调优C / C ++编译器以在多核应用程序中获得最佳并行性能:第一部分
领取嵌入式物联网学习路线对于希望通过多核设计中的多线程或分区利用并行性的而言,重要的第一步是提高应用程序的标量性能。
更好,更轻松的方法之一是应用积极的编译器优化。面向您的处理器并具有高级优化功能(例如自动矢量化,过程间优化和配置文件引导的优化)的编译器可以极大地提高应用程序的性能。
并应用编译器的可用性功能(如帮助兼容性,编译时间和代码大小的功能)可以大大提高开发效率。
为什么标量优化如此重要?
并行优化的绝对前提是高度可调的标量性能。为什么这个说法是正确的?要了解为什么会这样,请考虑一个具有以下要求的假设性能优化项目:并行优化必须比应用程序的标量版本提高30%的性能。
创建了一个开发团队M,以开发应用程序原型,该应用程序采用并行优化和多核处理器来满足性能要求。创建了另一个团队Team S,以查看多少标量优化技术可以提高性能。每个团队都将其改进作为原型,并获得性能比较。
下面的图5.1 是不同团队获得的绩效的图形表示。如您所见,M组的性能比原始代码提高了43%。S小组的性能比原始代码提高了11%。问题“ M团队是否达到了目标?
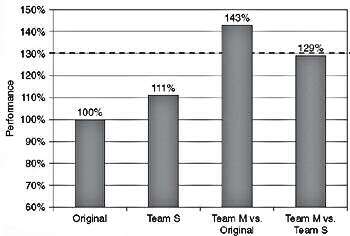
图5.1:假设标量与并行性能的改进
图中的最后一列显示了将Team M的结果与Team S进行比较后的性能提高,这可以视为应用程序的新标量版本。
严格来说,M队没有达到目标。M团队和新标量版本(S团队)之间的性能差异仅为29%。现在可以争论的是,在指定应使用代码的原始版本进行性能比较时,目标应该已经很清楚了,但现实是我们正在讨论最终结果。
如果可以以最小的努力完成标量优化工作,并且并行优化工作需要大量资源,则可以终止并行优化工作。如果M团队了解标量优化所提供的性能余量,那么M团队可能已经在更多应用程序中应用了并行技术来满足性能目标。
编译的重要性
C和C ++编译器广泛用于嵌入式软件开发[1]。编译器优化可以在提高应用程序性能方面发挥重要作用,采用专门针对您的处理器的最新编译器技术可以提供更大的收益。
下面的图5.2 是 在Intel Pentium M处理器系统上执行SPEC CINT2000 [1]的两种不同的编译器和几种优化设置的比较。所采用的两种编译器标记为“ COMP1 ”和“COMP2”,分别[2] 。
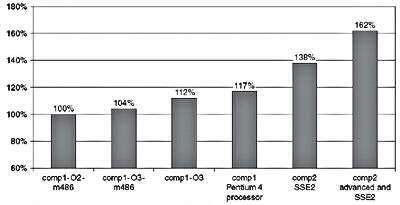
图5.2:编译器和目标体系结构比较
comp1编译基准时,采用了四个不同的优化设置。当comp2编译基准测试时,使用了两个不同的优化设置。以Intel 486处理器为目标的编译器comp1充当基线,并在图形的最左侧显示。
将comp1与-O3 选项一起使用并针对Intel486处理器可将性能提高4%。该-O3 选项提供了默认优化设置更大的优化。将comp1与-O3 选项及其默认的编译器处理器目标一起使用可以使性能提高12%。将comp1与Intel Pentium 4处理器的处理器目标结合使用可将性能提高17%。
使用第二个编译器comp2并以奔腾M处理器为目标可将性能提高38%。最后,使用针对奔腾M处理器的comp2和先进的优化技术可将性能提高62%。
基准编译器和选项设置(comp1以Intel486处理器为目标)代表使用旧式编译工具并以旧处理器为目标的旧应用程序,而仅依靠新处理器来提高应用程序性能。
以奔腾M处理器为目标并使用高级优化功能的comp2代表具有最新优化技术和优化功能的编译器,该技术专门针对用于在现场执行应用程序的处理器。在这两个系列的后续部分中,将更全面地解释诸如高级优化和处理器目标之类的术语。但是从这些数据中应该清楚两点:
1)尚未针对新的处理器目标进行重新编译的旧版应用程序可能会牺牲性能;和
2)使用专门针对您的体系结构进行调整的高性能编译器可以带来很大的性能改进。
对于使用C和C ++的开发人员,了解他们各自的编译器中可用的性能功能至关重要。本章描述了许多C和C ++编译器中可用的性能功能,这些功能的优点以及如何使用它们。
