大数据技术导论|datawhale组队学习
学习链接:https://datawhalechina.github.io/juicy-bigdata/#/README

Task01阅读第一、二章
第一章
主要介绍了大数据的概念、应用以及其关键技术。
第二章
开始介绍hadoop的相关内容。
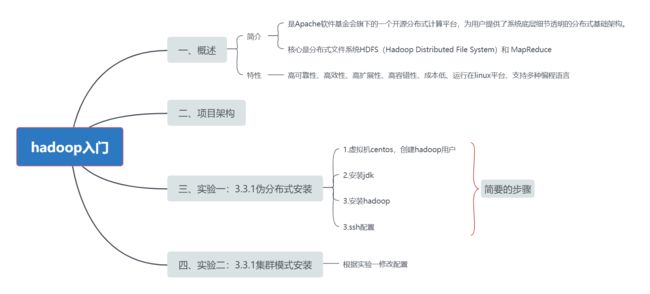
附厦大子雨老师的mooc教程:https://dblab.xmu.edu.cn/blog/285/,提供一些安装步骤!
安装过程中遇到的一个比较难搞的就是ssh配置那块,最后是通过修改权限解决了,其他暂时没有遇到问题,用的是win+虚拟机+centos7+hadoop3.3.1
架构补充学习

Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者, 是 Hadoop 的资源管理器。
MapReduce 将计算过程分为两个阶段: Map 和 Reduce
Map 阶段并行处理输入数据
Reduce 阶段对 Map 结果进行汇总
大数据技术生态体系,见下图:
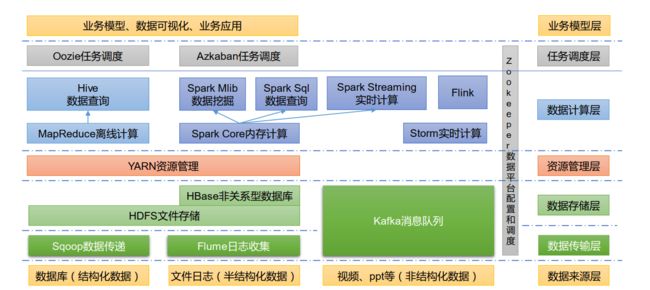
(来自尚硅谷的ppt)
图中涉及的技术名词解释如下:
1) Sqoop: Sqoop 是一款开源的工具,主要用于在 Hadoop、 Hive 与传统的数据库(MySQL)
间进行数据的传递,可以将一个关系型数据库(例如 : MySQL, Oracle 等)中的数据导进
到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2) Flume: Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3) Kafka: Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4) Spark: Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数
据进行计算。
5) Flink: Flink 是当前最流行的开源大数据内存计算框架。 用于实时计算的场景较多。
6) Oozie: Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7) Hbase: HBase 是一个分布式的、面向列的开源数据库。 HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8) Hive: Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张
数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运
行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开
发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9) ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、
名字服务、分布式同步、组服务等
解决方案:ssh 免密码登陆配置完后,输入ssh localhost提示还要密码
ssh配置代码:
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 authorized_keys
# 再试下
ssh localhost为什么要修改权限?参考下面的博客
https://blog.csdn.net/dujidan/article/details/122956840
心得体会
环境准备果然是最掉头发的。
Task02第三章HDFS
3.1概述
HDFS(Hadoop Distribute File System)是大数据领域一种非常可靠的存储系统,它以分布式方式存储超大数据量文件,但它并不适合存储大量的小数据量文件。同时HDFS是Hadoop和其他组件的数据存储层,运行在由价格廉价的商用机器组成的集群上的,而价格低廉的机器发生故障的几率比较高,因此HDFS在设计上采取了多种机制,在硬件故障的情况下保障数据的完整性。
(HDFS 只是分布式文件管理系统中的一种)
分布式文件系统的设计一般采用“客户机/服务器”(Client/Server),客户端以特定的通信协议通过网络与服务器建立连接,提出文件访问请求,客户端和服务器可以通过设置访问权,来限制请求方对底层数据存储块的访问。
HDFS 的使用场景:适合一次写入,多次读出的场景。 一个文件经过创建、写入和关闭之后就不需要改变
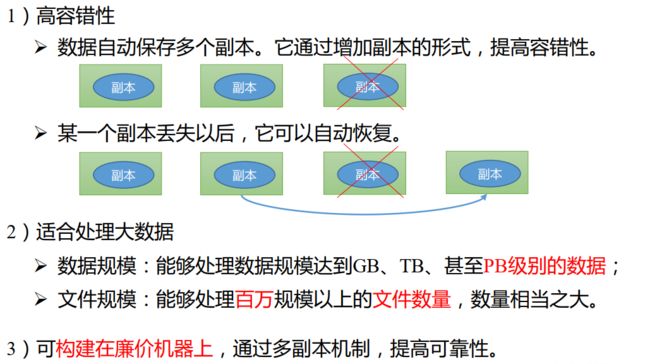
3.1.1HDFS的优点
3.1.2HDFS的缺点

