算法设计与分析--期末复习重点总结
目录
一.算法概述
1.算法的定义与特性
2.数学证明法
3.算法复杂性分析方法
4.渐进分析
二.递归与分治策略
1.递归概念
2.递归算法设计示例
3.递归算法分析
4.分治基本思想
5.分治算法设计示例
三.动态规划
四.贪心算法
五.回溯法
1.基本概念
2.回溯法解空间树
3.回溯算法设计框架
4.回溯算法示例--子集树
5.回溯算法示例--排列树
六.分支限界法
七.随机算法
一.算法概述
算法设计的优劣决定软件系统的性能。算法设计与分析的任务:
①设计阶段
该阶段的主要任务:对给定问题,如何设计解决此问题的有效算法。
②分析阶段
研究算法质量判定准则。
引例:求两正整数m,n的最大公约数
int gcd(int m,int n){
int r;
while(n!=0){
r=m%n;
m=n;
n=r;
}
return m;
} 递归实现:
int gcd(int m,int n)
{
return (m%n==0)?n:gcd(n,m%n);
} 1.算法的定义与特性
Def:算法是有规则的有限集合,是为解决特定问题而规定的一系列操作。
特性:(1)有限性:一个算法必须保证执行有限步后结束;
(2)确定性:算法的每一步必须有确切的定义,不能有歧义;
(3)可行性:算法原则上能精确地运行,在现有条件下是可以实现的;
(4)输入:一个算法有0个或多个输入,以刻画运算对象的初始状态;
(5)输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果。
2.数学证明法
1.反证法:
例:证明希尔排序的稳定性
证明:假设希尔排序是稳定的,对于 2,1,1,4排序结果,两个1的顺序发生了变化,故希尔排序是不稳定的算法。
2.数学归纳法:
例:证明前n个奇数的和为n^2,即求证![]() (2i-1)= n^2。
(2i-1)= n^2。
证明:当i=1时,有1=1^2;
设i=n-1,有 ![]() (2i-1) = (n-1)^2;
(2i-1) = (n-1)^2;
当i=n时,有 ![]() (2i-1)=
(2i-1)= ![]() (2i-1)+2n-1 =(n-1)^2+2n-1 =n^2。
(2i-1)+2n-1 =(n-1)^2+2n-1 =n^2。
3.算法复杂性分析方法
1.时间复杂度
排序:O(1) < O(logn)< O(n) < O(nlogn) < O(n^2 ) < O(n^3 ) < O(2^n ) < O(n!)
例1:

时间复杂度:
(1)基本语句:while
(2)执行次数:设while循环语
句执行的次数为m,i从1开始递
增,最后取值为1+2m,有:
i=1+2m>n
即m>(n-1)/2
(3)T(n)=O(n)
 T(n)=O(
T(n)=O(
 )
)
例3:
 T(n)=O(nlogn)
T(n)=O(nlogn)
2. 空间复杂度:
4.渐进分析
当问题规模很大,且趋于无穷时对算法性能的分析。
1.函数阶渐进形态的3种表示法
(1)低阶O:若存在一个正常数C和n0,对所有的n>n0,都有f(n)≤Cg(n),则记作f=O(g),即f的阶不高于g的阶;
(2)高阶Ω:若存在一个正常数C和n0,使得 n≥n0,f(n)≥Cg(n),记作f=Ω(g),即f的阶高于g的阶;
n≥n0,f(n)≥Cg(n),记作f=Ω(g),即f的阶高于g的阶;
(3)等阶 :当且仅当f(n)=O(g(n)),且f(n)=Ω(g(n))时,f与g同阶。
:当且仅当f(n)=O(g(n)),且f(n)=Ω(g(n))时,f与g同阶。
2.阶的证明方法
(1)反证法
例:对于n^3,n^2,证明n^3不是O(n^2)
证明:假设n^3是O(n^2),则有n^3≤Cn^2, 但对于n≥n0,n≤C,不成立,所以假设不成立。
(2)极限法:

3.求函数的渐进表达式
-
将函数中所有的加法项常数都去掉。
-
在修改后的函数中,只保留最高阶项。
-
如果最高阶项存在,那么去除高阶项前面的系数。
例题:
(1) 3n^2+10n O(n^2)
(2) n^2/100+2^n O(2^n)
(3) 21+1/n O(1)
(4) logn 3 O(logn)
(5) 10log3^n O(n)
二.递归与分治策略
1.递归概念
Def:函数,过程,子程序在运行过程中直接或间接调用自身而产生的重入现象。
引例1:设计求n!(n为正整数)的递归算法。
int fun(int n){
if(n==1){
return 1;
}else{
return fun(n-1)*n;
}
} int Sum(LinkList *L)
{ if (L==NULL)
return 0;
else
return(L->data+Sum(L->next));
}2.递归算法设计示例
1.集合全排列问题
思想:将求取1234(4个元素)全排列的问题转换为:分别取1234交换到第一个位置作为“开头”,求取剩余元素(3个)的全排列问题(递归体)当只有一个元素的时候其全排列就是该元素本身(递归出口)。
/在list数组中产生从元素k~m(下标从0开始)的全排列:
void Perm(int list[], int k, int m){
if(k==m) {
for(int i=0;i<=m;i++)
cout<2.整数划分问题(把一个正整数n表示成一系列正整数之和)


