大数据系列之Spark集群环境部署
Spark作为一种大数据分布式计算框架,已经构建Spark Streaming、Spark SQL、Spark ML等组件,与文件系统HDFS、资源调度YARN一起,构建了Spark生态体系,如下图所示:
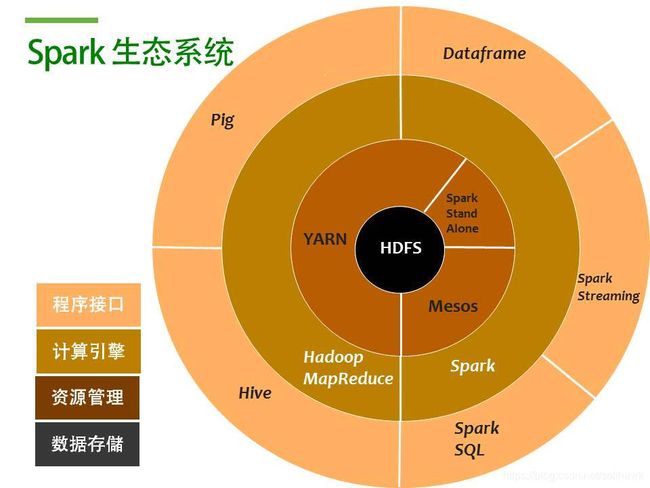
以下部分将主要介绍Hadoop和Spark两节点集群环境部署,并结合官方示例程序验证Spark作业提交的几种模式。
1、环境准备
1.1 Java环境
查看Java版本信息,如找不到JAVA命令,可通过yum install Java安装最新Java版本
[root@tango-spark01 local]# java -version
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
1)配置jps
Centos中使用yum安装java时,没有jps命令,安装安装java-1.X.X-openjdk-devel这个包
[root@tango-spark02 hadoop]# yum install java-1.8.0-openjdk-devel.x86_64
2)配置JAVA_HOME
通过yum install java,安装openjdk。安装后,执行echo $JAVA_HOME发现返回为空。说明JAVA_HOME没有配置,需要到/etc/profile中配置JAVA_HOME
[root@tango-spark01 etc]# which java
/bin/java
[root@tango-spark01 etc]# ls -lrt /bin/java
lrwxrwxrwx. 1 root root 22 May 24 16:08 /bin/java -> /etc/alternatives/java
[root@tango-spark01 etc]# ls -lrt /etc/alternatives/java
lrwxrwxrwx. 1 root root 73 May 24 16:08 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64/jre/bin/java
3)在/etc/profile.d目录下新建custom.sh文件,并添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
动态生效:
[root@tango-spark01 etc]# source /etc/profile
查看PATH是否生效:
[root@tango-spark01 profile.d]# echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
1.2 关闭防火墙
不同系统之间相互访问需要关闭防火墙,具体如下:
[root@tango-spark01 hadoop-2.9.0]# firewall-cmd --state
running
[root@tango-spark01 hadoop-2.9.0]# systemctl stop firewalld.service
[root@tango-spark01 hadoop-2.9.0]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@tango-spark01 hadoop-2.9.0]# firewall-cmd --state
not running
[root@tango-spark01 hadoop-2.9.0]#
1.3 配置主机名和IP地址对应关系
修改/etc/hosts文件,配置主机hostname和ip对应关系:
[root@tango-spark01 etc]# vi hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.112.121 tango-spark01
192.168.112.122 tango-spark02
[root@tango-spark02 etc]# vi hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.112.121 tango-spark01
192.168.112.122 tango-spark02
1.4 服务器配置说明
Spark集群环境服务器使用tango-spark01和tango-spark02两台虚机环境,其中一台作为namenode主节点、另一台作为DataNode从节点,如下所示:
| 主机名 | IP | 节点 |
|---|---|---|
| tango-spark01 | 192.168.112.121 | NameNode |
| tango-spark01 | 192.168.112.121 | Journalnode |
| tango-spark01 | 192.168.112.121 | ResourceManager |
| tango-spark01 | 192.168.112.121 | JobHistory Server |
| tango-spark01 | 192.168.112.121 | Master |
| tango-spark01 | 192.168.112.121 | Driver |
| tango-spark01 | 192.168.112.121 | History Server |
| tango-spark02 | 192.168.112.122 | DataNode |
| tango-spark02 | 192.168.112.122 | NodeManager |
| tango-spark02 | 192.168.112.122 | Worker |
2、配置Hadoop分布式集群
2.1 安装Hadoop软件
解压安装包到指定目录:
[root@tango-spark01 src-install]# tar -xzvf hadoop-2.9.0.tar.gz -C /usr/local/spark
2.2 配置环境变量
为了方便我们以后开机之后可以立刻使用到Hadoop的bin目录下的相关命令,可以把hadoop文件夹下的bin和sbin目录配置到/etc/profile.d/custom.sh文件中,添加:
export HADOOP_HOME=/usr/local/spark/hadoop-2.9.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
动态生效并查看生效:
[root@tango-spark01 etc]# source /etc/profile
[root@tango-spark01 hadoop-2.9.0]# echo $PATH
查看Hadoop信息:
[root@tango-spark01 hadoop-2.9.0]# hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/spark/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
2.3 建立以下目录
在Hadoop目录下创建以下目录:
[root@tango-spark01 hadoop-2.9.0]# mkdir tmp
[root@tango-spark01 hadoop-2.9.0]# mkdir hdfs
[root@tango-spark01 hadoop-2.9.0]# cd hdfs
[root@tango-spark01 hdfs]# mkdir data
[root@tango-spark01 hdfs]# mkdir name
[root@tango-spark01 hdfs]# ls
data name
[root@tango-spark01 hdfs]#
- a) 目录/tmp,用来存储临时生成的文件
- b) 目录/hdfs,用来存储集群数据
- c) 目录hdfs/data,用来存储真正的数据
- d) 目录hdfs/name,用来存储文件系统元数据
2.4 配置Hadoop文件
在/usr/local/spark/hadoop-2.8.3/etc/hadoop目录修改以下配置文件:
- core-site.xml:特定的通用Hadoop属性配置文件
- marpred-site.xml:特定的通用MapReduce属性配置文件
- hdfs-site.xml:特定的通用HDFS属性配置文件
- yarn-site.xml:特定的通用YARN属性配置文件
2.4.1 配置core-site.xml
官方详细配置参考文档:
http://hadoop.apache.org/docs/r2.8.4/hadoop-project-dist/hadoop-common/core-default.xml
core-site.xml是 Hadoop的主要配置文件之一,它包含对整个Hadoop通用的配置。它在集群的每个主机上都存在。基本上,core-site.xml的变量可以改变或者定义分布式文件系统的名字、临时目录以及其他与网络配置相关的参数。
fs.defaultFS
hdfs://tango-spark01:9000
hadoop.tmp.dir
file:/usr/local/spark/hadoop-2.9.0/tmp
io.file.buffer.size
131072
参数说明如下:
| 参数 | 属性值 | 解释 |
|---|---|---|
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| hadoop.tmp.dir | file:/usr/local/spark/hadoop-2.9.0/tmp | tmp目录路径 |
| io.file.buffer.size | 131072 | SequenceFiles文件中.读写缓存size设定 |
2.4.2 配置marpred-site.xml
官方详细配置参考文档:
http://hadoop.apache.org/docs/r2.8.4/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
mapred-site.xml是提高Hadoop MapReduce性能的关键配置文件,这个配置文件保护了与CPU、内存、磁盘I/O和网络相关的参数。
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
tango-spark01:10020
mapreduce.jobhistory.webapp.address
tango-spark01:19888
参数说明如下:
| 参数 | 属性值 | 解释 |
|---|---|---|
| mapreduce.framework.name | yarn | 执行框架设置为Hadoop YARN. |
| mapreduce.jobhistory.address | 10020 | Jobhistory地址 |
| mapreduce.jobhistory.webapp.address | 19888 | Jobhistory webAPP地址 |
2.4.3 配置hdfs-site.xml
官方详细配置参考文档:
http://hadoop.apache.org/docs/r2.8.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
hdfs-*.xml文件集用于配置HDFS系统的运行时属性和各个数据节点上文件的物理存储相关的属性
dfs.namenode.name.dir
file:/usr/local/spark/hadoop-2.9.0/hdfs/name
dfs.datanode.data.dir
file:/usr/local/spark/hadoop-2.9.0/hdfs/data
dfs.replication
1
dfs.namenode.secondary.http-address
tango-spark01:9001
dfs.webhdfs.enabled
true
变量dfs.replication指定了每个HDFS数据块的复制次数,即HDFS存储文件的副本个数。实验环境只有一台Master和一台Worker(DataNode),所以修改为1
参数说明如下:
| 参数 | 属性值 | 解释 |
|---|---|---|
| dfs.namenode.name.dir | …/hdfs/name | 在本地文件系统所在的NameNode的存储空间和持续化处理日志 |
| dfs.datanode.data.dir | …/hdfs/data | 本地磁盘目录,HDFS数据应该存储Block的地方。可以是逗号分隔的目录列表(典型的,每个目录在不同的磁盘) |
| dfs.replication | 2 | 数据块副本数。此值可以在创建文件是设定,客户端可以只有设定,也可以在命令行修改 |
| dfs.namenode.secondary.http-address | 9001 | SNN的http服务地址。如果是0,服务将随机选择一个空闲端口 |
