flink介绍(二)
4.1 window
4.1.1 概述
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
Window是无限数据流处理的核心, Window 将一个无限的 stream 拆分成有限大小的” buckets”桶,我们可以在这些桶上做计算操作。
4.1.2 Window 类型
Window 可以分成CountWindow和TimeWindow两类。CountWindow按照指定的数据条数生成一个 Window,与时间无关;TimeWindow按照时间生成Window
- TimeWindow
TimeWindow,可以根据窗口实现原理的不同分成三类:滚动窗口(TumblingWindow)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个 5 分钟大小的滚动窗口,窗口的创建如下图所示:

适用场景:适合做BI统计等(做每个时间段的聚合计算)
滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
特点:时间对齐,窗口长度固定, 可以有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有 10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上个 10 分钟产生的数据,如下图所示:

适用场景:对最近一个时间段内的统计(求某接口最近 5 min 的失败率来决定是否要报警)
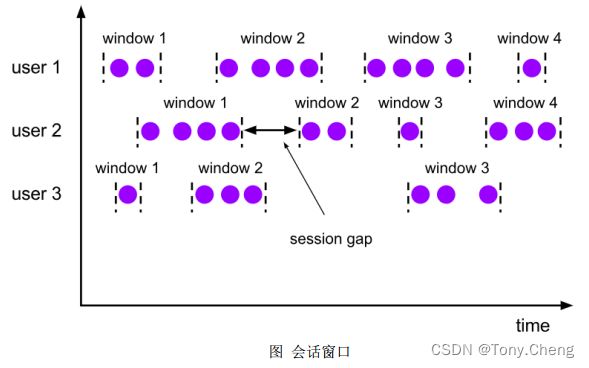
会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session 窗口分配器通过 session 活动来对元素进行分组, session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。
4.1.3 CountWindow
计数窗口可以分为滚动计数窗口和滑动计数窗口
4.1.4 window API
- 窗口分配器(window assigner)
- 窗口函数(window function)
4.2 时间语义和Wartermark
4.2.1 Flink 中的时间语义
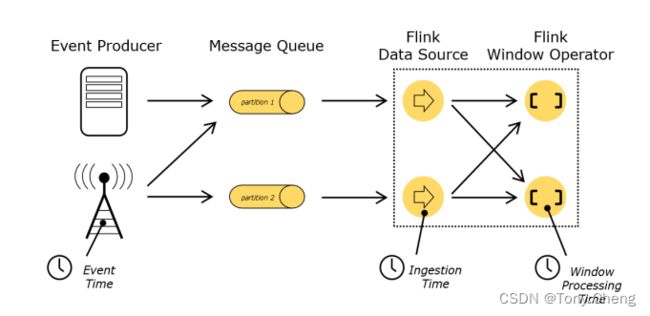
- Event Time:事件创建的时间
- Ingestion Time:数据进入Flink的时间
- Processing Time:执行操作算子的本地系统时间,与机器相关
不同的时间语义有不同的应用场合,我们往往更关心事件时间(Event Time)
4.2.2 设置 Event Time
我们可以直接在代码中,对执行环境调用 setStreamTimeCharacteristic方法,设置流的时间特性。具体的时间,还需要从数据中提取时间戳(timestamp)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
4.2.3 水位线(Watermark)
- 概念
事件出现乱序时,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了,这个特别的机制,就是 Watermark。

Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发
Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现;
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此, window 的执行也是由 Watermark 触发的。
watermark 用来让程序自己平衡延迟和结果正确性
- 特点
watermark有以下特点:
1. watermark 是一条特殊的数据记录
2. watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
3. watermark 与数据的时间戳相关
- watermark 的传递
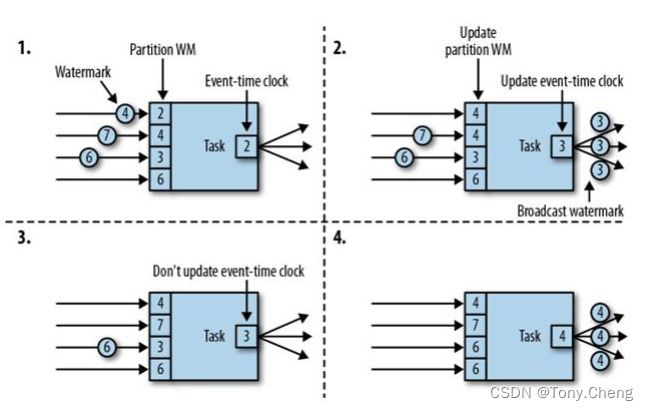
- watermark的引入
调用 assignTimestampAndWatermarks 方法,传入一个BoundedOutOfOrdernessTimestampExtractor,就可以指定
dataStream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor() {
@Override
public long extractAscendingTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
})
// 乱序数据设置时间戳和watermark
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
Flink 暴露了TimestampAssigner 接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳和生成watermark
dataStream.assignTimestampsAndWatermarks(new MyAssigner())
TimestampAssigner,定义了抽取时间戳,以及生成 watermark 的方法,有两种类型: AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks
- watermark的设定