3.1.3HDFS的组成架构

hadoop3.3.1官方文档:https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。


3.2HDFS存储原理
3.2.1数据的冗余存储
也就是多副本方式,即一个数据块的多个副本会被分到不同的数据节点上。

可以看到,当数据节点A损坏时,由B和C也能完成读取任务。
这种多副本方式具有以下 3 个优点:
加快数据传输速度:当多个客户端需要同时访问同一个文件时,可以让各个客户端分别从不同的数据块副本中读取数据,这就大大加快了数据传输速度,实现了并行操作。
容易检查数据错误:HDFS的数据节点之间通过网络传输数据,采用多个副本可以很容易判断数据传输是否出错。
保证数据的可靠性:即使某个数据节点出现故障失效,也不会造成数据丢失。
3.2.2数据存取策略
数据存放
数据读取
数据复制
a.数据存放的策略
HDFS默认的冗余复制因子是 3,每一个文件会被同时保存到 3 个地方,其中两份副本放在同一个机架的不同机器上面,第三个副本放在不同机架的机器上面。

HDFS副本的存放策略是:
如果是在集群内发起写操作请求,则把第1个副本放置在发起写操作请求的数据节点上,实现就近写入数据。如果是来自集群外部的写操作,则从集群内部挑选一台磁盘空间较为充足、CPU不太忙的数据节点,作为第1个副本的存放地。
第2个副本会被放置在与第1个副本不同的机架的数据节点上。
第3个副本会被放置在与第1个副本相同的机架的其他节点上。
如果还有更多的副本,则继续从集群中随机选择数据节点进行存放。
b.数据读取的策略
HDFS提供了一个API,用于确定一个数据节点所属的机架的ID,客户端可以调用该API获取自己所属机架的ID。
当客户端读取数据时,从名称节点获取数据块不同副本的存放位置的列表,列表中包含了副本所在的数据节点,可以调用API确定客户端和这些数据节点所属的机架ID。当发现某个数据块副本对应的机架ID和客户端对应的机架的ID相同时,则优先选择该副本读取数据;如果没有发现,则随机选择一个副本读取数据。
c.数据复制
流水线复制的策略。顾名思义,内容被分成各个小块,每个小块按顺序给到每个datanode。
3.2.3数据错误与恢复
a.名称节点出错
Hadoop采用两种机制来确保名称节点的安全:
把名称节点上的元数据信息同步存储到其他文件系统中;
运行一个第二名称节点,当名称节点宕机以后,利用第二名称节点中的元数据信息进行系统恢复。
但是用第二种方法恢复数据,仍然会丢失部分数据。 因此,一般会把上述两种方法结合使用,当名称节点宕机时,首先到远程挂载的网络文件系统中获取备份的元数据信息,放到第二名称节点上进行恢复,并把第二名称节点作为名称节点来使用。
b.数据节点出错
每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态。当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自这些节点的“心跳”信息,这时,这些节点就会被标记为“宕机”,节点上面的数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求。 当名称节点检查发现,某个数据的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本。
c.数据出错
网络传输和磁盘错误等因素都会造成数据错误。客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确保读取到正确的数据。在文件被创建时,客户端会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面。 当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验。如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。
3.3HDFS的数据读写过程
https://blog.csdn.net/hudiefenmu/article/details/37655491
更好的帮助我理解整个的工作流程!差不多光看漫画懂了一些原理。
3.4心得
本章最后一节通过实验,讲解了在Linux系统中的HDFS文件系统基本命令,通过这些命令可以进一步熟悉HDFS分布式文件系统的使用。
这一个实验让我熟悉了最基本的操作。
