C++对多继承的理解
学到C++时我们知道了继承但是一般都是使用单继承为主,单继承就是一个子类只能继承一个父类而多继承是指一个子类可以同时继承多个父类。
菱形继承
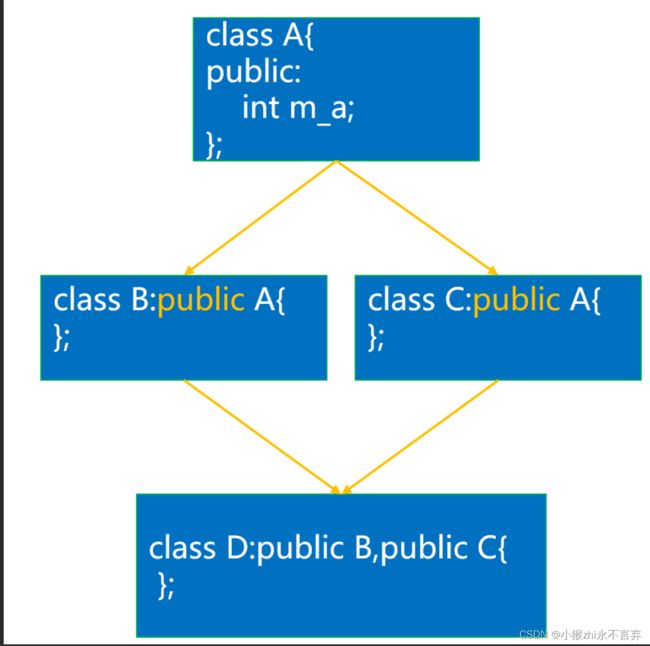
菱形继承是多继承中的一个特殊情况。当一个子类同时继承两个具有共同父类的类时,就会出现菱形继承问题。但是这种情况下,子类会继承同一个父类的特性和方法两次,导致特性和方法的冗余。
代码视角的菱形继承
class Person
{
public:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _num; //学号
};
class Teacher : public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};此时如果Assistant创建a对象时,如果此时访问a对象的_name成员时(也就是People类里的成员)就产生了歧义,因为此时存在两种情况:访问的是Student类里的_name成员,也可能是Teacher类里的_name成员。所以就产生了二义性的问题。
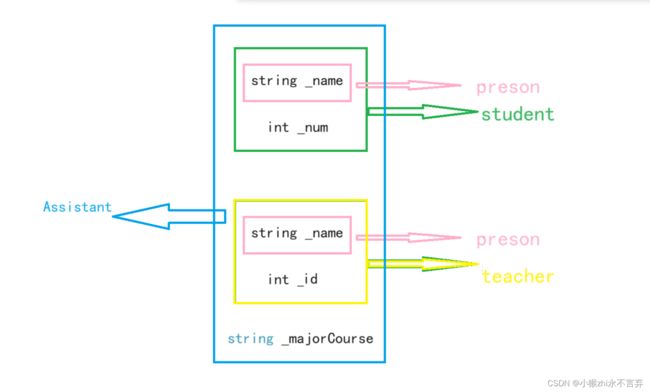
但是也是有解决方法的:指定类成员
a.Student::_name = "陈同学";
a.Teacher::_name = "陈老师";
但是这样就显得代码十分冗余看起来就十分别扭。这种菱形继承就相当于是继承同一父类两次,这是完全没必要的,就像你一个人身份证上不可能有两个名字吧
解决策略
虚继承(virtual inheritance):在父类之间的继承关系中,使用关键字virtual来声明继承关系。这样在派生类中只会有一份共同祖先的数据,从而避免了冗余数据的问题。
//在存在数据冗余的基类下的派生类加上virtual关键字
class Person
{
public:
string _name; // 姓名
};
class Student : virtual public Person//
{
protected:
int _num; //学号
};
class Teacher : virtual public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};所以此时就只有一份Person数据了。
验证:(即使指定类初始化也是进行统一初始化)

虚继承中的内存关系
class A
{
public:
int _a;
};
class B:virtual public A
{
public:
int _b;
};
class C:virtual public A
{
public:
int _c;
};
class D :public B, public C
{
public:
int _d;
};先看看非虚拟继承数据的存储空间:
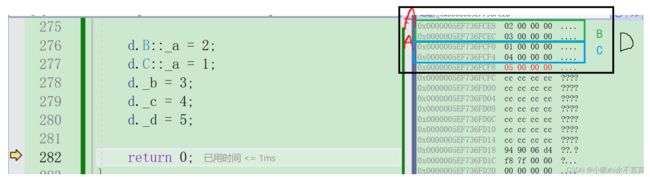