在 Flink 中, watermark 由应用程序开发人员生成,这通常需要对相应的领域有一定的了解
如果watermark设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果
而如果watermark到达得太早,则可能收到错误结果,不过 Flink 处理迟到数据的机制可以解决这个问题
4.3 状态管理
4.3.1 Flink 中的状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IRo0KFSh-1659965307584)(https://note.youdao.com/yws/res/37339/WEBRESOURCEc52ec0bcb45e9e837a7746fc1472bd58)]
- 由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态
- 可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
- Flink 会进行状态管理, 包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑
- 在 Flink 中,状态始终与特定算子相关联
- 为了使运行时的 Flink 了解算子的状态,算子需要预先注册其状态
总的说来,有两种类型的状态:
- 算子状态( Operator State),算子状态的作用范围限定为算子任务
- 键控状态( Keyed State),根据输入数据流中定义的键( key)
4.3.2 算子状态(Operatior State)

算子状态的作用范围限定为算子任务, 由同一并行任务所处理的所有数据都可以访问到相同的状态
状态对于同一子任务而言是共享的
算子状态不能由相同或不同算子的另一个子任务访问
算子状态数据结构
- 列表状态(List state),将状态表示为一组数据的列表
- 联合列表状态(Union list state),也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点( savepoint)启动应用程序时如何恢复
- 广播状态( Broadcast state),如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
4.3.3 键控状态(Keyed State)
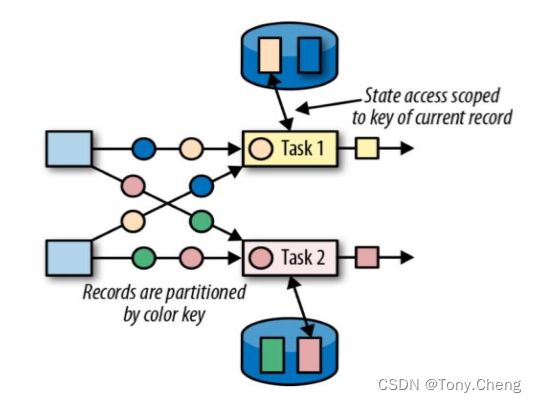
- 值状态(Value state),将状态表示为单个的值
- 列表状态(List state),将状态表示为一组数据的列表
- 映射状态(Map state),将状态表示为一组 Key-Value 对
- 聚合状态(Reducing state & Aggregating State),将状态表示为一个用于聚合操作的列表
键控状态的用途:
- 声明一个键控状态
- 读取状态
- 对状态赋值
4.3.4 状态后端(State Backends)
- 每传入一条数据,有状态的算子任务都会读取和更新状态
- 由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问
- 状态的存储、访问以及维护, 由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
- 状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
状态后端有如下类型:
- MemoryStateBackend,内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中,特点是:快速、低延迟,但不稳定
- FsStateBackend,将 checkpoint 存到远程的持久化文件系统( FileSystem) 上, 而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上,同时拥有内存级的本地访问速度,和更好的容错保证
- RocksDBStateBackend,将所有状态序列化后,存入本地的RocksDB中存储
4.4 容错机制
4.4.1 一致性检查点
Flink故障恢复机制的核心,就是应用状态的一致性检查点
有状态流应用的一致检查点, 其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照); 这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候;应用状态的一致检查点,是 Flink 故障恢复机制的核心
4.4.2 从检查点恢复状态
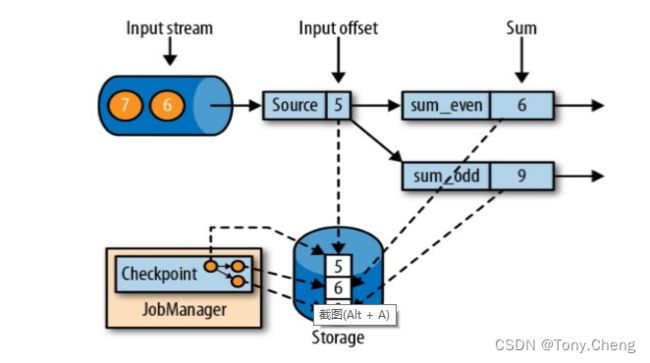
恢复步骤如下:
1. 重启应用
2. 从 checkpoint 中读取状态,将状态重置,重置后的状态与检查点完成时的状态完全相同
3. 开始消费并处理检查点到发生故障之间的所有数据,这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
4.4.3 检查点的实现算法
基于 Chandy-Lamport 算法的分布式快照,将检查点的保存和数据处理分离开,不暂停整个应用
- 检查点分界线
Flink 的检查点算法用到了一种称为分界线( barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开。分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中
- 检查点算法
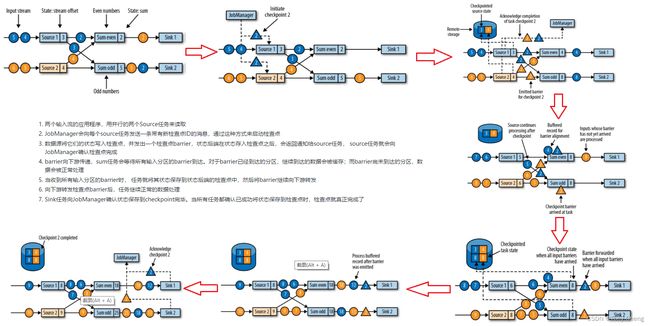