| dfs.webhdfs.enabled | true | 在NN和DN上开启WebHDFS (REST API)功能 |
如果使用ip作为host,需配置:
dfs.namenode.datanode.registration.ip-hostname-check
false
2.4.4 配置yarn-site.xml
官方详细配置参考文档:
http://hadoop.apache.org/docs/r2.8.4/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
yarn-site.xml文件用来配置由YARN框架提供的通用服务守护进程的属性,比如资源管理器和节点管理器,yarn-*.xml文件中定义的一些关键属性:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
tango-spark01:8032
yarn.resourcemanager.scheduler.address
tango-spark01:8030
yarn.resourcemanager.resource-tracker.address
tango-spark01:8031
yarn.resourcemanager.admin.address
tango-spark01:8033
yarn.resourcemanager.webapp.address
tango-spark01:8088
参数说明如下:
| 参数 | 属性值 | 解释 |
|---|---|---|
| yarn.nodemanager.aux-services | mapreduce_shuffle | mapreduce.shuffle,在Yarn上开启MR的必须项 |
| yarn.nodemanager.aux-services.mapreduce.shuffle.class | org.apache.hadoop.mapred.ShuffleHandler | 参考yarn.nodemanager.aux-services |
| yarn.resourcemanager.address | Host:8032 | 客户端对ResourceManager主机通过 host:port 提交作业 |
| yarn.resourcemanager.scheduler.address | Host:8030 | ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源 |
| yarn.resourcemanager.resource-tracker.address | Host:8031 | NodeManagers通过ResourceManager主机访问host:port |
| yarn.resourcemanager.admin.address | Host:8033 | 管理命令通过ResourceManager主机访问host:port |
| yarn.resourcemanager.webapp.address | Host:8038 | ResourceManager web页面host:port. |
如果spark-on-yarn模式下运行出现以下错误信息:
diagnostics: Application application_1527602504696_0002 failed 2 times due to AM Container for appattempt_1527602504696_0002_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2018-05-29 22:36:53.917]Container [pid=3355,containerID=container_1527602504696_0002_02_000001] is running beyond virtual memory limits. Current usage: 226.5 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
考虑增加以下配置信息:取消虚拟内存的检查yarn.nodemanager.vmem-check-enable=false和设置虚拟内存的比例yarn.nodemanager.vmem-pmem-ratio为3,默认为2.1
yarn.nodemanager.vmem-check-enabled
false
Whether virtual memory limits will be enforced for containers
yarn.nodemanager.vmem-pmem-ratio
3
Ratio between virtual memory to physical memory when setting memory limits for containers
2.4.5 修改slave内容
修改./etc/hadoop/slaves内容,添加slave节点信息
[root@tango-spark01 hadoop]# vi slaves
tango-spark02
2.5 配置slave节点信息
将tango-spark01主节点的内容同步放去其他节点
[root@tango-spark01 local]# scp -r spark 192.168.112.122:/usr/local/
其中配置文件信息无需修改
2.6 启停Hadoop分布式集群
2.6.1 格式化集群的文件系统
在tango-spark01 Master节点格式化集群的文件系统
[root@tango-spark01 hadoop-2.9.0]# hdfs namenode -format
18/05/25 16:14:56 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = tango-spark01/192.168.112.121
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.9.0
18/05/25 16:15:40 INFO namenode.FSImage: Allocated new BlockPoolId: BP-304911741-192.168.112.121-1527236140321
18/05/25 16:15:40 INFO common.Storage: Storage directory /usr/local/spark/hadoop-2.9.0/hdfs/name has been successfully formatted.