实验之前的部分也让我对HDFS的工作原理和方式有了更深的了解!因为不是大数据专业,只是想泛泛阅读一下,所以没有太深入了解。
Task03第四章Hbase
这一块的概念还是得看博客再学习学习,都是重点,摘了自己觉得是重点的部分:https://datawhalechina.github.io/juicy-bigdata/#/ch4%20HBase
4.1Hbase概述
由于Hadoop只能进行批处理,并且只能以顺序的方式访问数据,所以尽管只搜寻一个数据,也要搜索整个数据库,无法实现对数据的随机访问。由此Hbase诞生了。
HBase旨在提供对大量结构化数据的快速随机访问。它利用Hadoop文件系统(HDFS)提供的容错功能,同时作为Hadoop生态系统的一部分,提供对Hadoop文件系统中的数据的随机实时读写访问。
HBase在hadoop生态系统中是这样工作的:
使用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算;
使用ZooKeeper作为协同服务,实现稳定服务和失败恢复;
使用HDFS作为高可靠的底层存储;
利用廉价集群提供海量数据存储能力。(当然,HBase也可以直接使用本地文件系统而不用HDFS作为底层数据存储方式。)
Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
Hbase VS 传统数据库
区别 |
Hbase |
传统的关系型数据库 |
数据类型 |
数据类型简单,未经解释的字符串 |
int\data\long,,, |
数据操作 |
存储在同个表中,高效率 |
增删改查联表,效率低 |
存储模式 |
列模式 |
行模式 |
数据索引 |
行键索引 |
列 |
数据维护 |
回收站模式 |
直接删除 |
可伸缩性 |
分布式集群存储,扩展性好 |
不好 |
但是Hbase不支持事务,因此无法实现跨行的原子性。
事务(trasaction):
事务就是由单独单元的一个或多个sql语句组成,在这个单元中,每个sql语句都是相互依赖的。而整个单独单元是作为一个不可分割的整体存在,类似于物理当中的原子(一种不可分割的最小单位)。
往通俗的讲就是,事务就是一个整体,里面的内容要么都执行成功,要么都不成功。不可能存在部分执行成功而部分执行不成功的情况。
就是说如果单元中某条sql语句一旦执行失败或者产生错误,那么整个单元将会回滚(返回最初状态)。所有受到影响的数据将返回到事务开始之前的状态,但是如果单元中的所有sql语句都执行成功的话,那么该事务也就被顺利执行。
来自 https://blog.csdn.net/qq_56880706/article/details/122653735
4.2BHbase数据模型
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。
每个值是一个未经解释的字符串,没有数据类型。
用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。
列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储。因此对于整个映射表的每行数据而言,有些列的值是空的,所以说HBase是稀疏的。
HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)
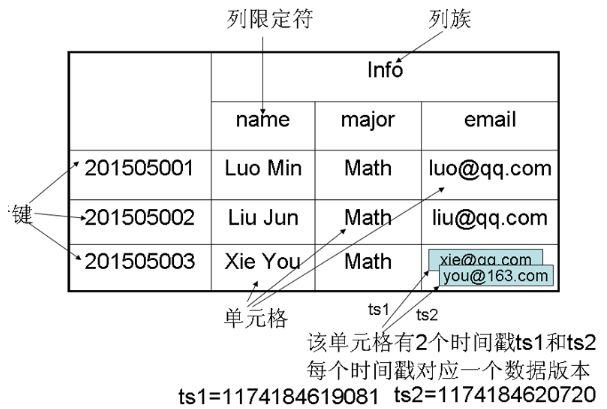
表:存储学生信息的Hbase表
行键:学号
列祖:Info
列:Info这个列组里有若干个列name、major、email
列限定符:和列的概念差不多
单元格:cell。通过行、列族和列限定符和时间戳确定
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。时间戳较大的版本的数据是最新的数据
数据坐标:四维坐标,[行键, 列族, 列限定符, 时间戳],通过思维坐标确定一个单元格

概念视图:
在HBase的概念视图中,一个表可以视为一个稀疏、多维的映射关系。

物理视图:
HBase中的每个表是许多行组成的,但是在物理存储层面,它采用基于列的存储方式,而不是像传统关系数据库那样采用基于行的存储方式,这也是HBase和传统关系数据库的重要区别。
属于同一个列族的数据保存在一起,同时,和每个列族一起存放的还包括行键和时间戳。
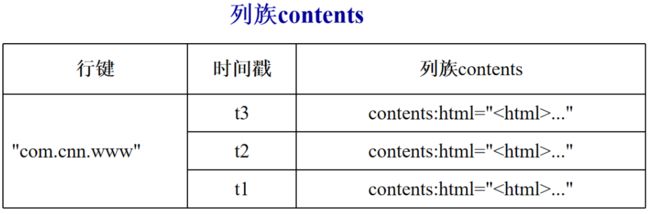