- 两个输入流的应用程序,用并行的两个Source任务来读取
- JobManager会向每个source任务发送一条带有新检查点ID的消息,通过这种方式来启动检查点
- 数据源将它们的状态写入检查点,并发出一个检查点barrier,状态后端在状态存入检查点之后,会返回通知给source任务, source任务就会向JobManager确认检查点完成
- barrier向下游传递,sum任务会等待所有输入分区的barrier到达。对于barrier已经到达的分区,继续到达的数据会被缓存;而barrier尚未到达的分区,数据会被正常处理
- 当收到所有输入分区的barrier时, 任务就将其状态保存到状态后端的检查点中,然后将barrier继续向下游转发
- 向下游转发检查点barrier后,任务继续正常的数据处理
- Sink任务向JobManager确认状态保存到checkpoint完毕。当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了
4.4.4 保存点
- 概念
Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints),原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作
- 作用
除了故障恢复外,保存点可以用于: 有计划的手动备份, 更新应用程序,版本迁移,暂停和重启应用等等
4.4.5 应用开启检查点
程序中默认是不开启检查点配置的,如果要开启,可通过如下代码进行开启和配置:
// 1. 状态后端配置
env.setStateBackend( new MemoryStateBackend());
env.setStateBackend( new FsStateBackend(""));
env.setStateBackend( new RocksDBStateBackend(""));
// 2. 检查点配置
env.enableCheckpointing(300);
// 高级选项
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100L);
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
// 3. 重启策略配置
// 固定延迟重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L));
// 失败率重启
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10), Time.minutes(1)));
4.5 状态一致性
4.5.1 什么是状态一致性
有状态的流处理,内部每个算子任务都可以有自己的状态,对于流处理器内部来说,所谓的状态一致性就是:
- 计算结果要保证准确
- 一条数据不丢失,也不重复计算
- 在遇到故障时可以恢复状态, 恢复以后重新计算,结果应该也是完全正确的
状态一致性可以分为以下三类:
- AT-MOST-ONCE(最多一次),当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据
- AT-LEAST-ONCE(至少一次),所有的事件都得到了处理,而一些事件还可能被处理多次
- EXACTLY-ONCE(精确一次),恰好处理一次是最严格的保证,也是最难实现的,没有事件丢失,对每一个数据,内部状态仅仅更新一次
4.5.2 端到端( end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的;而在真实应用中,流处理应用还包含数据源(例如 Kafka)和输出到持久化系统
端到端的一致性保证, 意味着结果的正确性贯穿了整个流处理应用的始终,每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件
端到端exactly-once的条件:
- 内部保证 —— checkpoint
- source端 —— 可重设数据的读取位置
- sink端 —— 从故障恢复时,数据不会重复写入外部系统,有幂等写入和事务写入两种方法
事务写入的实现思想:构建的事务对应着checkpoint, 等到checkpoint真正完成的时候,才把所有对应的结果写入sink系统中,实现方式有预写日志和两阶段提交两种
-
预写日志(Write-Ahead-Log,WAL)
把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。好处是:简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink 系统,都能用这种方式一批搞定。DataStream API 提供了一个模板类: GenericWriteAheadSink,来实现这种事务性 sink -
两阶段提交(Two-Phase-Commit,2PC)
对于每个 checkpoint,sink任务会启动一个事务,并将接下来所有接收的数据添加到事务里;然后将这些数据写入外部 sink 系统,但不提交它们 —— 这时只是“预提交”;当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部sink 系统。Flink 提供了 TwoPhaseCommitSinkFunction 接口。
2PC 对外部 sink 系统的要求:
外部 sink 系统必须提供事务支持, 或者 sink 任务必须能够模拟外部系统上的事务
在 checkpoint 的间隔期间里,必须能够开启一个事务并接受数据写入
