C指针 --- 初阶
目录
1. 指针是什么
2. 指针和指针类型
1. 指针 +- 整数
2. 不同指针类型的解引用
3. 野指针
3.1. 野指针的形成原因:
1. 指针未初始化
2. 已释放的指针
3. 悬挂指针
3.2. 如何规避野指针
4. 指针运算
4.1. 指针 +- 整数
4.2. 指针 - 指针
4.3. 指针的关系运算
5. 指针和数组
6. 二级指针
7. 指针数组
1. 指针是什么
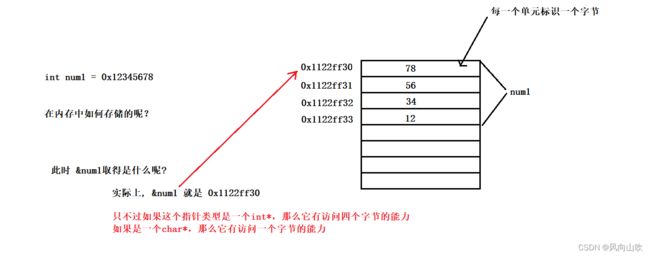
每个内存都有唯一的一个编号,这个编号也被称之为地址,也就是我们的指针。
指针是一个变量,它的值为另一个变量的内存地址(内存的编号)。它允许通过内存地址直接访问和修改变量的值。
可以将指针视为一个包含内存地址的容器,通过该内存地址可以找到存储在计算机内存中的数据。

一个小的单元一个字节。对于32位机器,假设有32根地址线,那么每根地址线在寻址的时候产生一个电信号正电/负电(1或者0),那么总共就会有2^32个地址,每个地址表示唯一的一个字节。我们知道,2^10 = 1024,那么2^30 = 1024 * 1024 * 1024 = 1GB,也就是说,2^32 个字节 = 4GB。
因此我们可以明白,在32位系统下,一个指针需要32个bit位,也就是4个字节。而在64位系统下,一个指针需要64个bit位,即8个字节。
void Test1(void)
{
// 在内存中开辟一块空间给i这个整形
int i = 10;
// &a 可以取出a的地址, 其类型是 int*
// 定义一个指针变量p,将i的地址赋值给p
int* p = &i;
}
总结:
指针 == 地址 == 内存的唯一编号
指针(这里特指指针变量),用来存放地址的,地址是一块空间的唯一标识。指针的大小在32位平台是4个字节,在64位平台是8个字节。注意:我们平常口语中说的指针,通常是一个指针变量
2. 指针和指针类型
通过上面我们已经知道,指针本质是一块空间的唯一标识,是一个编号。那么指针类型又是什么呢?指针类型可以决定什么呢?
简单来讲,指针类型,就是你指向的数据的类型 + *。例如:
void Test2(void)
{
int i = 10;
int* i_ptr = &i;
double d = 1.1;
double* d_ptr = &d;
char ch = 'a';
char* c_ptr = &ch;
}i_ptr指向的数据的类型是一个int,那么它的指针类型就是一个int*
同理,d_ptr指向的数据的类型是一个double,那么指针类型就是double*
同理,c_ptr指向的数据的类型是一个char,那么指针类型就是char*
那么指针类型有什么用呢?请看下面的例子:
1. 指针 +- 整数
void Test3(void)
{
int i = 10;
char ch = 'x';
int* i_ptr = &i;
char* c_ptr = &ch;
printf("original address:> %p\n", i_ptr);
printf("changed address:> %p\n", i_ptr + 1);
printf("original address:> %p\n", c_ptr);
printf("changed address:> %p\n", c_ptr + 1);
}结果如下:
original address:> 0095FCD4
changed address:> 0095FCD8
original address:> 0095FCCB
changed address:> 0095FCCC通过结果,我们可以看到,指针的类型决定了 指针 + 一个整数向前或者向后移动多远。
具体,如果是一个int*,那么指针 + 1相当于,向后走了4个字节,那如果是type*,那么指针+n 相当于跳过了 n*sizeof(type)个字节。
2. 不同指针类型的解引用
void Test4(void)
{
int num1 = 0x12345678; // 0x开头的是一个 十六进制数
