CADD分子对接-机器学习代谢组学-AIDD人工智能药物发现与设计
CADD(Computer Aided Drug Design):计算机辅助药物设计,依据生物化学、酶学、分子生物学以及遗传学等生命科学的研究成果,针对这些基础研究中所揭示的包括酶、受体、离子通道及核酸等潜在的药物设计靶点,并参考其它类源性配体或天然产物的化学结构特征,以计算机化学为基础,通过计算机的模拟、计算和预算药物与受体生物大分子之间的相互作用,考察药物与靶点的结构互补、性质互补等,设计出合理的药物分子。它是设计和优化先导化合物的方法,CADD的应用,包括基于结构的药物设计(SBDD)、基于配体的药物设计(LBDD)、高通量虚拟筛选(HTVS)等技术,突破了传统的先导物发现模式,极大地促进了先导化合物发现和优化。特别是在食品、生物、化学、医药、植物、疾病方面应用广泛!靶点的发现与确证是现代新药研发的第一步,也是新药创制过程中的瓶颈之一。CADD的应用可以加快靶点发现的速度,提高靶点发现的准确度,从而推进新药研发。
AIDD(AI Drug Discovery & Design):是近年来非常火热的技术应用,且已经介入到新药设计到研发的大部分环节当中,为新药发现与开发带来了极大的助力。随着医药大数据的积累和人工智能技术的发展,运用AI技术并结合大数据的精准药物设计也不断推动着创新药物的发展。在新型冠状病毒的治疗方案中,通过一系列计算机辅助药物生物计算的方法发现一大类药物分子可以有效阻止新冠病毒的侵染,为治疗新冠提供了新思路。倾向于机器对数据库信息的自我学习,可以对数据进行提取和学习,一定程度上避免了化合物设计过程中的试错路径,同时还会带来很多全新的结构,为药物发现打破常规的结构壁垒。
代谢组学是对某一生物或细胞在一特定生理时期内所有代谢产物同时进行定性定量分析的学科,被广泛用于揭示小分子与生理病理效应间的关系。目前,代谢组学已经被应用于药物开发的各个阶段(如药物靶标识别、先导化合物发现、药物代谢分析、药物响应和耐药研究等)。基于代谢组学的高性价比特性,它被药学领域的研究者给予了厚望,有望加速新药开发的进程。然而,代谢组领域还面临着严重的信号处理与数据分析问题,对其在新药研发中的应用构成了巨大挑战。为了有效消除由环境、仪器和生物因素所引入的不良信号波动,就需要开发针对代谢组信号系统优化的新方法,为不同组学研究量身定制最优的数据分析策略。
一:CADD计算机辅助药物设计
第一天上午
背景与理论知识以及工具准备
1.PDB数据库的介绍和使用
1.1数据库简介
1.2靶点蛋白的结构查询与选取
1.3靶点蛋白的结构序列下载
1.4靶点蛋白的下载与预处理
1.5批量下载蛋白晶体结构
2.Pymol的介绍与使用
2.1软件基本操作及基本知识介绍
2.2蛋白质-配体相互作用图解
2.3蛋白-配体小分子表面图、静电势表示
2.4蛋白-配体结构叠加与比对
2.5绘制相互作用力
3.notepad的介绍和使用
3.1 优势及主要功能介绍
3.2 界面和基本操作介绍
3.3插件安装使用
下午
一般的蛋白-配体分子对接讲解
1.对接的相关理论介绍
1.1分子对接的概念及基本原理
1.2分子对接的基本方法
1.3分子对接的常用软件
1.4分子对接的一般流程
2.常规的蛋白-配体对接
2.1收集受体与配体分子
2.2复合体预构象的处理
2.3准备受体、配体分子
2.4蛋白-配体对接
2.5对接结果的分析
以新冠病毒蛋白主蛋白酶靶点及相关抑制剂为例
第二天
虚拟筛选
1.小分子数据库的介绍与下载
2.相关程序的介绍
2.1 openbabel的介绍和使用
2.2 chemdraw的介绍与使用
3.虚拟筛选的前处理
4.虚拟筛选的流程及实战演示
案例:筛选新冠病毒主蛋白酶抑制剂
5.结果分析与作图
6.药物ADME预测
6.1ADME概念介绍
6.2预测相关网站及软件介绍
6.3预测结果的分析
第三天
拓展对接的使用方法
1.蛋白-蛋白对接
1.1蛋白-蛋白对接的应用场景
