 单词转索引数字
except:
sentences.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(sentences)
return new_sentences
#将数据切割成一样的指定长度
def text_cut_to_same_long(sents):
data_num = len(sents)
new_sents = np.zeros((data_num,maxlen)) #构建一个矩阵来装修剪好的数据
se = []
for i in range(len(sents)):
new_sents[i,:] = sents[i,:maxlen]
new_sents = np.array(new_sents)
return new_sents
#加载数据特征与标签,将数据特征映射成数字,分割训练集与测试集
with open("F:/python_data/practice/tansongbo/neg.txt", "r", encoding='UTF-8') as f:
neg_data1 = f.readlines()
with open("F:/python_data/practice/tansongbo/pos.txt", "r", encoding='UTF-8') as g:
pos_data1 = g.readlines()
neg_data = sorted(set(neg_data1), key=neg_data1.index) #列表去重 保持原来的顺序
pos_data = sorted(set(pos_data1), key=pos_data1.index)
neg_data = [del_stop_words(data) for data in neg_data]
pos_data = [del_stop_words(data) for data in pos_data]
data = neg_data + pos_data
#将每个句子的序号矩阵替换成词向量矩阵
def creat_wordvec_tensor(embedding_weights,X_T):
X_tt = np.zeros((len(X_T),maxlen,vocab_dim))
num1 = 0
num2 = 0
for j in X_T:
for i in j:
X_tt[num1,num2,:] = embedding_weights[int(i),:]
num2 = num2+1
num1 = num1+1
num2 = 0
return X_tt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print ('正在使用计算的是:%s'%device)
data = all_sentences #获取之前分好词的数据
# 读取语料类别标签
label_list = ([0] * len(neg_data) + [1] * len(pos_data))
# 划分训练集和测试集,此时都是list列表
X_train_l, X_test_l, y_train_l, y_test_l = train_test_split(data, label_list, test_size=0.2)
#print (X_train_l[0])
# 转为数字索引形式
# token = Tokenizer(num_words=3000) #字典数量
# token.fit_on_texts(train_text)
X_train = text_to_index_array(index_dict, X_train_l)
X_test = text_to_index_array(index_dict, X_test_l)
#print("训练集shape: ", X_train[0])
y_train = np.array(y_train_l) # 转numpy数组
y_test = np.array(y_test_l)
##将数据切割成一样的指定长度
from torch.nn.utils.rnn import pad_sequence
#将数据补长变成和最长的一样长
X_train = pad_sequence([torch.from_numpy(np.array(x)) for x in X_train],batch_first=True).float()
X_test = pad_sequence([torch.from_numpy(np.array(x)) for x in X_test],batch_first=True).float()
#将数据切割成需要的样子
X_train = text_cut_to_same_long(X_train)
X_test = text_cut_to_same_long(X_test)
#将词向量字典序号转换为词向量矩阵
X_train = creat_wordvec_tensor(embedding_weights,X_train)
X_test = creat_wordvec_tensor(embedding_weights,X_test)
#print("训练集shape: ", X_train.shape)
#print("测试集shape: ", X_test.shape)
####Datloader和创建batch####
from torch.utils.data import TensorDataset, DataLoader
# 创建Tensor datasets
train_data = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
test_data = TensorDataset(torch.from_numpy(X_test), torch.from_numpy(y_test))
# shuffle是打乱数据顺序
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)
class lstm(nn.Module):
def __init__(self):
super(lstm, self).__init__()
self.lstm = nn.LSTM(
input_size=vocab_dim,
hidden_size=64,
batch_first=True) #batch_first 是因为DataLoader所读取的数据与lstm所需的输入input格式是不同的,
#所在的位置不同,故通过batch_first进行修改
self.fc = nn.Linear(64, 2)#连接层的输入维数是hidden_size的大小
def forward(self, x):
out, (h_0, c_0) = self.lstm(x)
out = out[:, -1, :]
out = self.fc(out)
out = F.sigmoid(out) #二分类使用sigmoid函数,多分类使用softmax函数 out = F.softmax(out,dim=1)
return out, h_0
model = lstm()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
####训练train data####
from sklearn.metrics import accuracy_score, classification_report
print ('————————进行训练集训练————————')
for epoch in range(n_epoch):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
optimizer.zero_grad()
data,target = data.cuda(),target.cuda() #将数据放入GPU
output, h_state = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)
####进行测试集验证####
print ('————————进行测试集验证————————')
for epoch in range(1):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(test_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