char* c_ptr = (char*)&num1;
*c_ptr = 0;
int num2 = 0x12345678;
int* i_ptr = &num2;
*i_ptr = 0;
}
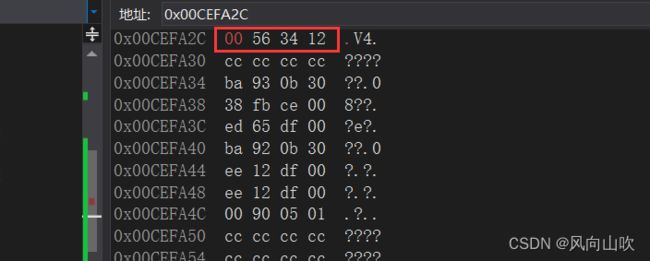
上面的代码不同之处在于,第一个是一个char*的指针指向一个int,并通过解引用将其置为0,第二个是一个int*的指着指向一个int,也通过解引用将其置为0,那它们有什么不一样吗?
我们看num1在内存中的变化情况:
初始态:

置为0后:
我们观察num2在内存的变化情况:
初始态:

置为0后:
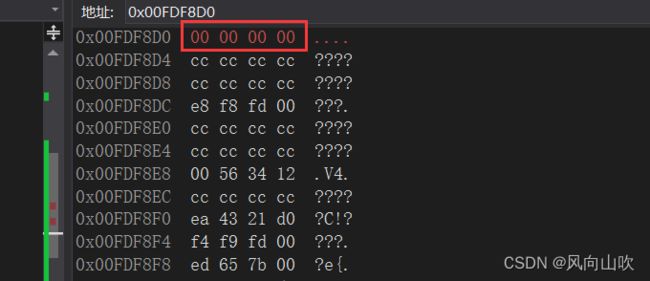
通过对比,我们可以得出指针类型的另一个作用:指针类型决定了对指针进行解引用是能访问几个字节(指针的权限)。例如上面,如果你是一个int*,那么你就能访问四个字节。如果你是一个char*,那么你只能访问一个字节。
也就是从 type* ptr ,我们可以得出,ptr是一个指针变量,p指向的对象的类型是type,p解引用的时候访问的对象的的大小是 sizeof(type);
3. 野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)指针变量在定义时如果未初始化,其值是随机的,指针变量的值是别的变量的地址,意味着指针指向了一个地址是不确定的变量,此时去解引用就是去访问了一个不确定的地址,其行为是未定义的。
3.1. 野指针的形成原因:
1. 指针未初始化
未初始化指针:当一个指针被声明但未被初始化时,它可能包含一个无效的内存地址。这样的指针是不安全的,使用时可能导致程序出错,例如,下面的情况:
void Test5(void)
{
int* ptr;
*ptr = 20; // 这个指针是一个野指针,对其解引用,其行为未定义
}
2. 已释放的指针
已释放的指针:当一个指针指向的内存被释放或销毁后,该指针就变成了野指针。在使用已释放的指针时,会访问到无效的内存地址,可能导致程序崩溃或产生不可预料的错误。
void Test6(void)
{
int* ptr = new int;
delete ptr; // 释放了该指针,那么此时这个指针就是一个野指针
std::cout << *ptr << std::endl; // 非法访问,进程crash
}3. 悬挂指针
悬挂指针:在某些情况下,指针可能指向了被销毁或超出作用域的对象。这样的指针也称为悬挂指针,使用悬挂指针可能导致未定义的行为
void Test7(void)
{
int arr[5] = { 0 };
int* ptr = arr;
for (int i = 0; i < 6; ++i)
{
// 当i等于5时,此时ptr就是一个野指针
*(ptr++) = i;
}
}
3.2. 如何规避野指针
1. 指针初始化
如果知道指针应该初始化为谁的地址,就直接初始化。不知道指针初始化为什么的地址,初始化为NULL
void Test9(void)
{
int i = 10;
// 如果知道初始化为谁的地址,就直接初始化
int* ptr1 = &i;
// 如果不知道,就初始化为NULL
// 注意: 在C中 NULL ---> ((void*)0)
// 在C++中, NULL ---> 0
// ptr2是一个空指针,没有指向任何有效的空间,这个指针不能直接使用
char* ptr2 = NULL;
}2. 防止指针越界
4. 指针运算
4.1. 指针 +- 整数
如前面所说,指针 +- 整数,需要看这个指针的类型是什么。其指针类型决定了 +- 的长度。例如:
void Test8(void)
{
int i = 10;
int* i_ptr = &i;
printf("%p 'int*:+1'---> %p\n", i_ptr, i_ptr + 1);
printf("%p 'int*:-1'---> %p\n", i_ptr, i_ptr - 1);
char ch = 'a';
char* c_ptr = &ch;
