NVIDIA NCCL 源码学习(十一)- ring allreduce
之前的章节里我们看到了nccl send/recv通信的过程,本节我们以ring allreduce为例看下集合通信的过程。整体执行流程和send/recv很像,所以对于相似的流程只做简单介绍,主要介绍ring allreduce自己特有内容。
单机
搜索ring
在nccl初始化的过程中会分析机内拓扑,建立CPU,GPU,网卡等PCI节点的拓扑图,并基于这个图搜索一系列的channel,假设单机内执行ncclTopoCompute搜索出的ring为:
graph->intra: GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7
接着设置每个channel中ncclRing的prev和next,表示当前rank的前后的GPU,例如GPU0的prev为GPU7,next为GPU1
建链
然后开始建立当前rank到prev和next GPU的链接
for (int c=0; c<comm->nChannels; c++) {
struct ncclChannel* channel = comm->channels+c;
NCCLCHECKGOTO(setupChannel(comm, c, rank, nranks, rings+c*nranks), ret, affinity_restore);
if (comm->nRanks == 1) continue;
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, &ringGraph, channel, 1, &channel->ring.prev, 1, &channel->ring.next), ret, affinity_restore);
}
链接建立完成之后如下图所示,buff位于发送端,head和tail为send端recv端共同持有。
为了后续表述方便,这里做一下约定,假设send端为rank0,recv端为rank1,sendbuff指的是用户执行api传进来的输入,recvbuff指的是用户执行api传进来的输出;buffer指的是图一所示的buff;实际rank0将数据发送给rank1的流程是将数据从sendbuff拷贝到位于rank0的buff,recv端接收数据是从位于rank0的buff拷贝到recvbuff,但我们后续会将send流程表述为将sendbuff发送到rank1的buffer,接收流程表述为将数据从当前rank的buffer拷贝到recvbuff(换句话说假设buff位于rank1以方便理解)

执行api
在完成上述的初始化之后用户开始执行allreduce。
ncclResult_t ncclAllReduce(const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream) {
struct ncclInfo info = { ncclCollAllReduce, "AllReduce",
sendbuff, recvbuff, count, datatype, op, 0, comm, stream, /* Args */
ALLREDUCE_CHUNKSTEPS, ALLREDUCE_SLICESTEPS };
return ncclEnqueueCheck(&info);
}
enqueue
创建info之后执行ncclEnqueueCheck,假设为非group操作
ncclResult_t ncclEnqueueCheck(struct ncclInfo* info) {
// Launch asynchronously if needed
if (ncclAsyncMode()) {
...
} else {
NCCLCHECK(PtrCheck(info->comm, info->opName, "comm"));
NCCLCHECK(ArgsCheck(info));
NCCLCHECK(checkSetStream(info));
INFO(NCCL_COLL,"%s: opCount %lx sendbuff %p recvbuff %p count %zi datatype %d op %d root %d comm %p [nranks=%d] stream %p",
info->opName, info->comm->opCount, info->sendbuff, info->recvbuff, info->count,
info->datatype, info->op, info->root, info->comm, info->comm->nRanks, info->stream);
NCCLCHECK(ncclSaveKernel(info));
NCCLCHECK(ncclBarrierEnqueue(info->comm));
NCCLCHECK(ncclBarrierEnqueueWait(info->comm));
NCCLCHECK(ncclEnqueueEvents(info->comm));
return ncclSuccess;
}
}
ncclSaveKernel
然后通过ncclSaveKernel将参数等信息添加到channel里。
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
info->comm->myParams->blockDim.x = std::max<unsigned>(info->comm->myParams->blockDim.x, info->nThreads);
int nChannels = info->coll == ncclCollSendRecv ? 1 : coll.args.coll.nChannels;
int nSubChannels = (info->pattern == ncclPatternCollTreeUp || info->pattern == ncclPatternCollTreeDown) ? 2 : 1;
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
if (channel->collCount == NCCL_MAX_OPS) {
WARN("Too many aggregated operations on channel %d (%d max)", channel->id, NCCL_MAX_OPS);
