0x00 Logstash概述
官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
Logstash常用于日志关系系统中做日志采集设备,最常用于ELK(elasticsearch + logstash + kibane)中作为日志收集器使用;
官网介绍
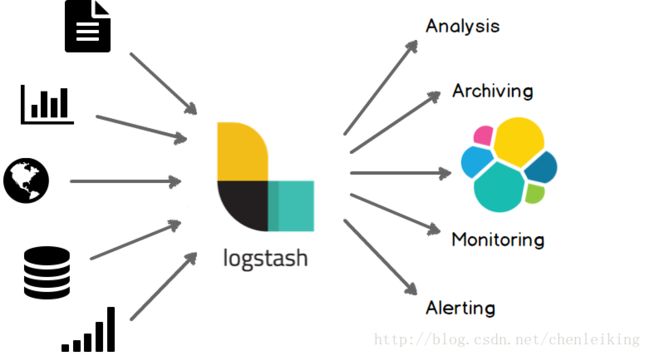
从 Logstash 的名字就能看出,它主要负责跟日志相关的各类操作,在此之前,我们先来看看日志管理的三个境界吧
境界一 『昨夜西风凋碧树。独上高楼,望尽天涯路』,在各台服务器上用传统的 linux 工具(如 cat, tail, sed, awk, grep 等)对日志进行简单的分析和处理,基本上可以认为是命令级别的操作,成本很低,速度很快,但难以复用,也只能完成基本的操作。 境界二 『衣带渐宽终不悔,为伊消得人憔悴』,服务器多了之后,分散管理的成本变得越来越多,所以会利用 rsyslog 这样的工具,把各台机器上的日志汇总到某一台指定的服务器上,进行集中化管理。这样带来的问题是日志量剧增,小作坊式的管理基本难以满足需求。 境界三 『众里寻他千百度,蓦然回首,那人却在灯火阑珊处』,随着日志量的增大,我们从日志中获取去所需信息,并找到各类关联事件的难度会逐渐加大,这个时候,就是 Logstash 登场的时候了
Logstash 的主要优势,一个是在支持各类插件的前提下提供统一的管道进行日志处理(就是 input-filter-output 这一套),二个是灵活且性能不错
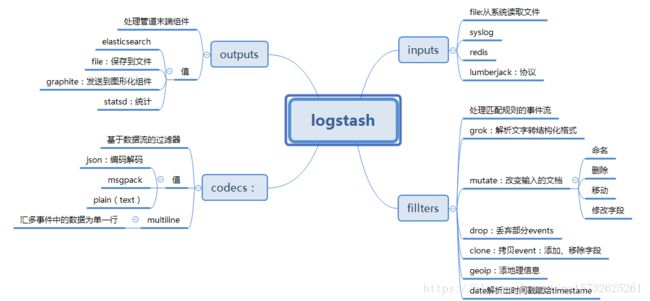
logstash里面最基本的概念(先不管codec)
logstash收集日志基本流程:
input–>filter–>output
input:从哪里收集日志 filter:对日志进行过滤 output:输出哪里
0x01 Logstash架构
Logstash 是由 JRuby 编写的,使用基于消息的简单架构,在 JVM 上运行。理念非常简单,如果说 MapReduce 框架分为 Mapper 和 Reducer 两大模块,那么 Logstash 有
Collect: 数据输入。对应 input Enrich: 数据处理。对应 filter Transport: 数据输出。对应 output
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats) filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
虽然模块仅仅比 MapReduce 框架多了一个,但是无三不成几,通过不同的拓扑结构,可以完成各类数据处理应用。不过这里我们主要还是以日志汇总处理系统的思路来进行介绍,一个典型的架构为: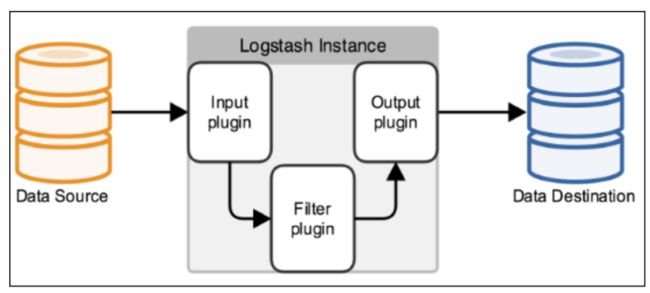
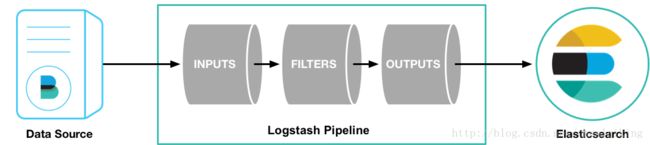
0x02 Logstash安装
1. 环境清单
- 操作系统:CentOS Linux release 7.3.1611
- Logstash版本:logstash-5.4.1
- Jdk版本:1.8.0_131
2. 软件下载
- 下载Jdk:
[root@root ~]$ wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
- 下载Logstash:
[root@root ~]$ wget https://artifacts.elastic.co/downloads/logstash/logstash-5.4.1.tar.gz
3. 安装Jdk
- 创建安装目录
[root@root ~]$ sudo mkdir /usr/local/Java
- 解压缩安装文件
## 移动安装包到安装目录 ## [root@root ~]$ sudo mv jdk-8u131-linux-x64.tar.gz /usr/local/Java/ ## 进入安装目录 ## [root@root ~]$ cd /usr/local/Java/ ## 解压缩安装包 ## [root@root Java]$ sudo tar -zxvf jdk-8u131-linux-x64.tar.gz ## 删除安装包 ## [root@root Java]$ sudo rm jdk-8u131-linux-x64.tar.gz
- 测试安装是否成功
## 进入JAVA_HOME ## [root@root Java]$ cd jdk1.8.0_131/ ## 测试java命令是否可以正常执行 ## [root@root jdk1.8.0_131]$ ./bin/java -version
- 配置JAVA_HOME环境变量
