Parameter-efficient transfer learning系列之LoRA与BitFit
每天给你送来NLP技术干货!
来自:NLP日志
提纲
1 简介
2 LoRA
3 Bitfit
4 总结
参考文献
1 简介
NLP一个重要的范式包括在通用领域数据上的大规模预训练和在特定任务或者领域上的微调。目前大规模语言模型在诸多任务上取得sota效果,Finetune全模型参数以适配下游任务虽然能取得不错的效果,但是却是一种低效的参数更新方式,归因于模型的庞大模型参数量带来的训练成本,从而限制了在诸多下游任务的应用。
在这个章节我们介绍另外两种高效的参数更新方式,LoRA与BitFit,一种通过在transformer结构中固定原本的模型参数同时引入可训练的分解矩阵,另一种通过只更新模型中的bias参数,都能极大程度的减少下游任务需要训练的参数数量,提高训练速度并且取得不错的效果。
2 LoRA
神经网络包含很多全连接层,借助于矩阵乘法得以实现,很多全连接层的权重矩阵都是满秩的。当针对特定任务训练时,预训练模型具有low intrinsic dimension,尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定任务这些权重矩阵就不要求满秩。基于此,LoRA(Low-Rank Adaptaion)被提出,它的想法也很朴素直观。在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的intrinsic rank。在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx。通常第一个矩阵的A的权重参数会通过高斯函数得到,而第二个矩阵的B的参数则是零矩阵,这样能保证训练开始时新增的通路BA=0从而对mo xing 结果没有影响。在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,不会增加额外的计算资源。
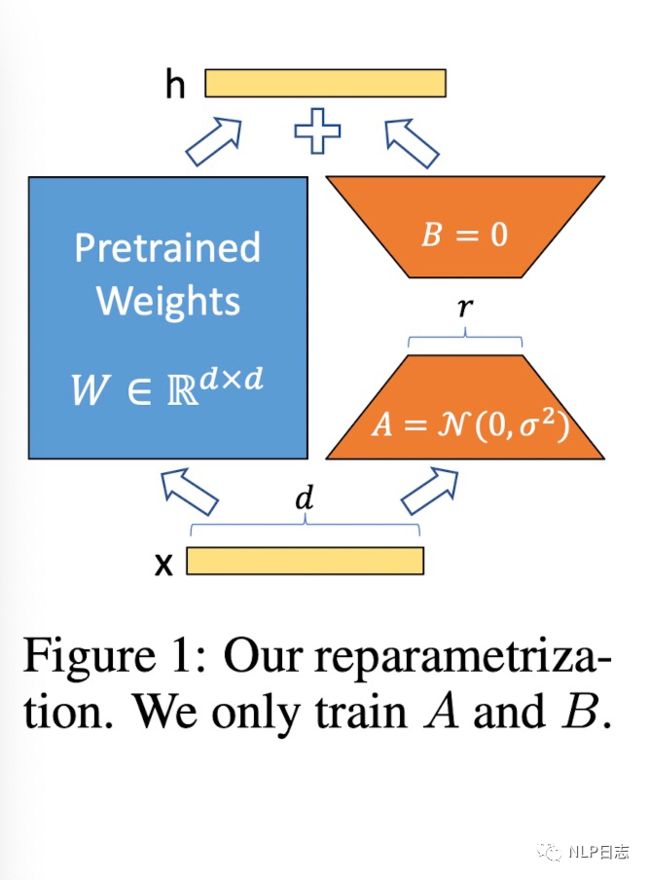
图1:LoRA框架
一般情况下,r会远小于模型原本的维度m,所以LoRA训练的模型参数相比于模型原本的参数而言非常轻量,对于下游任务而言,原本的模型参数可以公摊到多个下游任务中去,每个下游任务只独立维护自身的LoRA的矩阵BA参数,从而省下了大量内存跟存储资源。同时,冻结语言模型原本的参数,只更新新增通路的少量参数也能节省大量计算资源跟IO成本,从而提升模型训练速度。
通过实验也发现,在众多数据集上LoRA在只训练极少量参数的前提下,达到了匹配训练全部参数的finetune方式,是一种高效的参数更新方法。相比其他高效的参数训练方式,类似Adapter, BitFit,LoRA在较少训练参数时就能保证比较稳定的效果。而prefix等方式则会由于插入了更多token导致输入的分布偏离预训练数据分布,从而导致精度下降。
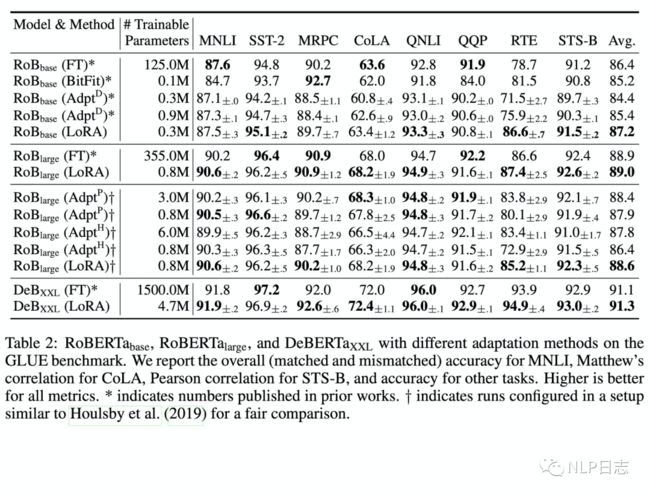