在收到 checkpoint 完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候sink系统关闭事务(例如超时了),那么未提交的数据就会丢失
sink 任务必须能够在进程失败后恢复事务
提交事务必须是幂等操作
不同 Source 和 Sink 的一致性保证如下表所示:

4.5.3 Flink+Kafka 端到端状态一致性
各个组件的一致性保证如下所示:
- 内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer 作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
Exactly-once 两阶段提交步骤如下:

1. JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存
2. 当checkpoint启动时,JobManager会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去
3. 每个算子会对当前的状态做个快照,保存到状态后端;checkpoint机制可以保证内部的状态一致性
4. 每个内部的transform任务遇到barrier时,都会把状态存到checkpoint里;sink任务首先把数据写入外部kafka,这些数据都属于预提交的事务;遇到barrier时,把状态保存到状态后端,并开启新的预提交事务
5. 当所有算子任务的快照完成,也就是这次的checkpoint完成时, JobManager会向所有任务发通知,确认这次checkpoint完成;sink任务收到确认通知,正式提交之前的事务,kafka 中未确认数据改为“已确认”
- 第一条数据来了之后, 开启一个 kafka 的事务( transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发 checkpoint 操作, barrier 从 source 开始向下传递, 遇到barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态, 存入 checkpoint, 通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息, 正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了
5. API和扩展库
5.1 三层API
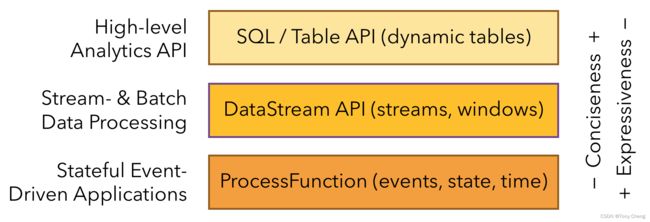
最底层级的抽象ProcessFunction仅仅提供了有状态流,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
核心API(Core APIs)有 DataStream API(有界或无界流数据)和DataSet API(有界数据集)之分。DataStream API由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。 DataSet API 为有界数据集提供了支持,例如循环与迭代。这些 API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API 遵循(扩展的)关系模型:表有二维数据结构( schema)(类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、 project、 join、 group-by、aggregate 等。
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与Table API 类似,但是是以 SQL 查询表达式的形式表现程序。 SQL 抽象与 Table API交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行
5.1.1 ProcessFunction
ProcessFunction API用来构建事件驱动的应用以及实现自定义的业务逻辑,可以访问时间戳、 watermark 以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。
Flink 提供了如下7个 Process Function:
- KeyedProcessFunction
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
侧输出流
大部分的 DataStream API 的算子的输出是单一输出,也就是某种数据类型的流。除了 split 算子,可以将一条流分成多条流,这些流的数据类型也都相同。 process function 的 side outputs 功能可以产生多条流,并且这些流的数据类型可以不一样。
下面是一个示例程序,用来监控传感器温度值,将温度值低于 30 度的数据输出到 side output
// 定义一个OutputTag,用来表示侧输出流低温流
OutputTag lowTempTag = new OutputTag("lowTemp") {
};
// 测试ProcessFunction,自定义侧输出流实现分流操作
SingleOutputStreamOperator highTempStream = dataStream.process(new ProcessFunction() {
@Override
public void processElement(SensorReading value, Context ctx, Collector out) throws Exception {
// 判断温度,大于30度,高温流输出到主流;小于低温流输出到侧输出流