18/05/25 16:15:41 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/spark/hadoop-2.9.0/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/05/25 16:15:41 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/spark/hadoop-2.9.0/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
18/05/25 16:15:41 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/05/25 16:15:41 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at tango-spark01/192.168.112.121
************************************************************/
格式化成功后,看到hdfs/name目录下出现current目录,且包含多个文件
[root@tango-spark01 hadoop-2.9.0]# cd hdfs
[root@tango-spark01 hdfs]# ls
data name
[root@tango-spark01 hdfs]# cd name
[root@tango-spark01 name]# ls
current
[root@tango-spark01 name]# cd current
[root@tango-spark01 current]# ls
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
2.6.2 启动Hadoop集群
因为tango-spark01是namenode,tango-spark02是datanode,所以只需要再tango-spark01上执行启动命令即可,使用命令启动Hadoop集群:start-dfs.sh和start-yarn.sh
[root@tango-spark01 hadoop-2.9.0]# start-dfs.sh
Starting namenodes on [tango-spark01]
root@tango-spark01's password:
tango-spark01: starting namenode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-namenode-tango-spark01.out
[email protected]'s password:
192.168.112.122: starting datanode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-datanode-tango-spark02.out
Starting secondary namenodes [tango-spark01]
root@tango-spark01's password:
tango-spark01: starting secondarynamenode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-secondarynamenode-tango-spark01.out
[root@tango-spark01 hadoop-2.9.0]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/spark/hadoop-2.9.0/logs/yarn-root-resourcemanager-tango-spark01.out
[email protected]'s password:
192.168.112.122: starting nodemanager, logging to /usr/local/spark/hadoop-2.9.0/logs/yarn-root-nodemanager-tango-spark02.out
使用jps查看各个节点的进程信息
- 节点1
[root@tango-spark01 hadoop-2.9.0]# jps
1539 NameNode
1734 SecondaryNameNode
2139 Jps
1884 ResourceManager
- 节点2
[root@tango-spark02 hadoop-2.9.0]# jps
1445 DataNode
1637 Jps
1514 NodeManager
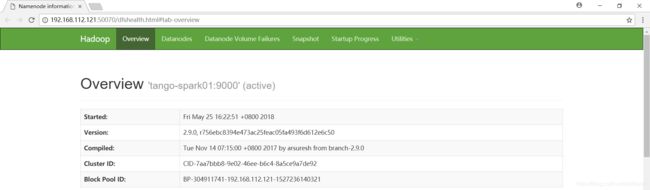
此时分布式的hadoop集群已经搭好了,在浏览器输入http://192.168.112.121:50070,自动跳转到了overview页面
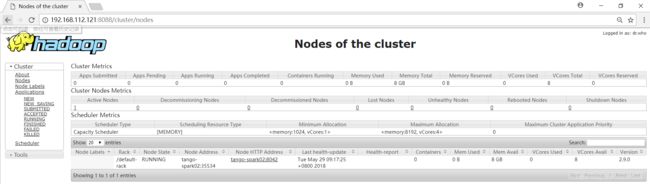
http://192.168.112.121:8088,自动跳转到了cluster页面,看到以下界面代表Hadoop集群已经开启了
2.6.3 停止Hadoop服务
停止Hadoop,依次执行stop-dfs.sh、stop-yarn.sh
[root@tango-spark01 spark-2.3.0]# stop-dfs.sh
Stopping namenodes on [tango-spark01]
root@tango-spark01's password:
tango-spark01: stopping namenode
[email protected]'s password:
192.168.112.122: stopping datanode
Stopping secondary namenodes [tango-spark01]
root@tango-spark01's password:
tango-spark01: stopping secondarynamenode
[root@tango-spark01 hadoop-2.9.0]# stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
[email protected]'s password:
192.168.112.122: stopping nodemanager
192.168.112.122: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
查看jps已无namenode和DataNode进程
2.7 Hadoop-wordcount示例程序