[root@root ~]$ cd ~ [root@root ~]$ vi .bash_profile # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs ## 配置JAVA_HOME环境变量 ## JAVA_HOME=/usr/local/Java/jdk1.8.0_131 ## 将java执行目录加入到PATH下面 ## PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin export PATH ~ ## 使环境变量生效 ## [root@root ~]$ source .bash_profile ## 测试JAVA_HOME是否正确配置 ## [root@root ~]$ java -version
4. 安装Logstash
- 创建安装目录
[root@root ~]$ sudo mkdir /usr/local/logstash
- 解压缩安装文件
[root@root ~]$ sudo mv logstash-5.4.1.tar.gz /usr/local/logstash/ [root@root ~]$ cd /usr/local/logstash/ [root@root logstash]$ sudo tar -zxvf logstash-5.4.1.tar.gz
测试安装是否成功
- 测试一、快速启动,标准输入输出作为input和output,没有filter
[root@root logstash]$ cd logstash-5.4.1/ [root@root logstash-5.4.1]$ ./bin/logstash -e 'input { stdin {} } output { stdout {} }' Sending Logstash's logs to /usr/local/logstash/logstash-5.4.1/logs which is now configured via log4j2.properties [2018-10-31T13:37:13,449][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/usr/local/logstash/logstash-5.4.1/data/queue"} [2018-10-31T13:37:13,467][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"dcfdb85f-9728-46b2-91ca-78a0d6245fba", :path=>"/usr/local/logstash/logstash-5.4.1/data/uuid"} [2018-10-31T13:37:13,579][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>250} [2018-10-31T13:37:13,612][INFO ][logstash.pipeline ] Pipeline main started The stdin plugin is now waiting for input: [2018-10-31T13:37:13,650][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} ## 此时命令窗口停留在等待输入状态,键盘键入任意字符 ## hello world ## 下方是Logstash输出到效果 ## 2018-10-31T12:21:14.401Z logstash.master hello world
- 测试二、在测试一堆基础上加上codec进行格式化输出
[root@root logstash-5.4.1]$ ./bin/logstash -e 'input{stdin{}} output{stdout{codec=>rubydebug}}'
Sending Logstash's logs to /usr/local/logstash/logstash-5.4.1/logs which is now configured via log4j2.properties
[2018-10-31T14:01:50,325][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>250}
[2018-10-31T14:01:50,356][INFO ][logstash.pipeline ] Pipeline main started
The stdin plugin is now waiting for input:
[2018-10-131T14:01:50,406][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
## 此时命令窗口停留在等待输入状态,键盘键入任意字符 ##
hello world
## 下方是Logstash输出到效果 ##
{
"@timestamp" => 2018-10-31T06:02:19.189Z,
"@version" => "1",
"host" => "chenlei.master",