1.2相关程序的介绍
1.3目标蛋白的收集以及预处理
1.4使用算例进行运算
1.5关键残基的预设
1.6结果的获取与文件类型
1.7结果的分析
以目前火热的靶点PD-1/PD-L1等为例。
2.涉及金属酶蛋白的对接
2.1 金属酶蛋白-配体的背景介绍
2.2蛋白与配体分子的收集与预处理
2.3金属离子的处理
2.4金属辅酶蛋白-配体的对接
2.5结果分析
以人类法尼基转移酶及其抑制剂为例
3.蛋白-多糖分子对接
4.1蛋白-多糖相互作用
4.2对接处理的要点
4.3蛋白-多糖分子对接的流程
4.4蛋白-多糖分子对接
4.5相关结果分析
以α-糖苷转移酶和多糖分子对接为例
5.核酸-小分子对接
5.1核酸-小分子的应用现状
5.2相关的程序介绍
5.3核酸-小分子的结合种类
5.4核酸-小分子对接
5.5相关结果的分析
以人端粒g -四链和配体分子对接为例。
操作流程介绍及实战演示
第四天
拓展对接的使用方法
1.柔性对接
1.1柔性对接的使用场景介绍
1.2柔性对接的优势
1.3蛋白-配体的柔性对接
重点:柔性残基的设置方法
1.4相关结果的分析
以周期蛋白依赖性激酶2(CDK2)与配体1CK为例
2.共价对接
2.1两种共价对接方法的介绍
2.1.1柔性侧链法
2.1.2两点吸引子法
2.2蛋白和配体的收集以及预处理
2.3共价药物分子与靶蛋白的共价对接
2.4结果的对比
以目前火热的新冠共价药物为例。
3.蛋白-水合对接
3.1水合作用在蛋白-配体相互作用中的意义及方法介绍
3.2蛋白和配体的收集以及预处理
3.3对接相关参数的准备
重点:水分子的加入和处理
3.4蛋白-水分子-配体对接
3.5结果分析
以乙酰胆碱结合蛋白(AChBP)与尼古丁复合物为例
第五天
分子动力学模拟(linux与gromacs使用安装)
1. linux系统的介绍和简单使用
1.1 linux常用命令行
1.2 linux上的常用程序安装
1.3 体验:如何在linux上进行虚拟筛选
2.分子动力学的理论介绍
2.1分子动力学模拟的原理
2.2分子动力学模拟的方法及相关程序
2.3相关力场的介绍
3.gromacs使用及介绍
重点:主要命令及参数的介绍
4.origin介绍及使用
第六天
溶剂化分子动力学模拟的执行
1.一般的溶剂化蛋白的处理流程
2.蛋白晶体的准备
3.结构的能量最小化
4.对体系的预平衡
5.无限制的分子动力学模拟
6.分子动力学结果展示与解读
以水中的溶菌酶为例
第七天
蛋白-配体分子动力学模拟的执行
1.蛋白-配体在分子动力学模拟的处理流程
2.蛋白晶体的准备
3.蛋白-配体模拟初始构象的准备
4.配体分子力场拓扑文件的准备
4.1 高斯的简要介绍
4.2 ambertool的简要介绍
4.3生成小分子的力场参数文件
5.对复合物体系温度和压力分别限制的预平衡
6.无限制的分子动力学模拟
7.分子动力学结果展示与解读
8.轨迹后处理及分析
以新冠病毒蛋白主蛋白酶靶点及相关抑制剂为例
部分模型案例图片
二:AIDD人工智能药物发现与设计
(第一天)
人工智能药物发现(AIDD)简介
机器学习和深度学习在药物发现领域的应用
工具的介绍与安装
1.人工智能药物发现(AIDD)简介2.机器学习和深度学习在药物发现领域的应用
1.2 环境搭建
python
anaconda
工具包
RDKit
scikit-learn
pandas
numpy
(第二天)
机器学习
机器学习药物发现
2.1 机器学习
2.1.1 随机森林Random Forest (RF)
2.1.2 支持向量机Support Vector Machines (SVMs)
2.1.3卷积神经网络
Ø 梯度下降
Ø 反向传播
Ø 随机梯度下降
Ø 学习率和激活函数
Ø 卷积神经网络CNN
Ø 常用框架介绍
Ø Pytorch
Ø TensorFlow
2.1.4机器学习任务
Ø 分类任务:classification
Ø 回归任务:regression