int split(int n,int m)
{
if(n==1||m==1) return 1;
else if (n3.选择排序的递归算法
void SelectSort(int a[],int i,int n){
int j,min;
if (i==n) return; //递归出口
else{
min=i;
for (j=i+1;j<=n;j++){
if(a[j]4.冒泡排序的递归算法
void BubbleSort(int a[],int i,int n)
{ int j;
bool exchange;
if (i==n) return; //递归出口
else{
exchange=false; //置exchange为false
for(j=0;j<=n-i;j++){
if(a[j]>a[j+1]){
swap(a[j],a[j+1]);
exchange=true;
}
}
if(exchange==false) //未发生交换时直接返回
return;
else
BubbleSort(a,i+1,n);
}
}3.递归算法分析
当一个算法包含对自身的递归调用时,该算法的运行时间复杂度可用递归方程进行描述。
1.替换法
根据递归规律,将递归公式通过方程展开、反复代换子问题的规模变量,通过多项式整理,如此类推,从而得到递归方程的解。
例: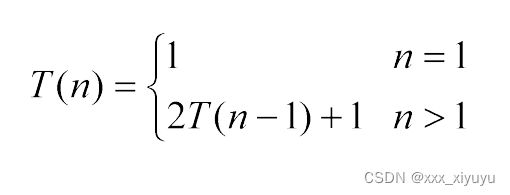

例:采用特征方程求解以下递归方程T(n)
T(0)=0;T(1)=1;T(2)=2
T(n)=T(n-1)+9T(n-2)-9T(n-3) 当n>2时
假设T(n)=x^n,将其代入递归方程
得:x^3-x^2-9x+9=0,解得x1=3,x2=-3,x3=1.
因此,通解为:f(n)=C1*3^n+C2*(-3)^n+C3.
根据初始条件T(0)=0,T(1)=1,T(2)=2.因此:T(n)=3^(n-1)-(-3)^n/12-1/4.
2.递归树法
例:
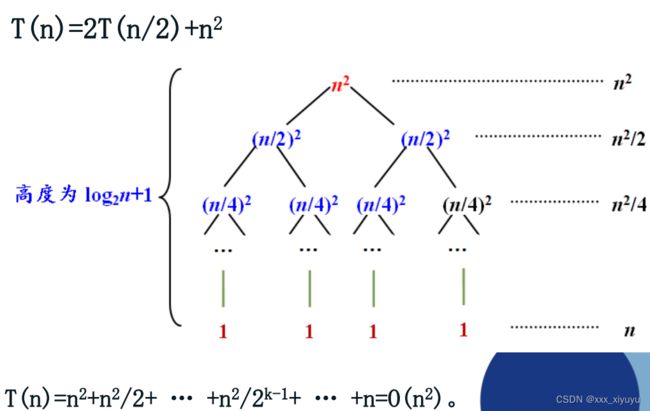
PS:如何根据递归关系确定递归树的高度?
如果递归的形式为T(n)= aT(n / b)+ f(n),则树的深度为n的对数底b。
例如,2T(n / 2)+ n递归将具有深度为lg(n)的树(n的对数底数2)。
3.主方法
主方法(master method)提供了解如下形式递归方程的 一般方法:T(n)=aT(n/b)+f(n)
其中a≥1,b>1为常数,该方程描述了算法的执行时间,算法将规模为n的问题分解成a个子问题,每个子问题的大小为 n/b。
例如,对于递归方程T(n)=3T(n/4)+n 2,有:a=3,b=4 ,f(n)=n 2 。


例:

4.分治基本思想
将问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
5.分治算法设计示例
1.快速排序
#include
using namespace std;
const int N = 100010;
int q[N];
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
} 2.归并排序
void merge(int a[],int left,int mid,int right){
int i=left,j=mid+1,k=0;
int *temp=(int *)malloc((right-left+1)*sizeof(int));
while(i<=mid&&j<=right){
if(a[i]<=a[j]){
temp[k++]=a[i++];
}else{
temp[k++]=a[j++];
}
}
while(i<=mid)temp[k++]=a[i++];
while(j<=right)temp[k++]=a[j++];
for(k=0,i=left;i<=right;k++,i++)a[i]=temp[k];
free(temp);
}
void MergeSort(int a[],int left,int right){
if(left>1;
MergeSort(a,left,mid);
MergeSort(a,mid+1,right);
merge(a,left,mid,right);
}
} 
3.查找最大元素和次大元素
思路:

void solve(int a[],int left,int right,int &max1,int &max2){
if(left==right){
max1=a[left];
max2=-1;
}else if(left==right-1){
max1=max(a[left],a[right]);
max2=min(a[left],a[right]);
}else{
int mid=left+right>>1;
int lmax1,lmax2;
solve(a,left,mid,lmax1,lmax2);
int rmax1,rmax2;
solve(a,mid+1,right,rmax1,rmax2);
if(lmax1>rmax1){
max1=lmax1;
max2=max(lmax2,rmax1);
}else{
max1=rmax1;
max2=max(lmax1,rmax2);
}
}
}4.折半查找
int fun(int a[],int left,int right,int k){
if(left<=right){
int mid=left+right>>1;
if(a[mid]==k)return mid;
else if(a[mid]5.寻找序列中第k小元素
思路:
对于序列a[s..t],在其中查找第k小元素的过程如下:
将a[s]作为基准(即最小下标位置的元素为数轴)进行一次划分,
对应的划分位置下标为i。3种情况:
若k=i-s+1 ,a[i]即为所求,返回a[i]。
若k<i-s+1 ,第k小的元素应在a[s..i-1]子序列中,递归在
该子序列中求解并返回其结果。
若k>i-s+1,第k小的元素应在a[i+1..t]子序列中,递归在该
子序列中求解并返回其结果。
int QuickSelect(int a[],int left,int right,int k){
int i=left,j=right,temp;
if(left=temp)j--;
a[i]=a[j];
while(ik)return QuickSelect(a,left,i-1,k);
else return QuickSelect(a,i+1,right,k-(i-left+1));
}
else if(left==right&&left==k-1)return a[k-1];
} 6.寻找两等长序列的中位数
对于含有n个元素的有序序列a[s..t],当n为奇数时,中
位数是出现在m=【(s+t)/2】处;当n为偶数时,中位数下标有
m=【(s+t)/2】(下中位)和m=【(s+t)/2】+1(上中位)两个。为了简
单,仅考虑中位数为m=【(s+t)/2】处。
int midNum(int a[],int l1,int r1,int b[],int l2,int r2)
{ //求两个有序序列a[s1..e1]和b[s2..e2]的中位数
int m1,m2;
if (l1==r1 && l2==r2) //两序列只有一个元素时返回较小者
return a[l1]b[m2]时
{
r1=m1; //a取前半部分
if((l2+r2)%2==0) l2=m2; //b取后半部分,奇数个元素
else l2=m2+1; //偶数个元素
return midNum(a,l1,r1,b,l2,r2);
}
}
} 7.求最大连续子序列和
对于含有n个整数的序列a[0..n-1],若n=1,表示该序列仅含一
个元素,如果该元素大于0,则返回该元素;否则返回0。
若n>1,采用分治法求解最大连续子序列时,取其中间位置mid=【(n-
1)/2】,该子序列只可能出现3个地方。
(1)该子序列完全落在左半部即a[0..mid]中。采用递归求出其最大连续子
序列和maxLeftSum。
(2)该子序列完全落在右半部即a[mid+1..n-1]中。采用递归求出其最
大连续子序列和maxRightSum。
(3)该子序列跨越序列a的中部而占据左右两部分。
long maxSubSum(int a[],int left,int right)
{
int i,j;
long maxleftsum,maxrightsum;
long maxleftbordersum,leftbordersum;
long maxrightbordersum,rightbordersum;
if(left==right){
if(a[left]>0){
return a[left];
}else{
return 0;
}
}
int mid=left+right>>1;
maxleftsum=maxSubSum(a,left,mid);
maxrightsum=maxSubSum(a,mid+1,right);
maxleftbordersum=0,leftbordersum=0;
for(i=mid;i>left;i--){
leftbordersum+=a[i];
if(leftbordersum>maxleftbordersum)
maxleftbordersum=leftbordersum;
}
maxrightbordersum=0,rightbordersum=0;
for(j=mid+1;j<=right;j++){
rightbordersum+=a[j];
if(rightbordersum>maxrightbordersum)
maxrightbordersum=rightbordersum;
}
return max(max(maxleftsum,maxrightsum),maxrightbordersum+maxleftbordersum);
}三.动态规划
四.贪心算法
1.贪心法概述
贪心法求解问题步骤:
1)确定合适的贪心选择标准
2)证明在此标准下该问题具有贪心选择性质和最优子结构性质
3)根据贪心选择标准,写出贪心选择的算法,求得最优解。
• 贪心法的基本思路是在对问题求解时总是做出在当前看来 是最好的选择,也就是说贪心法不从整体最优上加以考虑, 所做出的仅是在某种意义上的局部最优解。
• 方法的“贪婪性”反映在对当前情况总是作最大限度的选择,即贪心算法总是做出在当前看来是最好的选择。
所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最 优的选择,即贪心选择来达到。
也就是说,贪心法仅在当前状态下做出最好选择,即局部最优选择,然后再去求解做出这个选择后产生的相应子问题的解。
如果一个问题的最优解包含其子问题的最优解,则称此问题具有最优子结构性质。
问题的最优子结构性质是该问题可用动态规划算法或贪心法求解的关键特征。
贪心算法通常用来解决具有最大值或最小值的优化问题。 它是从某一个初始状态出发,根据当前局部而非全局的最优决策,以满足约束方程为条件,以使得目标函数的值增加最快或最慢为准则,选择一个最快地达到要求的输入元 素,以便尽快地构成问题的可行解。
算法框架:
SolutionType Greedy(SType a[],int n){
SolutionType x={};
for(int i=0;i2.贪心算法实例--求解单源最短路径
给定一个带权有向图G=(V,E),其中每条边的权是非负实数,另外,给定V中的一个顶点作为源点。现在要计算源点到其他各顶点的最短路径长度。这里路径长度是指路上各边权之和。这个问题通常称为单源最短路径问题。
Dijkstra算法是一种按各个顶点与源点之间路径长度的递增次序,生成源点到各个顶点的最短路径的方法——贪心算法,即先求出一条最短的路径,再参照它求出长度次短的一条路径,以此类推,直到求出所有为止。
算法步骤:将顶点集V划分成S和V-S两部分,其中S集合中的顶点到源点 的最短路径已经确定。
(1)初始时,S中仅含有源。设u是V的某一个顶点,把从源到u且中间只经过S中顶点的路称为从源到u的特殊路径,并用数组distance记录当前每个顶点所对应的最短特殊路径长度。
(2)每次从集合V-S中选取到源点v0路径长度最短的顶点w加入集合S。S中每加入一个新顶点w,都要修改顶点v0到集合V-S中节点的最短路径长度值。集合V-S中各节点新的最短路径长度值为原来最短路径长度值与顶点w的最短路径长度加上w到该顶点的路径长度值中的较小值。
(3)直到S包含了所有V中顶点,此时,distance就记录了从源到所有其他顶点之间的最短路径长度。
【贪心策略】设置两个顶点集合S和V-S,集合S 中存放己经找到最短路径的顶点,集合V-S中存放当前还未找到最短路径的顶点。 设置顶点集合S,并不断地作贪心选择来扩充这 个集合。一个顶点属于集合S当且仅当从源到该顶点的最短路径长度已知。
Dijkstra算法所作的贪心选择是从V-S中选择具有最短路径的顶点t,从而确定从源v到t的最短路径度distance [t]。 该最短路径:
要么是
要么是经过S 集合中的某顶点u到达的。
算法中确定的distance[u]确实是源点到顶点u的最短特殊路径长度。为此,只要考察算法在添加u到S中后,distance[u]的值所引起的变化。当添加u之后,可能出现一条到顶点i特殊的新路。
第一种情况:从u直接到达i。如果cost [u][i] + distance [u]
则 cost [u][i] + distance [u]作为distance [i]新值。
第二种情况:从u不直接到达i,如下图所示。回到老S中某个顶点x,最后到达i。当前distance [i]的值小于从源点经u和x,最后到达i的路径长度。因此,算法中不考虑此路。由此,不论distance [u]的值是否有变化,它总是关于当前顶点集S到顶点u的最短特殊路径长度。


