机器学习(一)Spark机器学习基础
文章目录
- 1. Spark机器学习基础
-
- 1.0机器学习和大数据的区别和联系
- 1.1机器学习引入
- 1.2机器学习三次浪潮
- 1.3人工智能领域基础概念区别
-
- 1.3.1人工智能、机器学习、深度学习关系
- 1.3.2 数据分析、数据挖掘基本概念区别
- 1.3.3各技术交叉点
- 后记
1. Spark机器学习基础
l 学习目标
掌握机器学习与大数据的区别和联系
掌握机器学习概念
掌握机器学习如何构建机器学习模型过程
1.0机器学习和大数据的区别和联系
首先,回顾大数据的4V特征:
1.数据量大
TB-PB-ZB
HDFS分布式文件系统
2.数据种类多
结构化数据-Mysql为主的存储和处理
非结构化数据-文本、图像、音频-HDFS、MR、Hive
半结构化数据-XML、HTML形式-HDFS、MR、Hive、Spark
3.速度快
数据的增长速度快-TB-PB-ZB- HDFS
数据的处理的速度快MR-HIVE-PIG-Impala(离线)-Spark-Flink(实时)
4.价值密度低
价值密度=有价值的数据/ALL、价值高
机器学习算法解决的问题
大数据框架实现基础的数据存储和数据计算,如果从大量的数据中发现和挖掘出有价值的信息,需要借助机器学习算法,结合数据,构建机器学习模型实现对现实事件的预测。不同于以往的硬编码规则的方式,机器学习是通过机器学习算法发现或挖掘出数据中存在的规律或模式。
1.1机器学习引入
试想这样一个场景,傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞。心里想着明天又是一个好天气。走到水果摊旁,挑了个色泽青绿、敲起来声音浊响的青绿西瓜,一边期待着西瓜皮薄肉厚瓤甜的爽落感,一边愉快地想着,明天学习Python机器学习一定要狠下功夫,基础概念搞得清清楚楚,案例作业也是信手拈来,我们的学习效果一定差不了。
希望大家在学习完之后有这样的感觉,我们首先大致了解什么是“机器学习”(machine learning)。
回想刚刚我们买西瓜的场景,我们会发现这里涉及很多基于经验做出的预判。
(1)为什么看到微湿路面、感到和风、天边晚霞就认为明天是好天呢?
答:这是因为在我们的生活经验中已经遇见过很多类似的情况,前一天观察到上述特征后,第二天天气通常会很好。
(2)为什么色泽青绿、敲声浊响就能判断出是正熟的好西瓜呢?
答:这是因为我们吃过、看过很多的西瓜,所以基于色泽、敲声这几个特征我们就可以做出相当好的判断。
再进一步深入机器学习概念之前首先了解下机器学习或人工智能在当下的应用场景。
首先,人工智能对我们未来生活的改变,大家试想几年后,人工智能将可能取代世界上90%的岗位:

人工智能不是模仿人类,而通常是超越人类。我们试想几年后我们能够每天自我对弈100万盘棋,并从中学习的AlphaGO吗?
随着人工智能的发展,人工智能的热门方向和应用越来越多,如下图,这里总结六个方面:
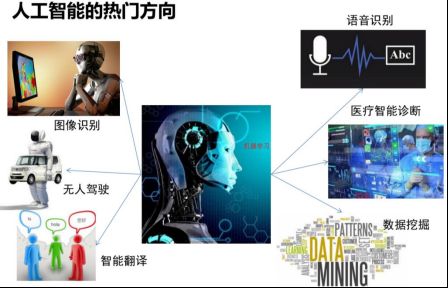
1.2机器学习三次浪潮
机器学习的三次浪潮也可以说是人工智能的三次浪潮,因为机器学习是人工智能(Artificial Intelligence)研究发展到一定阶段的必然产物。
l 1956 Artificial Intelligence提出
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。IBM公司“深蓝”电脑击败了人类的世界国际象棋冠军更是人工智能技术的一个完美表现。人工智能的目的就是让计算机这台机器能够像人一样思考。
l 1950-1970
符号主义流派:专家系统占主导地位
1950:图灵设计国际象棋程序
1962:IBM Arthur Samuel的跳棋程序战胜人类高手(人工智能第一次浪潮)
l 1980-2000
统计主义流派
主要用统计模型解决问题
Vapnik 1993
1997:IBM 深蓝战胜卡斯帕罗夫(人工智能第二次浪潮)
