Pyflink教程(六):窗口函数
在pyflink学习笔记(一)中简单介绍了table-sql的窗口函数,下面简单介绍下datastream形式的窗口函数,只能说,能用sql解决的,就别写datastream了。个人感觉udf+sql基本就能满足大部分的业务需求了。
我这是根据官网地址和尚硅谷java版Flink相关资料整理的。
概念
我们已经了解了 Flink 中事件时间和水位线的概念,那它们有什么具体应用呢?当然是做基于时间的处、计算了。其中最常见的场景,就是窗口聚合计算。
之前我们已经了解了 Flink 中基本的聚合操作。在流处理中,我们往往需要面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。所以聚合计算其实只能针对当前已有的数据——之后再有数据到来,就需要继续叠加、再次输出结果。这样似乎很“实时”,但现实中大量数据一般会同时到来,需要并行处理,这样频繁地更新结果就会给系统带来很大负担了。
更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“窗口”(Window)聚合操作。窗口聚合其实是对实时性和处理效率的一个权衡。在实际应用中,我们往往更关心一段时间内数据的统计结果,比如在过去的 1 分钟内有多少用户点击了网页。在这种情况下,我们就可以定义一个窗口,收集最近一分钟内的所有用户点击数据,然后进行聚合统计,最终输出一个结果就可以了。
Flink Windows 是处理无限流的核心。
通常我们将窗口理解成:根据某种条件或方法将流数据切分成多个块,每一块形成一个窗口。如下图所示,我们根据时间或者个数切分,而我们一般定义数据的时间都是事件时间,所以就会造成有的数据比实际晚到,造成窗口中数据不是我们想统计的时间段内的数据,当然我们可以让水位线时间后移,延迟窗口内数据范围,但还是不够严谨,这样会造成窗口处理结果的不准确。

Flink Windows 将流拆分为有限大小的“桶”,我们可以对其进行计算.所以在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如下图所示。
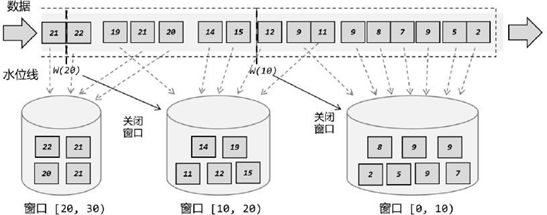
在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
窗口的分类
按照驱动类型分类
窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信息其实就是“怎样截取数据”。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的“驱动型”。
时间窗口(Time Window):是我们最容易想到的,也是用的最多的。时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
计数窗口(Count Window):计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。
按照窗口分配数据的规则分类
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能应用。
滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠, 也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动, 那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(windowsize)。比如我们可以定义一个长度为1 小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为 10 的滚动计数窗口,就会每 10 个数进行一次统计。

滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
既然是向前滑动,那么每一步滑多远,就也是可以控制的。所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(windowslide),它其实就代表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统计 1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。
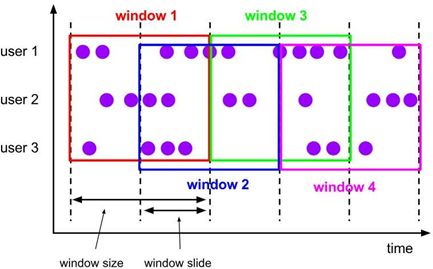
我们可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值(size/slide)来决定
所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小, 并尽量设置为整数倍的关系。
在一些场景中,可能需要统计最近一段时间内的指标,而结果的输出频率要求又很高,甚至要求实时更新,比如股票价格的 24 小时涨跌幅统计,或者基于一段时间内行为检测的异常报警。这时滑动窗口无疑就是很好的实现方式。
会话窗口
会话窗口分配器按活动会话对元素进行分组。与tumbling windows和sliding windows相比,会话窗口不重叠,也没有固定的开始和结束时间。取而代之的是,当会话窗口在一段时间内没有接收到元素时关闭,即,当出现不活动间隙时。会话窗口分配器可以配置为静态会话间隙或 会话间隙提取器函数,它定义了不活动的时间长度。当这段时间到期时,当前会话关闭,后续元素被分配给新的会话窗口。

还有全局窗口,这里就不介绍了,用的比较少。
窗口API概览
按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前, 是否有 key_by 操作。
(1)按键分区窗口(Keyed Windows)
经过按键分区keyBy 操作后,数据流会按照key 被分为多条逻辑流(logical streams),这就是 KeyedStream。基于KeyedStream进行窗口操作时, 窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个key 上都定义了一组窗口,各自独立地进行统计计算。
stream
.key_by(...)
