操作系统进程2---进程成员以及fork
在上一次我们认识了什么是进程以及进程在操作系统中是如何被管理的。今天我们来认识一下pcb中的成员
Linux中我们可以使用ps命令中的ajx选项来输出当前系统中所有的进程

而我们就先从pid和ppid来入手。
文章目录
- 1.进程中的pid和ppid
- 2.父进程与子进程的简单认识
- 3.系统调用函数
-
- 1). getpid,getppid
- 2). fork
-
- a. fork简单认识
- b. fork的用法
- c. fork的原理
1.进程中的pid和ppid
进程pcb中有两个成员,一个是pid,一个是ppid,pid是指该进程在操作系统中的id,ppid是指他的父进程的id。
大致如下:
struct pcb{
pid_t pid;
pid_t ppid;
//各种属性
};
这个pit_t是一个整型类型。
2.父进程与子进程的简单认识
操作系统中的父子进程,首先子进程中会有ppid来记录他的父进程id。而且子进程会将父进程的一些成员变量赋值给自己。
当我们编译好一个可执行程序执行他以后,我们会在进程中看到他。
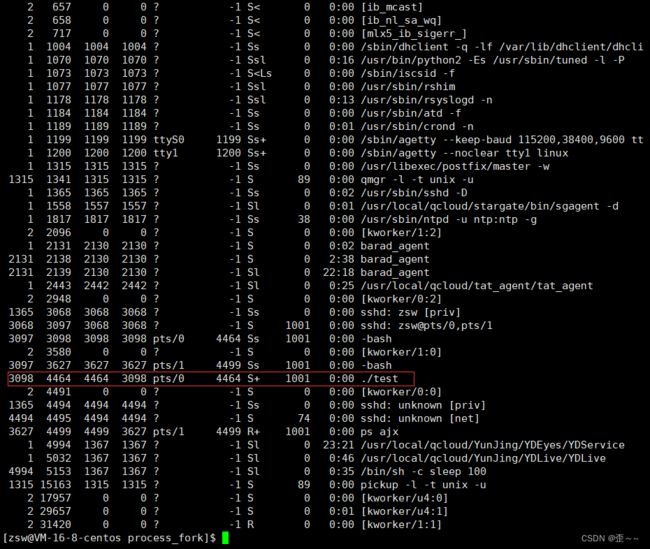
让我们来多次重复运行这个程序。
![]()
![]()
我们发现,这个程序的pid一直在变化,但是ppid没变,说明他的父进程一直是同一个,我们现在找到这个进程。
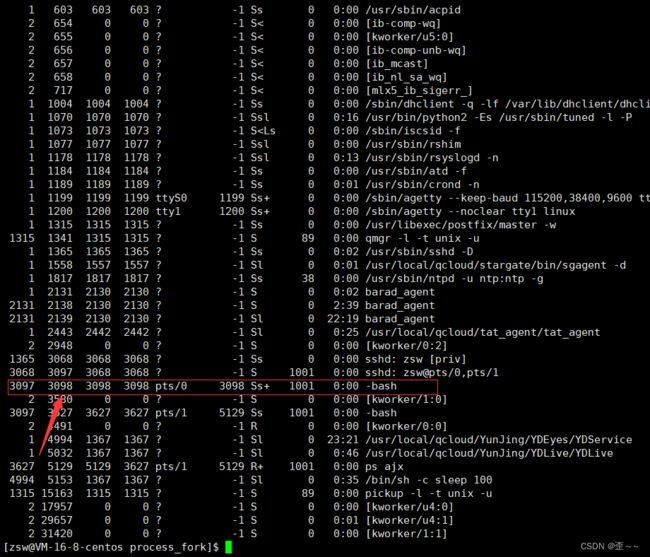
发现他是-bash,也就是我们的命令行解释器。从命令行运行的程进程都是bash的子进程
那我们除ps命令外,还有什么方法可以查看系统中的进程呢?
在Linux系统中有一个proc文件夹,里面就存放着所有的进程文件夹,文件夹中记录着进程的各种数据。又因为进程是一直在变化的,那么这个proc文件夹中的内容也一直在变化.

我们运行自己的程序,看看这个文件的关于我们的程序里面有什么。

这里面我们需要知道几个内容
一个是exe,它能让进程知道可执行程序在哪里(磁盘中)存储
一个是是cwd,它记录了程序的当前目录。
当前目录:我们写C语言进行文件io的时候,有过绝对路径和当前工作目录的概念,所以当前工作目录是我们不填写绝对路径时,默认创建文件的地方。这里一般是和自己的可执行程序在一个目录下。
还有一个命令,chdir,它可以修改当前工作目录
3.系统调用函数
Linux系统给了三个系统调用函数,getpid和getppid和fork。
1). getpid,getppid
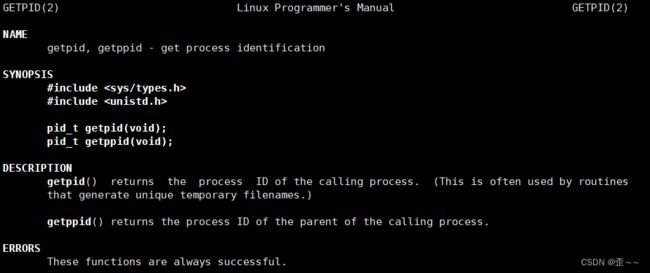
他说这个函数调用不会失败也给了相应的头文件。现在我们来试试这两个函数。
int main()
{
pid_t pid = getpid();
pid_t ppid = getppid();
printf("我是一个进程,我的id是:%d,我的父进程的id是:%d\n", pid, ppid);
return 0;
}

