如何给字符串字段加索引?
1.引例
现在的系统中,很多都会包含邮箱字段,那要如何给这个字段建立索引呢?
假设,现在维护了一个用户表,其中包含邮箱,定义如下:
mysql>
create table SUser(
ID int primary key,
email varchar(64),
...
)engine=InnoDB;
如果我们要根据邮箱查询用户信息,那必然会用到下面的语句:
mysql> select f1, f2 from SUser where email='xxx';
如果在email这个字段上没有索引,那么这个语句就只能做全表扫描。
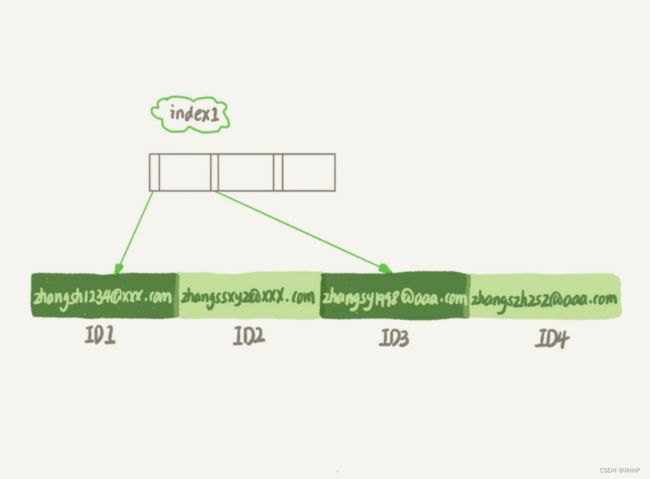
你可以给字符串加索引,当不指定索引的长度的时候,索引就会包含整个字符串,如下面的语句和图所示:
alter table SUser add index index1(email)
由于MySQL支持前缀索引,所以可以将字符串的一部分作为索引,如下图的语句和图所示:
mysql> alter table SUser add index index2(eamil(6));

由此可见,这个索引只使用了邮箱字段的前6个字节,占用空间更小,这就是前缀索引的优势。
接着,我们来看下这个语句,在两种索引下是如何执行的:
mysql> select id, name, email from SUser where email="[email protected]"
如果使用的是index1(整个字符串索引),则查询流程是:
- 从index1的索引树上查到"[email protected]",然后进行回表查询,判断email值是否正确,加入结果集
- 取index1索引树上的下一条记录,发现不满足了,就结束循环
可见,需要进行一次回表查询。
如果使用的是index2(email(6)索引),则查询流程是:
- 从index2的索引树上,涨到第一个满足前缀的"zhangs"的记录,进行回表查询,发现不匹配,这一行就丢弃。
- 取index2索引树上的下一条记录,发现仍然满足前缀"zhangs",进行回表查询,发现匹配,加入结果集。
- 继续重复上面的过程,直到不匹配
可见,需要进行四次回表查询。
因此,可以发现,有时候使用了前缀索引,反而导致查询语句读数据的次数变多。
但是容易发现,如果前缀索引的长度变为7,即"zhangss",则在索引树上只有一条记录满足,则只需要进行一次回表查询。
因此,使用前缀索引,长度很重要,既可以节省空间,又可以减少查询成本。我们在建立索引的时候,要关注区分度,区分度越高,意味着重复键值越少。
2.前缀索引对覆盖索引的影响
我们来看下面这个sql语句:
mysql>select id,email from SUser where email='[email protected]'
如果使用的是index1(整个字符串索引),那么就可以利用覆盖索引,直接返回结果了,不需要回表查询。
如果使用的是index2(email(6)索引),则需要回表查询email的值。
因此,如果使用前缀索引,那就用不上覆盖索引的优化了。
3. 其他方式
如果字符串区分度太低导致前缀区分的方式不好呢,还有什么方式。
例如当我们存储身份证号码的时候,同一个县的人,前6位都是一样的,那使用长度为6的前缀索引,需要回表的次数就很多。那如果使用长度为12的前缀索引,占有的磁盘空间又太大。
基于此,我们可以考虑下面两种方式,平衡这两者:
第一种方式是使用倒序存储,把身份证倒过来存储,查询的时候可以这样查询:
mysql> select field_list from t where id_card = reverse('input_id_car');
由于身份证后6位各不相同,就能够有很好的区分度。
第二种方式是使用hash字段,在表中再创建一个字段,使用hash函数对身份真进行计算,并存储到这个字段中。并且在这个hash字段建立索引。查询的时候可以这样写:
mysql>select field_list from t where id_card_hash=hash('input_id_card') and id_card = 'input_id_car';
这样就可以通过hash函数先筛选掉一部分,减少查询的次数。并且hash字段的长度也比身份证小很多。
最后,我们来比较两种方法的异同:
- 从占用空间看,倒序索引不需要消耗额外空间。hash字段只需要增加一个字段,但是也不用太长。
- 从CPU消耗看,倒序索引使用反转函数,比hash函数消耗小一些
- 从查询效率看,hash字段虽然会有冲突,但是概率会比倒序索引小一些。
来源:自己整理的MySQL实战45讲笔记