技术动态 | 大模型用于知识图谱推理常用范式:兼论基于TransE模型的知识推理实践...
转载公众号 | 老刘说NLP
知识推理是从已有的知识出发,得出未知的、隐性的知识,具体到知识图谱中,即利用图谱中现有的知识(三元组),得到一些新的实体间的关系或者实体的属性(三元组)。
关于知识推理这一任务,我们已经在《OGB-知识推理概览必读:三大推理评测任务、数据集与现有模型水平概述》、《技术总结:知识图谱推理中的常用方法、关键问题、评测指标与开放数据总结》等文章中进行了理论性的介绍。
其中知识图谱推理主要有以下几种常见方案:

1、KG补全常用方法
KG补全方法可以分为基于嵌入的和基于PLM的方法。
首先,基于嵌入的方法将实体和关系表示为嵌入向量,并在向量空间中保持其语义关系。例如:
TransE将三元组的头、关系和尾部向量化为一个欧氏空间;DistMult将所有的关系embeddings转换为双线性模型的对角线矩阵;RotatE将每一个关系embedding呈现为复数向量空间中从头实体到尾实体的旋转;
近年来,研究人员已经意识到PLM可以作为知识库,并且基于PLM的KG补全方法开始获得关注。例如:
KG-BERT通过在每个三元组中串联头部、关系和尾部来微调PLM,在链接预测任务中优于传统的基于嵌入的方法;PKGC使用人工设计的三元组提示和精心设计的支持提示作为PLM的输入;
2、使用提示的知识探查
LAMA是第一个从PLM中探测知识的框架,提示是手动创建的,有一个主题占位符和一个未填充的空间作为对象。
例如,一个三元组织查询(迈阿密,位置,?)可能有一个提示 "迈阿密位于[MASK]",其中"<主体>位于[MASK]"是 "位置 "关系的模版,训练目标是用PLM的预测来正确填充[MASK];
BertNet提出了一种应用GPT-3的方法,以输入实体对和手动种子提示自动生成一个加权的提示 en- semble。然后,再次使用PLM进行搜索,并将排名靠前的实体对与集合体进行配对,以使KG完成补全。
3、提示语挖掘方法
当有多个关系需要解释时,由于需要领域专家的知识,人工提示设计成本很高。此外,提示的质量也无法得到保证。
MINE在大型文本语料库(如维基百科)中搜索给定输入和输出之间的中间词或依赖路径,并通过对提示个体在PLM上的表现进行加权来优化挖掘出来的提示的合集。
在PLM出现和广泛使用之前,文本模式挖掘也受到关注,为信息提取找到可靠的模式。例如,MetaPAD通过模式质量函数的上下文感知分割生成高质量的元模式,TruePIE提出了模式嵌入的概念和自我训练框架,自动发现模式。
大模型时代,在工作《Text-Augmented Open Knowledge Graph Completion via Pre-Trained Language Models》一文将大模型应用于知识图谱推理,这个我们在之前的文章《预训语言模型在知识图谱补全任务上的探索:TAGREAL高质量提示自动化生成与KG补全框架工作解读》中已有介绍。
地址:https://arxiv.org/pdf/2305.15597.pdf

如下所示,TAGREAL为了自动生成更高质量的提示,通过信息检索方法从语料库中搜索相关的文本信息来支持PLM知识探测,先自动生成一个带有输入实体对和手动种子提示的加权提示集合,然后再次使用PLM进行搜索,并将排名靠前的实 体对与集合体进行配对,以完成KG补全。
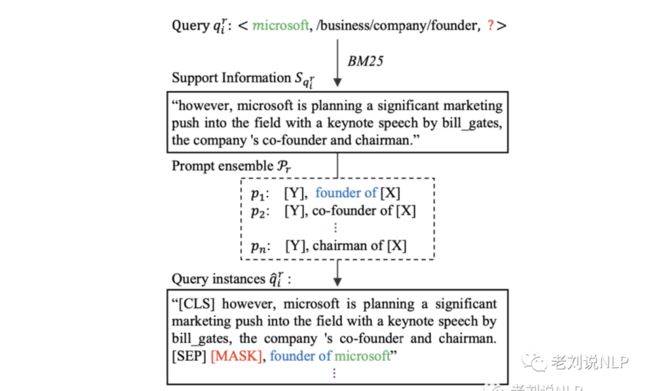
了解现在大模型用于知识推理工作之外,我们依旧需要从一些底层的方法来进行讲述,本文进一步从理论和实践的角度出发,完成一次知识推理的模型训练和推理小任务,增进大家对知识推理的了解,主要从知识推理的三个主流方法与基础任务、基于TransE模型的知识推理的训练、基于TransE模型的知识补全推理实验三个方面进行介绍,供大家一起参考。
一、知识推理的三个主流方法与基础任务
1、知识推理的几个基础任务
知识推理的几个基础任务主要包括知识补全、知识纠错、推理问答等,其中:
知识补全,即通过算法,补全知识图谱中缺失的属性或者关系。实际构建的知识图谱,通常存在不完备的问题,即部分关系或属性会缺失。
知识图谱的纠错,即发现图谱中的错误知识进行修正。例如,实际构建的知识图谱还可能存在错误知识。实体的类型、实体间的关系、实体属性值均可能存在错误。
基于知识图谱的推理问答,即KBQA,通常应用于涉及多个实体,多个关系,多跳,比较等相对复杂的问答任务。

1)知识推理任务示例
如上图所示,以“姚沁蕾的妈妈是谁“为例。有一条常识是 “父亲的妻子是妈妈”,则可依据该常识,推理出姚沁蕾的妈妈是叶莉,进而补全”姚沁蕾”和“叶莉”之间的关系,提升知识图谱的完备性。
2)知识纠错任务示例
如上图所示,在某个影视知识图谱中,虚线框中的实体《春光灿烂猪八戒》,其类型为“电影“。它的属性有集数,主题曲、片尾曲等。而其他同为”电影“类别的实体,其属性多包含上映时期、票房,且大多没有集数这个属性。则推理可知,《春光灿烂猪八戒》这个实体的类型大概率存在错误,其正确类型应该是电视剧。
3)推理问答任务示例
如上图所示,面对“刘德华主演的电影中豆瓣评分大于8分的有哪些?“这样的问题,需要机器对该问题进行解析、理解,在知识图谱中完成查询、推理、比较动作,找到《天下无贼》和《无间道》作为答案返回。
2、知识推理的三个主流方法
知识推理的方式主要包括基于本体的推理、基于规则的推理、基于表示学习的推理等几种方式。
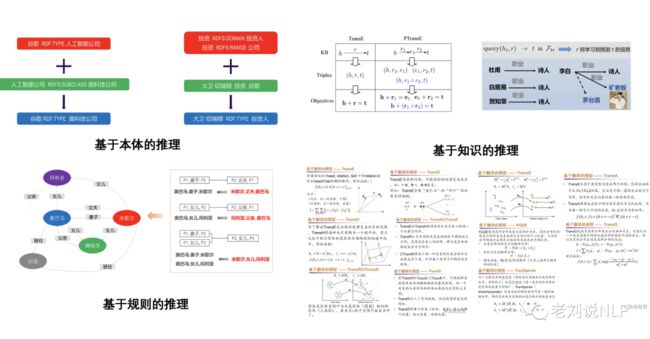
其中:
基于本体的推理思想在于:利用本体已经蕴含的语义和逻辑,来对实体类型以及实体之间的关系进行推理,例如,RDFS定义了一组用于资源描述的词汇:包括class,domain,range等。其本身就蕴含了简单的语义和逻辑。我们可以利用这些语义和逻辑进行推理。
基于规则的推理的思想在于:可以抽象出一系列的规则,将这些规则应用于知识图谱中,进行补全纠错。这种思路很简单、直观的。基于规则的推理的优点是,推理结果精准,并且具有可解释性。