optimizer.zero_grad()
data,target = data.cuda(),target.cuda() #将数据放入GPU
output, h_state = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)
2.CNN
# -*- coding: utf-8 -*-
####数据预处理####
#分词
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import jieba
from sklearn.model_selection import train_test_split
#f = open('./stop_words.txt', encoding='utf-8') # 加载停用词
#stopwords = [i.replace("\n", "") for i in f.readlines()] # 停用词表
def del_stop_words(text): #分词
word_ls = jieba.lcut(text)
#word_ls = [i for i in word_ls if i not in stopwords]
return word_ls
with open("F:/python_data/practice/tansongbo/neg.txt", "r", encoding='UTF-8') as e: # 加载负面语料
neg_data1 = e.readlines()
with open("F:/python_data/practice/tansongbo/pos.txt", "r", encoding='UTF-8') as s: # 加载正面语料
pos_data1 = s.readlines()
neg_data = sorted(set(neg_data1), key=neg_data1.index) #列表去重 保持原来的顺序
pos_data = sorted(set(pos_data1), key=pos_data1.index)
neg_data = [del_stop_words(data.replace("\n", "")) for data in neg_data] # 处理负面语料
pos_data = [del_stop_words(data.replace("\n", "")) for data in pos_data]
all_sentences = neg_data + pos_data # 全部语料 用于训练word2vec
####文本向量化####
#创建word2vec词向量模型
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
import pickle
import logging
#logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) # 将日志输出到控制台
####训练过一次后可以不再训练词向量模型####
####用于训练词向量模型###
model = Word2Vec(all_sentences, # 上文处理过的全部语料
size=100, # 词向量维度 默认100维
min_count=1, # 词频阈值 词出现的频率 小于这个频率的词 将不予保存
window=5 # 窗口大小 表示当前词与预测词在一个句子中的最大距离是多少
)
model.save('f.model') # 保存模型
#加载模型,提取出词索引和词向量
def create_dictionaries(model):
gensim_dict = Dictionary() # 创建词语词典
gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True)
w2indx = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号
w2vec = {word: model[word] for word in w2indx.keys()} # 词语的词向量
return w2indx, w2vec
model = Word2Vec.load('F:/python_data/practice/tansongbo/f.model') # 加载模型
index_dict, word_vectors= create_dictionaries(model) # 索引字典、词向量字典
#使用pickle进行字典索引与词向量的存储
output = open('F:/python_data/practice/tansongbo/dict.txt' + ".pkl", 'wb')
pickle.dump(index_dict, output) # 索引字典
pickle.dump(word_vectors, output) # 词向量字典
output.close()
####LSTM训练####
#参数设置
vocab_dim = 100 # 向量维度
maxlen = 28 # 文本保留的最大长度
n_epoch = 10 # 迭代次数
batch_size = 64 #每次送入网络的句子数
#加载词向量数据,填充词向量矩阵
f = open("F:/python_data/practice/tansongbo/dict.txt.pkl", 'rb') # 预先训练好的
index_dict = pickle.load(f) # 索引字典,{单词: 索引数字}
word_vectors = pickle.load(f) # 词向量, {单词: 词向量(100维长的数组)}
n_symbols = len(index_dict) + 1 # 索引数字的个数,因为有的词语索引为0,所以+1
embedding_weights = np.zeros((n_symbols, vocab_dim)) # 创建一个n_symbols * 100的0矩阵
for w, index in index_dict.items(): # 从索引为1的词语开始,用词向量填充矩阵
embedding_weights[index, :] = word_vectors[w] # 词向量矩阵,第一行是0向量(没有索引为0的词语,未被填充)
#将文本数据映射成数字(是某个词的编号,不是词向量)
def text_to_index_array(p_new_dic, p_sen):
##文本或列表转换为索引数字
if type(p_sen) == list:
new_sentences = []
for sen in p_sen:
new_sen = []
for word in sen:
try:
new_sen.append(p_new_dic[word]) # 单词转索引数字
except:
new_sen.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(new_sen)
return np.array(new_sentences) # 转numpy数组
else:
new_sentences = []
sentences = []
p_sen = p_sen.split(" ")
for word in p_sen:
try:
sentences.append(p_new_dic[word]) # 单词转索引数字
except:
sentences.append(0) # 索引字典里没有的词转为数字0
new_sentences.append(sentences)
return new_sentences
#将数据切割成一样的指定长度
def text_cut_to_same_long(sents):
data_num = len(sents)
new_sents = np.zeros((data_num,maxlen)) #构建一个矩阵来装修剪好的数据
se = []
for i in range(len(sents)):
new_sents[i,:] = sents[i,:maxlen]
new_sents = np.array(new_sents)
return new_sents
#将每个句子的序号矩阵替换成词向量矩阵
def creat_wordvec_tensor(embedding_weights,X_T):
X_tt = np.zeros((len(X_T),maxlen,vocab_dim))
num1 = 0
num2 = 0