return ncclInvalidUsage;
}
// Proxy
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
info->comm->myParams->gridDim.x++;
int opIndex = channel->collFifoTail;
struct ncclColl* c = channel->collectives+opIndex;
volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;
while (activePtr[0] != 0) sched_yield();
memcpy(c, &coll, sizeof(struct ncclColl));
if (info->coll != ncclCollSendRecv) c->args.coll.bid = bid % coll.args.coll.nChannels;
c->active = 1;
opIndex = (opIndex+1)%NCCL_MAX_OPS;
c->nextIndex = opIndex;
channel->collFifoTail = opIndex;
channel->collCount++;
}
info->comm->opCount++;
return ncclSuccess;
}
这里核心是computeColl,通过computeColl将kernel所需的参数信息添加到channel的collectives中,并更新myParams->gridDim.x,即一个channel对应一个block。
static ncclResult_t computeColl(struct ncclInfo* info /* input */, struct ncclColl* coll, struct ncclProxyArgs* proxyArgs /* output */) {
coll->args.sendbuff = info->sendbuff;
coll->args.recvbuff = info->recvbuff;
coll->args.comm = info->comm->devComm;
if (info->coll == ncclCollSendRecv) {
coll->args.p2p.sendCount = info->sendbytes;
coll->args.p2p.recvCount = info->recvbytes;
coll->args.p2p.delta = info->delta;
coll->funcIndex = FUNC_INDEX_P2P;
coll->args.p2p.nThreads = info->nThreads = info->comm->maxThreads[NCCL_ALGO_RING][NCCL_PROTO_SIMPLE]+2*WARP_SIZE;
return ncclSuccess;
}
// Set nstepsPerLoop and nchunksPerLoop
NCCLCHECK(getAlgoInfo(info));
NCCLCHECK(getPatternInfo(info));
NCCLCHECK(getLoopInfo(info));
...
}
nccl支持NCCL_PROTO_LL,NCCL_PROTO_LL128和NCCL_PROTO_SIMPLE三种协议,支持NCCL_ALGO_TREE,NCCL_ALGO_RING和NCCL_ALGO_COLLNET三种算法,getAlgoInfo会遍历三种算法和三种协议的组合,选出最好的算法和协议,具体如何选择后边介绍tree allreduce的时候再看,本节先忽略这块逻辑,先假定选出的协议为NCCL_PROTO_SIMPLE,算法为NCCL_ALGO_RING。
getPatternInfo中会将info->pattern设置为ncclPatternRingTwice。
getLoopInfo会设置nstepsPerLoop和nchunksPerLoop。
info->nstepsPerLoop = 2*(info->comm->nRanks-1); info->nchunksPerLoop = info->comm->nRanks;
然后看下上边提到的这几个变量的含义:
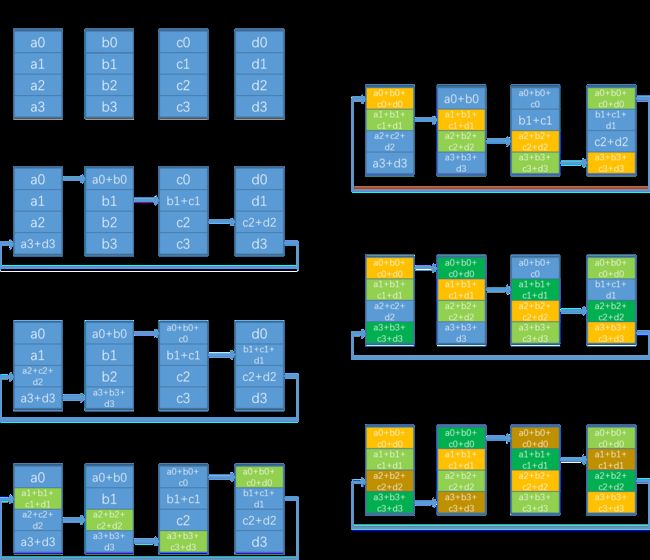
n个rank的ring allreduce过程如上图(图片来自这里)所示,假设要allreduce100M的数据,执行流程会分为多次循环,每次循环执行比如4M的数据,图中展示了allreduce中一次循环的过程,其中(a0+a1+a2+a3)长度为4M,这一次循环过程中分为左侧的reduce scatter和右侧的allgather过程,每个rank每个step收发这块数据的1/n,即1M长度,比如a0,所以nchunksPerLoop = nRanks,表示一次循环过程被分成了多少个数据块,一个数据块叫一个chunk;因为执行了reduce scatter和allgather两次ring的过程,因此pattern叫ncclPatternRingTwice,nstepsPerLoop = 2*(info->comm->nRanks-1),表示一次循环中需要执行多少步,reduce scatter执行nRank - 1步,allgather也执行nRanks - 1步。
launch kernel
然后执行ncclBarrierEnqueue,核心就是通过setupLaunch将第一个channel的第一个ncclColl拷贝到comm->args,然后通过ncclLaunchCooperativeKernelMultiDevice launch kernel。
ncclResult_t ncclBarrierEnqueue(struct ncclComm* comm) {
struct cudaLaunchParams* params = comm->myParams;
if (params->gridDim.x == 0) return ncclSuccess;
NCCLCHECK(setupLaunch(comm, params));
// Use internal NCCL stream for CGMD/GROUP launch if required or if the user stream is NULL
...