Ø 聚类任务:clustering
2.1.5机器学习验证和评估指标
Ø 验证:K折交叉验证K-fold cross validation
Ø 性能评估指标:
Ø Sensitivity
Ø Specificity
Ø Accuracy
Ø ROC-curve
Ø AUC
2.2 ChEMBL数据库介绍和使用
Ø compound activity measures
ØIC50
ØpIC50

2.3 化合物的编码方式及化学相似性
2.3.1 化合物编码方式
Ø SMILES
Ø InChI
Ø Chebi
Ø 分子指纹
Ø MACCS:Molecular ACCess System fingerprints (MACCS Keys)
Ø Morgan Fingerprints:Extended-Connectivity Fingerprints (ECFPs)
2.3.2 化合物的化学相似性
Ø Tanimoto 系数
Ø Dice 系数
2.4 项目实战
2.4.1 Classification:基于分子指纹的化合物活性预测

2.4.2 Clustering:基于Butina算法的分子聚类方法研究

(第三天)
图神经网络与药物发现
3.1 图神经网络
Ø 图卷积网络 GCN
Ø 图注意力网络 GAN
Ø 图同构网络 GIN
Ø 常用框架介绍
Ø Pytorch_Geometric
Ø DGL
3.2 分子毒性简介与相关数据集介绍
Ø Tox21
Ø ToxCast
Ø ClinTox
3.3 项目实战:基于图神经网络的分子毒性预测
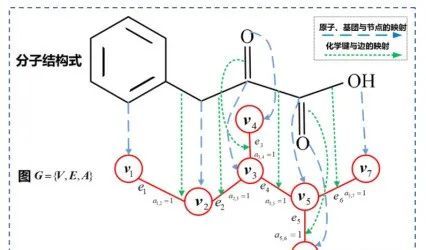
3.4 经典论文讲解:DeepTox: Toxicity Prediction using Deep Learning

(第四天)
(第四天)
自然语言处理与药物发现
4.1 自然语言处理
Ø 循环神经网络 RNN
Ø LSTM
Ø Seq2seq
Ø Transformer
Ø 常用框架介绍:
Ø Pytorch
Ø TensorFlow
4.2 有机反应产量简介及相关数据集
4.2.1 有机反应的表示方法
4.2.2 有机反应的产量
4.2.3 有机反应相关数据集 USPTO
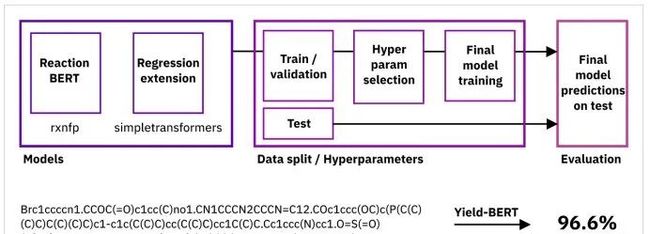
4.3 项目实战:基于Transformer的有机化学反应产量预测
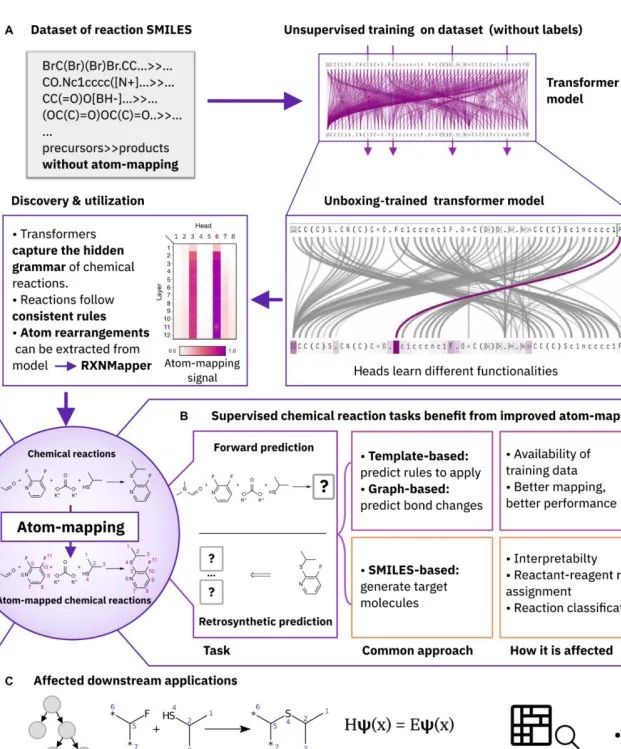
4.4 经典论文解读:Extraction of organic chemistry grammar from unsupervised learning of chemical reactions
(第五天)
生化代谢路径设计与药物发现
5.1 生化数据集介绍与使用
Ø KEGG
Ø BiGG
Ø BioCyc
Ø PubChem
Ø Chebi
5.2 搜索方法
Ø 基于化学计量矩阵的搜索方法
Ø 基于逆合成的搜索方法
Ø 基于图结构的搜索方法
Ø 基于进化算法的搜索方法
5.3 评估方法
Ø 通量平衡分析FBA
Ø 理论产量计算
Ø 热力学可行性分析
5.4 项目实战:基于逆合成的生物代谢路

5.5 经典论文讲解:Predicting Organic Reaction Outcomes with Weisfeiler-Lehman Network

免费视频:深度学习AiphaFold2蛋白质结构预测实例讲
蛋白质结构与功能的概述。
蛋白质的组成
蛋白质的结构
蛋白质的功能
常见蛋白质结构预测的网站及方法。
常用蛋白质结构预测的相关网站及软件
常用网站及软件的使用方法及说明
机器学习在蛋白质结构预测的应用。
蛋白质结构与小分子药物库获取
机器学习加速预测小分子药物
AlphaFold2机器学习模型对蛋白结构预测
实战蛋白结构预测目前最好的人工智能模型AlphaFold2。