行式数据库和列式数据库
行存储数据库适用在OLTP(on-line transaction processing)场景即联机事务处理,而列数据库适合适用在大数据分析OLAP(on-line Analytical processing)联机分析处理
以下表为例,表名为person
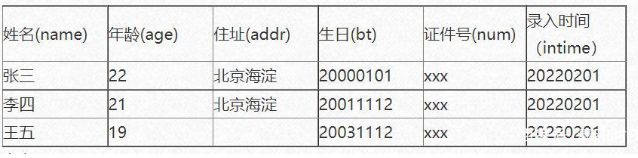
select name,addr from person where age>20
sql |
列式 |
行式 |
查询年满20岁人员姓名住址 |
读取3列 |
读取所有 |
4.3Hbase实现原理
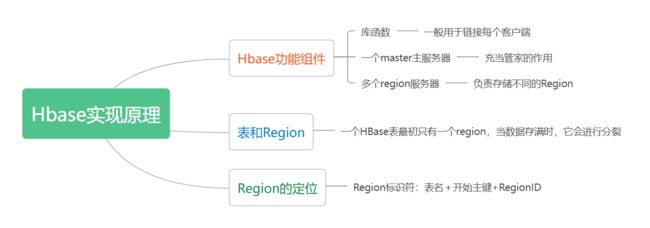
图1 本节的概括
Hbase功能组件
见图1
表和Region
Hbase存储多个表。Hbase表是根据行键的值的字典序进行维护的,表包含的行的数量可能非常大,因此无法存储在一台机器上,故需要根据行键的值对表中的行进行分区。每个行区间构成一个分区,被称为Region。Region包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。

Region的定位
每个Region都有一个RegionID来标识它的唯一性,这样,一个Region标识符就可以表示成表名+开始主键+RegionID。
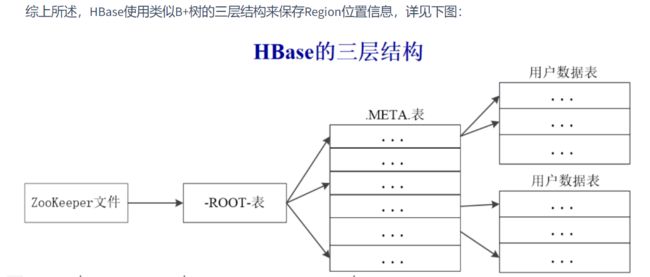
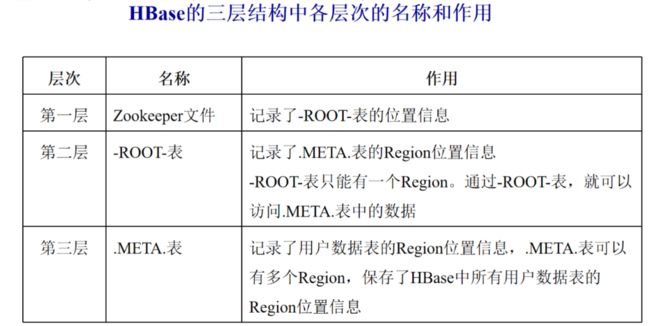
4.4Hbase运行机制
Hbase系统架构

