Hadoop学习笔记(3)-搭建Hadoop伪分布式
0.前言
搭建伪分布式要先搭建本地模式。请参照上一个博客:
http://blog.csdn.net/xummgg/article/details/51172933
参考资料(官网为主,网络资料为铺):
http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation
先确保本地模式配置正确后开始配置。
1.配置core-site.xml文件
配置hadoop目录下的etc/Hadoop/core-site.xml文件。
![]()
添加如下内容:

官网上只配置了fs.defaultFS参数,这个参数是配置hdfs的url地址。配置好后就可以在页面访问hdfs文件系统。
参考多数博客配置其零时文件夹tmp。原因后面解释。
2.配置hdfs-site.xml文件
![]()
添加如下内容:

官网上只配置了dfs.replication参数,参考大多数博客配置了namenode和datanode文件夹。

注:为什么要比官方多配置tmp,namenode,datanode文件呢?
先说这3个文件夹的作用,tmp是用来存放零时文件,比例运行过程中的文件等。namenode和datanode文件夹默认是放在tmp里面的,这2个文件夹用来存储hdfs里的内容。
不配置的话,hadoop默认把tmp会创建在ubuntu系统里的/tmp文件夹里,电脑一旦重启会自动清除tmp文件夹内容,同时也清除了里面的namenode和datanode文件内容,这样就会造成每次重启电脑namenode和datanode内容都不在了,那就需要重写格式化Hadoop文件系统hdfs,以前运行的记录和文件都会没有。所有配置了tmp和namenode和datanode文件夹,重启后可以不用格式化,原文件依然保持在hadoop文件系统上,只是放在了自己的目录里。
3.安装ssh
输入:sudo apt-get install ssh
![]()
SSH (Secure Shell)为建立在应用层和传输层基础上的安全协议。专为远程登录会话和其他网络服务提供安全性的协议。Ssh在hadoop中用来实现节点的登入和节点间传输文件。
4.安装rsync
输入:sudo apt-get install rsync
![]()
rsync(remote synchronize)顾名思意就知道它是一款实现远程同步功能的软件,它在同步文件的同时,可以保持原来文件的权限、时间、软硬链接等附加信息。可以通过ssh方式来传输文件。
5.配置ssh免秘密
分布式系统中需要用ssh来登入本地以及其他节点,然后进行文件的操作,以及传输。但是ssh默认下登入机器是需要用户密码的。而分布式的文件跨节点读写,若是每次都要输入密码时不现实的。所以需要ssh能免密码登入本地以及其他分布式节点。
5.1 生成秘钥对
输入指令:ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa
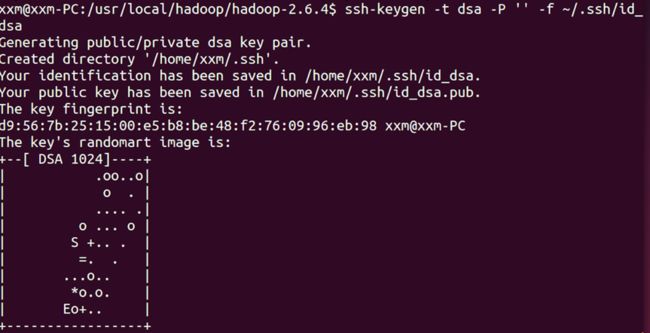
从截图提示可以看出,这个命令生成了一个id_dsa(私钥)文件,和一个id_dsa.pub(公钥)文件。
5.2 用cat命令追加公钥
输入指令:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
![]()
这部完成之后,就可以ssh登入本机来看是否已经可以无密码登入本机了。如下图,已经可以无密码登入啦。


6.格式化Hadoop文件系统
相当于我们新买来硬盘,装系统时候要先格式化一样。刚分配好的Hadoop文件系统也要格式化。
输入如下命令完成格式化:bin/hdfs namenode -format
![]()
格式化完成。
7.运行hdfs文件系统
输入如下代码:
sbin/start-dfs.sh
运行成功后再用jps查看进程,可以看到在进程中跑的namenode,datanode,secondarynamenode。

也可以在网页上查看,输入:localhost:50070
可以看到有一个节点活着。说明hdfs配置成功。

8.在hdfs中创建文件夹
现在的Hadoop文件系统时空的,我们来创建文件夹,用了作为根目录。官网提供如下2句代码。其中必须和本地的用户名同,比如下图所示,我的用户名是root。以后root用户名操作的所有的文件会在root文件夹里。
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/
![]()


9.测试伪分布式
把本地的input文件夹上传上来,作为后面测试的输入文件。
输入:bin/hdfs dfs -put input
![]()
可以在页面上查看input文件夹,自动放在了你的用户名root下,如下图所示:

和本地模式一样,这里测试2个mapreduce程序,一个grep,一个wordcount。
9.1例子一:grep
该例子是搜索input文件夹内所有文件,找到以dfs开始后面跟着字母a-z的单词,并输出在output/grep文件夹里。
输入代码如下:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output/grep ‘dfs[a-z.]+’
![]()

输入如下代码,查看结果:
bin/hdfs dfs -cat output/*
![]()
9.2例子二:wordcount
该例子是搜索input文件夹内所有文件,统计所有单词出现的次数,并输出在output/wordcount文件夹里。
输入代码如下:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar wordcount input output/wordcount
![]()
显示内容比较多,用get命令获取到本地hadoop目录下的output文件夹里查看。
输入:bin/hdfs dfs -get output output
![]()
可以在本地的output里查看。

当然也可以用cat查看,只是不能显示完整的内容。
cat output/*
![]()

以上内容就是配置完了hdfs并测试完成。
官网还提供了修改mapred-site.xml和yarn-site.xml文件来运行yarn。
10. 配置mapred-site.xml文件
![]()
添加如下内容:

测试中发现,配置了mapreduce.framework.name的值,运行程序报错。原因是ubuntu开启了防火墙,使得nodemanager处于安全模式。所以要先关闭ubuntu防火墙。命令如下:

另外在mapred-site.xml中比官网多配置了mapreduce.job.tracker。配置后job可以提交到集群里运行,默认是在本地运行。对于伪分布式不配置也不会有问题。
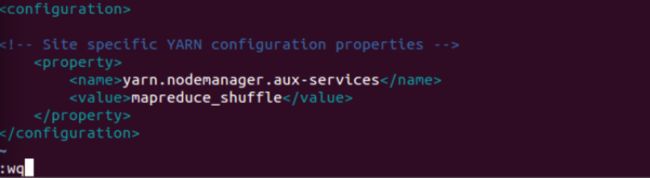
11. 配置yarn-site.xml文件
![]()
添加如下内容:
12.运行yarn资源管理器
可用jps查看

可以在页面localhost:8088中看到资源管理器。

到此yarn配置完成。
13.测试
运行hdfs和yarn(以后可以使用start-all.sh来同时运行)来测试grep和wordcount例子:
代码如下,结果请自行查看是否正确。
![]()
![]()
除了在50070上看输出结果,还可以在8088上看mapreduce作业的记录。

14.关闭hdfs和yarn
能开启自然也要会关闭,hdfs和yarn的关闭命令为:
stop-dfs.sh
stop-yarn.sh
或者
stop-all.sh
XianMing