BiFPN---加权双向特征金字塔网络(附代码)
前言
目前大多数的检测网络都喜欢用卷积神经网络逐层抽象,提取多个层次的特征。高层次网络感受野大,语义信息表征能力强,但特征图分辨率比较低,空间几何特征缺乏;低层次网络虽然感受野小,语义信息表达能力也较弱,但特征图分辨率大,空间几何细节充分。所以对各层次特征进行融合,对最后的检测网络比较有利。
要解决的问题
自FPN诞生以来,FPN已被广泛用于多尺度特征融合。近年来,PANet、NAS-FPN等研究发展了更多跨尺度特征融合的网络结构。以往的工作在融合不同输入特征的同时,大多是简单的总结,没有区别;然而,由于这些不同的输入特征具有不同的分辨率,本文观察到它们对融合输出特征的贡献通常是不均匀的。为了解决这一问题,提出了一种简单而高效的加权双向特征金字塔网络(BiFPN),该网络引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自底向上的多尺度特征融合。
具体来说:
FPN:由于升降维度导致的信息损失问题,这在很多多尺度特征融合方法都存在,AugFPN通过引入一致性监督的方法,在特征金字塔的每一层引入一致性损失,使得不同尺度的特征能够保持一致性,从而提高了模型性能。同时FPN只有自顶向下的过程,就很难把低层信息传递到最后一层。
PANet:相比于FPN,PANet多了一个自底向上的传递,让图像的低层信息也能得到冲分的利用,但是BiFPN认为PANet中的单节点能够获取的信息并不多,却增加了模型的参数,是一个弊大于利的操作
NAS-FPN:NAS-FPN在FPN的设计上进行了优化,通过引入更多的新层来增强模型的性能。但是融合输出特征的贡献通常是不均匀的。BiFPN引入可学习的权值来学习不同输入特征的重要性。
BiFPN
作者是对PANet提出了三种优化思路:
1.若一个结点只有一个输入,且不存在特征融合,那么它对整体的特征网络贡献比较小,可以将其切除,所以由PANet得到如下简化结构:

2.如果原始输入与输出节点处于同一级别,则在原始输入和输出节点之间添加一条额外的边,以便在不增加成本的情况下融合更多功能。

3. 可以将每一个双向路径(top-down + down-top)视为一个特征网络层,并且重复多次,以启用更高级别的特征融合。

关于加权
在特征融合过程中,因为分辨率不同,所以需要Resize,但是因为不同的特征输入分辨率不同,对最终特征网络的输出贡献也应该会有所差异,所以需要让网络去学习这个weights,作者提出三种方案:
1. 一般的加权特征融合
![]()
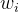 可能是基于每个特征的标量,也可能是针对每个channel的向量,异或是对每一个像素的多维张量。
可能是基于每个特征的标量,也可能是针对每个channel的向量,异或是对每一个像素的多维张量。
缺陷:由于 不加约束,会导致训练过程中的不稳定,难以收敛。
2.基于softmax的特征融合(将所有的权重归一化到0-1之间)
![]()
缺陷:会导致训练速度明显变慢(个人估计可能是大量的指数运算导致的)
3.快速归一化特征融合
![]()
>=0通过Relu来保证,  =0.0001确保数值的稳定。 因为避免了Softmax操作,训练速度大幅度提高。
=0.0001确保数值的稳定。 因为避免了Softmax操作,训练速度大幅度提高。
所以基于双向跨尺度连接和快速归一化特征融合,形成最终的加权双向特征金字塔网络
代码部分:
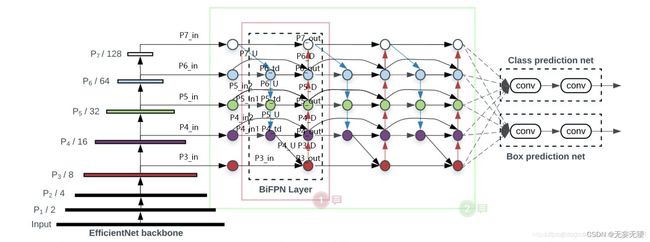
1.获得的输入特征p3,p4,p5,进行两次下采样得到p6,p7。之后在经过1*1卷积调整通道后,得到p3
_in,p4_in,p5_in,p6_in,p7_in

对应代码:
p3_in = self.p3_down_channel(p3)
p4_in_1 = self.p4_down_channel(p4)
p5_in_1 = self.p5_down_channel(p5)
p4_in_2 = self.p4_down_channel_2(p4)
p5_in_2 = self.p5_down_channel_2(p5)
p6_in = self.p5_to_p6(p5)
p7_in = self.p6_to_p7(p6_in)
2、在获得P3_ in. P4_ _in_ _1、P4_ _in_ 2、P5_ in. _1、P5_ _in_ _2、P6_ in. P7_ _in之后需要对P7_ _in进行上采样,上采样后与P6_ in堆叠获得P6_ td; 之后对P6_ _td进行上采样,上采样后与P5_ _in _1进行堆叠获得P5_ td; 之后对P5_ td进行上采样,上采样后与P4_ in. _1进行堆叠获得P4_ td;之后对P4_ _td进行上采样,上采样后与P3_ _in进行堆叠获得P3_ out.