Region服务器的工作原理
第一阶段:用户读写数据过程
用户写入数据时,被分配到相应Region服务器去执行
用户数据首先被写入到MemStore和Hlog中
只有当操作写入Hlog之后,调用commit() 方法才会将其返回给客户端
当用户读取数据时, Region服务器会首先访问MemStore缓存,如果找不到,再到磁盘的StoreFile中寻找
第二阶段:缓存的刷新
系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
每个Region服务器都有一个自己的HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
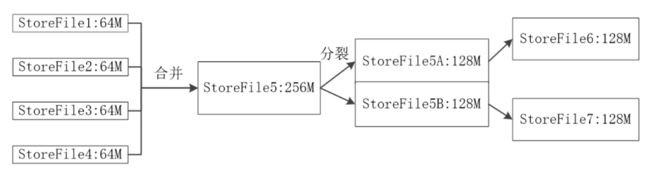
第三阶段:StoreFile的合并
每次刷写都生成一个新的StoreFile,数量太多,影响查找速度
调用Store.compact()把多个StoreFile合并成一个
合并操作比较耗费资源,只有数量达到一定阈值后才会启动合并
Store工作原理
Store是Region服务器的核心
多个StoreFile合并成一个StoreFile
单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
Hlog工作原理
在分布式环境下,必须考虑到系统出错的情形,比如当Region服务器发生故障时,MemStore缓存中的数据(还没有写入文件)会全部丢失。因此,HBase用HLog来保证系统发生故障时能够恢复到正确的状态
Task04第五章MapReduce
5.1概述
MapReduce可以拆分成Map喝Reduce来理解。
它设计的理念是计算向数据靠拢(将应用程序分发到数据所在的机器上)。在Hadoop中,存储数据的是分布式文件系统HDFS,因此MapReduce框架会将Map程序就近在HDFS数据所在节点运行,减少了节点间数据移动开销。
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave上运行 TaskTracker。用户提交的每个计算作业,会被划分成若干个任务。
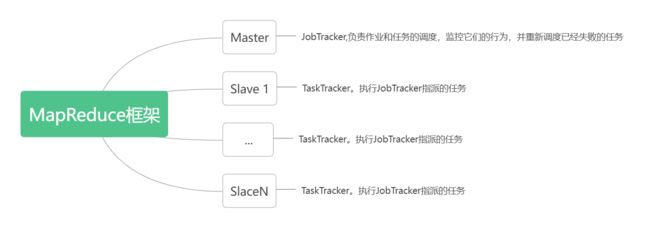
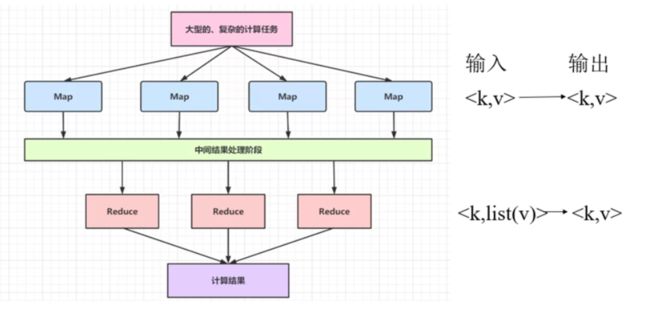
MapReduce的作业过程分为:
数据的输入
数据的处理(由map,reduce,combiner组成)
数据的输出
MapReduce的作业过程中涉及到的组件:
客户端:提交MapReduce作业
yarn资源管理器:负责集群上计算资源的协调
yarn节点管理器:负责启动和监控集群中机器上的计算容器(container)
MapReduce的application master:负责协调运行MapReduce的作业
HDFS:分布式文件系统,负责与其他实体共享作业文件
5.1.1Map和Reduce

5.2MapReduce的工作流程
大规模数据集的处理包括分布式存储和分布式计算两个核心环节。
Hadoop使用分布式文件系统HDFS实现分布式数据存储,用Hadoop MapReduce实现分布式计算
比较关键的地方:
Map任务会根据用户自定义的映射规则,输出一系列的
为了让Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区、排序(Sort)、合并(Combine)和归并(Merge)等操作,得到
所谓Shuffle,是指针对Map输出结果进行分区、排序和合并等处理,并交给Reduce的过程。因此,Shuffle过程分为Map端的操作和Reduce端的操作
Map端操作:
Map的输出结果首先被写入缓存,缓存满了后,首先将数据进行分区(MapReduce通过Partitioner接口对这些键值对进行分区,默认采用的分区方式是采用Hash函数对key进行哈希后,再用Reduce任务的数量进行取模,可以表示成hash(key) mod R。其中,R表示Reduce任务的数量,这样,就可以把Map输出结果均匀地分配给这R个Reduce任务去并行处理了。当然,MapReduce也允许用户通过重载Partitioner接口来自定义分区方式。),进行排序、合并(所谓“合并”,是指将那些具有相同key的
每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并(Merge,所谓归并(Merge),是指对于具有相同key的键值对,会被归并成一个新的键值对。具体而言,对于若干个具有相同key的键值对
Reduce端操作:
从Map读取结果(也就是领取fetch),然后执行归并操作,接着输送给Reduce就行。
5.3总结
具体的过程了解了。用word count的实验实在是太通透了,理解的很透彻。这个图就是大致的工作流程,具体的细节就需要回过头看刚刚写的5.2节。一条线就是map-->shuffle-->reduce
回答下面的问题就说明大概能理解了:
map的输入数据是什么?map的输出是什么?中间是怎么处理的?此时数据存储在什么地方?
shuffle在map和reduce端分别起到一个什么作用?此时数据存储在什么地方?
reduce的输入数据是什么?输出又是什么?是怎么处理的?此时数据存储在什么地方?
Task05第六章:期中测试
6.1笔试题
6.1.1 简述Hadoop小文件弊端
HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个DataNode跳到另外一个DataNode,严重影响性能。最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。