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.allowed_lateness(...)] <- optional: "lateness" (else zero)
[.side_output_late_data(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.get_side_output(...)] <- optional: "output tag"(2)非按键分区(Non-KeyedWindows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
stream
.window_all(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.allowed_lateness(...)] <- optional: "lateness" (else zero)
[.side_output_late_data(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.get_side_output(...)] <- optional: "output tag"窗口分配器
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种
滚动时间窗口。
参数:
size :定义窗口大小,如下面Time.seconds(5),就是定义一个5秒间隔的窗口
offset:偏移量,这个参数的主要作用是调整时间初试值,比如下面Time.days(1), Time.hours(-8),我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了
from pyflink.common import Types, Time
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.window import TumblingEventTimeWindows, TumblingProcessingTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds = env.from_collection(
[('a', 'id=1', 1), ('a', 'id=2', 2), ('a', 'id=3', 3), ('b', 'home=1', 1), ('b', 'home=2', 2)],
type_info=Types.ROW_NAMED(["key", "url", "value"], [Types.STRING(), Types.STRING(), Types.INT()]))
result1 = ds.key_by(lambda x: x[0]) \
#创建了一个长度为 5 秒的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5))) # 滚动事件时间窗口
# .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) # 滚动处理时间窗口
# .window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8))) #滚动事件时间窗口
滑动时间窗口
参数:
size :滑动窗口的大小
slide:滑动窗口的滑动步长
offset:偏移量
result = ds.key_by(lambda x: x[0]) \
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) # 滑动事件时间窗口
# .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) #滑动处理时间窗口
# .window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8))) 会话时间窗口
参数:
size :会话窗口的大小
offset:偏移量
这里.withDynamicGap()方法需要传入一个 SessionWindowTimeGapExtractor作为参数,用来定义 session gap 的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔。
class MySessionWindowTimeGapExtractor(SessionWindowTimeGapExtractor):
def extract(self, element: tuple) -> int:
return element[0].length() * 1000
result = ds.key_by(lambda x: x[0]) \
# 这里.withGap()方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最小间隔 sessiongap。我们这里创建了静态会话超时时间为 10 分钟的会话窗口。
.window(EventTimeSessionWindows.with_gap(Time.minutes(10)))
#这里.withDynamicGap()方法需要传入一个 SessionWindowTimeGapExtractor 作为参数,用来定义 session gap 的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔。
# .window(EventTimeSessionWindows.with_dynamic_gap(MySessionWindowTimeGapExtractor()))
# .window(ProcessingTimeSessionWindows.with_gap(Time.minutes(10)))
# .window(DynamicProcessingTimeSessionWindows.with_dynamic_gap(MySessionWindowTimeGapExtractor()))计数窗口(Count Window)
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink 为我们提供了非常方便的接口:直接调用.count_window()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
参数:
size: 窗口大小属性
slide: 步长
ds.key_by(lambda x: x[0]).count_window(10,3)窗口函数(Window Functions)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream.