l 2010-至今
神经网络、深度学习、大数据流派
Hinto> 2006
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
刚才说到我们三次浪潮,前两次每次都是这样,说人类要毁灭了,后来发现其实并不是这样。我们现在就处在这个状态,人类又要毁灭了。其实和前两次比,还是有一点区别。

最大的一个区别就是它现在真的是深入到我们生活的每一个角落,打开你的手机看看,淘宝,智能推荐,拍一拍,谷歌翻译,搜索引擎,智能出行,智能规划,微信,智能助理,头条,智能推荐,还有机器识别,其实它已经深入的改变了我们生活的每一个角落,而将来它会改变更多。
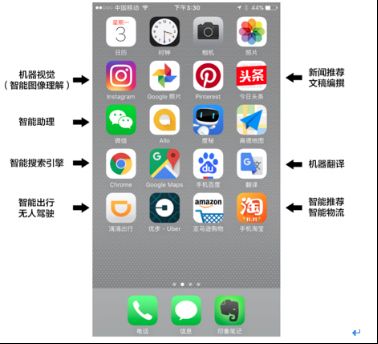
1.3人工智能领域基础概念区别
1.3.1人工智能、机器学习、深度学习关系
机器学习是人工智能的一个分支,深度学习是实现机器学习的一种技术。如下图:
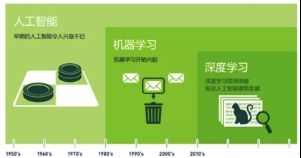
机器学习是研究如何使计算机能够模拟或实现人类的学习功能,从大量的数据中发现规律,提取知识,并在实践中不断地完善和增强自我。机器学习是机器获取知识的根本途径,只有让计算机系统具有类似人的学习能力,才可能实现人工智能的终极目标。
机器学习是人工智能研究的核心问题之一,也是当前人工智能研究的一个热门方向,同时也是人工智能理论研究和实际应用的主要瓶颈之一。
1.3.2 数据分析、数据挖掘基本概念区别
首先我们了解什么是数据,什么是信息?
(1)数据—即观测值,例如测量数据,你的身高,体重都是测量数据。
(2)信息:(信息抽象地说就是)可信的数据。
数据------>信息:数据和信息最大的区别就是一个是客观一个是主观。如:用尺子量桌子宽度,测量得到的值就是数据,这是客观存在的。
而对于用户而言只会关心桌子是长还是短、高还是低,大了买小的等。这种主观对客观数据的接受和在描述,就是信息。
(3)数据分析:对数据的一种操作手段,目标是经过先验(已有经验)的约束,对数据进行整理、筛选和加工,最后得到信息。【从数据到信息的转化过程】
(4)数据挖掘:是对数据分析之后的信息,进行价值化的分析。【信息的价值化】
(5)数据挖掘和数据分析的关系
数据分析:针对历史数据,分析得出各项指标,经过数据分析我们得到的是信息。
数据挖掘[大量的数据挖掘规律]:经过数据挖掘我们得到的是有价值的信息,即对信息进行价值提取或数据挖掘。
举例:啤酒和尿布的故事
数据分析(信息):根据沃尔玛历史销售数据,分别分析买各种商品的人各自具有什么特征。
数据挖掘(有价值的信息):根据历史销售数据,使用关联规则挖掘,分析买了啤酒的人还会购买什么,从而得出尿布。
1.3.3各技术交叉点
了解了数据挖掘,我们在介绍下机器学习和数据挖掘的关系。
用机器学习的方法来进行数据挖掘。机器学习是一种方法;数据挖掘是一件事情;还有一个相似的概念就是模式识别,这也是一件事情。而现在流行的深度学习技术只是机器学习的一种;
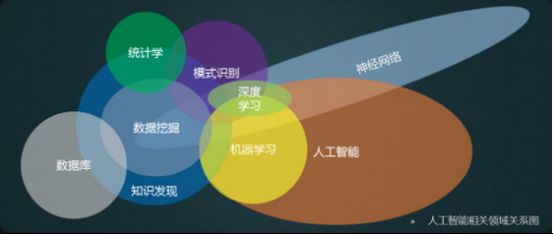
人工智能是研究如何让机器具有类人智能的学科,目标是让机器具有人类的智能。机器学习,是达到人工智能目标的手段之一;模式识别也是达到人工智能的手段之一;
如上图所示,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。
人工智能范围比较大,机器学习相对来说属于人工智能的范畴。数据挖掘则是将机器学习作为工具,利用机器学习的算法用来完成数据挖掘。另外数据挖掘也使用到其他很多内容。
后记
博客主页:https://manor.blog.csdn.net
欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
本文由 Maynor 原创,首发于 CSDN博客
不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12468207.html