"message" => "hello world"
}
0x03 Logstash参数与配置
Logstash宏观的配置文件内容格式如下:
# 输入 input { ... } # 过滤器 filter { ... } # 输出 output { ... }
配置文件参考
input { # 从文件读取日志信息 file { path => "/var/log/error.log" type => "error"//type是给结果增加一个type属性,值为"error"的条目 start_position => "beginning"//从开始位置开始读取 # 使用 multiline 插件,传说中的多行合并 codec => multiline { # 通过正则表达式匹配,具体配置根据自身实际情况而定 pattern => "^\d" negate => true what => "previous" } } } #可配置多种处理规则,他是有顺序,所以通用的配置写下面 # filter { # grok { # match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" } } # } output { # 输出到 elasticsearch elasticsearch { hosts => ["192.168.22.41:9200"] index => "error-%{+YYYY.MM.dd}"//索引名称 } }
上面的file可以配置多个:
file { type => "tms_inbound.log" path => "/JavaWeb/tms2.wltest.com/logs/tms_inbound.es.*.log" codec => json { charset => "UTF-8" } } file { type => "tms_outbound.log" path => "/JavaWeb/tms2.wltest.com/logs/tms_outbound.es.*.log" codec => json { charset => "UTF-8" } }
1. 常用启动参数
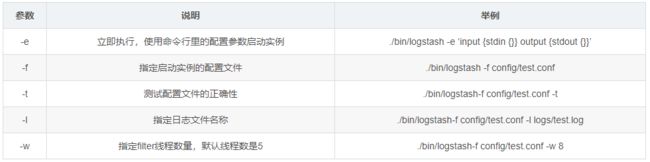
2. 配置文件结构及语法
-
区段
Logstash通过
{}来定义区域,区域内可以定义插件,一个区域内可以定义多个插件,如下:
input { stdin { } beats { port => 5044 } }
- 数据类型
Logstash仅支持少量的数据类型:
Boolean:ssl_enable => true
Number:port => 33
String:name => “Hello world”
Commonts:# this is a comment
- 字段引用
Logstash数据流中的数据被称之为Event对象,Event以JSON结构构成,Event的属性被称之为字段,如果你像在配置文件中引用这些字段,只需要把字段的名字写在中括号[]里就行了,如[type],对于嵌套字段每层字段名称都写在[]里就可以了,比如:[tags][type];除此之外,对于Logstash的arrag类型支持下标与倒序下表,如:[tags][type][0],[tags][type][-1]。
- 条件判断
Logstash支持下面的操作符:
equality:==, !=, <, >, <=, >=
regexp:=~, !~
inclusion:in, not in
boolean:and, or, nand, xor
unary:!
例如:
if EXPRESSION { ... } else if EXPRESSION { ... } else { ... }
- 环境变量引用
Logstash支持引用系统环境变量,环境变量不存在时可以设置默认值,例如:
export TCP_PORT=12345
input { tcp { port => "${TCP_PORT:54321}" } }
0x04 常用输入插件(Input Plug)
1. File读取插件
文件读取插件主要用来抓取文件的变化信息,将变化信息封装成Event进程处理或者传递。
- 配置事例
input file { path => ["/var/log/*.log", "/var/log/message"] type => "system" start_position => "beginning" } }
- 常用参数
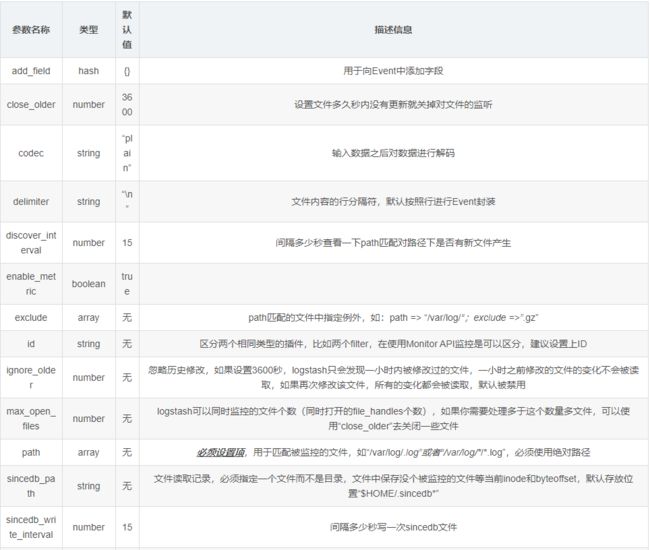

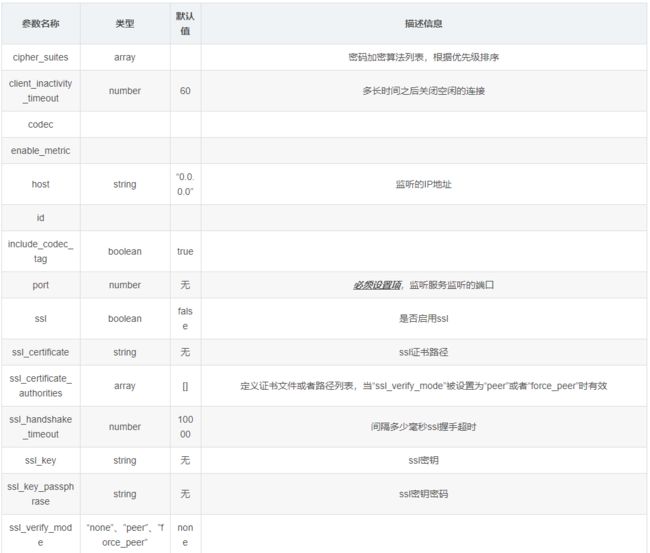
2. Beats监听插件
Beats插件用于建立监听服务,接收Filebeat或者其他beat发送的Events;
- 配置事例
input { beats { port => 5044 } }
- 常用参数(空 => 同上)

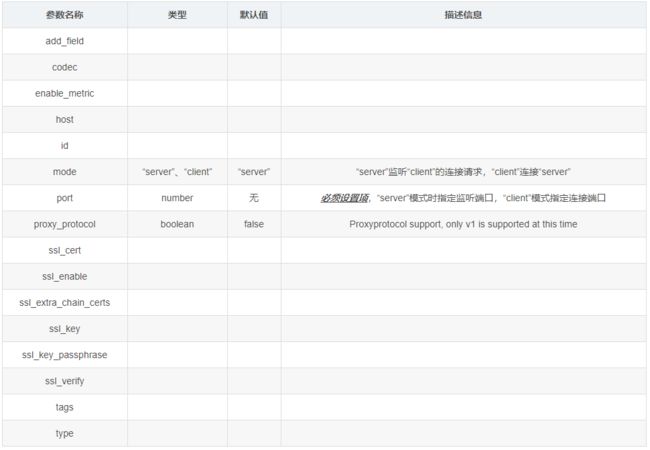