增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结果的一瞬间再去进行聚合,显然就不够高效了——这相当于真的在用批处理的思路来做实时流处理。
为了提高实时性,我们可以再次将流处理的思路发扬光大:就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出,这无疑就大大提高了程序运行的效率和实时性。
归约函数(ReduceFunction)
最基本的聚合方式就是归约(reduce)。我们在基本转换的聚合算子中介绍过 reduce 的用法,窗口的归约聚合也非常类似,就是将窗口中收集到的数据两两进行归约。当我们进行流处理时,就是要保存一个状态;每来一个新的数据,就和之前的聚合状态做归约,这样就实现了增量式的聚合。
下面的例子是前面我们写过的reduce例子,加上窗口函数,我们看看结果。
import random
import time
from typing import Any
from pyflink.common import Types, Time, WatermarkStrategy
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
from pyflink.datastream.window import TumblingEventTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
# env.get_config().set_auto_watermark_interval(100)
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
result_list = []
for num in range(20):
result_tuple = (random.choice(name_list), random.choice(url_list), int(round(time.time() * 1000)))
print(result_tuple)
result_list.append(result_tuple)
time.sleep(random.randint(1, 5))
print("create data success")
#窗口函数实现类,需指定时间参数
class myTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value: Any, record_timestamp: int) -> int:
return int(value[2])
ds = env \
.from_collection(result_list,
type_info=Types.ROW_NAMED(["name", "url", "timestamp1"],
[Types.STRING(), Types.STRING(), Types.INT()])) \
.assign_timestamps_and_watermarks(
WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(myTimestampAssigner()))
#因为我们的数据就是按顺序生成的,不存在乱序的问题,只是间隔时间不同,所以这块的水位线就是单调递增
class MyReduceFunction(ReduceFunction):
def reduce(self, value1, value2):
return value1[0], value1[1] + value2[1]
class MyReduceFunction2(ReduceFunction):
def reduce(self, value1, value2):
return value1 if value1[1] > value2[1] else value2
result = ds \
.map(lambda x: (x.name + "_" + x.url, 1)) \
.key_by(lambda x: x[0]) \
.window(TumblingEventTimeWindows.of(Time.seconds(120))) \
.reduce(MyReduceFunction())
result.print("reduce:")
env.execute()
首先,窗口函数的时间,可以改变, 我这块设置了120秒。意味着,我们是收集了120秒内所有的数据形成一个窗口,统计这个窗口范围内所有的数据进行reduce,所以看结果输出,只打印了每个分类一个结果,如果没有则所有结果都会打印。
reduce:> ('zhao_google.com', 2)
reduce:> ('wang_taobao.com', 1)
reduce:> ('wang_google.com', 2)
reduce:> ('yu_yangshi.com', 4)
reduce:> ('yu_google.com', 1)
reduce:> ('yu_baidu.com', 2)
reduce:> ('wang_baidu.com', 2)
reduce:> ('wang_yangshi.com', 2)
reduce:> ('zhao_taobao.com', 3)
reduce:> ('zhao_baidu.com', 1)聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
所以我们可能要经历map-reduce-map-reduce 一系列比较麻烦的操作,不够灵活。
所以我们可以使用Flink提供的AggregateFunction函数,AggregateFunction 可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型IN)、累加器类型(ACC)和输出类型
(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
下面的例子,我们填个数据,求个用户均数,均数=总和/个数和
import random
import time
from typing import Any
from pyflink.common import Types, WatermarkStrategy, Time
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction
from pyflink.datastream.window import TumblingEventTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
# env.get_config().set_auto_watermark_interval(100)
name_list = ["wang", "zhao"]
url_list = ["baidu.com", "taobao.com", "google.com"]
result_list = []
for num in range(10):
result_tuple = (
random.choice(name_list), random.choice(url_list), int(round(time.time() * 1000)), random.randint(1, 5))
print(result_tuple)
result_list.append(result_tuple)
time.sleep(random.randint(1, 5))
print("create data success")
class myTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value: Any, record_timestamp: int) -> int:
return int(value[2])
ds = env \
.from_collection(result_list,
type_info=Types.ROW_NAMED(["name", "url", "timestamp1", "random_num"],
[Types.STRING(), Types.STRING(), Types.INT(), Types.INT()])) \
.assign_timestamps_and_watermarks(
WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(myTimestampAssigner()))
class myAggregateFunction(AggregateFunction):
# 创建一个累加器,这就是为聚合创建了一个初始状态,每个聚 合任务只会调用一次。
def create_accumulator(self):
# 初始累加器,第一个是时间相加总和,第二个是时间个数的累加个数
return 0, 0
# 将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进 一步聚合的过程。
# 方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。
# 每条数据到来之后都会调用这个方法。
def add(self, value, accumulator):
# 两个返回, 一个是时间相加求和,第二个是数量相加求个数综合
return accumulator[0] + value.random_num, accumulator[1] + 1
# 从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态, 然后再基于这些聚合的状态计算出一个结果进行输出。
# 比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。
# 这个方法只在窗口要输出结果时调用。可能多次调用
def get_result(self, accumulator):
# 这块我们求的是均值
return str((accumulator[0] / accumulator[1]))
# 合并两个累加器,并将合并后的状态作为一个累加器返回。
# 这个方法只在 需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
# 这里没有涉及会话窗口,所以 merge()方法可以不做任何操作。但还是写下,基本就这意思。
def merge(self, acc_a, acc_b):
return acc_a[0] + acc_b[0], acc_a[1], acc_b[1]
result = ds.key_by(lambda x: x.name) \
.window(TumblingEventTimeWindows.of(Time.seconds(120))) \
.aggregate(myAggregateFunction(), accumulator_type=Types.TUPLE([Types.LONG(), Types.LONG()]),
output_type=Types.STRING())
result.print("agg:")
env.execute()
我们现在就2个用户,当我们key_by根据用户分组后,就2个分区,我们通过对random_num字段求和和统计个数,即可得到2个agg结果,由于我们没有记录用户名,但是也可以根据结果计算出来是哪个用户。
('zhao', 'baidu.com', 1678688382739, 1)
('zhao', 'baidu.com', 1678688384744, 3)
('wang', 'baidu.com', 1678688389750, 3)
('zhao', 'baidu.com', 1678688393761, 5)
('zhao', 'taobao.com', 1678688395764, 2)
('zhao', 'taobao.com', 1678688399771, 2)
('zhao', 'baidu.com', 1678688403785, 1)
('wang', 'taobao.com', 1678688405801, 1)
('zhao', 'baidu.com', 1678688408806, 2)
('wang', 'baidu.com', 1678688411811, 3)
create data success
agg:> 2.2857142857142856
agg:> 2.3333333333333335通过 ReduceFunction 和 AggregateFunction 我们可以发现,增量聚合函数其实就是在用流处理的思路来处理有界数据集,核心是保持一个聚合状态,当数据到来时不停地更新状态。这就是 Flink 所谓的“有状态的流处理”,通过这种方式可以极大地提高程序运行的效率,所以在实际应用中最为常见。
全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
很明显,这就是典型的批处理思路了——先攒数据,等一批都到齐了再正式启动处理流程。这样做毫无疑问是低效的:因为窗口全部的计算任务都积压在了要输出结果的那一瞬间,而在之前收集数据的漫长过程中却无所事事。这就好比平时不用功,到考试之前通宵抱佛脚,肯定不如把工夫花在日常积累上。
那为什么还需要有全窗口函数呢?这是因为有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。所以,我们还需要有更丰富的窗口计算方式,这就可以用全窗口函数来实现。
窗口函数(WindowFunction)
WindowFunction字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于WindowedStream 调用.apply()方法,传入一个 WindowFunction的实现类。
它就是将数据集合起来,然后统一计算,基本上跟所有的apply的用法一样。
代码就写个示例把,因为比较简单,而且这个基本不用了,WindowFunction的功能被ProcessWindowFunction覆盖了,可能下个版本就被弃用了。
from typing import Iterable
from pyflink.common import Time
from pyflink.datastream import StreamExecutionEnvironment, WindowFunction
from pyflink.datastream.functions import KEY, W, IN, OUT
from pyflink.datastream.window import TumblingEventTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection(
collection=[(1, 'aaa@bb'), (2, 'bb@a'), (3, 'aaa@a')])
class myWindowFunction(WindowFunction):
def apply(self, key: KEY, window: W, inputs: Iterable[IN]) -> Iterable[OUT]:
pass