if (comm->launchMode == ncclComm::GROUP) {
int isLast = 0;
NCCLCHECK(ncclCpuBarrierIn(comm, &isLast));
if (isLast) {
// I'm the last. Launch all operations.
NCCLCHECK(ncclLaunchCooperativeKernelMultiDevice(comm->intraParams, comm->intraCudaDevs, comm->intraRanks, *comm->intraCGMode));
NCCLCHECK(ncclCpuBarrierLast(comm));
}
}
return ncclSuccess;
}
ring allreduce kernel
我们直接看下allreduce kernel,怎么调用到这里的逻辑可以参考第九节,这里不再赘述,
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
const int tid = threadIdx.x;
const int nthreads = args->coll.nThreads-WARP_SIZE;
const int bid = args->coll.bid;
const int nChannels = args->coll.nChannels;
struct ncclDevComm* comm = args->comm;
struct ncclChannel* channel = comm->channels+blockIdx.x;
struct ncclRing* ring = &channel->ring;
const int stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE] / (sizeof(T)*NCCL_STEPS);
const int chunkSize = stepSize * ALLREDUCE_CHUNKSTEPS;
const int nranks = comm->nRanks;
const ssize_t loopSize = nChannels*(ssize_t)chunkSize;
const ssize_t size = args->coll.count;
// Compute pointers
const T * __restrict__ thisInput = (const T*)args->sendbuff;
T * __restrict__ thisOutput = (T*)args->recvbuff;
ncclPrimitives<UNROLL, ALLREDUCE_CHUNKSTEPS/ALLREDUCE_SLICESTEPS, ALLREDUCE_SLICESTEPS, T, 1, 1, 1, FUNC>
prims(tid, nthreads, &ring->prev, &ring->next, thisOutput, stepSize, channel, comm);
...
}
类似send/recv kernel,allreduce kernel也会有一个专门的warp做sync以降低延迟。
然后这里会看到几个概念,step,slice和chunk,buffer会被切分为NCCL_STEPS个slot,一个slot就是一个step,因此stepSize就是bufferSize / (sizeof(T) * NCCL_STEPS);如图二提到的,一个rank一次收发比如1M的数据,这个1M数据就是一个chunk,通信原语ncclPrimitives的api比如directSend,一次传输的就是一个chunk的数据;一个chunk有多个step,即ALLREDUCE_CHUNKSTEPS,所以chunkSize就是stepSize * ALLREDUCE_CHUNKSTEPS;在directSend内部,会将chunk切分为多个slice,一个slice也是多个step,prmitives里数据通信和同步的实际粒度为slice。
一个kernel一共有nChannels个block,所以一次循环过程中一个rank会处理loopSize = nChannels * chunkSize长度的数据。sendbuff为用户传入的输入数据,recvbuff为用户传入的输出数据,然后初始化ncclPrimitives,SLICESPERCHUNK为一个chunk等于几个slice,slicesteps为一个slice是几个step,NRECV表示从几个地方收数据,NSEND表示发送给几个地方,ring allreduce的NRECV和NSEND均为1,DIRECT表示是否支持直接收发,这个下边会介绍。构造函数中recvPeers就是从哪里接收,长度为NRECV,就是ring中的前一个rank,sendPeers同理。
template <int UNROLL, int SLICESPERCHUNK, int SLICESTEPS, typename T, int NRECV, int NSEND, int DIRECT, class FUNC>
class ncclPrimitives {
...
public:
__device__ __forceinline__
ncclPrimitives(const int tid, const int nthreads, int* recvPeers, int* sendPeers, T* directBuff, int stepSize, struct ncclChannel* channel, struct ncclDevComm* comm)
: comm(comm), tid(tid), nthreads(nthreads), wid(tid%WARP_SIZE), stepSize(stepSize) {
...