3. TCP监听插件
TCP插件有两种工作模式,“Client”和“Server”,分别用于发送网络数据和监听网络数据。
- 配置事例
tcp { port => 41414 }
- 常用参数(空 => 同上)
4. Redis读取插件
用于读取Redis中缓存的数据信息。
- 最小化配置
input {
redis {
data_type => "list" #logstash redis插件工作方式
key => "logstash-test-list" #监听的键值
host => "127.0.0.1" #redis地址
port => 6379 #redis端口号
}
}
output {
stdout{}
}
- 详细配置
input { redis { batch_count => 1 #EVAL命令返回的事件数目 data_type => "list" #logstash redis插件工作方式 key => "logstash-test-list" #监听的键值 host => "127.0.0.1" #redis地址 port => 6379 #redis端口号 password => "123qwe" #如果有安全认证,此项为密码 db => 0 #redis数据库的编号 threads => 1 #启用线程数量 } } output { stdout{} }
5. Syslog监听插件
监听操作系统syslog信息
- 配置事例
syslog {
}
- 输出至屏幕
[root@node1 conf.d]# cat syslog.conf input{ syslog{ type => "system-syslog" port => 514 } } filter{ } output{ stdout{ codec => rubydebug } } [root@node1 conf.d]# /opt/logstash/bin/logstash -f syslog.conf
- 修改rsyslog配置文件
[root@node1 ~]# vim /etc/rsyslog.conf *.* @@192.168.79.103:514 [root@node1 ~]# systemctl restart rsyslog
- 输出至es
[root@node1 conf.d]# cat syslog.conf input{ syslog{ type => "system-syslog" port => 514 } } filter{ } output{ elasticsearch{ hosts => ["192.168.79.103:9200"] index => "system-syslog-%{+YYYY.MM}" } } [root@node1 conf.d]# /opt/logstash/bin/logstash -f syslog.conf
0x05 常用过滤插件(Filter plugin)
丰富的过滤器插件的是 logstash威力如此强大的重要因素,过滤器插件主要处理流经当前Logstash的事件信息,可以添加字段、移除字段、转换字段类型,通过正则表达式切分数据等,也可以根据条件判断来进行不同的数据处理方式。
1. grok正则捕获
grok 是Logstash中将非结构化数据解析成结构化数据以便于查询的最好工具,非常适合解析syslog logs,apache log, mysql log,以及一些其他的web log
预定义表达式调用
Logstash提供120个常用正则表达式可供安装使用,安装之后你可以通过名称调用它们,语法如下:%{SYNTAX:SEMANTIC}
SYNTAX:表示已经安装的正则表达式的名称
SEMANTIC:表示从Event中匹配到的内容的名称
例如:Event的内容为“[debug] 127.0.0.1 - test log content”,匹配%{IP:client}将获得“client: 127.0.0.1”的结果,前提安装了IP表达式;如果你在捕获数据时想进行数据类型转换可以使用%{NUMBER:num:int}这种语法,默认情况下,所有的返回结果都是string类型,当前Logstash所支持的转换类型仅有“int”和“float”;
一个稍微完整一点的事例:
日志文件http.log内容:55.3.244.1 GET /index.html 15824 0.043
表达式:%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
配置文件内容:
input { file { path => "/var/log/http.log" } } filter { grok { match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"} } }
输出结果:
client: 55.3.244.1 method: GET request: /index.html bytes: 15824 duration: 0.043
- 自定义表达式调用
语法:(?