图2:LoRA的效果

图3:各种参数更新方法下模型效果跟可训练参数量的关系
此外,Transformer的权重矩阵包括attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于attention模块中的4种权重矩阵,而且通过消融实验发现其中Wq,Wk两者不可缺失。同时,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间,这也显示了低秩的中间矩阵A跟B对于LoRA已经足够了。
3 BitFit
这是一种稀疏的finetune方法,它只在训练时更新bias的参数(或者部分bias参数)。对于transformer模型而言,冻结大部分模型参数,只训练更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果的涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。像Bert base跟Bert large这种模型里的bias参数占模型全部参数量的0.08%~0.09%。
通过实验可以看出,Bitfit在只更新极少量参数下在多个数据集上都达到了不错的效果,虽不及训练全部参数的finetune,但是远超固定全部模型参数的Frozen方式。同时,通过比起Bitfit训练前后的参数对比,发现很多bias参数没有太多变化,例如跟计算key所涉及到的bias参数。发现其中计算query与将特征维度从N放大到4N的FFN层的bias参数变化最为明显,只更新这两类bias参数也能达到不错的效果,反之,固定其中任何一者,模型的效果都有较大损失。
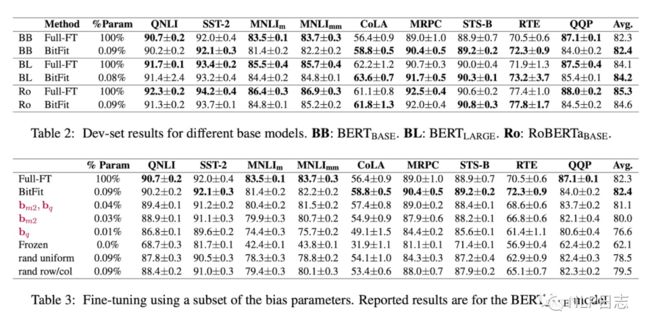
图4:BitFit效果
4 总结
上述这两种参数优化方法都是在Adapter之后提出的,相比adapter需要在原模型基础上加入了额外模块,虽然减少了训练成本跟存储资源,但在推理时却也不可避免的增加了计算资源从而增加了耗时。但LoRA跟Biffit在推理时跟原语言模型结果保持一致,没有额外的计算资源。
参考文献
1. (2021,) LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS
https://arxiv.org/pdf/2106.09685v2.pdf
2. (2022,) Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models
https://arxiv.org/pdf/2106.10199.pdf
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
苏州大学NLP团队文本生成&预训练方向招收研究生/博士生(含直博生)
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~