AlphaFold2模型的获取及安装
AlphaFold2相关数据的获取
AlphaFold2模型的实战操作
三:机器学习与代谢组学专题课表内容
第一天
A1 代谢物及代谢组学的发展与应用
(1) 代谢生理功能;
(2) 代谢疾病;
(3) 非靶向与靶向代谢组学;
(4) 空间代谢组学与质谱成像(MSI);
(5) 代谢流与机制研究;
(6) 代谢组学与药物和生物标志物。
A2 代谢组学实验流程简介
A3 色谱、质谱硬件原理
(1) 色谱分析原理;
(2) 色谱的气相、液相和固相;
(3) 色谱仪和色谱柱的选择;
(4) 质谱分析原理及动画演示;
(5) 正、负离子电离模式;
(6) 色谱质谱联用技术;
(7) LC-MS 的液相系统
A4 代谢通路及代谢数据库
(1) 几种经典代谢通路简介;
(2) 能量代谢通路;
(3) 三大常见代谢物库:HMDB、METLIN 和 KEGG;
(4) 代谢组学原始数据库:Metabolomics Workbench 和Metabolights.
第二天
(3) 样本及代谢物的运输与保存问题;
B2 LC-MS 数据质控与搜库
(1) LC-MS 实验过程中 QC 样本的设置方法;
(2) LC-MS 上机过程的数据质控监测和分析;
(3) XCMS 软件数据转换与提峰;
B3 R 软件基础
(1) R 和 Rstudio 的安装;
(2) Rstudio 的界面配置;
(3) R 的基本数据结构和语法;
(4) 下载与加载包;
(5) 函数调用和 debug;
B4 ggplot2
(1) 安装并使用 ggplot2
(2) ggplot2 的画图哲学;
(3) ggplot2 的配色系统;
(4) ggplot2 画组合图和火山图;
第三天
机器学习
C1 无监督式机器学习在代谢组学数据处理中的应用
(1) 大数据处理中的降维;
(2) PCA 分析作图;
(3) 三种常见的聚类分析:K-means、层次分析与 SOM
(4) 热图和 hcluster 图的 R 语言实现;
C2 一组代谢组学数据的降维与聚类分析的 R 演练
(1) 数据解析;
(2) 演练与操作;
C3 有监督式机器学习在代谢组学数据处理中的应用
(1) 数据用 PCA 降维处理后仍然无法找到差异怎么办?
(2) PLS-DA 找出最可能影响差异的代谢物;
(3) VIP score 和 coef 的意义及选择;
(4) 分类算法:支持向量机,随机森林
C4 一组代谢组学数据的分类算法实现的 R 演练
(1) 数据解读;
(2) 演练与操作;
第四天
D1 代谢组学数据清洗与 R 语言进阶
(1) 代谢组学中的 t、fold-change 和响应值;
(2) 数据清洗流程;
(3) R 语言 tidyverse
(4) R 语言正则表达式;
(5) 代谢组学数据过滤;
(6) 代谢组学数据 Scaling 原理与 R 实现;
(7) 代谢组学数据的 Normalization;
(8) 代谢组学数据清洗演练;
D2 在线代谢组分析网页 Metaboanalyst 操作
(1) 用 R 将数据清洗成网页需要的格式;
(2) 独立组、配对组和多组的数据格式问题;
(3) Metaboanalyst 的 pipeline 和注意事项;
(4) Metaboanalyst 的结果查看和导出;
(5) Metaboanalyst 的数据编辑;
(6) 全流程演练与操作
第五天
E1 机器学习与代谢组学顶刊解读(2-3 篇);
(1) Nature Communication 一篇代谢组学小鼠脑组织样本 database 类型的文献;
(2) Cell 一篇代谢组学患者血液样本的机器学习与疾病判断的文献;
(3) 1-2 篇代谢组学与转录组学和蛋白组学结合的文献。
E2 文献数据分析部分复现(1 篇)
(1) 文献深度解读;
(2) 实操:从原始数据下载到图片复现;
(3) 学员实操。
|
|
|
|
|
|