}
...
}
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
ssize_t realChunkSize = min(chunkSize, DIVUP(size-gridOffset,nranks*nChannels));
ALIGN_SIZE(realChunkSize, nthreads*sizeof(uint64_t)/sizeof(T));
ssize_t chunkOffset = gridOffset + bid*nranks*realChunkSize;
/// begin AllReduce steps ///
ssize_t offset;
int nelem;
int chunk;
// step 0: push data to next GPU
chunk = ring->devUserRanks[nranks-1];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.send(thisInput+offset, nelem);
...
}
按照图二的例子的话,一个block一次处理图二中的1M数据,例如a0,所以4个rank加起来能处理的总长度就是4M,即(a0+a1+a2+a3),第二个block从a5开始处理,因此4个rank所有block一次循环能处理nranks*loopSize长度的数据,因此gridOffset每次加这么多。
然后开始执行reduce scatter的第一步,将数据从用户的输入thisInput发送到下一个rank的buffer。devUserRanks是以当前rank为起点按序保存了当前ring的所有rank,这里和图二不同的一点是第一次发送的是当前ring最后一个rank的数据,比如rank0发送的是a3,后续按照实际代码来讲。然后执行prims.send将a3发送到下一个rank的buffer里。
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
...
// k-2 steps: reduce and copy to next GPU
for (int j=2; j<nranks; ++j) {
chunk = ring->devUserRanks[nranks-j];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.recvReduceSend(thisInput+offset, nelem);
}
// step k-1: reduce this buffer and data, which will produce the final
// result that we store in this data and push to the next GPU
chunk = ring->devUserRanks[0];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.directRecvReduceCopySend(thisInput+offset, thisOutput+offset, offset, nelem);
...
}
}
然后继续执行reduce scatter过程的nranks - 2步,每次都通过recvReduceSend将自己buffer中已经接收到的数据和thisInput中的数据进行reduce,比如求和,然后将结果发送给next rank的buffer。以rank0为例,最后rank0通过directRecvReduceCopySend将a0和prev rank发送过来的数据进行reduce,然后发送给next rank的buffer和thisOutput,此时reduce scatter执行完成,每个rank都拿到了一块完整的数据,例如对于rank0的完整数据就是a0对应的数据,并将自己对应的完整数据拷贝到了下一个rank的buffer和用户api输入的recvbuff中。
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
...
// k-2 steps: copy to next GPU
for (int j=1; j<nranks-1; ++j) {
chunk = ring->devUserRanks[nranks-j];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.directRecvCopySend(thisOutput+offset, offset, nelem);
}
// Make final copy from buffer to dest.
chunk = ring->devUserRanks[1];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
// Final wait/copy.
prims.directRecv(thisOutput+offset, offset, nelem);
}
}
然后开始执行allgather,先执行nranks - 2步的directRecvCopySend,将当前buffer里nelem长度的数据发送给next rank的buffer以及用户api输入的recvbuff中。第nranks - 1步通过directRecv将当前buffer里nelem长度的数据发送到用户api输入的recvbuff中,不需要发送给next rank了。
到这里就完成了ring allreduce kernel的执行,然后我们看下ring allreduce kernel中用到的ncclPrimitives api。
ncclPrimitives
第九节介绍过ncclPrimitives如何收发数据和同步的,但是send/recv场景只用到了directSend和directRecv,这里我们主要介绍下ring allreduce场景中各个ncclPrimitives api的作用。
ncclPrimitives api都是使用的GenericOp,GenericOp核心作用就是根据参数创建srcs和dsts数组,然后将srcs数组规约,规约的结果拷贝到dsts中的每一个输出。
template <int DIRECTRECV, int DIRECTSEND, int RECV, int SEND, int SRC, int DST>
inline __device__ void
GenericOp(const T* srcPtr, T* dstPtr, int nelem, ssize_t directOffset) {
int offset = 0;
int sliceSize = stepSize*SLICESTEPS;
int dataSize = max(DIVUP(nelem, 16*SLICESPERCHUNK)*16, sliceSize/32);
const T* srcs[RECV*NRECV+SRC];
srcs[0] = SRC ? srcPtr : directRecvPtr<DIRECTRECV>(0, directOffset);
if (RECV) {
if (SRC) srcs[1] = recvPtr(0);
for (int i=1; i<NRECV && i<nrecv; i++) srcs[SRC+i] = recvPtr(i);
}
T* dsts[SEND*NSEND+DST];
dsts[0] = DST ? dstPtr : directSendPtr<DIRECTSEND>(0, directOffset);
if (SEND) {
if (DST) dsts[1] = directSendPtr<DIRECTSEND>(0, directOffset);
for (int i=1; i<NSEND && i<nsend; i++) dsts[DST+i] = directSendPtr<DIRECTSEND>(i, directOffset);
}
...