void Dijkstra(int cost[][],int n,int v0,int distance[],int prev[]){
int *s=new int[n];
int mndis,dis;
int i,j,u;
for(int i=0;idis){
Distance[j]=dis;
prev[j]=u;
}
}
}
}
} 3.贪心算法实例--求解部分背包问题
【问题描述】设有编号为1、2、 … 、n的n个物品,它们的重量分别为w1、w2、 … 、wn,价值分别为v1、v2、 … 、vn,其中wi、vi (1≤i≤n)均为正数。
有一个背包可以携带的最大重量不超过W。
求解目标:在不超过背包负重的前提下,使背包装入的总价值最大(即效益最大化),与0/1背包问题的区别是,这里的每个物品可以取一部分装入背包。
选利润/重量为量度,使每一次装入的物品应使它占用的每一单位容量获得当前最大的单位效益。 按物品的vi/wi重量从大到小排序此方法解为最优解。可见,可以把vi/wi 作为部分背包问题的最优量度标准。
【贪心策略】选择单位重量价值最大的物品。
每次从物品集合中选择单位重量价值最大的物品,如果其重量小于背包容量,就可以把它完全装入,并将背包容量减去该物品的重量,然后就面临了一个最优子问题——它同样是背 包问题,只不过背包容量减少了,物品集合减少了。因此背包问题具有最优子结构性质。
int n=5;
double W=100;
struct Node{
double w;
double v;
double p;
bool operator<(const Node &s)const
{
return p>s.p;
}
};
Node A[]={{0},{10,20},{20,30},{30,66},{40,40},{50,60}};
double V;
double x[MAXN];
void Knap(){
V=0;
double weight=W;
memset(x,0,sizeof(x));
int i=1;
while(A[i].w0){
x[i]=weight/A[i].w;
V+=x[i]*A[i].v;
}
} 4.贪心算法实例--求解最优装载问题
【问题求解】
这里的最优解是选出尽可能多的集装箱个数,并采用贪心法求解。当重量限制为W时,wi越小可装载的集装箱个数越多,所以采用优先选取重量轻的集装箱装船的贪心思路。
对wi从小到大排序得到{w1,w2, … ,wn},设最优解向量为x={x1,x2, … ,xn},显然,x1=1,则x'= {x2, … ,xn}是装载问题w'={w2, … ,wn},W'=W-w1的最优解,满足贪心最优子结构性质。
int w[]={0,5,2,6,4,3};
int n=5,W=10;
int maxw;
int x[MAXN];
void solve(){
memset(x,0,sizeof(x));
sort(w+1,w+n+1);
maxw=0;
int restw=W;
for(int i=1;i<=n&&w[i]5.贪心算法实例--求解最优服务次序问题
【问题描述】 最优服务次序问题: 设有n个顾客同时等待同一 项服务,顾客i 需要的服务时间为ti,1 ≤ i ≤ n, 应如何安排这n个顾客的服务次序才能使平均等待时间达到最小。平均等待时间是n 个顾客等待服务时间的总和除以n。
五.回溯法
1.基本概念
搜索法:是利用计算机的高性能来有目的地枚举一个问题的部分或所有可能情况,从而找到问题的解的一种算法设计方法
搜索法的搜索策略:①穷举搜索,②深度优先搜索(回溯法),③广度优先搜索(分支限界法)。