代码实现:
# 简单的注意力机制,用于确定更关注p7_in还是p6_in
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
p6_up = self.conv6_up(self.swish(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in)))
# 简单的注意力机制,用于确定更关注p6_up还是p5_in
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
p5_up = self.conv5_up(self.swish(weight[0] * p5_in_1 + weight[1] * self.p5_upsample(p6_up)))
# 简单的注意力机制,用于确定更关注p5_up还是p4_in
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
p4_up = self.conv4_up(self.swish(weight[0] * p4_in_1 + weight[1] * self.p4_upsample(p5_up)))
# 简单的注意力机制,用于确定更关注p4_up还是p3_in
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
p3_out = self.conv3_up(self.swish(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up)))
3、在获得P3_ _out. P4_ td. P4_ _in_ _2、P5_ _td、 P5_ in_ 2. P6_ _in、 P6_ _td. P7_ in之后,之后需要对P3_ out进行下采样,下采样后与P4_ td. P4_ in_ 2堆叠获得P4_ _out; 之后对P4_ _out进行下采样,下采样后与P5_ _td、 P5_ in_ 2进行堆叠获得P5_ _out; 之后对P5_ _out进行下采样,下采样后与P6_ in. P6_ _td进行堆叠获得P6_ _out; 之后对P6_ _out进行下采样,下采样后与P7_ _in进行堆叠获得P7_ out。

代码实现:
# 简单的注意力机制,用于确定更关注p4_in_2还是p4_up还是p3_out
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.swish(weight[0] * p4_in_2 + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out)))
# 简单的注意力机制,用于确定更关注p5_in_2还是p5_up还是p4_out
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
p5_out = self.conv5_down(
self.swish(weight[0] * p5_in_2 + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out)))
# 简单的注意力机制,用于确定更关注p6_in还是p6_up还是p5_out
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
p6_out = self.conv6_down(
self.swish(weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out)))
# 简单的注意力机制,用于确定更关注p7_in还是p7_up还是p6_out
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
p7_out = self.conv7_down(self.swish(weight[0] * p7_in + weight[1] * self.p7_downsamp
4、将获得的P3_ _out、 P4_ _out、 P5_ _out、 P6_ _out、 P7_ _out作为P3_ in. P4_ in. P5_ _in、 P6_ _in. P7_ in,复2、3步骤进行堆叠即可,对于fricientdet B0来讲,还需要重复2次,需要注意P4_ _in_ .1和P4_ _in_ 2此时不需要分开了,P5也是。

代码实现:
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
# 简单的注意力机制,用于确定更关注p7_in还是p6_in
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
p6_up = self.conv6_up(self.swish(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in)))
# 简单的注意力机制,用于确定更关注p6_up还是p5_in
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
p5_up = self.conv5_up(self.swish(weight[0] * p5_in + weight[1] * self.p5_upsample(p6_up)))
# 简单的注意力机制,用于确定更关注p5_up还是p4_in
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
p4_up = self.conv4_up(self.swish(weight[0] * p4_in + weight[1] * self.p4_upsample(p5_up)))
# 简单的注意力机制,用于确定更关注p4_up还是p3_in
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
p3_out = self.conv3_up(self.swish(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up)))
# 简单的注意力机制,用于确定更关注p4_in还是p4_up还是p3_out
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.swish(weight[0] * p4_in + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out)))
# 简单的注意力机制,用于确定更关注p5_in还是p5_up还是p4_out
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
p5_out = self.conv5_down(
self.swish(weight[0] * p5_in + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out)))
# 简单的注意力机制,用于确定更关注p6_in还是p6_up还是p5_out
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
p6_out = self.conv6_down(
self.swish(weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out)))
# 简单的注意力机制,用于确定更关注p7_in还是p7_up还是p6_out
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
p7_out = self.conv7_down(self.swish(weight[0] * p7_in + weight[1] * self.p7_downsample(p6_out)))
代码地址:bubbliiiing
参考:Pytorch搭建Efficientdet目标检测平台
EfficientDet论文和代码解析
【读点论文】EfficientDet: Scalable and Efficient Object Detection,改进特征融合层,BiFPN双向融合特征便于框信息回归,类别分类