data_stream.key_by(lambda x: x[0]).window(TumblingEventTimeWindows.of(Time.seconds(120))).apply(myWindowFunction())处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processingtime)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上, ProcessWindowFunction 是 Flink 底层API——处理函数(process function)中的一员
当然,这些好 处是以牺 牲性 能和资 源为代价 的。 作为一 个全窗口 函数ProcessWindowFunction 同样需要将所有数据缓存下来、等到窗口触发计算时才使用它.其实就是一个增强版WindowFunction。
具体使用跟 WindowFunction 非常类似,我们可以基于 WindowedStream调用.process()方法,传入一个 ProcessWindowFunction 的实现类。下面是一个电商网站统计每小时 UV 的例子
"""
desc:
# -*- coding: utf-8 -*-
@Project: python_workspace
@File: window_process.py
@Author: xinjian.yu
@Time: 2023/3/13 15:49
"""
import random
import time, datetime
from typing import Any, Iterable
from pyflink.common import Types, WatermarkStrategy, Time
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction, ProcessWindowFunction
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import TumblingEventTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
name_list = ["wang", "zhao", "yu", "li", "tian"]
url_list = ["baidu.com", "taobao.com", "google.com"]
result_list = []
for num in range(10):
result_tuple = (
random.choice(name_list), random.choice(url_list), '{0:%Y-%m-%d %X}'.format(datetime.datetime.now()),
int(round(time.time() * 1000)), random.randint(1, 5))
print(result_tuple)
result_list.append(result_tuple)
time.sleep(random.randint(1, 3))
print("create data success")
class myTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value: Any, record_timestamp: int) -> int:
return int(value[3])
ds = env \
.from_collection(result_list,
type_info=Types.ROW_NAMED(["name", "url", 'now_time_str', "timestamp1", "random_num"],
[Types.STRING(), Types.STRING(), Types.STRING(), Types.INT(),
Types.INT()])) \
.assign_timestamps_and_watermarks(
WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(myTimestampAssigner()))
class myProcessWindowFunction(ProcessWindowFunction):
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
dis_list = []
for un in elements:
dis_list.append(un.name)
# 去重
uv_value = len(list(set(dis_list)))
context.current_watermark()
# 返回的是一个迭代器,所以不能直接return返回。
yield "Window: {} ,process_time:{}, count: {},data : {},dis_data : {}".format(
context.window(),
context.current_processing_time(),
uv_value, str(dis_list),
str(list(set(dis_list))))
# 将所有的数据集中在一个分区内
result = ds.key_by(lambda x: "key") \
.window(TumblingEventTimeWindows.of(Time.seconds(5))) \
.process(myProcessWindowFunction())
result.print("process:")
env.execute()
我们是通过事件时间来,滚动窗口,每个5秒统计该窗口范围内的uv值.
PS:这里简单说下,在java里 context.window().getStart()和getEnd()可以直接打印事件的开始和结束时间,但是在python里就没这两个方法,在api里我也没找到,但是在1.18版本里会添加context.window().start和end方法,来获取时间。
现在就只能在TimeWindow(start=-635265000, end=-635260000) 这个也能看到开始和结束时间,当作参考把。
('zhao', 'google.com', '2023-03-13 16:42:29', 1678696949245, 5)
('zhao', 'taobao.com', '2023-03-13 16:42:32', 1678696952246, 2)
('zhao', 'google.com', '2023-03-13 16:42:35', 1678696955252, 4)
('yu', 'baidu.com', '2023-03-13 16:42:36', 1678696956263, 2)
('yu', 'taobao.com', '2023-03-13 16:42:38', 1678696958263, 1)
('tian', 'google.com', '2023-03-13 16:42:40', 1678696960273, 1)
('wang', 'taobao.com', '2023-03-13 16:42:41', 1678696961286, 5)
('wang', 'google.com', '2023-03-13 16:42:42', 1678696962299, 5)
('zhao', 'taobao.com', '2023-03-13 16:42:43', 1678696963311, 1)
('zhao', 'baidu.com', '2023-03-13 16:42:44', 1678696964320, 4)
create data success