回溯法解空间:问题的解由解向量X={x1,x2, … ,xn}组成,其中分量xi表示第i步的操作(确定解向量第i个分量xi )。
• 所有满足约束条件的解向量组构成了问题的解空间。
• 问题的解空间一般用树形式来组织,也称为解空间树或状态空间,树中的每一个结点确定所求解问题的一个问题状态。
•当搜索到第n+1层时,即到了叶子结点,则找到了问题的一个解。
2.回溯法解空间树
1.子集树
所给问题是从n个元素的集合中找出满足某种性质的子集时,相应的解空间树称为子集树。

2.排列树
例如,旅行售货员问题:一售货员周游若干城市销售商品,已知各个城市之间的路程,选择一个路线,使其经过每个城市仅一次,最后返回原地,并且总路程最小。
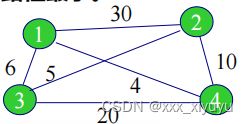

3.满M叉树
当所给问题的n个元素中每一个元素均有m种选择,要求确定其中的一种选择,使得对这n个元素的选择结果组成的向量满足某种性质,即寻找满足某种特性的n个元素取值的一种组合。这类问题的解空间树称为满m叉树。
3.回溯算法设计框架
回溯法是对解空间树的深度优先搜索法,通常有两种实现的算法。
递归回溯:采用递归的方法对解空间树进行深度优先 遍历来实现回溯。
迭代回溯:采用非递归迭代过程对解空间树进行深度 优先遍历来实现回溯。
1.子集树和m叉树的算法框架

【例】有一个含n个整数的数组a,所有元素均不相同,设计一个算法求其所有子集
【算法思想】 解:显然本问题的解空间为子集树,每个元素只有两种扩 展,要么选择,要么不选择。 采用深度优先搜索思路。
解向量为x[],x[i]=0表示不选择a[i], x[i]=1表示选择a[i]。
用i扫描数组a,也就是说问题的初始状态是(i=1,x的元素均为0),目标状 态是(i=n+1,x为一个解)。从状态(i,x)可以扩展出两个状态:不选择a[i]元素下一个状态为(i+1,x[i]=0)。 选择a[i]元素下一个状态为(i+1,x[i]=1)。
void display(int a[],int n,int x[]){
cout<<"{";
for(int i=0;i=n)display(a,n,x);
else{
x[i]=0;dfs(a,n,i+1,x);
x[i]=1;dfs(a,n,i+1,x);
}
} 回溯法搜索子集树和m叉树的算法性能 :
时间复杂度分析:n个分量,每个分量有m种取值,则树中共有(m^n )个叶子结点,总结点数为(O(m^n )),因此,遍历m叉树的时间复杂度为(m^(n+ 1)-1) 。
则空间复杂度:递归的深度,O(n)

【例】有一个含n个整数的数组a,所有元素均不相同,求其所有元素的全排列。
将求取1234(4个元素)全排列的问题转换为:分别取1234交换到第一 个位置作为“开头”,求取剩余元素(3个)的全排列问题(递归体) 当只有一个元素的时候其全排列就是该元素本身(递归出口)
void display(int a[],int n){
cout<<"{";
for(int i=0;i=n)display(a,n);
else{
for(int j=i;j 为了提高搜索效率,需要不断使用剪枝函数
约束函数:剪去不满足约束(显式、隐式)条件的子树
限界函数:剪去不能得到最优解的子树

归纳起来,用回溯法解题的一般步骤如下:
1、对于给定的问题,确定问题的解空间,确定解空间树类型(子集树or排列树or满M叉树),问题的解空间树应至少包含问题的一个(最优)解。
2、确定结点的扩展规则。
3、以深度优先方式搜索解空间树,并在搜索过程中可以采用剪枝函数来避免无效搜索。