基于知识表示的推理的思想在于:基于表示学习的推理,通过映射函数,将离散符号映射到向量空间进行数值表示,同时捕捉实体和关系之间的关联,再在映射后的向量空间中进行推理。其用于解决本体体推理和规则推理不易于扩展的缺点。
1)基于本体的推理示例
如上图所示,谷歌的类型是一家人工智能公司,而人工智能公司又是高科技公司的子类,那么可推理,谷歌的也是一家高科技公司。右侧例子中,定义了投资这种关系的domain是投资人,range是公司。可以简单的认为,投资这种关系的头节点都是投资人这种类型、尾节点都是公司这种类型。假设现在有一条事实是<大卫切瑞顿, 投资, 谷歌> 。则可以推理出,大卫切瑞顿的类型是投资人。
2)基于规则的推理示例
如上图所示,人工定义了一些规则,包括“B是A的妻子,则A是B的丈夫”、“B是A的女儿,则A是B的父亲”等等。运用这些规则来进行推理,进而补全知识图谱的缺失关系。我们可以利用这些规则,推理出“米歇尔的丈夫是奥巴马”、“玛利亚的父亲是奥巴马”等新的知识。
3)基于表示学习的推理示例
如上图所示,我们基于已有图谱推理“李白的职业”。假设我们已经找到了一个映射函数,可以把知识图谱和一段包含相关信息的文本映射到同一向量空间。再对这些向量进行计算,比如把“李白”、“职业”两个向量简单相加后,并与候选的诗人、矿老板、茅台酒的向量相减,可以得到与诗人的向量距离最小,就可以得到李白的职业是诗人这一结论。
二、基于TransE模型的知识推理的训练
1、TransE基本算法
TransE将每个实体和关系都表示成一个向量,并假设对于一个存在在知识图谱中的三元组, 的向量表示满足: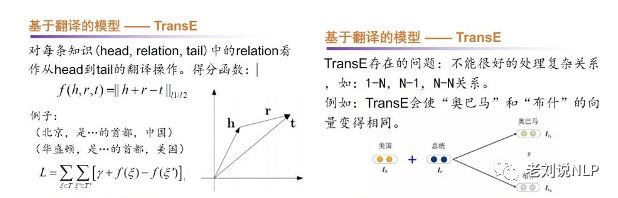 即:
即:
对于一个三元组的评分函数为:
TransE的损失函数:
其中是所有正样本的集合,是所有负样本的集合,对于一个正样本负样本通过随机替换或得到, 表示间隔,是一个超参。
因此,我们可以定义出模型的代码结构:
class TransE(BaseModel):
def __init__(self, args):
super(TransE, self).__init__(args)
self.entity_num = args.entity_num
self.rel_num = args.rel_num
self.embedding_dimension = args.embedding_dim
self.entity_embedding = nn.Embedding(self.entity_num, self.embedding_dimension).to(DEVICE)
self.rel_embedding = nn.Embedding(self.rel_num, self.embedding_dimension).to(DEVICE)
if args.score_func == 'l1':
self.score_func = l1_score
else:
self.score_func = l2_score
def init_weights(self):
nn.init.xavier_normal_(self.entity_embedding.weight)
nn.init.xavier_normal_(self.rel_embedding.weight)
def forward(self, head, rel, tail):
vec_head = self.entity_embedding(head).view(-1, self.embedding_dimension)
vec_rel = self.rel_embedding(rel).view(-1, self.embedding_dimension)
vec_tail = self.entity_embedding(tail).view(-1, self.embedding_dimension)
vec_head = F.normalize(vec_head)
vec_rel = F.normalize(vec_rel)
vec_tail = F.normalize(vec_tail)
return self.score_func(vec_head, vec_rel, vec_tail)2、训练数据集构造
这个示例中,我们使用的是一个人工构造的小的中文数据集(主要来自于参考文献2),示例图谱可视化如下:
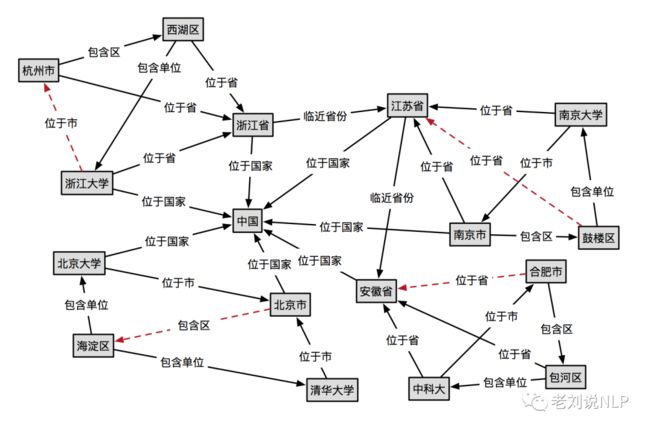
train.csv:包含28个训练三元组,文件的每一行每一行表示一个三元组, 按头实体、关系、尾实体顺序 ,并用’,’分隔。
西湖区,包含单位,浙江大学
西湖区,位于省,浙江省
浙江大学,位于省,浙江省
浙江大学,位于国家,中国
杭州市,位于省,浙江省
杭州市,包含区,西湖区
浙江省,位于国家,中国
浙江省,临近省份,江苏省
南京大学,位于省,江苏省
南京大学,位于市,南京市
鼓楼区,包含单位,南京大学
南京市,包含区,鼓楼区
南京市,位于省,江苏省
南京市,位于国家,中国
江苏省,位于国家,中国
海淀区,包含单位,清华大学
海淀区,包含单位,北京大学
清华大学,位于市,北京市
北京市,位于国家,中国
北京市,包含区,海淀区
北京大学,位于市,北京市
北京大学,位于国家,中国
安徽省,位于国家,中国
合肥市,包含区,包河区
包河区,位于省,安徽省
包河区,包含单位,中科大
中科大,位于省,安徽省
中科大,位于市,合肥市test.csv:包含4个测试三元组,文件的每一行表示一个三元组, 按头实体、关系、尾实体顺序 ,并用’,’分隔。
浙江大学,位于市,杭州市
北京市,包含区,海淀区
鼓楼区,位于省,江苏省
合肥市,位于省,安徽省3、模型训练
在模型训练阶段,我们以参考文献4为实验脚本进行处理,train阶段的代码如下,其思想在于,以训练集中的所有样本作为正样本,并使用gen_neg_batch,随机替换头尾实体,生成负样本进行训练。