process:> Window: TimeWindow(start=-635265000, end=-635260000) ,process_time:1678696971667, count: 1,data : ['zhao', 'zhao'],dis_data : ['zhao']
process:> Window: TimeWindow(start=-635260000, end=-635255000) ,process_time:1678696971668, count: 2,data : ['zhao', 'yu'],dis_data : ['yu', 'zhao']
process:> Window: TimeWindow(start=-635255000, end=-635250000) ,process_time:1678696971668, count: 3,data : ['yu', 'tian', 'wang', 'wang'],dis_data : ['tian', 'wang', 'yu']
process:> Window: TimeWindow(start=-635250000, end=-635245000) ,process_time:1678696971668, count: 1,data : ['zhao', 'zhao'],dis_data : ['zhao']当然,这里我 们并没有用到上下文中其他信息,所以其 实没有必要使用ProcessWindowFunction。全窗口函数因为运行效率较低,很少直接单独使用,往往会和增量聚合函数结合在一起,共同实现窗口的处理计算。
增量聚合和全窗口函数的结合使用
增量聚合函数处理计算会更高效。举一个最简单的例子,对一组数据求和。大量的数据连续不断到来,全窗口函数只是把它们收集缓存起来,并没有处理;到了窗口要关闭、输出结果的时候,再遍历所有数据依次叠加,得到最终结果。而如果我们采用增量聚合的方式,那么只需要保存一个当前和的状态,每个数据到来时就会做一次加法,更新状态;到了要输出结果的时候,只要将当前状态直接拿出来就可以了。增量聚合相当于把计算量“均摊”到了窗口收集数据的过程中,自然就会比全窗口聚合更加高效、输出更加实时。
而全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。它只负责收集数据、提供上下文相关信息,把所有的原材料都准备好,至于拿来做什么我们完全可以任意发挥。这就使得窗口计算更加灵活,功能更加强大。
简单的说,就是AggregateFunction来收集信息,将收集后的信息(按时间分窗口),发给ProcessWindowFunction函数来处理,大致就是这个意思。
所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的Window API 就给我们实现了这样的用法。
下面统计name出现的次数,在AggregateFunction-add里面 只有累加器,出现一次加一次,将结果(也就是get_result方法)传递给ProcessWindowFunction-process方法进行打印处理,在process想怎么弄就怎么弄,大致是这个意思。
ps:这块的数据最好是流,比如kafka之类的,像我这样 有界流数据其实效果不怎么好,但是意思明白就行。
import datetime
import random
import time
from typing import Any, Iterable
from pyflink.common import Types, WatermarkStrategy, Time
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction, ProcessWindowFunction
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import TumblingEventTimeWindows
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
name_list = ["wang", "zhao", "yu", "li", "tian"]
url_list = ["baidu.com", "taobao.com", "google.com"]
result_list = []
for num in range(20):
result_tuple = (
random.choice(name_list), random.choice(url_list), '{0:%Y-%m-%d %X}'.format(datetime.datetime.now()),
int(round(time.time() * 1000)), random.randint(1, 5))
print(result_tuple)
result_list.append(result_tuple)
time.sleep(random.randint(1, 3))
print("create data success")
class myTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value: Any, record_timestamp: int) -> int:
return int(value[3])
class myAggregateFunction(AggregateFunction):
def create_accumulator(self):
return "", 0
def add(self, value, accumulator):
return accumulator[0] + "_" + value[0], accumulator[1] + 1
#只负责将数据传递出去 不计算。
def get_result(self, accumulator):
return accumulator
def merge(self, acc_a, acc_b):
return None
class myProcessWindowFunction(ProcessWindowFunction):
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
for em in elements:
yield "Window: {} , count: {}".format(
context.window(),
em)
ds = env \
.from_collection(result_list,
type_info=Types.ROW_NAMED(["name", "url", 'now_time_str', "timestamp1", "random_num"],
[Types.STRING(), Types.STRING(), Types.STRING(), Types.INT(),
Types.INT()])) \
.assign_timestamps_and_watermarks(
WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(myTimestampAssigner()))
result = ds.key_by(lambda x: x.name) \
.window(TumblingEventTimeWindows.of(Time.seconds(3))) \
#同时传递2个class
.aggregate(myAggregateFunction(), myProcessWindowFunction())
result.print("agg+process:")
env.execute()