4.回溯算法示例--子集树
1.子集和问题

思路:
为解决该问题可以使用递归回溯的方法来构造最优解,设cs为当前子集和,在解空间树中进行搜索时,若当前层i>n时,算法搜索至叶节点,其相应的子集和为cs。当cs=c,则找到了符合条件的解。当i<=n时,当前扩展结点Z是子集树的内部结点。该结点有x[i]=1和x[i]=0两个儿子结点。其左儿子结点表示x[i]=1的情形。
剪枝函数图示:(设置了一个全局变量r,记录剩余元素的和,初值为全部元素的和)
剪左支:若当前子集和+w[i]的和大于C,左子树的所有情况都可以排除;
剪右支:若当前子集和+剩余元素的和小于C,右子树的所有情况都可以排除。

//伪代码
void SubSum(int n){
if(i>=n){
if(cs==c){
for(int j=1;j<=n;j++){
if(x[j]==1)cout<=c){//检测右子树
x[i]=0;
SubSum(i+1);
}
r+=w[i];//递归退层时将该段加入剩余路径r中即第i层的扩展结点
return;
} 2.0-1背包问题
有n个重量分别为{w1,w2, … ,wn}的物品,它 们的价值分别为{v1,v2, … ,vn},给定一个容量为W的背包。设计从这些物品中选取一部分物品放入该背包的方案,每个物品要么选中要么不选中,要求选中的物品不仅能够放到背包中,而且满足重量限制具有最大的价值。
思路:
用w[1..n]/v[1..n]存放物品信息,x[1..n]数组存放最优 解,其中每个元素取1或0,x[i]=1表示第i个物品放入背包中, x[i]=0表示第i个物品不放入背包中。
case1:放入物品重量等于W。
int n=4; //4种物品
int W=6; //限制重量6
int w[]={0,5,3,2,1};//存放4个物品重量
int v[]={0,4,4,3,1};//存放4个物品价值
int x[MAXN]; //存放最终解
int maxv; //存放最优解
void dfs(int i,int tw,int tv,int op[]) {
if(i>n){
if(tw==W&&tv>maxv){
maxv=tv;
for(int j=1;j<=i;j++){
x[j]=op[j];
}
}
}
else{
op[i]=1;
dfs(i+1,tw+w[i],tv+v[i],op);
op[i]=0;
dfs(i+1,tw,tv,op);
}
}T(n)=O(2^n);
增加剪枝函数:
左支:对于第i层的有些结点,tw+w[i]已超过了W( W=6),显然 再选择w[i]是不合适的。
仅扩展满足tw+w[i]<=W的左孩子结点。
右支:rw=w[i]+w[i+1]+…+w[n],
当不选择物品i(第i个物品的决策已做出,即不选择第i个物品)时:若tw+rw-w[i]
int n=4; //4种物品
int W=6; //限制重量6
int w[]={0,5,3,2,1};//存放4个物品重量
int v[]={0,4,4,3,1};//存放4个物品价值
int x[MAXN]; //存放最终解
int maxv; //存放最优解
int rw; //存放剩余物品重量,初始为所有物品重量。
void dfs(int i,int tw,int tv,int op[]) {
if(i>n){
if(tw==W&&tv>maxv){
maxv=tv;
for(int j=1;j<=i;j++){
x[j]=op[j];
}
}
}
else{
if(tw+w[i]<=W){//左剪枝
op[i]=1;
dfs(i+1,tw+w[i],tv+v[i],op);
}
if(tw+rw-w[i]>=W){//右剪枝
op[i]=0;
dfs(i+1,tw,tv,op);
}
}
}case2:放入物品重量小于W。
前面左剪枝的方式不变,但右剪枝不再有效,需要改为上界函数进行右剪枝。


假设当前求出最大价值maxv,若 bound(i)≤maxv,则右剪枝,否则继续扩展。
显然r越小,bound(i)也越小,剪枝越多,为了构造更小的r,将所有物品以单位重量价值递减排列。

int n=4; //4种物品
int W=6; //限制重量6
int w[]={0,5,3,2,1};//存放4个物品重量
int v[]={0,4,4,3,1};//存放4个物品价值
int x[MAXN]; //存放最终解
int maxv; //存放最优解
int rw; //存放剩余物品重量,初始为所有物品重量。
int A[n]; //递减排列物品单位重量
int bound(int i,int tw,int tv){
i++;
while(i<=n&&tw+A[i].w<=W){
tw+A[i].w;
tv+A[i].v;
i++;
}
if(i<=n)
return tv+(W-tw)*A[i].p;//其实是背包达不到的一个最大价值数
else
return tv;
}
void dfs(int i,int tw,int tv,int op[]) {
if(i>n){
if(tw==W&&tv>maxv){
maxv=tv;
for(int j=1;j<=i;j++){
x[j]=op[j];
}
}
}
else{
if(tw+w[i]<=W){//左剪枝
op[i]=1;
dfs(i+1,tw+A[i].w,tv+A[i].v,op);
}
if(bound(i,tw,tv)>maxv){//右剪枝
op[i]=0;
dfs(i+1,tw,tv,op);
}
}
}5.回溯算法示例--排列树
1.N后问题
N皇后问题,是一个古老而著名的问题,是回溯算法的典型例题,可以简单的描述为:在N*N格的棋盘上摆放N个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法?