虚继承下的数据空间地址:(32位机器测试)
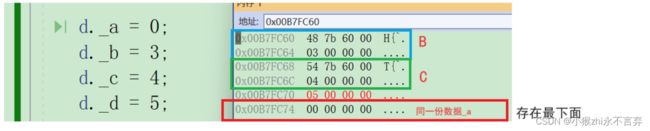 但是为什么存在二义性的数据公有一份后类B和类C里还存了一个一个类似地址的东西,那么在内存窗口查看一下:
但是为什么存在二义性的数据公有一份后类B和类C里还存了一个一个类似地址的东西,那么在内存窗口查看一下:
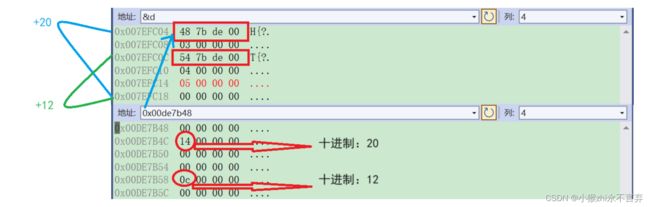
经过分析可以了解到非虚拟继承时的共有数据存放的位置在虚拟继承时存放的是一个地址,而该地址下存放的数据恰恰就是与共有的祖先数据的偏移量。就相当于为D类创建了一个偏移量表(不占D对象内存),以便为D创建多个对象都可以用该表查看偏移量从而找到共同祖先数据。
为什么要存一个地址:
其实这样做的目的就是以便父子类对象的赋值。因为在继承关系中,子类继承了父类的特性和方法。子类和父类之间是一种"is-a"的关系。"is-a"关系表示子类是父类的一种类型。所以子类对象赋值给父类是天然的,不会产生临时对象。这也叫作父子类赋值兼容规则(切割/切片)。相当于将子类多余父类的数据切割再赋值给父类。
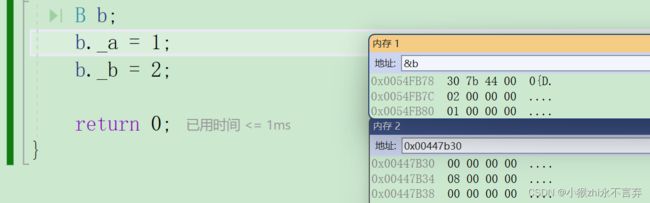
而在虚拟继承中同样是满足父子类复制兼容的,所以就拿上代码来说当我们B b=d;的过程时B类中并没有A类的成员数据,所以说就将类似B类这种类再存一个指针,而指针中存的就是改地址处与A类成员地址的偏移量,所以在赋值的过程中编译器就会以这种方式来寻找A类的成员数据。
其实虚继承以后不仅仅是D类的对象数据是这样的存储方式,其实B类C类创建的对象也是这种存储方式。
继承和组合
继承是指一个类(称为派生类或子类)可以从另一个类(称为基类或父类)中继承属性。
组合是指一个类可以包含其他类的对象作为自己的成员。
在继承关系中,子类继承了父类的特性和方法,但父类并不是子类的成员对象。public继承,子类和父类之间是一种"is-a"的关系,而不是"has-a"的关系。"is-a"关系表示子类是父类的一种类型,而"has-a"关系表示一个类具有另一个类的成员对象。而组合的两个类就是"has-a"的关系。
通过继承,派生类可以重用基类的代码和功能,并可以扩展或修改这些功能。继承可以建立类之间的"是一个"关系,其中派生类是基类的一种类型。继承可以实现代码的重用和面向对象编程的多态性。
通过组合,一个类可以将其他类的对象组合起来实现更复杂的功能。组合可以建立类之间的"具有"关系,其中包含对象是类的一部分。通过组合,可以灵活地构建类之间的关系,实现更灵活和模块化的设计。
选择使用
选择继承还是组合取决于具体的场景和需求。一般来说,当两个类之间存在"是一个"关系,并且派生类需要重用基类的代码和功能时,使用继承更合适。而当两个类之间存在"具有"关系,并且一个类需要使用另一个类的功能,但并不满足"是一个"关系时,使用组合更合适。
但是一般能使用组合尽量使用组合。组合的耦合度低,代码维护性更好。
有关继承的题目
test_1