在这两篇文章的第1部分中,我将详细介绍一些C和C ++编译器的性能功能,例如常规优化,高级优化和用户控制的优化。接下来,在第2部分中,我将详细介绍优化应用程序时要使用的过程,并讨论有助于提高兼容性的可用性功能,以及减少编译时间和减少代码大小的方法。借助这些技术,领取嵌入式物联网学习路线可以轻松地从其应用程序中获得更高的性能。
编译器优化
编译器通过分析源代码并确定源代码以机器语言表示的方式进行优化,以尽可能有效地执行。编译器优化可以分为一般优化和高级优化:
1)常规优化包括与体系结构无关和与体系结构相关的优化。
2)高级优化是专门的,并且在非常特定的代码类型上显示出最大的好处。
一般优化 。常规优化包括与体系结构无关和与体系结构相关的优化。与体系结构无关的优化不依赖于基础体系结构的知识。无论代码将在什么平台上执行,这些都是适用的好技术。
与体系结构无关的优化示例包括死代码消除,公共子表达式消除和循环不变代码运动。下面的图5.3 显示了编译器可以执行以下优化以产生更高性能的代码的代码:
消除死代码: 可以优化第6行和第7行,因为可以证明第6行的if语句总是错误的,从而保证了第7行永远不会执行。
循环不变的代码运动: 第9行的比较可以移出循环,因为y的值不受循环中其他任何因素的影响。
公共子表达式消除: 可以共享第10行 中 a [i]的两个引用的指针计算。

图5.3:常规优化代码示例
与体系结构相关的优化包括寄存器分配和指令调度。需要一个微处理器体系结构的详细知识,才能创建一个与体系结构相关的良好优化器。寄存器分配是编译器功能,可确定在处理器中将变量加载到何处进行计算。
x86 ISA只有八个通用寄存器,因此可以同时进行的活动计算数量受到一定程度的限制。指令调度是基于内部处理器约束和程序依赖性对机器语言代码的排序。寄存器分配和指令调度都是编译器编写者和汇编语言程序员的领域。
通常,将常规优化的组合捆绑在几个编译器选项下。下表5.1 总结了可用于优化应用程序的许多编译器中可用的各种常规优化。
选项-O2 是很好的基本优化标志,并且是某些编译器中的默认优化设置。该-O3 选项采用更积极的优化,可以提高性能,但在应用程序代码大小或编译时间方面可能花费更多。将这些常规优化选项视为应用程序性能调整的第一步。
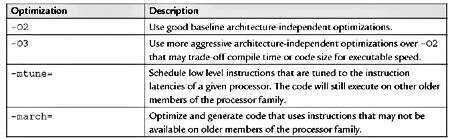
表5.1:常规优化选项的说明
所述-mtune = 选项时间表指示根据指定的基于处理器的。例如,要为奔腾M处理器安排指令,可以使用-mtune = pentium-m。在与指定的体系结构不同的体系结构上,此选项可能会导致性能降低。
所述-march = 选项时考虑一个特定的处理器生成的代码。此选项自动将-mtune = 设置为相同的处理器,此外,它可能会使用较旧的处理器不支持的指令。
例如,-mtune = Prescott 选项可以选择不会在不支持SSE3的处理器(如奔腾III处理器)上执行的SSE3指令。 如果大多数目标系统是特定的处理器目标,请考虑-mtune =选项。 如果所有目标系统都具有与指定处理器等效的功能,请考虑-march =选项。
高级优化
一些优化利用了处理器中的最新技术,并且/或者需要开发人员付出更多的努力才能使用。术语“高级优化”用于统称这些编译器功能。下一节将介绍三种高级优化:自动矢量化,过程间优化和配置文件引导的优化 。
自动矢量化 。一些处理器已经扩展了其指令集,以允许访问处理器中的新功能,例如数据预取和并行执行。例如,嵌入式英特尔架构处理器提供了一组指令扩展,称为MMX技术,SSE,SSE2,SSE3,SSSE3和SSE4。
对于C和C ++等高级语言,编译器技术提供了通往这些新指令的门户。在您的应用程序中采用这些说明的方法可能包括:
1)编写内联汇编语言以明确指定新指令
2)使用C内部库或C ++类库,可以访问更高级的语言指令
3)使用自动矢量化技术自动生成新指令
自动矢量化技术使编译器能够分析您的C和C ++源代码,以确定可以在何处使用这些指令来加速代码。执行矢量化的编译器会分析循环,并确定何时可以安全地并行执行循环的多次迭代。