思路:
假设皇后t放在第t行上,用n元组x[1:n]表示n皇后问题的解,x[t]表示皇后t放在第t行的第x[t]列上。
剪枝函数:对于两个皇后i,j 两个皇后肯定不同行
两个皇后不同列:x[i] ≠x[j]
两个皇后不同一条斜线: abs(i-j) ≠ abs(x[i]-x[j])
int place(int j){
for(int i=1;i=n)sum++;//可行解加一
else{
for(int j=t;j<=n;j++){
swap(&x[j],&x[t]);
if(place(t))queen(t+1);
swap(&x[j],&x[t]);
}
}
} 满n叉树:
void queen(int t){//排列树框架
if(t>=n)sum++;//可行解加一
else{
for(int j=t;j<=n;j++){
swap(&x[j],&x[t]);
if(place(t))queen(t+1);
swap(&x[j],&x[t]);
}
}
}2.哈密尔顿回路问题
设G=(V,E)是一个有n个结点的无向图。一条哈密顿回路是通过图中每个结点仅且一次的回路。设计算法,给定一个图,求其是否存在一条哈密顿回路。如果是,输出每一条哈密顿回路;否则给出提示。
思路:
用数组x[n]表示该问题的一组解,x[i]表示在 第i次访问的结点号。
当k=n+1时,当前扩展结点是叶结点。此时需要检测无向图G是否存在一条从顶点x[n]到顶点x[1]的边,如果存在,则找到一条哈密顿回路;否则回溯。当k<=n时,当前扩展结点位于排列树的第k层,若图G中存在从顶点x[k-1]到顶点x[k]的邻接的边时,x[1:k]就构成了图G的一条路径。
void hamilton(int k){
if(k>n&&g[x[n]][x[1]]==1)
output(x);
else
for(int j=k;j<=n;j++){
swap(x[k],x[j]);
if(g[x[k-1]][x[k]]==1)
hamilton(k+1);
swap(x[j],x[k]);
}
}6.总结

六.分支限界法
1.分支限界法概述
1.分支限界法与回溯法类似,也是对问题在解空间树上的解决,不同之处在于,回溯法是对解空间树进行深度优先搜索,而分支限界法是对解空间树的广度优先搜索。回溯法的目的是找出所有满足条件的解,而分支限界法目的是找出最优解。
Q:求最优解时,如何选择子结点进行再扩展?
A:设计一个限界函数,计算限界函数值,选择一个最有利的子结点作为扩展结点,使搜索朝着解空间树上有最优解的分支推进,以便尽快地找出一个最优解。
分支限界法与回溯法比较:

2.设计思想
①设计合适的限界函数
在搜索解空间树时,每个活结点可能有很多孩子结点,其中有些孩子结点搜索下去是可能产生问题解或最优解。通过设计好的限界函数在扩展时删除不必要的孩子结点,从而提高搜索效率。
②组织活结点表
Ⅰ普通队列式分支限界法
队列式分支限界法将活结点表组织成一个队列,并按照队列先
进先出(FIFO)原则选取下一个结点为扩展结点。步骤如下:
①将根结点加入活结点队列。
②从活结点队中取出队头结点,作为当前扩展结点。
③对当前扩展结点,先从左到右地产生它的所有孩子结点,用约
束条件检查,把所有满足约束条件的孩子结点加入活结点队列。
④重复步骤②和③,直到找到一个解或活结点队列为空为止。
Ⅱ优先队列式分支限界法
优先队列式分支限界法的主要特点是将活结点表组成一个优先
队列,并选取优先级最高的活结点成为当前扩展结点。步骤如下:
①计算起始结点(根结点)的优先级并加入优先队列(与特定问题相
关的信息的函数值决定优先级)。
②从优先队列中取出优先级最高的结点(队头)作为当前扩展结点,使
搜索朝着解空间树上可能有最优解的分枝推进,以便尽快地找出一
个最优解。
③对当前扩展结点,先从左到右地产生它的所有孩子结点,然后用约
束条件检查,对所有满足约束条件的孩子结点计算优先级并加入优
先队列(进队)。
④重复步骤②和③,直到找到一个解或优先队列为空为止。
PS:
优先队列利用堆来实现。堆可以看作一棵完全二叉树的顺序存储结构。在这棵完全二叉树中:Ø 若树非空,且根结点的值均大于其左右孩子结点的值,则称之为大根堆;且其左、右子树分别也是大根堆。Ø 若树非空,且根结点的值均小于其左、右孩子结点的值,则称之为小根堆;且其左、右子树分别也是小根堆。
优先队列的两个基本操作:
出队:堆顶出队,最后一个元素代替堆顶位置,重新调整成堆;
进队:新进队元素放在堆末尾之后,重新调整成堆
优先队列出队操作(以大根堆为例)
• 出队:堆顶出队,最后一个元素代替堆顶位置。除了堆顶外,其他结点均满足大根堆定义,只需将堆顶执行“下沉”操作即可调整为堆。
• “下沉” :堆顶与其左、右孩子进行比较,若满足堆定义,则不需调整。若不满足,则与其值较大的孩子进行交换,交换后,继续向下调整,直到满足大根堆定义为止