}
模板参数中RECV表示是否需要recv数据,SEND表示是否需要send数据,SRC表示srcs数组中是否有参数srcPtr,如果SRC不为0,那么srcs数组中第一个是srcPtr,第二个是前一个rank的buffer,如果SRC为0,那么srcs只有一个,就是前一个GPU的buffer;DST同理。
DIRECTSEND和DIRECTRECV在这个场景没有什么差异,我们先忽略,稍等介绍一下。
api
send
__device__ __forceinline__ void
send(const T* src, int nelem) {
GenericOp<0, 0, 0, 1, 1, 0>(src, NULL, nelem, 0);
}
send接口的SEND和SRC为1,所以srcs数组只有src,dsts数组只有下一个rank的buffer,因此send的作用就是将src里的nelem长度的数据发送给下一个rank的buffer
recvReduceSend
__device__ __forceinline__ void
recvReduceSend(const T* src, int nelem) {
GenericOp<0, 0, 1, 1, 1, 0>(src, NULL, nelem, 0);
}
SRC和RECV都为1,因此srcs数组为src和前一个rank的buffer,SEND为1但DST为0,因此dsts数组只有下一个rank的buffer,因此recvReduceSend的作用就是将src里的nelem长度的数据和prev rank发送过来的数据进行reduce,然后发送给next rank的buffer
directRecvReduceCopySend
__device__ __forceinline__ void
directRecvReduceCopySend(const T* src, T* dst, ssize_t directOffset, int nelem) {
// Direct is only for the send part
GenericOp<0, 1, 1, 1, 1, 1>(src, dst, nelem, directOffset);
}
SRC和RECV均为1,因此srcs数组为src和当前rank的buffer,SEND和DST均为1,因此dsts数组为dst和下一个rank的buffer,因此directRecvReduceCopySend的作用就是将src里的nlem长度的数据和prev rank发送到当前buffer的数据进行reduce,然后发送给next rank的buffer和dst
directRecvCopySend
__device__ __forceinline__ void
directRecvCopySend(T* dst, ssize_t directOffset, int nelem) {
GenericOp<1, 1, 1, 1, 0, 1>(NULL, dst, nelem, directOffset);
}
由于SRC为0其他均为1,因此srcs数组只有当前rank的buffer,dsts数组为dst和下一个rank的buffer,因此directRecvCopySend的作用就是将当前rank buffer里收到的数据拷贝到dst和下一个rank的buffer
directRecv
__device__ __forceinline__ void
directRecv(T* dst, ssize_t directOffset, int nelem) {
GenericOp<1, 0, 1, 0, 0, 1>(NULL, dst, nelem, directOffset);
}
由于RECV为1,SRC为0,因此srcs只有当前rank的buffer,DST为1,因此dsts数组为dst,因此directRecv的作用就是将数据从当前rank的buffer里收到的数据拷贝到dst
direct
然后介绍下之前提到的direct的作用,比如rank0执行send,rank1执行recv,那么rank0将数据从src拷贝到rank1的buffer,rank1将数据从buffer拷贝到dst,而如果是directSend,那么有可能会bypass rank1的buffer,直接发送给dst。为什么是有可能,以及rank0如何知道dst是哪里,我们回顾下transport的建立。
struct ncclSendMem {
union {
struct {
uint64_t head;
char pad1[CACHE_LINE_SIZE-sizeof(uint64_t)];
void* ptrExchange;
char pad2[CACHE_LINE_SIZE-sizeof(void*)];
};
char pad3[MEM_ALIGN];
};
char buff[1]; // Actually larger than that
};
send端有个变量叫ptrExchange。
static ncclResult_t p2pSendConnect(struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* send) {
...
send->conn.ptrExchange = &resources->devMem->ptrExchange;
}
ncclResult_t p2pRecvConnect(struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* recv) {
...
if (info->direct) {
remDevMem = (struct ncclSendMem*)(info->directPtr);
if (info->read == 0) {
recv->conn.direct |= NCCL_DIRECT_GPU;
recv->conn.ptrExchange = &remDevMem->ptrExchange;
}
}
...