Wordcount是Hadoop中的一个类似Helloworld程序,在安装好的Hadoop集群上已有相应的程序,它的功能是统计文件中各单词的数目。
- 准备数据
在/usr/local/spark/下新建demo-file文件夹,生成file1.txt,file2.txt,file3.txt,file4.txt四个文件
[root@tango-spark01 spark]# mkdir demo-file
[root@tango-spark01 spark]# cd demo-file/
[root@tango-spark01 demo-file]# echo "Hello world Hello Hadoop" > file1.txt
[root@tango-spark01 demo-file]# echo "Hello world Hello 2018" > file2.txt
[root@tango-spark01 demo-file]# echo "Hello tango Hello May" > file3.txt
[root@tango-spark01 demo-file]# echo "Hello tango Hello world" > file4.txt
[root@tango-spark01 demo-file]# ls -l
total 16
-rw-r--r--. 1 root root 25 May 28 15:45 file1.txt
-rw-r--r--. 1 root root 23 May 28 15:45 file2.txt
-rw-r--r--. 1 root root 22 May 28 15:45 file3.txt
-rw-r--r--. 1 root root 24 May 28 15:46 file4.txt
- 然后把数据put到HDFS里
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -mkdir /input
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -put /usr/local/spark/demo-file/file1.txt /input
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -put /usr/local/spark/demo-file/file2.txt /input
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -put /usr/local/spark/demo-file/file3.txt /input
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -put /usr/local/spark/demo-file/file4.txt /input
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -ls /input
Found 4 items
-rw-r--r-- 1 root supergroup 25 2018-05-29 10:41 /input/file1.txt
-rw-r--r-- 1 root supergroup 23 2018-05-29 10:41 /input/file2.txt
-rw-r--r-- 1 root supergroup 22 2018-05-29 10:42 /input/file3.txt
-rw-r--r-- 1 root supergroup 24 2018-05-29 10:42 /input/file4.txt
- 进入hadoop-mapreduce-examples-2.9.0.jar所在文件夹,使用pwd输出当前目录的路径
[root@tango-spark01 mapreduce]# ls -l
total 5196
-rw-r--r--. 1 tango tango 571621 Nov 14 2017 hadoop-mapreduce-client-app-2.9.0.jar
-rw-r--r--. 1 tango tango 787871 Nov 14 2017 hadoop-mapreduce-client-common-2.9.0.jar
-rw-r--r--. 1 tango tango 1611701 Nov 14 2017 hadoop-mapreduce-client-core-2.9.0.jar
-rw-r--r--. 1 tango tango 200628 Nov 14 2017 hadoop-mapreduce-client-hs-2.9.0.jar
-rw-r--r--. 1 tango tango 32802 Nov 14 2017 hadoop-mapreduce-client-hs-plugins-2.9.0.jar
-rw-r--r--. 1 tango tango 71360 Nov 14 2017 hadoop-mapreduce-client-jobclient-2.9.0.jar
-rw-r--r--. 1 tango tango 1623508 Nov 14 2017 hadoop-mapreduce-client-jobclient-2.9.0-tests.jar
-rw-r--r--. 1 tango tango 85175 Nov 14 2017 hadoop-mapreduce-client-shuffle-2.9.0.jar
-rw-r--r--. 1 tango tango 303317 Nov 14 2017 hadoop-mapreduce-examples-2.9.0.jar
drwxr-xr-x. 2 tango tango 4096 Nov 14 2017 jdiff
drwxr-xr-x. 2 tango tango 4096 Nov 14 2017 lib
drwxr-xr-x. 2 tango tango 30 Nov 14 2017 lib-examples
drwxr-xr-x. 2 tango tango 4096 Nov 14 2017 sources
[root@tango-spark01 mapreduce]# pwd
/usr/local/spark/hadoop-2.9.0/share/hadoop/mapreduce
- 在Hadoop根目录执行以下命令,运行Wordcount
[root@tango-spark01 hadoop-2.9.0]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /input /output1
18/05/29 22:03:04 INFO client.RMProxy: Connecting to ResourceManager at tango-spark01/192.168.112.121:8032