6.1.2 HDFS中DataNode挂掉如何处理?
重启
6.1.3 HDFS中NameNode挂掉如何处理?
重启,激活备用节点。如果都不行,就移动文件。
6.1.4 HBase读写流程?
读取:
Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着 hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。 当一个表多个region怎么办呢? 如果我们获取数据是以get的方式,只会返回一个regionserver 如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据: 读取顺序:memstore-->blockcache-->storefile-->Hfile中 注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
写入:
Hbase的写入数据流程:1)由客户端发起写数据请求,首先会与zookeeper建立连接2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
6.1.5 MapReduce为什么一定要有Shuffle过程
因为map的结果reduce不能处理?
6.1.6 MapReduce中的三次排序
shuffle的map端。shuffle的reduce端。然后reduce的结果进行排序。
6.1.7 MapReduce为什么不能产生过多小文件
6.2实战
实在没时间了。。。
Taks06第七章Hive
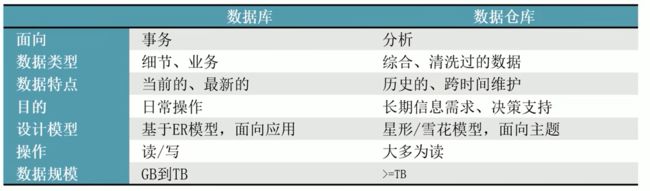
7.1数据仓库
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
主要是用于组织历史积累的历史数据,并使用分析方法(数据分析)进行分析。


7.2Hive
Hive是建立在Hadoop之上的一种数仓工具。该工具的功能是将结构化的数据文件映射为一张数据库表,基于数据库表,提供了一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive本身并不具备存储功能,其核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群中执行。
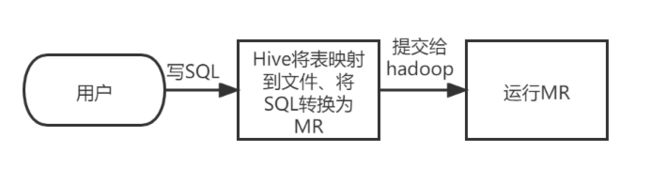
用HiveQL语句编写的处理逻辑,最终都要转换成MapReduce任务来运行.
7.2.1hive的数据模型
库、表、分区、分桶
7.2.2hive的系统结构
Hive主要由3个模块组成。
用户接口模块,主要实现外部应用对Hive的访问
驱动模型,所采用的执行引擎可以是 MapReduce、Tez或Spark等。当采用MapReduce作为执行引擎时,驱动模块负责把 HiveQL语句转换成一系列MapReduce作业
元数据存储模块
元数据(metadata)是描述数据的数据,在Hive中,元数据储存在mysql中。元数据存储模块中主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
Metastore管理元数据的方式:
内嵌模式
本地模式
远程模式
7.2.3HQL的执行流程

Task07第八章Spark
8.0前导知识
内存和磁盘两者都是存储设备,但内存储存的是我们正在使用的资源,磁盘储存的是我们暂时用不到的资源
MapReduce每一个步骤发生在内存中,但产生的中间值(溢写文件)都会写入在磁盘里,下一步操作时又会将这个中间值merge到内存中,如此循环直到最终完成计算。
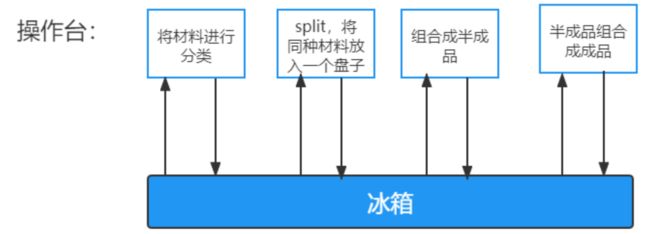
而对于Spark,每个步骤也是发生在内存之中,但产生的中间值会直接进入下一个步骤,直到所有的步骤完成之后才会将最终结果保存进磁盘。所以在使用Spark做数据分析时,较少进行很多次相对没有意义的读写,节省大量的时间。当计算步骤很多时,Spark的优势就体现出来了。
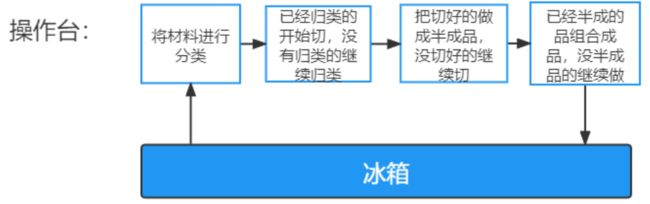
8.1Spark概述
Hadoop处理大数据的流程:
首先从HDFS读取输入数据;(一次读取操作)
接着在 Map 阶段使用用户定义的mapper function;
然后把结果写入磁盘;(一次写入操作)
在Reduce阶段,从各个处于Map阶段的机器中读取Map计算的中间结果,使用用户定义的reduce function,(一次读取操作)
最后把结果写回HDFS。(一次写入操作)
Spark是基于内存存储来进行数据存储(指的是计算存储而非持久化的存储)和读写。
但是Spark没有分布式文件系统,必须依赖外部的数据源,例如可以依赖Hadoop系统的HDFS。

