Elasticsearch 8.X 分词插件版本更新不及时解决方案
1、关于 Elasticsearch 8.X IK 分词插件相关问题
球友在 ElasticSearch 版本选型问题中提及:如果要使用ik插件,是不是就使用目前最新的IK对应elasticsearch的版本“8.8.2”?
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v8.8.2如果要使用最新es版本,而IK没有对应的,老师有推荐的其他类似插件吗?谢谢!——问题来源:https://t.zsxq.com/13YX8fFQy

2、 说一下 Elasticsearch 中文分词插件
IK Analyzer
描述:基于词典的中文分词插件。
资源链接:https://github.com/medcl/elasticsearch-analysis-ik目前业界使用相对广泛,尤其中小型企业。
HanLP
描述:基于NLP技术,提供了一系列中文处理能力的分词插件。
资源链接:https://github.com/KennFalcon/elasticsearch-analysis-hanlpJieba
描述:结巴分词的Elasticsearch插件版本。
资源链接:https://github.com/sing1ee/elasticsearch-jieba-pluginAnsj
描述:速度快,能够识别新词的中文分词插件。
资源链接:https://github.com/NLPchina/elasticsearch-analysis-ansjSmartCN
描述:Elasticsearch自带的基于Lucene的中文分词插件。
资源链接:Elasticsearch官方文档MMSEG
描述:基于词典的复杂切分算法中文分词插件。5.X版本后未再更新
资源链接:https://github.com/medcl/elasticsearch-analysis-mmseg根据具体的应用场景和需求,可以选择合适的中文分词插件。
另外,需要注意的是,当使用插件时要确保其版本与Elasticsearch版本相匹配,以避免可能出现的兼容性问题。
3、IK 分词插件如何使用最新版本?
开篇提及问题本质:Elasticsearch 更新版本快, 而 IK 更新较慢的问题。举例:如下图所示,当前是 2023年10月20日,Elasticsearch 最新版本为:8.10.4,而 IK 插件的版本为:8.9.0。
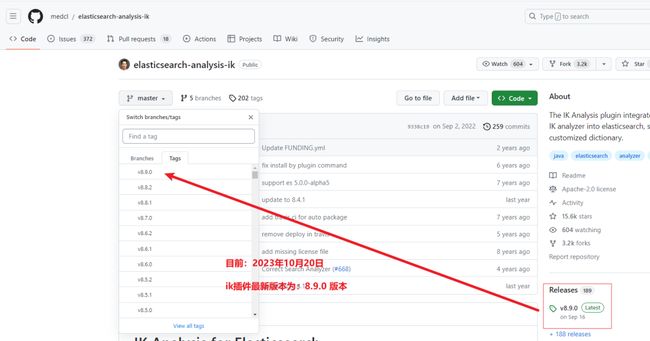
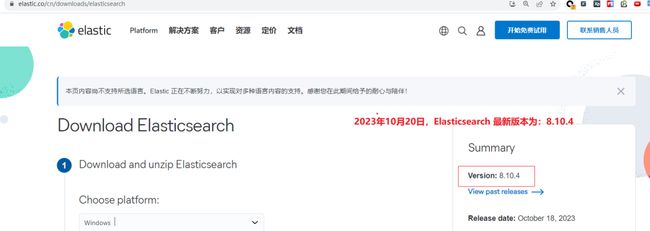
两者类型不匹配,安装的时候会报错。
怎么办?这其实就是开篇问题所在。
咱们可以分析一下 IK 插件的代码,插件源码近1年+几乎没有任何更新。
也就是说:是不是只手动改一下配置文件,自己手动下载部署可不可以呢?
其实是可以的,咱们归拢一下步骤。
步骤1:下载当前最新的 IK 插件。

步骤2:解压源码
这里的外层文件名是我手动由 8.9.0 改成 8.10.2 的,我的虚拟机集群是 8.10.2 版本。
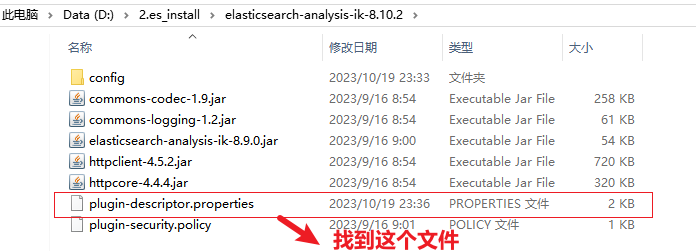
修改配置:
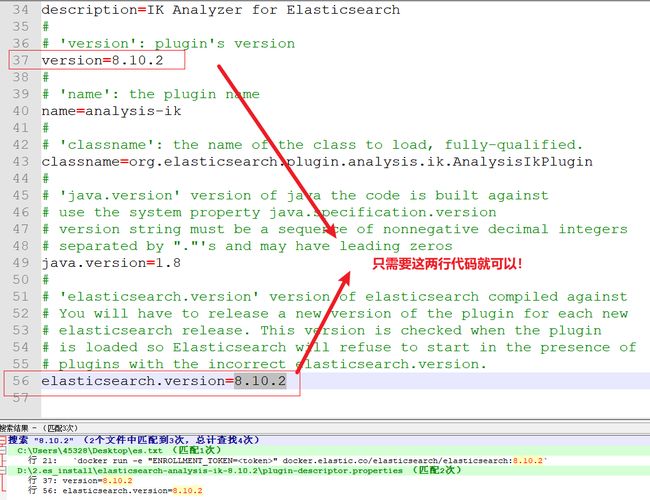
如上内容由原来的版本号 8.9.0,改成 8.10.2 就可以了!
完成后新版本打包,如下所示,打包为:elasticsearch-analysis-ik-8.10.2.zip文件。
![]()
步骤3:安装 Elasticsearch IK插件。
如下图所示,参考IK的文档,我们采取方式1。
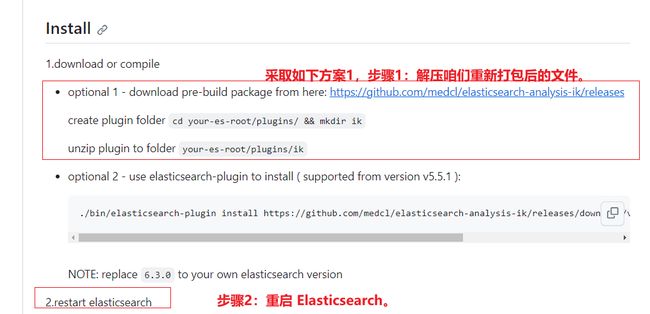
第一步:解压elasticsearch-analysis-ik-8.10.2.zip到如下的 plugins 下的 ik 文件夹下。
ik 文件需要我们提前手动创建。
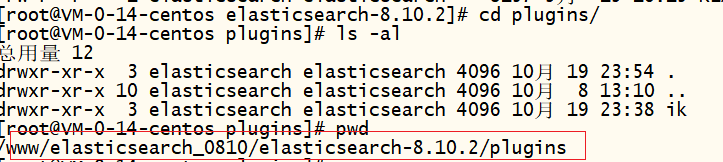
解压后效果:
第二步:重启 Elasticsearch。

步骤4:验证 IK 插件是否成功。
这个创建个索引,指定映射中的某个字段为 ik_max_word 或者 ik_smart 就可以了。
PUT test_index_001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}4、小结
改动非常小,只为版本适配问题。更多类似问题,欢迎留言交流。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
那些 ChatGPT4 也搞不定的 Elasticsearch 问题,请抛给我们!

更短时间更快习得更多干货!
中国50%+Elastic认证专家出自于此!

比同事抢先一步学习进阶干货!