def train(self, train_path, model_type=DEFAULT_CONFIG['model_type'], save_path=DEFAULT_CONFIG['save_path'], dev_path=None, **kwargs):
train_dataset = rl_tool.get_dataset(train_path)
if dev_path:
dev_dataset = rl_tool.get_dataset(dev_path)
entity_vocab, relation_vocab = rl_tool.get_vocab(train_dataset, dev_dataset)
else:
entity_vocab, relation_vocab = rl_tool.get_vocab(train_dataset)
self._entity_vocab = entity_vocab
self._relation_vocab = relation_vocab
train_iter = rl_tool.get_iterator(train_dataset, batch_size=DEFAULT_CONFIG['batch_size'])
config = Config(entity_vocab, relation_vocab, save_path=save_path, **kwargs)
if model_type in MODELS:
model = MODELS[model_type](config)
else:
raise Exception('there is no model named {}! please check the name carefully'.format(model_type))
# print(self._model)
self._model = model
optim = torch.optim.Adam(self._model.parameters(), lr=config.lr)
criterion = nn.MarginRankingLoss(config.loss_margin, reduction='mean')
for epoch in range(config.epoch):
self._model.train()
acc_loss = 0
for item in tqdm(train_iter):
optim.zero_grad()
neg_head, neg_tail = get_neg_batch(item.head, item.tail, self._model.entity_num)
pos_score = self._model(item.head, item.rel, item.tail)
neg_score = self._model(neg_head, item.rel, neg_tail)
item_loss = criterion(neg_score, pos_score, torch.ones_like(pos_score))
acc_loss += item_loss.item()
item_loss.backward()
optim.step()
logger.info('epoch: {}, acc_loss: {}'.format(epoch, acc_loss))
if dev_path:
dev_score = self._validate(dev_dataset)
logger.info('dev score:{}'.format(dev_score))
adjust_learning_rate(optim, config.lr / (1 + (epoch + 1) * config.lr_decay))
config.save()
self._model.save()4、模型训练结果
我们训练迭代一千次后,可以发现,dev score已经达到0.5584765374660492,并不算高。
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5579377072198051
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 344.59it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:63] epoch: 995, acc_loss: 1.0587621927261353
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 875.64it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5580466261931828
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 340.14it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:63] epoch: 996, acc_loss: 1.1031407117843628
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 904.92it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5581563987902233
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 319.98it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:63] epoch: 997, acc_loss: 1.234864354133606
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 700.80it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5582636243530682