举例:捕获10或11和长度的十六进制queue_id可以使用表达式(?
- 安装自定义表达式
与预定义表达式相同,你也可以将自定义的表达式配置到Logstash中,然后就可以像于定义的表达式一样使用;以下是操作步骤说明:
1、在Logstash根目录下创建文件夹“patterns”,在“patterns”文件夹中创建文件“extra”(文件名称无所谓,可自己选择有意义的文件名称);
2、在文件“extra”中添加表达式,格式:patternName regexp,名称与表达式之间用空格隔开即可,如下:
# contents of ./patterns/postfix: POSTFIX_QUEUEID [0-9A-F]{10,11}
3、使用自定义的表达式时需要指定“patterns_dir”变量,变量内容指向表达式文件所在的目录,举例如下:
## 日志内容 ## Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>
## Logstash配置 ## filter { grok { patterns_dir => ["./patterns"] match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" } } }
## 运行结果 ## timestamp: Jan 1 06:25:43 logsource: mailserver14 program: postfix/cleanup pid: 21403 queue_id: BEF25A72965
- grok常用配置参数(空 => 同上)
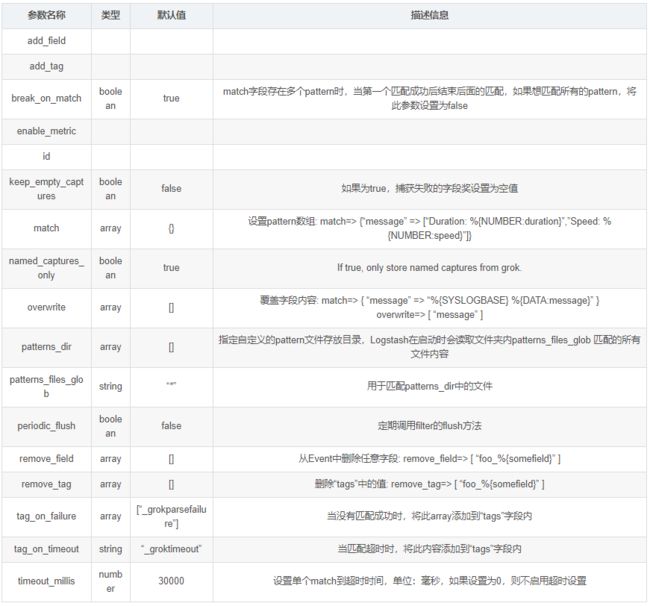
- 其他
- 一般的正则表达式只能匹配单行文本,如果一个Event的内容为多行,可以在pattern前加“(?m)”
- 对于Hash和Array类型,Hash表示键值对,Array表示数组
- Grok表达式在线debug地址:http://grokdebug.herokuapp.com
- 预定义正则表达式参考地址:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
2. date时间处理插件
该插件用于时间字段的格式转换,比如将“Apr 17 09:32:01”(MMM dd HH:mm:ss)转换为“MM-dd HH:mm:ss”。而且通常情况下,Logstash会为自动给Event打上时间戳,但是这个时间戳是Event的处理时间(主要是input接收数据的时间),和日志记录时间会存在偏差(主要原因是buffer),我们可以使用此插件用日志发生时间替换掉默认是时间戳的值。
- 常用配置参数(空 => 同上)
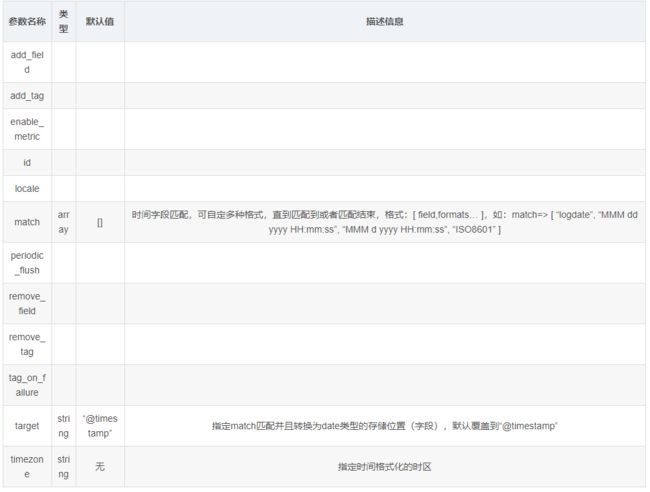
3. mutate数据修改插件
mutate 插件是 Logstash另一个重要插件。它提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
# logstash-filter-mutate 插件是Logstash 另一个重要插件,它提供了丰富的基础类型数据处理能力,包括类型转换,字符串处理和字段处理等 #1.类型转换 #类型转换是logstash-filter-mutate 插件最初诞生时的唯一功能, #可以设置的转换类型包括:"integer","float" 和 "string"。示例如下: input { stdin { } } filter { grok { match =>{ "message" =>"(?\d+(?:\.