}
send端和recv端connect的过程中,recv端会保存下send端的ptrExchange。
__device__ __forceinline__ void loadSendConn(struct ncclConnInfo* conn, int i) {
sendBuff[i] = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
...
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
void* volatile* ptr = conn->ptrExchange;
while ((sendDirectBuff[i] = (T*)(*ptr)) == NULL);
barrier();
if (tid == 0) *ptr = NULL;
}
...
}
__device__ __forceinline__ void loadRecvConn(struct ncclConnInfo* conn, int i, T* directBuff) {
recvBuff[i] = (const T*)conn->buffs[NCCL_PROTO_SIMPLE];
...
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
recvDirectBuff[i] = directBuff;
if (tid == 0) *conn->ptrExchange = directBuff;
}
...
}
然后ncclPrimitives加载conn的时候,recv端会将directBuff,也就是dst,写入到ptrExchange,所以send端就知道了dst在哪里。
同时也能看到限制,只有info->direct == 1且info->read == 0的时候才支持direct,也就是说必须为同一个进程并且使用p2p write才支持,我们这个场景使用了p2p read,因此直接忽略了direct。
多机
多机的实际通信流程和第十节的多机send/recv一致,我们主要关注下不一致的地方。
初始化
假设单机内执行ncclTopoCompute搜索出的ring为:
NET/0 GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7 NET/0
相比单机的环,变成了一条链,前后加了网卡。建链的过程只是多了机器间的建链,不再赘述。
ncclSaveKernel
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
...
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
...
// Proxy
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
...
}
info->comm->opCount++;
return ncclSuccess;
}
ncclSaveKernel中唯一有区别的就是computeColl和ncclProxySaveColl。
computeColl
static ncclResult_t computeColl(struct ncclInfo* info /* input */, struct ncclColl* coll, struct ncclProxyArgs* proxyArgs /* output */) {
...
int stepSize = info->comm->buffSizes[info->protocol]/NCCL_STEPS;
int chunkSteps = (info->protocol == NCCL_PROTO_SIMPLE && info->algorithm == NCCL_ALGO_RING) ? info->chunkSteps : 1;
int sliceSteps = (info->protocol == NCCL_PROTO_SIMPLE && info->algorithm == NCCL_ALGO_RING) ? info->sliceSteps : 1;
int chunkSize = stepSize*chunkSteps;
...
// Compute nSteps for proxies
int chunkEffectiveSize = chunkSize;
if (info->protocol == NCCL_PROTO_LL) chunkEffectiveSize /= 2;
if (info->protocol == NCCL_PROTO_LL128) chunkEffectiveSize = (chunkSize / NCCL_LL128_LINEELEMS) * NCCL_LL128_DATAELEMS;
int nLoops = (int)(DIVUP(info->nBytes, (((size_t)(info->nChannels))*info->nchunksPerLoop*chunkEffectiveSize)));
proxyArgs->nsteps = info->nstepsPerLoop * nLoops * chunkSteps;
proxyArgs->sliceSteps = sliceSteps;
proxyArgs->chunkSteps = chunkSteps;
proxyArgs->protocol = info->protocol;
proxyArgs->opCount = info->comm->opCount;
proxyArgs->dtype = info->datatype;
proxyArgs->redOp = info->op;
...