printf("%p 'char*:+1'---> %p\n", c_ptr, c_ptr + 1);
printf("%p 'char*:-1'---> %p\n", c_ptr, c_ptr - 1);
}结果:
00D6FA88 'int*:+1'---> 00D6FA8C
00D6FA88 'int*:-1'---> 00D6FA84
00D6FA73 'char*:+1'---> 00D6FA74
00D6FA73 'char*:-1'---> 00D6FA72总而言之,指针 +- 整数,需要看这个指针的类型是什么,如果是int*,+1,就会跳过四个字节,如果是char*, +1,就会跳过1个字节。
理解了上面,我们可以看看下面的例子:
void Test10(void)
{
int arr[10] = { 0 };
int* ptr = &arr[0]; // 数组的首地址
int* ptr1 = arr; // 数组名也是首元素的低地址
for (size_t i = 0; i < 10; ++i)
{
//arr[i] = i;
*(ptr + i) = i;
*(ptr1 + i) = i;
// 本质来说, 编译器对于arr[i]的处理
// 会将其转化为 *(arr + i) , arr 就是数组的首地址
}
// 我们知道 arr[i] 等价于 *(ptr + i)
// 而根据加法具有交换律 *(ptr + i) 也等价于 *(i + ptr)
// 那么 arr[i] 是不是也可以写成 i[arr]呢 ?
// 我们验证一下
for (size_t i = 0; i < 10; ++i)
{
std::cout << i[arr] << " ";
}
std::cout << std::endl;
}结果:0 1 2 3 4 5 6 7 8 9
在这里想说的是,对于[]而言,它只是一个操作符(下标引用操作符),而i 和 arr是这个操作符的两个操作数,因此 arr[i] 也可以写成 i[arr],但正常情况下我们不建议写成i[arr],还是写成arr[i]。
4.2. 指针 - 指针
void Test11(void)
{
int arr[10] = { 0 };
std::cout << &arr[9] - &arr[0] << std::endl;
std::cout << &arr[0] - &arr[9] << std::endl;
}结果:
9
-9
地址 - 地址得到的数据的绝对值 : 是指针和指针之间的元素个数。
指针 - 指针的前提条件: 这两个指针必须指向同一段空间的两个地址,否则,没有意义。
4.3. 指针的关系运算
void Test12(void)
{
int arr[5];
int *ptr;
// 从最后一个元素的下一个位置的地址开始,与第一个元素的地址比较
for (ptr = &arr[5]; ptr > &arr[0];)
{
*(--ptr) = 0;
}
// 从最后一个元素的地址开始,与第一个元素的地址比较
for (ptr = &arr[4]; ptr >= &arr[0]; --ptr)
{
*ptr = 0;
}
}
C标准规定允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证它可行。
5. 指针和数组
首先,指针不是数组,数组也不是指针。
指针变量就是指针变量,不是数组,指针变量的大小是4/8个字节。专门是用来存放地址的。
数组就是数组,不是指针。数组是一块连续的空间,可以存放一个或多个类型相同的数据。
它们的联系:
在数组中, 数组名是数组首元素的地址,可以理解为数组名是一个地址。当我们知道数组首元素的地址的时候,又因为数组是连续存放的,因此可以通过数组的首元素的地址来访问它的数据。
void Test13(void)
{
int arr[5] = { 1, 2, 3, 4, 5 };
// 数组名是数组首元素的地址,int类型的地址,是一个int*
// 因此 我们在这里用一个int* 接收
int* ptr = arr;