if( value.getTemperature() > 30 ){
out.collect(value);
} else {
ctx.output(lowTempTag, value);
}
}
});
highTempStream.print("high-temp");
highTempStream.getSideOutput(lowTempTag).print("low-temp");
5.1.2 DataStreamAPI
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h2KGrKPW-1659965307587)(https://note.youdao.com/yws/res/37404/WEBRESOURCE783e37ff7b5dc400cd8bb709a380a705)]
-
source,可以以集合、文件、kafka为数据来源,也可以自定义source
-
transform,可以是map、flatmap、filter、keyBy、Rolling Aggregation、Reduce、Split、Select、Connect、CoMap和Union
flat和flatMap区别:
map,DataStream → DataStream,可以把一个输入的数据转为另外一个数据(比如把小写字母转换为大写字母, 数字转换成他的相反数等)
FlatMap,DataStream → DataStream,可以把一个输入的数据转为0-N条数据(比如把一个单词中所有的字母拆出来)
Connect 与 Union 区别:
Union 之前两个流的类型必须是一样, Connect 可以不一样,在之后的 coMap中再去调整成为一样的
Connect 只能操作两个流, Union 可以操作多个
-
函数
UDF(User-defined Functions)自定义函数,极大地扩展了查询的表达能力,UDF有ScalarFunction、TableFunction、AggregateFunction三种
Lambda Functions,匿名函数
Rich Functions,富函数 -
Sink,可以是Kafka、Redis、Elasticsearch,也可以自定义sink
5.1.3 SQL/Table API
Table API 是一套内嵌在 Java 和 Scala 语言中的查询API, 它允许以非常直观的方式组合来自一些关系运算符的查询
Flink 的 SQL 支持基于实现了 SQL 标准的 Apache Calcit
// 2. 转换成POJO
DataStream dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 3. 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 4. 基于流创建一张表
Table dataTable = tableEnv.fromDataStream(dataStream);
// 5. 调用table API进行转换操作
Table resultTable = dataTable.select("id, temperature")
.where("id = 'sensor_1'");
// 6. 执行SQL
tableEnv.createTemporaryView("sensor", dataTable);
String sql = "select id, temperature from sensor where id = 'sensor_1'";
Table resultSqlTable = tableEnv.sqlQuery(sql);
5.2 CEP简介
5.2.1 什么是CEP
复杂事件处理(Complex Event Processing,CEP),Flink CEP是在 Flink 中实现的复杂事件处理(CEP)库
CEP允许在无休止的事件流中检测事件模式,让我们有机会掌握数据中重要的部分,一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据——满足规则的复杂事件
5.2.2 CEP特点及使用场景

- 目标:从有序的简单事件流中发现一些高阶特征
- 输入:一个或多个由简单事件构成的事件流
- 处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
- 输出:满足规则的复杂事件
CEP一般用于分析低延迟、频繁产生的不同来源的事件流。CEP可以帮助在复杂的、不相关的时间流中找出有意义的模式和复杂的关系,以接近实时或准实时的获得通知或组织一些行为。比如实现以下一些功能:
- 输入的流数据,尽快产生结果;
- 在2个事件流上,基于时间进行聚合类的计算;
- 提供实时/准实时的警告和通知;
- 在多样的数据源中产生关联分析模式;
- 高吞吐、低延迟的处理
5.2.3 架构

CEP包含Event Stream、Pattern Definition、Pattern Detection和Alert Generation四个组件。开发人员要在DataStream流上定义出模式条件,之后Flink CEP引擎进行模式检测,必要时生成警告
5.2.3 Pattern API
处理事件的规则,被叫做模式(Pattern),Flink CEP 提供了Pattern API,用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列,使用如下:
DataStream input = ...;
// 定义一个Pattern
Pattern pattern = Pattern.begin("start").where(...).next("middle").subtype(SubEvent.Class).