return ncclSuccess;
}
nLoops表示一共有多少次循环,如图二描述,一个chunk就是a0,大小为chunkEffectiveSize,一次执行能处理nchunksPerLoop*chunkEffectiveSize的数据,即(a0+a1+a2+a3),一共有nChannels,所以一次处理的数据再乘上nChannels,然后去除nBytes就算出了一共需要循环执行多少次。
然后计算nsteps,表示一共有多少个step,step就是buff中的一个slot,因为处理一个chunk的时候会发送数据nstepsPerLoop次,一个chunk里有chunkSteps个step,一共有nLoops个循环,因此nsteps就是nstepsPerLoop * nLoops * chunkSteps。
所以proxy就通过proxyArgs里的这些信息知道了应该发送多少次数据。
ncclProxySaveColl
然后将每个channel的proxyArgs加到comm的args链表中
ncclResult_t ncclProxySaveColl(struct ncclProxyArgs* args, int pattern, int root, int nranks) {
if (pattern == ncclPatternRing || pattern == ncclPatternRingTwice || pattern == ncclPatternPipelineFrom || pattern == ncclPatternPipelineTo) {
struct ncclRing* ring = &args->channel->ring;
if (NeedProxy(RECV, pattern, root, ring, nranks)) NCCLCHECK(SaveProxy<proxyRecv>(ring->prev, args));
if (NeedProxy(SEND, pattern, root, ring, nranks)) NCCLCHECK(SaveProxy<proxySend>(ring->next, args));
}
...
}
NeedProxy固定返回true,然后执行SaveProxy
template <int type>
static ncclResult_t SaveProxy(int peer, struct ncclProxyArgs* args) {
if (peer < 0) return ncclSuccess;
struct ncclPeer* peerComm = args->channel->peers+peer;
struct ncclConnector* connector = type == proxyRecv ? &peerComm->recv : &peerComm->send;
if (connector->transportComm == NULL) {
WARN("[%d] Error no transport for %s peer %d on channel %d\n", connector->comm->rank,
type == proxyRecv ? "recv" : "send", peer, args->channel->id);
return ncclInternalError;
}
if (connector->transportComm->proxy == NULL) return ncclSuccess;
struct ncclProxyArgs* op;
NCCLCHECK(allocateArgs(connector->comm, &op));
memcpy(op, args, sizeof(struct ncclProxyArgs));
op->connector = connector;
op->progress = connector->transportComm->proxy;
op->state = ncclProxyOpReady;
ProxyAppend(connector, op);
return ncclSuccess;
}
因为建链接的过程中只有rank7的send是netTransport,所以只有rank7的send会执行ProxyAppend,同理只有rank0的recv会执行ProxyAppend。
数据发送
ProxyAppend不再赘述,就是将args加入到comm中的链表,launch kernel之后就会唤醒proxy线程,proxy遍历这个链表,执行对应的操作,以send为例。
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
if (args->state == ncclProxyOpReady) {
// Round to next multiple of sliceSteps
resources->step = ROUNDUP(resources->step, args->chunkSteps);
args->head = resources->step;
args->tail = resources->step;
args->end = args->head + args->nsteps;
args->state = ncclProxyOpProgress;
}
if (args->state == ncclProxyOpProgress) {
int p = args->protocol;
int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;
char* localBuff = args->connector->conn.buffs[p];
void* mhandle = *(resources->mhandlesProto[p]);
args->idle = 1;
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
if (args->tail < args->end && args->tail < args->head + NCCL_STEPS) {
volatile int* sizesFifo = resources->recvMem->sizesFifo;
volatile uint64_t* recvTail = &resources->recvMem->tail;
...
else if (args->tail < *recvTail) {
// Send through network
if (sizesFifo[buffSlot] != -1) {
NCCLCHECK(ncclNetIsend(resources->netSendComm, localBuff+buffSlot*stepSize, sizesFifo[buffSlot], mhandle, args->requests+buffSlot));
if (args->requests[buffSlot] != NULL) {
sizesFifo[buffSlot] = -1;
// Make sure size is reset to zero before we update the head.
__sync_synchronize();
args->tail += args->sliceSteps;
args->idle = 0;
}
}
}
}
if (args->head < args->tail) {
int done;
int buffSlot = args->head%NCCL_STEPS;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, NULL));
if (done) {
args->head += args->sliceSteps;
resources->sendMem->head = args->head;
args->idle = 0;
}
}
}
if (args->head == args->end) {
resources->step = args->end;
args->idle = 0;
args->state = ncclProxyOpNone;
}
}
return ncclSuccess;
}
可以看到end就是通过nsteps计算得到的,所以proxy知道整个算法流程一共需要多少个slot,因为primitives一次实际发送sliceSteps个slot,因此每次对head和tail的移动都是sliceSteps。