for (size_t i = 0; i < 5; ++i)
{
printf("&arr[%d] = %p <==> ptr+%d = %p\n", i, &arr[i], i, ptr + i);
}
}&arr[0] = 012FF8F4 <==> ptr+0 = 012FF8F4
&arr[1] = 012FF8F8 <==> ptr+1 = 012FF8F8
&arr[2] = 012FF8FC <==> ptr+2 = 012FF8FC
&arr[3] = 012FF900 <==> ptr+3 = 012FF900
&arr[4] = 012FF904 <==> ptr+4 = 012FF904通过结果,我们可以得知:ptr + i 就是这个数组下标为i的元素的地址。
通常讲,我们说一个数组的数组名就是首元素的地址。但注意有两种特殊情况:
void Test16(void)
{
int arr[5] = { 1, 2, 3, 4, 5 };
// 一般情况下,数组名代表着数组首元素的地址
// 但有两种特殊情况
// 第一: sizeof 数组名
// 注意 :sizeof 数组名 代表着数组的大小
std::cout << sizeof arr << std::endl;
for (size_t i = 0; i < 5; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
std::cout << " --------------- " << std::endl;
// 第二: &数组名
// 数组名 + 1 会跳过一个元素
// &数组名 + 1 会跳过整个数组大小,即跳过sizeof arr 个字节
printf("arr = %p\n", arr);
printf("arr + 1 = %p\n", arr + 1);
printf("&arr = %p\n", &arr);
printf("&arr + 1 = %p\n", &arr + 1);
}20
&arr[0] = 0024F864
&arr[1] = 0024F868
&arr[2] = 0024F86C
&arr[3] = 0024F870
&arr[4] = 0024F874
---------------
arr = 0024F864
arr + 1 = 0024F868
&arr = 0024F864
&arr + 1 = 0024F878
6. 二级指针
什么叫二级指针呢?简单的理解,一级指针变量的地址(指针)就是二级指针,即可以用二级指针变量存储一级指针变量的地址。

int** pp 的理解, 第二个*,我们可以理解为 pp是一个指针变量,int* 说明指针变量pp所指向空间中的存储的数据的类型是一个int*,因此,我们说pp是一个二级指针变量。
void Test14(void)
{
int a = 10;
// a的数据类型是一个int,那么&a的类型就是int*
// 因此在这里用 int* p 接收 &a
int* p = &a;
// p的数据类型是一个int*,那么&p的数据类型是int**
// 因此在这里用 int** pp 接受 &p
int** pp = &p;
}7. 指针数组
什么叫指针数组呢?指针数组是一个数组,其每一个元素是一个指针变量。

void Test15(void)
{
// 数组中的每一个元素类型为 int
int arr1[3] = { 1, 2, 3 };
int arr2[3] = { 2, 3, 4 };
int arr3[3] = { 3, 4, 5 };
// 数组中的每一个元素类型为 int*
// p_arr 就是一个指针数组,该数组的每一个元素都是一个int*
int* p_arr[3] = { arr1, arr2, arr3 };
for (size_t i = 0; i < 3; ++i)
{
for (size_t j = 0; j < 3; ++j)
{
std::cout << *(*(p_arr + i) + j) <<" ";
}
std::cout << "\n";
}
}