for j in X_T:
for i in j:
X_tt[num1,num2,:] = embedding_weights[int(i),:]
num2 = num2+1
num1 = num1+1
num2 = 0
return X_tt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print ('正在使用计算的是:%s'%device)
data = all_sentences #获取之前分好词的数据
# 读取语料类别标签
label_list = ([0] * len(neg_data) + [1] * len(pos_data))
# 划分训练集和测试集,此时都是list列表
X_train_l, X_test_l, y_train_l, y_test_l = train_test_split(data, label_list, test_size=0.2)
#print (X_train_l[0])
# 转为数字索引形式
# token = Tokenizer(num_words=3000) #字典数量
# token.fit_on_texts(train_text)
X_train = text_to_index_array(index_dict, X_train_l)
X_test = text_to_index_array(index_dict, X_test_l)
#print("训练集shape: ", X_train[0])
y_train = np.array(y_train_l) # 转numpy数组
y_test = np.array(y_test_l)
##将数据切割成一样的指定长度
from torch.nn.utils.rnn import pad_sequence
#将数据补长变成和最长的一样长
X_train = pad_sequence([torch.from_numpy(np.array(x)) for x in X_train],batch_first=True).float()
X_test = pad_sequence([torch.from_numpy(np.array(x)) for x in X_test],batch_first=True).float()
#将数据切割成需要的样子
X_train = text_cut_to_same_long(X_train)
X_test = text_cut_to_same_long(X_test)
#将词向量字典序号转换为词向量矩阵
X_train = creat_wordvec_tensor(embedding_weights,X_train)
X_test = creat_wordvec_tensor(embedding_weights,X_test)
#print("训练集shape: ", X_train.shape)
#print("测试集shape: ", X_test.shape)
####Datloader和创建batch####
from torch.utils.data import TensorDataset, DataLoader
# 创建Tensor datasets
train_data = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
test_data = TensorDataset(torch.from_numpy(X_test), torch.from_numpy(y_test))
# shuffle是打乱数据顺序
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)
class CNN(nn.Module):
def __init__(self, embedding_dim, n_filters, filter_sizes, dropout):
super(CNN, self).__init__()
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes]) #.ModuleList将模块放入一个列表
self.fc = nn.Linear(n_filters * len(filter_sizes), 2)
self.dropout = nn.Dropout(dropout) #防止过拟合
def forward(self, text):
# text = [batch_size, sent_len, emb_dim]
embedded = text.unsqueeze(1)
# embedded = [batch_size, 1, sent_len, emb_dim]
convd = [conv(embedded).squeeze(3) for conv in self.convs]
# conv_n = [batch_size, n_filters, sent_len - fs + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in convd]
# pooled_n = [batch_size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1)) #torch.cat使张量进行拼接
# cat = [batch_size, n_filters * len(filter_sizes)]
return self.fc(cat)
n_filters = 100
filter_sizes = [2, 3, 4]
dropout = 0.5
model = CNN(vocab_dim, n_filters, filter_sizes, dropout)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
####训练train data####
from sklearn.metrics import accuracy_score, classification_report
print ('————————进行训练集训练————————')
for epoch in range(n_epoch):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
optimizer.zero_grad()
data,target = data.cuda(),target.cuda() #将数据放入GPU
output = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)
####进行测试集验证####
print ('————————进行测试集验证————————')
for epoch in range(1):
correct = 0
total = 0
epoch_loss = 0
model.train()
for batch_idx, (data, target) in enumerate(test_loader):
#print (data.shape)
data = torch.as_tensor(data, dtype=torch.float32)
target = target.long() ##要保证label的数据类型是long
optimizer.zero_grad()
data,target = data.cuda(),target.cuda() #将数据放入GPU
output = model(data)
#labels = output.argmax(dim= 1)
#acc = accuracy_score(target, labels)
correct += int(torch.sum(torch.argmax(output, dim=1) == target))
total += len(target)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target) #交叉熵损失函数;
epoch_loss += loss.item()
loss.backward()
optimizer.step()
loss = epoch_loss / (batch_idx + 1)
print ('epoch:%s'%epoch, 'accuracy:%.3f%%'%(correct *100 / total), 'loss = %s'%loss)