\d+)?) " } } } output { stdout { codec =>rubydebug } } [elk@Vsftp logstash]$ logstash -f t2.conf Settings: Default pipeline workers: 4 Pipeline main started 23.45 { "message" => "23.45", "@version" => "1", "@timestamp" => "2017-01-11T02:07:33.581Z", "host" => "Vsftp", "request_time" => "23.45" }
#字符串 转换为float型 [elk@Vsftp logstash]$ cat t2.conf input { stdin { } } filter { grok { match =>{ "message" =>"(?\d+(?:\.\d+)?) " } } mutate { convert => ["request_time", "float"] } } output { stdout { codec =>rubydebug } } [elk@Vsftp logstash]$ logstash -f t2.conf Settings: Default pipeline workers: 4 Pipeline main started 23.45 { "message" => "23.45", "@version" => "1", "@timestamp" => "2017-01-11T02:10:07.045Z", "host" => "Vsftp", #字符串转换成数值型: [elk@Vsftp logstash]$ cat t2.conf input { stdin { } } filter { grok { match =>{ "message" =>"(?\d+(?:\.\d+)?) " } } mutate { convert => ["request_time", "integer"] } } output { stdout { codec =>rubydebug } } [elk@Vsftp logstash]$ logstash -f t2.conf Settings: Default pipeline workers: 4 Pipeline main started 23.45 { "message" => "23.45", "@version" => "1", "@timestamp" => "2017-01-11T02:11:21.071Z", "host" => "Vsftp", "request_time" => 23
4. JSON插件
JSON插件用于解码JSON格式的字符串,一般是一堆日志信息中,部分是JSON格式,部分不是的情况下
- 配置事例
json { source => ... }
## 事例配置,message是JSON格式的字符串:"{\"uid\":3081609001,\"type\":\"signal\"}" ## filter { json { source => "message" target => "jsoncontent" } }
## 输出结果 ## { "@version": "1", "@timestamp": "2014-11-18T08:11:33.000Z", "host": "web121.mweibo.tc.sinanode.com", "message": "{\"uid\":3081609001,\"type\":\"signal\"}", "jsoncontent": { "uid": 3081609001, "type": "signal" } } ## 如果从事例配置中删除`target`,输出结果如下 ## { "@version": "1", "@timestamp": "2014-11-18T08:11:33.000Z", "host": "web121.mweibo.tc.sinanode.com", "message": "{\"uid\":3081609001,\"type\":\"signal\"}", "uid": 3081609001, "type": "signal" }
- 常用配置参数(空 => 同上)