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 296.65it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:63] epoch: 998, acc_loss: 1.181252360343933
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 791.68it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5583705337984222
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 292.65it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:63] epoch: 999, acc_loss: 1.221413016319275
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 876.92it/s]
[2023-03-12 10:39:17] [INFO] [MainThread] [module.py:66] dev score:0.5584765374660492
[2023-03-12 10:39:17] [INFO] [MainThread] [model.py:33] saved config to ./krl_2TransE_saves/config.pkl
[2023-03-12 10:39:17] [INFO] [MainThread] [model.py:55] saved model to ./krl_2TransE_saves/model.pkl
[2023-03-12 10:39:17] [INFO] [MainThread] [model.py:21] loadding config from ./krl_2TransE_saves/config.pkl
[2023-03-12 10:39:17] [INFO] [MainThread] [model.py:47] loadding model from ./krl_2TransE_saves/model.pkl
[2023-03-12 10:39:17] [INFO] [MainThread] [tool.py:30] loading dataset from data2/train.sample.csv
[2023-03-12 10:39:17] [INFO] [MainThread] [tool.py:32] successed loading dataset三、基于TransE模型的知识补全推理实验
在完成TransE模型的训练之后,我们可以进行过基于TransE模型的知识补全推理实验,其中包括根据头实体和关系预测尾实体、根据头实体和尾实体预测关系、根据关系和尾实体预测头实体以及验证给定三元组的成立性四种场景。
1、根据头实体和关系预测尾实体
根据头实体和关系预测尾实体思想在于,给定
a.算法实现
def predict_tail(self, head, rel, topk=3):
self._model.eval()
if head not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(head))
return None
if rel not in self._relation_vocab.stoi:
print('there is not relation named:{} in database!'.format(rel))
return None
head_id = torch.tensor([self._entity_vocab.stoi[head]] * self._model.entity_num).view((-1, 1)).to(DEVICE)
rel_id = torch.tensor([self._relation_vocab.stoi[rel]] * self._model.entity_num).view((-1, 1)).to(DEVICE)
candidate_tails = torch.arange(self._model.entity_num).view((-1, 1)).to(DEVICE)
head_scores = torch.exp(- self._model(head_id, rel_id, candidate_tails))
topk_scores, topk_index = torch.topk(head_scores, topk)
topk_scores = topk_scores.tolist()
topk_entities = [self._entity_vocab.itos[i] for i in topk_index]
return list(zip(topk_entities, topk_scores))b.实际效果
please given head entity:浙江大学
please given rel type:位于市
infer tails results: [('杭州市', 0.337802529335022), ('西湖区', 0.3094748556613922), ('浙江省', 0.30640822649002075), ('中国', 0.2227523773908615), ('北京市', 0.21652191877365112), ('南京市', 0.216506227850914), ('江苏省', 0.20090846717357635), ('合肥市', 0.19793014228343964), ('安徽省', 0.15178096294403076)]