where().followedBy().where(...);
// 将创建好的Pattern应用到输入事件流上
PatternStream patternStream = CEP.pattern(input, pattern);
// 检测匹配事件序列,处理得到结果
DataStream result = patternStream.select(...);
模式分为三类:
- 个体模式(Individual Patterns)
start.times(3).where(new SimpleCondition() {...})
个体模式包括单例模式和循环模式。单例模式只接收一个事件,而循环模式可以接收多个事件。
- 量词
可以在一个个体模式后追加量词,也就是指定循环次数
// 匹配出现4次
start.time(4)
// 匹配出现0次或4次
start.time(4).optional
// 匹配出现2、3或4次
start.time(2,4)
// 匹配出现2、3或4次,并且尽可能多地重复匹配
start.time(2,4).greedy
// 匹配出现1次或多次
start.oneOrMore
// 匹配出现0、2或多次,并且尽可能多地重复匹配
start.timesOrMore(2).optional.greedy
- 条件
每个模式都需要指定触发条件,作为模式是否接受事件进入的判断依据,CEP 中的个体模式主要通过调用 .where() .or() 和 .until()来指定条件。
按不同的调用方式,可以分成以下几类:
简单条件(Simple Condition)
通过 .where() 方法对事件中的字段进行判断筛选,决定是否接受该事件
start.where(new SimpleCondition() {
@Override
public boolean filter(Event event) throws Exception {
return event.getName.startWith("foo");
}
});
组合条件(Combining Condition)
将简单条件进行合并; .or() 方法表示或逻辑相连, where 的直接组合就是 AND
Pattern.where(event => …/*some condition*/).or(event => /*or condition*/)
终止条件
如果使用了oneOrMore或者oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态。
迭代条件
能够对模式之前所有接收的事件进行处理;调用
ctx.getEventForPattern(“name”).where(new IterativeCondition() {...})
- 组合模式(Combining Patterns,也叫模式序列)
很多个体模式组合起来,就形成了整个的模式序列,模式序列必须以一个“初始模式”开始:
Pattern start = Pattern.begin("start")
- 严格近邻(Strict Contiguity)
所有事件按照严格的顺序出现,中间没有任何不匹配的事件, 由 .next() 指定,例如对于模式”a next b” ,事件序列 [a, c, b1, b2] 没有匹配
- 宽松近邻(Relaxed Contiguity)
允许中间出现不匹配的事件,由 .followedBy() 指定,例如对于模式”a followedBy b” ,事件序列 [a, c, b1, b2] 匹配为 {a, b1}
- 非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
进一步放宽条件,之前已经匹配过的事件也可以再次使用,由 .followedByAny() 指定,例如对于模式”a followedByAny b” ,事件序列 [a, c, b1, b2] 匹配为 {a, b1}, {a,b2}
- 除以上模式序列外,还可以定义 “不希望出现某种近邻关系”
.notNext() —— 不想让某个事件严格紧邻前一个事件发生
.notFollowedBy() —— 不想让某个事件在两个事件之间发生
注意事项
所有模式序列必须以 .begin() 开始
模式序列不能以 .notFollowedBy() 结束
“not” 类型的模式不能被 optional 所修饰
此外,还可以为模式指定时间约束,用来要求在多长时间内匹配有效,next.within(Time.seconds(10)
- 模式组(Groups of patterns)
将一个模式序列作为条件嵌套在个体模式里,成为一组模式
5.2.4 Pattern Detection
指定要查找的模式序列后,就可以将其应用于输入流以检测潜在匹配
调用 CEP.pattern(),给定输入流和模式,就能得到一个PatternStream
5.2.5 匹配事件的提取
创建PatternStream之后,就可以应用select或者flatSelect方法,从检测到的事件序列中提取事件了
select()方法需要输入一个select function作为参数,每个成功匹配的事件序列都会调用它。
select()以一个Map[String,Iterable[IN]]来接收匹配到的事件序列,其中key就是每个模式的名称,而value就是所有接收到的事件的Iterable类型
public OUT select(Map pattern>) throws Exception {
IN startEvent = pattern.get("start").get(0);
IN endEvent = pattern.get("end").get(0);
return OUT(startEvent, endEvent);
}
超时事件的提取
当一个模式通过within关键字定义了检测窗口时间时,部分事件序列可能因为超过窗口长度而被丢弃;为了能够处理这些超时的部分匹配,select和flatSelect API调用允许指定超时处理程序