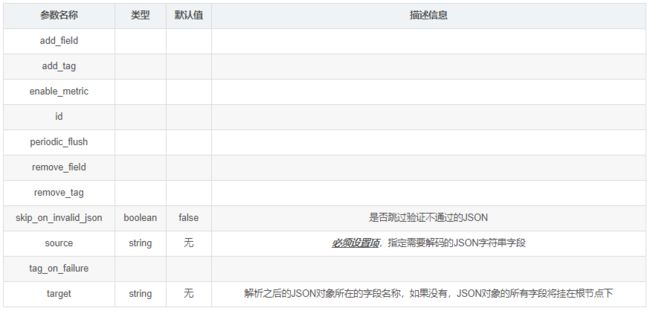
5. elasticsearch查询过滤插件
用于查询Elasticsearch中的事件,可将查询结果应用于当前事件中
- 常用配置参数(空 => 同上)
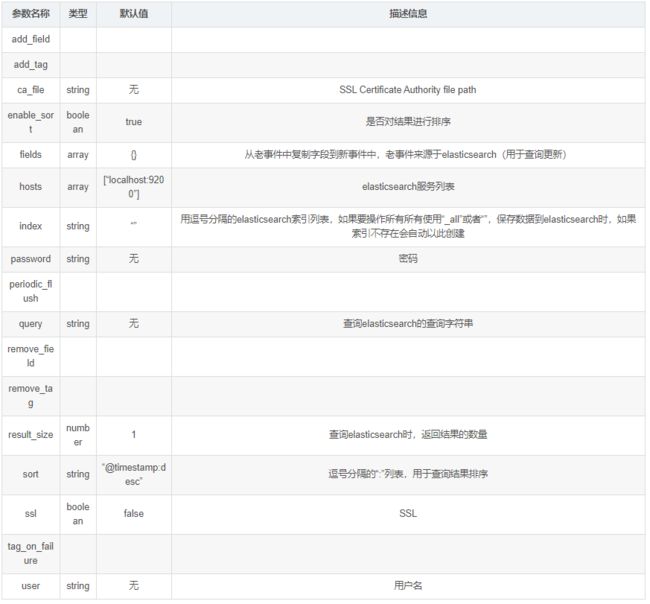
6. 其他
还有很多其他有用插件,如:Split、GeoIP、Ruby,这里就不一一写了,等以后用到再补充
0x06 常用输出插件(Output plugin)
1. ElasticSearch输出插件
用于将事件信息写入到Elasticsearch中,官方推荐插件,ELK必备插件
- 配置事例
output { elasticsearch { hosts => ["127.0.0.1:9200"] index => "filebeat-%{type}-%{+yyyy.MM.dd}" template_overwrite => true } }
- 常用配置参数(空 => 同上)
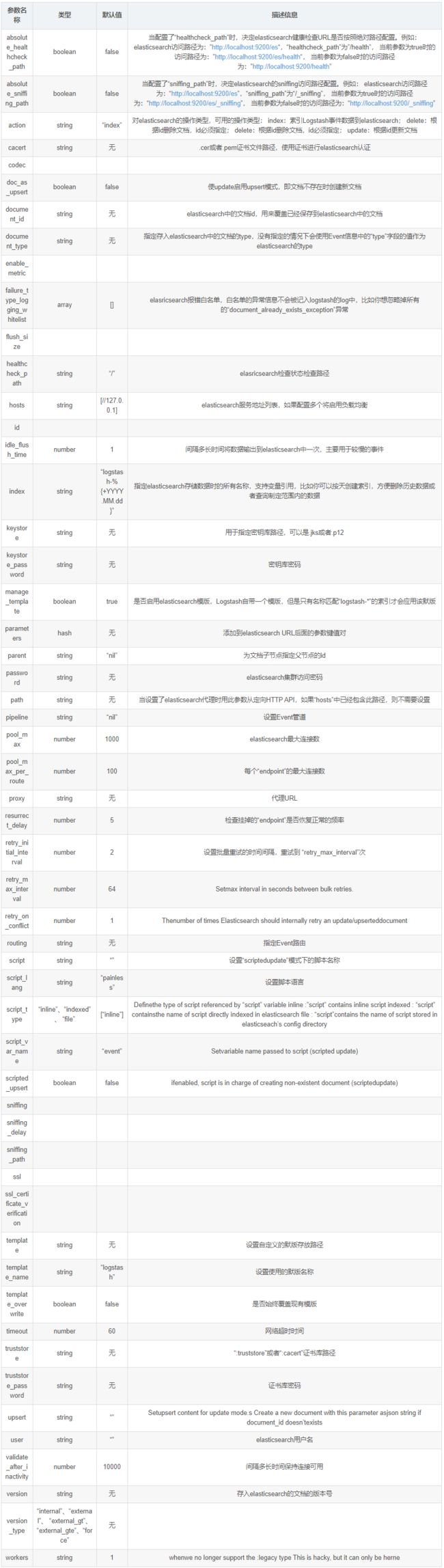
2、Redis输出插件
用于将Event写入Redis中进行缓存,通常情况下Logstash的Filter处理比较吃系统资源,复杂的Filter处理会非常耗时,如果Event产生速度比较快,可以使用Redis作为buffer使用
- 配置事例
output { redis { host => "127.0.0.1" port => 6379 data_type => "list" key => "logstash-list" } }
- 常用配置参数(空 => 同上)
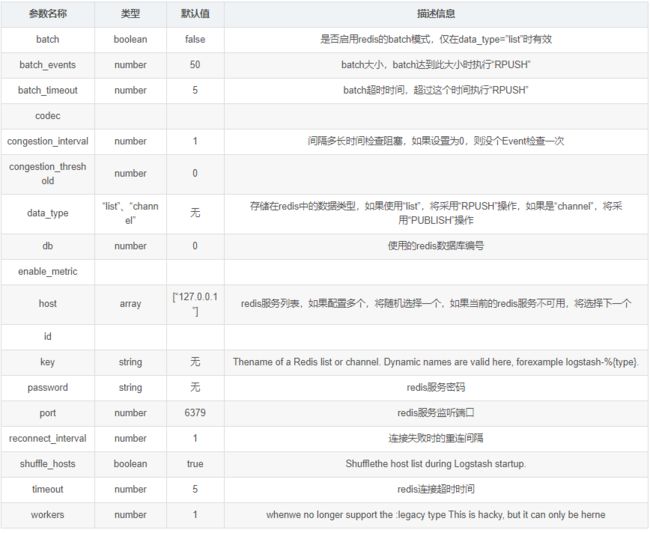
3. File输出插件
用于将Event输出到文件内
- 配置事例
output { file { path => ... codec => line { format => "custom format: %{message}"} } }
- 常用配置参数(空 => 同上)
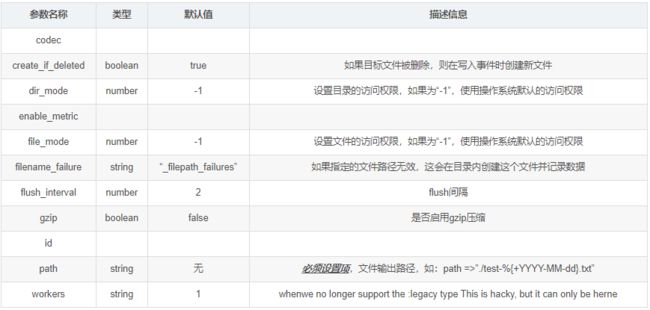
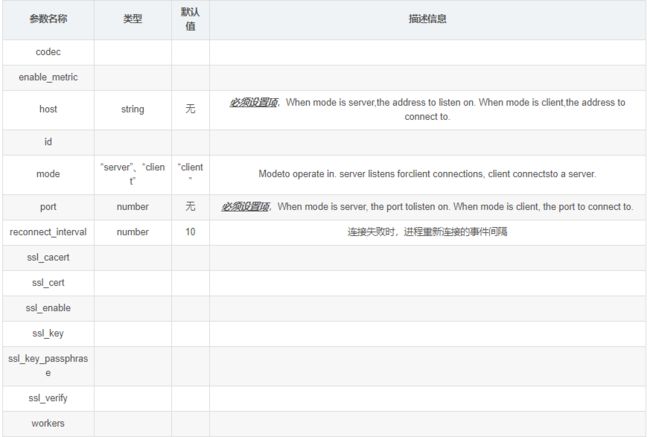
4. TCP插件
Write events over a TCP socket.Each event json is separated by a newline.Can either accept connections from clients or connect to a server, depending on mode.
- 配置事例
tcp { host => ... port => ... }
- 常用配置参数(空 => 同上)
0x07 常用编码插件(Codec plugin)
1. JSON编码插件
直接输入预定义好的 JSON 数据,这样就可以省略掉 filter/grok 配置
- 配置事例
json {
}
- 常用配置参数

0x08 Logstash实例
1. 接收Filebeat事件,输出到Redis