参考:https://blog.csdn.net/feizuiku0116/article/details/122795787
8.1.1Spark生态体系
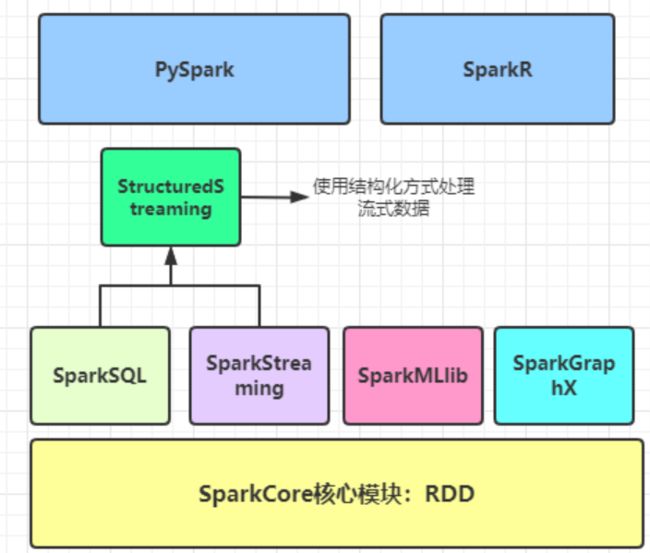
8.2RDD及一些原理
8.2.1RDD概述
RDD是Spark的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。RDD既是Spark面向开发者的编程模型,又是Spark自身架构的核心元素。
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。
RDD是分布式内存的一个抽象概念,是只读的记录分区集合,能横跨集群所有节点进行并行计算。Spark建立在抽象的RDD上,可用统一的方式处理不同的大数据应用场景,把所有需要处理的数据转化为RDD,然后对RDD进行一系列的算子运算,通过丰富的API来操作数据,从而得到结果。

分区:将计算以分区为单位,分配到多个机器上并行计算。Spark通过位置信息,将计算工作发给离数据近的机器,减少跨网络传输的数据量。
可并行计算:每个分区由一个Task处理,每个分区有计算函数(具体执行的计算算子),计算函数以分片为基本单位进行并行计算,RDD的分区数决定着并行计算的数量
依赖关系
Key-Value数据的RDD分区器
每个分区都有一个优先位置列表
跟MapReduce一样,Spark也是对大数据进行分片计算,Spark分布式计算的数据分片、任务调度都是以RDD为单位展开的,每个RDD分片都会分配到一个执行进程中进行处理。
操作函数包含两种:
转换(transformation),返回值还是RDD,指定RDD之间的相互依赖关系
执行(action),执行计算并指定输出的形式
RDD典型的执行过程如下:
RDD读入外部数据源(或者内存中的集合)进行创建;
RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用,并构建DAG
DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
RDD采用惰性调用,也就是说在以上执行过程中,真正的计算是发生在action操作,所有的transformation操作只是被Spark记录下来,Spark也记录了RDD生成的轨迹,即相互之间的依赖关系。
例如在下图,AC是两个RDD,经过一系列的transformation操作,逻辑上生成了一个F(也是一个RDD),但是这个时候并没有真的生成一个F。当F进行action操作,Spark才会根据RDD的依赖关系生成DAG。(在Spark中,DAGScheduler组件负责应用DAG的生成和管理,DAGScheduler会根据程序代码生成DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。)