图5.4:矢量化示例” C源代码和所得汇编代码
上面的图5.4 是一个C源代码示例,以及使用Intel C ++编译器使用自动矢量化编译代码时得到的x86汇编语言。矢量化器能够利用SSE2指令,并对循环进行转换,以便每次迭代计算a [i]的两个结果,而不是源代码指定的一个结果。
过程间优化编译器通常一次处理一个功能,并且与程序中的其他功能隔离。在优化期间,由于其他函数中可能出现的副作用,编译器通常必须对程序中的值做出保守的假设,从而限制了优化的机会。
使用具有过程间优化的编译器可以在了解应用程序中其他功能的详细知识的情况下优化每个功能。过程间优化支持其他优化;由于增强了过程间信息,因此这些其他优化更为激进。过程间优化支持的典型优化示例包括:
内联 :无需任何用户指导即可内联功能的功能。
寄存器中的参数: 函数参数可以在寄存器中而不是在堆栈中传递,这可以减少调用/返回开销。
过程间常量传播: 通过函数调用传播常量参数。
循环不变的代码运动: 更好的编译器分析信息可以增加可以安全地移出循环主体的代码量。
消除无效代码: 更好的全局信息可以增加对无法证明的代码的检测。
下面的图5.5 是可以通过过程间优化有效地优化的代码示例。领取嵌入式物联网学习路线

图5.5:过程间优化代码示例
在上面的图5.5中的示例中 ,由于以下原因,可以优化函数check()中 的整个循环主体:
1)过程间常数传播会将参数传播到第10行的被调用函数,该函数在函数check()中是恒定的 。
2)循环不变的代码运动将认识到第3行的if语句不依赖于循环。
3)死代码消除将在第3行的if语句的真实条件下消除代码,因为变量debug是一个常数,零。
配置文件引导的优化 。概要文件引导的优化使编译器可以从经验中学习。配置文件引导的优化过程分为三个阶段:
阶段1: 编译软件以生成配置文件。编译器将工具插入已编译的代码中,从而能够记录有关代码在执行时的行为的度量。
第2阶段: 执行应用程序以收集一个概要文件,该概要文件包含所谓的应用程序“训练运行”的特征。
第3阶段:重新 编译应用程序以利用配置文件或在培训运行过程中从应用程序中学到的知识。
编译器现在知道程序中执行最频繁的路径在哪里,并且可以将优化的优先级放在这些区域。在典型的编译器中,由配置文件引导的优化启用的几种优化的说明如下:
函数排序: 通过将经常执行的函数放在一起,提高指令缓存命中率。
切换语句优化: 优化switch语句中最常执行的情况,使其最先发生。
基本块排序。。 通过将频繁执行的块放在一起提高指令高速缓存命中率。
改进了寄存器分配。。 在代码的最高执行区域为计算提供最佳的寄存器分配。
高级优化选项 。上面的表5.2列出了在多个编译器中启用高级优化的选项。在 GNU GCC 4.1版采用了先进的优化。使用 -ftree-vectorize 选项启用自动矢量化。
常规的过程间优化不可用。但是,-wholeprogram 和Combine options启用了一些过程间优化 。通过-fprofile-generate 选项用于配置文件生成,以及使用“ profile-use 选项”用于配置文件使用阶段来启用配置文件引导的优化。
Microsoft Visual C ++编译器当前不支持自动矢量化。使用/ GL 选项进行编译并使用/ LTCG 选项在链接时启用过程间优化。配置文件引导的优化通过/ GL 选项启用进行编译,并与/ LTCG:PGI链接以 进行配置文件生成,与/ LTCG:PGO链接 以进行配置文件应用。
用于Linux的英特尔C ++编译器通过-x proc 选项启用自动矢量化,其中proc 指定多个处理器目标之一。使用 编译命令行和链接命令行上的-ipo选项可以启用过程间优化。使用-prof-gen 选项(用于配置文件生成)和-prof-use 选项(用于配置文件应用程序)启用配置文件引导的优化。