************************************
please given head entity:北京市
please given rel type:包含区
infer tails results: [('海淀区', 0.5505775809288025), ('清华大学', 0.36967259645462036), ('北京大学', 0.3490602970123291), ('中国', 0.22732128202915192), ('鼓楼区', 0.2193053513765335), ('包河区', 0.21486233174800873), ('安徽省', 0.21285992860794067), ('西湖区', 0.2106468230485916)]
************************************
please given head entity:合肥市
please given rel type:位于省
infer tails results: [('安徽省', 0.42767229676246643), ('包河区', 0.2601960301399231), ('中科大', 0.251761257648468), ('浙江省', 0.24999287724494934), ('江苏省', 0.24325673282146454), ('北京市', 0.23182258009910583), ('', 0.2063301056623459), ('中国', 0.20469005405902863)]
************************************
please given head entity:鼓楼区
please given rel type:位于省
infer tails results: [('江苏省', 0.4168913662433624), ('南京市', 0.28137487173080444), ('南京大学', 0.26589757204055786), ('浙江省', 0.2564704418182373), ('安徽省', 0.22413446009159088), ('中国', 0.2185172140598297), ('海淀区', 0.2170836478471756), ('北京市', 0.1879209578037262)] 2)根据头实体和尾实体预测关系
根据头实体和尾实体预测关系思想在于,给定
a.算法实现
def predict_rel(self, head, tail, topk=3):
self._model.eval()
if head not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(head))
return None
if tail not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(tail))
return None
head_id = torch.tensor([self._entity_vocab.stoi[head]] * self._model.rel_num).view((-1, 1)).to(DEVICE)
tail_id = torch.tensor([self._entity_vocab.stoi[tail]] * self._model.rel_num).view((-1, 1)).to(DEVICE)
candidate_rels = torch.arange(self._model.rel_num).view((-1, 1)).to(DEVICE)
rel_scores = torch.exp(- self._model(head_id, candidate_rels, tail_id))
topk_scores, topk_index = torch.topk(rel_scores, topk)
topk_scores = topk_scores.tolist()
topk_rels = [self._relation_vocab.itos[i] for i in topk_index.tolist()]
return list(zip(topk_rels, topk_scores))b.实际效果
please given head entity:鼓楼区
please given tail tail:江苏省
infer reltyple results: [('位于省', 0.4168913662433624), ('包含单位', 0.2959556579589844), ('位于市', 0.2559424340724945), ('', 0.23076234757900238), ('临近省份', 0.21668316423892975)]
************************************
please given head entity:中科大
please given tail tail:浙江大学
infer reltyple results: [('位于市', 0.202473446726799), ('位于省', 0.18402916193008423), ('包含单位', 0.17473995685577393), ('位于国家', 0.16850699484348297))]
************************************
please given head entity:南京大学
please given tail tail:中国
infer reltyple results: [('位于国家', 0.31398749351501465), ('位于省', 0.24333298206329346), ('位于市', 0.23868469893932343),]
************************************
please given head entity:鼓楼区