2). fork
a. fork简单认识
Linux中创建进程可以从命令行创建,也可以通过代码来创建进程。这就是第三个要知道的系统调用接口,fork。
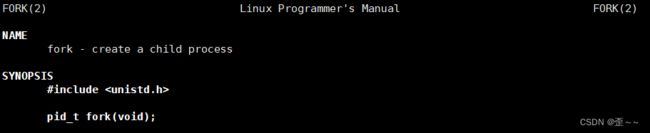
他会在执行到他之后,创建一个关于这个可执行程序形成的进程的子进程。并且这个子进程的pcb里有一些属性是直接拷贝的父进程的。
他会返回两个值。返回给父进程子进程的id,返回给子进程0,如果创建进程失败,则会返回小于0的数。
我们来演示一下:
int main()
{
printf("我是一个进程我的id是:%d\n", getpid());
fork();
printf("hello world\n");
return 0;
}
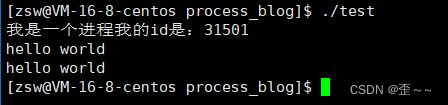
我们会看到一个现象,第一句程序执行了一遍,第三句竟然执行了两遍,这是一个没有见过的情况。
我们对代码稍加改造:
int main()
{
printf("我是一个进程我的id是:%d\n", getpid());
fork();
printf("hello world,我的id是:%d, 我的父id是:%d\n", getpid(), getppid());
return 0;
}

这个3078进程是bash,我们也知道fork会创建新的进程,那么现在知道这个新的进程是当前程序的子进程。fork函数执行之后创建好的子进程会和父进程一起执行之后的程序(这个由cpu中寄存器的eip实现,eip是用来记录将要执行的代码的地址的),而fork之前只由父进程执行
我们发现fork还有返回值,让我们稍加改造上面的代码,看看这个返回值。
#include 
我们发现同一个变量竟然会出现不一样的结果,那么显然是fork竟然有两个返回值,给父进程返回子进程的pid,给子进程返回0,这显然是不符合我们之前的认知的。还有就是fork失败后会返回小于0的数。这是为什么我们之后再谈,我们先来谈谈,它的返回值能干什么?
b. fork的用法
我们知道fork可以用代码创建进程,而且是他当前进程的子进程,对于两个进程有着不同的返回值。我们创建子进程的目的一定是因为单个进程无法完成任务,所以我们需要两个进程来完成我们所需要的任务。比如边下载边播放,那如何保证每个进程都做着正确的自己的事呢?别忘了我们可是有两个返回值的。我们用代码来演示一下:
#include 
c. fork的原理
我们认识fork之后肯定有一个非常大的疑惑,那就是一个函数有两个返回值。接下来我们来详细说明一下fork背后的原理。
fork干了什么?
我们知道一个程序被运行,是程序先被加载到内存中然后操作系统生成对应的pcb结构体然后再把这个结构体链入到运行队列中。那假如代码中有fork,那他就会再创建一个进程。那就意味着操作系统会再生成一个pcb结构体,再把他链入到运行队列中。那么就会有两个pcb指向同一个代码段,我们也知道,进程 = 代码 + 进程pcb,而代码又包含代码段和运行代码时产生的数据,所以说倒不如详细一点:进程 = 代码段 + 代码数据 + 进程pcb。对于两个进程他们的代码可能相同但是他们产生的代码数据不一定相同,所以当我们用fork创建好子进程后,生成的代码数据肯定是父进程一份,子进程一份,而这里操作系统采用的方法是写时拷贝,具体什么是写时拷贝,有兴趣可以看一下我的另一篇博客:用了写时拷贝的思想。
那为什么fork会返回给父进程子进程的pid呢?
这是因为父子关系是一对多的关系。父进程需要知道每个子进程的存在,而子进程只需要知道自己和父进程就可以。
fork为什么会返回两个值?
现在我们再来研究一个普通的函数:当一个函数执行到return的时候意味着什么?意味着这个函数已经把他该做的任务已经完成了,接下来只需要返回关于他所产生一个数据就可以。那么对于fork这个系统调用接口来说也是一样,他也是一个函数,当他执行到return的时候,说明他创建子进程的任务已经完成了,fork之后,代码共享。那就说明从return开始父子进程就开始一起执行代码了。这就是为什么return会有不同的返回值了。
为什么一个变量会存储两个不同的值呢?
肯定有人会说因为代码执行了两次,那变量名是一样的,执行之后代码要使用接收返回值的变量的时候,操作系统怎么就知道它使用的是谁返回呢?那我们再看看这个变量的地址:
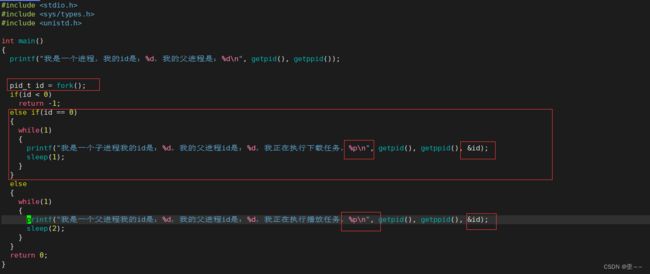

他的地址竟然是一样的!!!
关于这个问题我们日后再讨论。