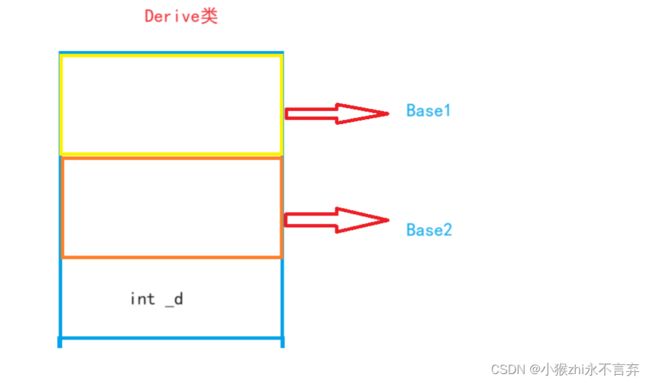
class Base1 { public: int _b1; }; class Base2 { public: int _b2; }; class Derive : public Base1, public Base2 //先继承的先创建 { public: int _d; }; int main() { Derive d; Base1* p1 = &d; Base2* p2 = &d; Derive* p3 = &d; return 0; }//判断p1 p2 p3的关系???分析:先创建Derive类的对象,而Derive类同时也继承了Base1和Base2这两个类,所以地址空间模拟图应该是:
因为Base1继承在Base2的前面,所以Base1先被创建出来,所以p1和p3都是指向起始处,所以地址值是相同的,但是两个指针指向的内容范围是不同。而Base2就显然不同于Base1。

test_2(虚拟继承)
class A { public: A(const char* s) { cout << s << endl; } ~A() {} }; class B :virtual public A { public: B(const char* s1, const char* s2) :A(s1) { cout << s2 << endl; } }; class C :virtual public A { public: C(const char* s1, const char* s2) :A(s1) { cout << s2 << endl; } }; class D :public B, public C { public: D(const char* s1, const char* s2, const char* s3, const char* s4) :B(s1, s2), C(s1, s3), A(s1) { cout << s4 << endl; } }; int main() { D* p = new D("class A", "class B", "class C", "class D"); delete p; return 0; }首先是new并且初始化一个D类的对象,此时不难看出ABCD四个类呈现菱形继承的关系,而且还是虚拟继承。所以可以明确类A只会创建一份。D类的初始化列表中显示调用了其父类的构造函数,但是初始化列表的顺序并不是真的调用顺序,这依赖于继承顺序。所以再看D类的继承顺序是B类在前C类在后,所以先创建B类,但是此时别急构造,B类虚拟继承了A类所以想要创建B类之前是先构造A类,所以最先调用构造函数的一定是A类,其次就是B类,再C类,虽然初始化列表最后还显示调用了A类的构造函数,但是这是虚拟继承,所以实际上并不会再多调用一次。

成员变量初始化:成员变量走初始化列表进行初始化的顺序是依据于成员变量在类里被声明的顺序
继承类的初始化:先继承的先初始化即先被调用