please given tail tail:中国
infer reltyple results: [('位于国家', 0.28061357140541077), ('包含单位', 0.2268422693014145), ('位于省', 0.2185172140598297), ('位于市', 0.19347675144672394), ]
************************************
please given head entity:西湖区
please given tail tail:安徽省
infer reltyple results: [('位于省', 0.23189961910247803), ('临近省份', 0.18381954729557037), ('包含单位', 0.18333646655082703), ]
************************************ 3)根据关系和尾实体预测头实体
根据关系和尾实体预测头实体思想在于,给定,要求求其中的h,这时候,可以将所有的关系作为候选头实体h,根据模型公式||h+r-t||,求其距离,并经归一化后将其作为预测的概率。可以根据概率的大小进行排序,得到预测结果。
a.算法实现
def predict_head(self, rel: str, tail: str, topk=3):
self._model.eval()
if rel not in self._relation_vocab.stoi:
print('there is not relation named:{} in database!'.format(rel))
return None
if tail not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(tail))
return None
rel_id = torch.tensor([self._relation_vocab.stoi[rel]] * self._model.entity_num).view((-1, 1)).to(DEVICE)
tail_id = torch.tensor([self._entity_vocab.stoi[tail]] * self._model.entity_num).view((-1, 1)).to(DEVICE)
candidate_heads = torch.arange(self._model.entity_num).view((-1, 1)).to(DEVICE)
head_scores = torch.exp(- self._model(candidate_heads, rel_id, tail_id))
topk_scores, topk_index = torch.topk(head_scores, topk)
topk_scores = topk_scores.tolist()
topk_entities = [self._entity_vocab.itos[i] for i in topk_index]
return list(zip(topk_entities, topk_scores))b.实际效果
please given tail entity:杭州市
please given rel type:位于市
infer heads results: [('浙江大学', 0.337802529335022), ('西湖区', 0.3305158317089081), ('浙江省', 0.24935834109783173), ('南京大学', 0.23898373544216156), ('中科大', 0.2234327495098114), ('北京大学', 0.21060407161712646), ('清华大学', 0.20760872960090637), ('', 0.19473561644554138), ('鼓楼区', 0.1927061676979065)]
************************************
please given tail entity:海淀区
please given rel type:包含区
infer heads results: [('北京市', 0.5505775809288025), ('北京大学', 0.38351476192474365), ('清华大学', 0.36997684836387634), ('中国', 0.25594568252563477), ('合肥市', 0.253858357667923), ('杭州市', 0.2449134886264801), ('江苏省', 0.2319747656583786), ('南京市', 0.23006437718868256), ('浙江省', 0.22964642941951752)]
************************************
please given tail entity:中国
please given rel type:位于国家
infer heads results: [('江苏省', 0.4878770411014557), ('浙江省', 0.47457343339920044), ('北京市', 0.38223934173583984), ('浙江大学', 0.3821854889392853), ('南京市', 0.3662233352661133), ('北京大学', 0.34556764364242554), ('安徽省', 0.33287811279296875), ('杭州市', 0.32895809412002563), ('南京大学', 0.31398749351501465)]
************************************
please given tail entity:浙江省
please given rel type:位于省