图 RDD执行过程的一个实例
上述这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性;相反,在MapReduce的设计中,为了尽可能地减少MapReduce过程,在单个MapReduce中会写入过多复杂的逻辑。
8.2.2RDD之间的依赖关系
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为
窄依赖(Narrow Dependency)
宽依赖(Wide Dependency)
下图是窄依赖和宽依赖的区别所在:
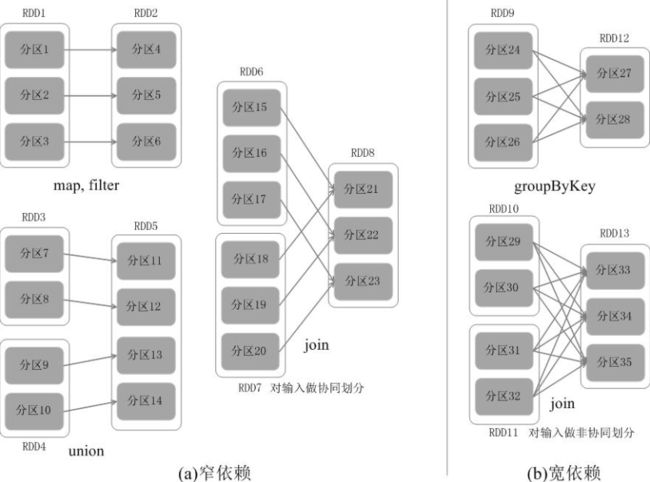
图 窄依赖与宽依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;比如图(a)中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。比如图(b)中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
8.2.3划分阶段
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,
具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
关于shuffle的概念不是很清楚。
Task08第九章总结与期末
大数据框架的组成引擎主要分为:存储和分析。
针对存储,目前学习到的是HDFS和Hbase
针对分析,目前学习到的是MapReduce,Hive,Spark
笔试题
hive外部表和内部表的区别
1. 内部表数据由Hive自身管理,外部表数据由HDFS管理;
2.内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里)。
3.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
4.对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)。
简述对Hive桶的理解
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
https://blog.csdn.net/u010003835/article/details/80911215
Hbase和Hive的区别?
一个是存储的,一个是计算的。
hbase是物理表,hive是逻辑表
简述Spark宽窄依赖
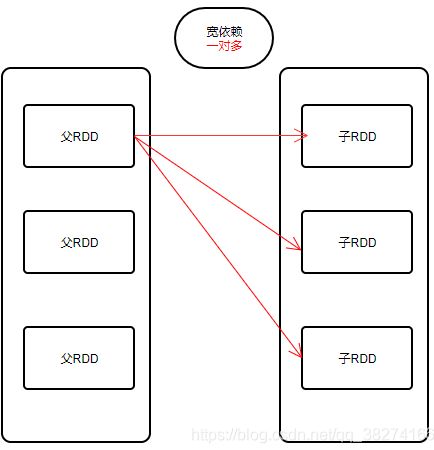
1、宽依赖:是指1个父RDD分区对应多个子RDD的分区
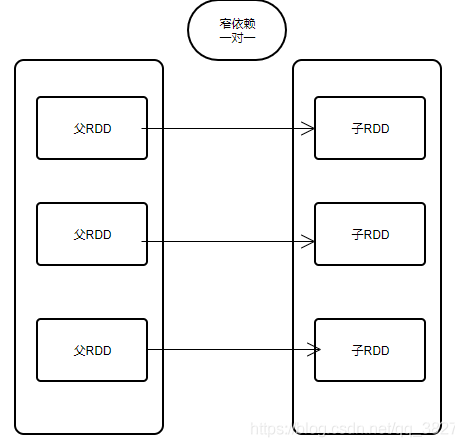
2、窄依赖:是指一个或多个父RDD分区对应一个子RDD分区
简单的说就是我们在数学中的映射关系
宽依赖就是1对多,窄依赖就是一对一或者多对一

Hadoop和Spark的相同点和不同点
相同点:都是大数据生态里的;都是并行计算
不同点:Hadoop是分布式管理、存储、计算的生态系统。Spark是分布式计算平台
Spark为什么比MapReduce快?
Spark是基于内存进行计算的,所以减少了从磁盘读取数据的次数
对Hadoop生态的认识
Hadoop生态中包含的三大组件为HDFS(存储),MapReduce(计算),YARN(资源管理器)。除此之外,也产生了更多的工具和组件,例如HIVE,SPARK,pig等,这些都是为了更好的进行大数据计算。