优先队列进队操作(以大根堆为例)
• 进队:进队操作后,除了新进队的元素外,其他结点都满足大根堆的定义,需要将新元素执行“上浮”操作,调整成堆。
• “上浮” :新进队元素与其双亲比较,如果值小于其双亲,则满足堆定义,无需调整。如果其值比双亲大,则与双亲交换,交换到新位置后,继续向上比较、调整,直到满足大根堆定义为止。

③.确定最优解的解向量x

两个X均要入队保存的两种方法:
①对每个扩展结点保存从根结点到该结点的“路径” 。每个结点带有一个可能的解向量。这种做法比较浪费空间,但实现起来简单。(0-1背包问题为例)
②在搜索过程中构建搜索经过的树结构。每个结点记录其双亲的信息,当找到最优解时,通过双亲信息找到对应的最优解向量。(单源最短路径为例)
3.算法性能
在最坏情况下,时间复杂性是指数阶。通过设计限界函数和 约束进行剪枝,提高算法效率
2.分支限界法示例
有n个重量分别为{w1,w2,…,wn}的物品,它 们的价值分别为{v1,v2,…,vn},给定一个容量为W的背包。 设计从这些物品中选取一部分物品放入该背包的方案,每个物品要么选中要么不选中,要求选中的物品不仅能够放到背包中,而且重量和不超过W具有最大的价值。
设计限界函数:
对于第i层的某个结点e,用e.w表示结点e时已装入的总重量,用e.v表示已装入的总价值。E.i=i即对应表示结点e的状态是在确定解向量的e.X[E.i]分量;计算当前结点e对应的状态所能达到的价值上界ub。如果所有剩余的物品都能装入背包, 那么价值的上界e.ub=e.v+ (v[i+1]+…+v[n]) 如果所有剩余的物品不能全部装入背包, 那么价值的上界e.ub=e.v+ (v[i+1]+…+v[k])+(物品k+1装入的部分重量)× 物品k+1的单位重量价值。
注:为了计算出来的上界更加紧凑,需要物品按单位重量价值递减有序。
2.图的单源最短路径问题
给定一个带权有向图G=(V,E),其中每条边的权是一个正整数。另外,还给定V中的一个顶点v,称为源点。计算从源点到其他所有顶点的最短路径长度。这里的长度是指路上各边权之和。
①普通队列式
设计记录路径path的解向量:即用prev数组存放最短路径,prev[i]表示源点v到顶点i的最短路径中顶点i的前驱顶点。
用dist数组存放源点v出发的最短路径长度,dist[i]表示源 点v到顶点i的最短路径长度,初始时所有dist[i]值为∞。
#define INF 0x3f3f3f3f //表示∞
#define MAXN 51
int n; //图顶点个数
int a[MAXN][MAXN];//图的邻接矩阵
int v; //源点
int dist[MAXN]; //dist[i]源点到顶点i的最短路径长度
int prev[MAXN]; //prev[i]表示源点到j的最短路径中顶点j的前驱顶点
struct Node{
int vno;
int length;
};
void bfs(int v){
Node e1,e;
queueq;
e.vno=v;e.length=0;//建立源点结点e(根结点)
q.push(e);//根结点入队
dist[v]=0;
while(!q.empty()){
e=q.front();
q.pop();
for(int j=0;j ②优先队列式
采用STL的priority_queue

#define INF 0x3f3f3f3f //表示∞
#define MAXN 51
int n; //图顶点个数
int a[MAXN][MAXN];//图的邻接矩阵
int v; //源点
int dist[MAXN]; //dist[i]源点到顶点i的最短路径长度
int prev[MAXN]; //prev[i]表示源点到j的最短路径中顶点j的前驱顶点
struct Node{
int vno;
int length;
bool operator < (const Node& b) const
{
return length>b.length;
}
};
void bfs(int v){
Node e1,e;
priority_queue pq;
e.vno=v;e.length=0;//建立源点结点e(根结点)
pq.push(e);//根结点入队
dist[v]=0;
while(!pq.empty()){
e=pq.top();
pq.pop();
for(int j=0;j 3,小结
分支限界法与回溯法的主要区别。
分支限界法对问题的解空间树进行搜索的过程
Ø一次性产生当前扩展结点的所有孩子结点;
Ø在产生的孩子结点中,抛弃那些不可能产生可行解(约束)或最优解的结点(限界);
Ø将其余的孩子结点加入活结点表;
Ø从活结点表中选择下一个活结点作为新的扩展结点。
Ø重复上述步骤,直到找到一个解或优先队列为空为止。
分支限界法的关键问题
Ø如何确定合适的限界函数。
Ø如何组织待处理活结点表(普通队列和优先队列)。
Ø如何确定最优解中的各个分量。