infer heads results: [('杭州市', 0.6059702634811401), ('浙江大学', 0.6012405753135681), ('西湖区', 0.5815775394439697), ('南京市', 0.28694549202919006), ('南京大学', 0.2781519889831543), ('中国', 0.2696285843849182), ('鼓楼区', 0.2564704418182373), ('合肥市', 0.24999287724494934), ('中科大', 0.24369628727436066)]
************************************
please given tail entity:江苏省
please given rel type:临近省份
infer heads results: [('浙江省', 0.5878790020942688), ('浙江大学', 0.32541632652282715), ('杭州市', 0.30989789962768555), ('西湖区', 0.28610822558403015), ('中国', 0.2844085097312927), ('南京市', 0.2596832811832428), ('安徽省', 0.2467907965183258), ('北京市', 0.23456719517707825), ('南京大学', 0.23364374041557312)]
************************************ 4)验证给定三元组的成立性
验证给定三元组的成立性,给定
a.算法实现
def predict(self, head: str, rel: str, tail:str):
self._model.eval()
if head not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(head))
return None
if rel not in self._relation_vocab.stoi:
print('there is not relation named:{} in database!'.format(rel))
return None
if tail not in self._entity_vocab.stoi:
print('there is not entity named:{} in database!'.format(tail))
return None
head_id = torch.tensor([self._entity_vocab.stoi[head]]).view((-1, 1)).to(DEVICE)
rel_id = torch.tensor([self._relation_vocab.stoi[rel]]).view((-1, 1)).to(DEVICE)
tail_id = torch.tensor([self._entity_vocab.stoi[tail]]).view((-1, 1)).to(DEVICE)
score = torch.exp(- self._model(head_id, rel_id, tail_id))[0].item()
return scoreb.实际效果
please given head entity:海淀区
please given rel type:位于省
please given tail tail:江苏省
truth probablity results: 0.20812608301639557
************************************
please given head entity:海淀区
please given rel type:位于国家
please given tail tail:中国
truth probablity results: 0.28417718410491943
************************************
please given head entity:中科大
please given rel type:位于国家
please given tail tail:中国
truth probablity results: 0.2529098093509674
************************************
please given head entity:杭州市
please given rel type:位于省
please given tail tail:北京市
truth probablity results: 0.22008921205997467
************************************
please given head entity:杭州市
please given rel type:位于省
please given tail tail:安徽省
truth probablity results: 0.22788943350315094总结
本文为了进一步从理论和实践的角度出发,完成一次知识推理的模型训练和推理小任务,增进大家对知识推理的了解,主要从知识推理的三个主流方法与基础任务、基于TransE模型的知识推理的训练、基于TransE模型的知识补全推理实验三个方面进行了介绍。
本文充分参考了参考文献中的几个开源的项目,在此表示感谢。
参考文献
1、华为云社区:Cheri Chen,https://bbs.huaweicloud.com/blogs/286074
2、https://github.com/amorsun/kg-course
3、https://github.com/smilelight/lightKG
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。