上面为每个编译器列出的选项在它们之间并不完全等效。例如,gcc选项-ftree-vectorize 仅启用自动矢量化;例如,但是,英特尔C ++编译器选项-xproc 启用了自动矢量化并以指定的处理器为目标,因此可以启用其他优化,例如针对该处理器目标的软件预取和指令调度。
阅读您的编译器文档以了解编译器高级优化所提供的功能以及任何特殊要求。最后,在比较每个编译器的高级优化功能时,要记住最终的价值是应用程序性能,这意味着可能有必要构建和衡量从每个编译器及其高级优化中获得的性能。
帮助优化
在以下情况下,开发人员可以协助编译器优化:在对代码进行假设,代码在内存中的布局方式以及开发人员对代码的运行时行为有先验知识的情况下限制编译器。
在这些情况下,对这些问题以及如何有效地将优化信息传达给编译器的仔细了解可能会对性能产生重大影响。
开发人员可以协助编译器的第一个领域涉及指针的使用和别名问题,这些问题可能会限制优化。当两个指针引用相同的对象时,会发生混淆。在存在别名的情况下,编译器的假设和优化必须保守。
上面的图5.6显示了一种情况,编译器无法假定a 和b 指向内存的不同区域,必须保守地优化或添加指针的运行时边界检查。
在这种情况下,编译器甚至可以选择不进行向量化。通过向编译器提供有关函数中引用的指针的更多信息,可以解决图5.6中突出显示的问题。可使用多种技术来协助编译器进行别名分析,概述如下:
Restrict : C99 定义了strict关键字,该关键字使开发人员可以指定不指向内存相同区域的指针。
数组符号: 使用数组符号(例如 a [i]和 b [i]) 有助于表示内存的引用区域。
过程间优化: 可以进行更大的别名分析,并且可以使编译器证明某些指针未指向同一区域。
下面的图5.7中的限制代码示例 基于图5.6中的代码,并添加了strict关键字的使用,以允许编译器消除a 和b的歧义, 并在运行时使用循环的矢量化版本。
图5.7还包括使用杂注#pragma vectoraligned,它将数据布局信息传达给编译器。如果保证数据在特定的存储器边界上对齐,则某些体系结构包含的指令执行速度会更快。
正确使用编译指示将知识传达给编译器可以带来一些好处,如下面的表5.3所示 。有关正确的语法和用法,请参考编译器的参考手册。
开发人员可以帮助编译器的最后一个领域是应用程序使用的数据结构的内存布局。现代体系结构具有包含多层缓存的内存层次结构。有效使用内存层次结构涉及尝试使访问的数据在时间和空间上在连续区域中非常紧密地保持在一起。优化缓存的技术很多。但是,一些重要的问题总结为:
1)数据布局
2)数据对齐
3)预取
数据布局可帮助数据结构更有效地适合缓存。考虑下面的图5.8中的结构声明。
假设SIZE 的值 定义为1。 在许多编译器中,soa的大小为24个字节,因为编译器将在f,z 和v之后填充三个字节 。 在许多编译器中,soa2的大小为16个字节,大小减少了33%。对结构中的数据声明进行排序,以最大程度地减少不必要的填充。
数据对齐是一种使用有用的填充以允许有效访问数据的技术。再次考虑图5.8中的声明,其中这次SIZE 被定义为一个较大的数字,例如100,000。无法保证数组a,b和c 在16字节边界上对齐,如果对访问数据的循环进行矢量化处理,则这将阻止采用更快版本的SSE指令。
例如,如果 使用SSE指令对下面的图5.9中详细说明的for循环进行矢量化处理,则将对数据执行未对齐的加载,这些数据的效率要低于对齐的对应数据。如果 在代码中用soa2 代替soa,则将使用对齐的负载。
预取是优化内存访问的第二种技术。预取的目的是在应用程序引用数据之前立即请求将其放置在缓存中。
现代处理器具有预取数据的软件指令和自动预取功能。自动预取是一种处理器功能,可以分析内存引用流,尝试预测将来的访问并将预测的内存访问放置在缓存中。
自动预取有助于定期访问数据的应用程序,如果数据访问不规则,则可能会损害性能。在某些情况下,关闭处理器上的自动预取可能会有所帮助。几个BIOS程序可以设置自动预取。如果您的应用程序对数据具有不规则的非随机访问权限,则有必要关闭自动预取功能以查看它是否可以提高性能。嵌入式开发工程师