input { beats { port => 5044 } } output { redis { host => "127.0.0.1" port => 6379 data_type => "list" key => "logstash-list" } }
2. 读取Redis数据,根据“type”判断,分别处理,输出到ES
input { redis { host => "127.0.0.1" port => 6379 data_type => "list" key => "logstash-list" } } filter { if [type] == "application" { grok { match => ["message", "(?m)-(?.+?):(? "] } date { match => ["logTime", "yyyy-MM-dd HH:mm:ss,SSS"] } json { source => "message" } date { match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"] } } if [type] == "application_bizz" { json { source => "message" } date { match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"] } } mutate { remove_field => ["@version", "beat", "logTime"] } } output { stdout{ } elasticsearch { hosts => ["127.0.0.1:9200"] index => "filebeat-%{type}-%{+yyyy.MM.dd}" document_type => "%{documentType}" template_overwrite => true } }(?>\d\d){1,2}-(?:0?[1-9]|1[0-2])-(?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) (?:2[0123]|[01]?[0-9]):(?:[0-5][0-9]):(?:(?:[0-5][0-9]|60)(?:[:.,][0-9]+)?)) \[(? (\b\w+\b)) *\] (? (\b\w+\b)) \((? .*?)\) - (? .*)
0x09 Logstash注意事项
- 问题记录
启动logstash慢,输入./bin/logstash没有反应,多出现在新安装的操作系统上
- 原因
jruby启动的时候jdk回去从/dev/random中初始化随机数熵,新版本的jruby会用RPNG算法产生随后的随机数,但是旧版本的jruby会持续从/dev/random中获取数字。但是不幸的是,random发生器会跟不上生成速度,所以获取随机数的过程会被阻塞,直到随机数池拥有足够的熵然后恢复。这在某些系统上,尤其是虚拟化系统,熵数池可能会比较小从而会减慢jruby的启动速度。
检查一下系统的熵数池 cat /proc/sys/kernel/random/entropy_avail,正常情况这个数字推荐大于1000,对比了一下独立主机的这个数值,大约在700-900之间晃悠。
- 解决
使用伪随机,编辑/usr/local/logstash/logstash-5.4.1/config/jvm.options,在最后增加一行:-Djava.security.egd=file:/dev/urandom
- 参考
https://github.com/elastic/logstash/issues/5507
http://www.tuicool.com/articles/jEBBZbb
参考