18/05/29 22:03:05 INFO input.FileInputFormat: Total input files to process : 4
18/05/29 22:03:05 INFO mapreduce.JobSubmitter: number of splits:4
18/05/29 22:03:06 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/05/29 22:03:06 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1527602504696_0001
18/05/29 22:03:07 INFO impl.YarnClientImpl: Submitted application application_1527602504696_0001
18/05/29 22:03:07 INFO mapreduce.Job: The url to track the job: http://tango-spark01:8088/proxy/application_1527602504696_0001/
18/05/29 22:03:07 INFO mapreduce.Job: Running job: job_1527602504696_0001
18/05/29 22:03:18 INFO mapreduce.Job: Job job_1527602504696_0001 running in uber mode : false
18/05/29 22:03:18 INFO mapreduce.Job: map 0% reduce 0%
18/05/29 22:03:42 INFO mapreduce.Job: map 100% reduce 0%
18/05/29 22:04:00 INFO mapreduce.Job: map 100% reduce 100%
18/05/29 22:04:01 INFO mapreduce.Job: Job job_1527602504696_0001 completed successfully
18/05/29 22:04:01 INFO mapreduce.Job: Counters: 49
出现“INFO mapreduce.Job: Job job_1527602504696_0001 completed successfully”意味着运行成功,否则就要根据出错信息或者日志排错。其中,/output1是执行结果输出目录,可以用hadoop fs -cat /output1/part-r-* 命令来查看结果.
5. 结果如下
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -ls /output1
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-05-29 22:03 /output1/_SUCCESS
-rw-r--r-- 1 root supergroup 46 2018-05-29 22:03 /output1/part-r-00000
[root@tango-spark01 hadoop-2.9.0]# hadoop fs -cat /output1/part-r-00000
2018 1
Hadoop 1
Hello 8
May 1
tango 2
world 3
3、Scala环境配置
3.1 下载并安装Scala
解压安装包到目标路径:
[root@tango-spark01 src-install]# tar -xzvf scala-2.12.6.tgz -C /usr/local/spark
3.2 配置命令环境
在/etc/profile.d/custom.sh文件结尾,添加:
export SCALA_HOME=/usr/local/spark/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
动态生效:
[root@tango-spark01 etc]# source /etc/profile
检查是否安装成功:
[root@tango-spark01 scala-2.12.6]# scala -version
Scala code runner version 2.12.6 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
3.3 其它节点配置Scala
用SCP将Scala产品介质复制到其它节点
[root@tango-spark01 spark]# scp -r scala-2.12.6/ 192.168.112.122:/usr/local/spark
修改/etc/profile.d/custom.sh文件并动态生效
4、Spark集群环境配置
4.1 安装spark软件
解压安装包到目标路径:
[root@tango-spark01 src-install]# tar -xzvf spark-2.3.0-bin-hadoop2.7.tgz -C /usr/local/spark
修改spark文件夹名称:
[root@tango-spark01 spark]# mv spark-2.3.0-bin-hadoop2.7/ spark-2.3.0
[root@tango-spark01 spark]# ls
hadoop-2.9.0 scala-2.12.6 spark-2.3.0
4.2 配置环境变量
在/etc/profile.d/custom.sh文件结尾,添加:
export SPARK_HOME=/usr/local/spark/spark-2.3.0
export PATH=$PATH:$SPARK_HOME/bin
动态生效:
[root@tango-spark01 etc]# source /etc/profile
4.3 配置spark环境
4.3.1 修改spark-env.sh文件
在最尾巴加入
[root@tango-spark01 conf]# vi spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
export SCALA_HOME=/usr/local/spark/scala-2.12.6
export HADOOP_HOME=/usr/local/spark/hadoop-2.9.0
export HADOOP_CONF_DIR=/usr/local/spark/hadoop-2.9.0/etc/hadoop
export SPARK_MASTER_IP=192.168.112.121
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明:
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
4.3.2 修改slaves文件
配置slaves节点的信息
[root@tango-spark01 conf]# vi slaves
# A Spark Worker will be started on each of the machines listed below.
tango-spark02
4.3.3 同步配置到slave节点
使用SCP命令将spark产品复制到slave节点
[root@tango-spark01 spark]# scp -r spark-2.3.0/ 192.168.112.122:/usr/local/spark
4.4 启停Spark集群
因为这里只需要使用hadoop的HDFS文件系统,所以并不用把hadoop全部功能都启动
4.4.1 启动hadoop的HDFS文件系统
使用如下命令:
[root@tango-spark01 spark]# start-dfs.sh
Starting namenodes on [tango-spark01]
root@tango-spark01's password:
tango-spark01: starting namenode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-namenode-tango-spark01.out
[email protected]'s password:
192.168.112.122: starting datanode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-datanode-tango-spark02.out
Starting secondary namenodes [tango-spark01]
root@tango-spark01's password:
tango-spark01: starting secondarynamenode, logging to /usr/local/spark/hadoop-2.9.0/logs/hadoop-root-secondarynamenode-tango-spark01.out
启动之后使用jps命令可以查看到tango-spark01已经启动了namenode,tango-spark02启动了datanode,说明hadoop的HDFS文件系统已经启动了。
[root@tango-spark01 spark]# jps
2289 Jps
1988 NameNode
2180 SecondaryNameNode
[root@tango-spark02 spark]# jps
1557 DataNode
1903 Jps
注:在使用yarn模式提交的时候,需要启动YARN服务
[root@tango-spark01 spark]# start-yarn.sh
4.4.2 启动Spark
在spark安装路径下,执行以下命令启动spark:
[root@tango-spark01 spark-2.3.0]# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-2.3.0/logs/spark-root-org.apache.spark.deploy.master.Master-1-tango-spark01.out
[email protected]'s password:
192.168.112.122: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-2.3.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tango-spark02.out
启动之后使用jps在tango-spark01和tango-spark02节点上分别可以看到新开启的Master和Worker进程:
[root@tango-spark01 spark-2.3.0]# jps
2434 Jps
1988 NameNode
2180 SecondaryNameNode
2367 Master
[root@tango-spark02 spark]# jps
1557 DataNode
1934 Worker
1983 Jps
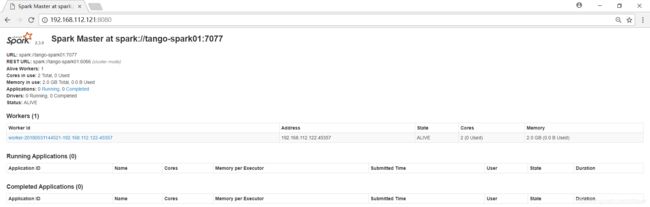
成功打开Spark集群之后可以进入Spark的WebUI界面,访问http://192.168.112.121:8080,看到如下界面:
4.4.3 打开Spark-shell
使用命令spark-shell打开spark-shell
[root@tango-spark01 spark-2.3.0]# spark-shell
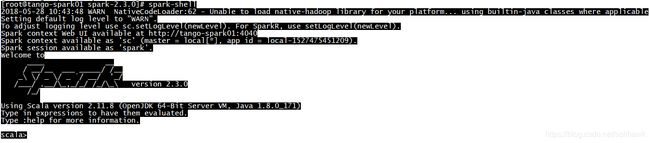
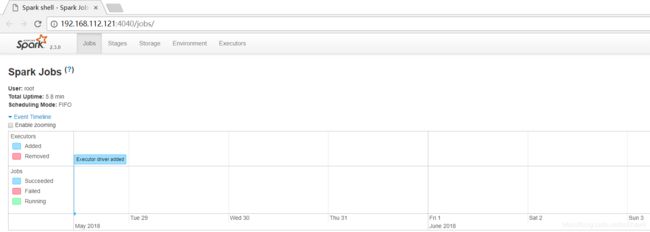
同时因为shell在运行,也可以通过http://192.168.112.121:4040访问WebUI,查看当前执行的任务。
4.4.4 停止Spark服务
[root@tango-spark01 spark-2.3.0]# ./sbin/stop-all.sh
[email protected]'s password:
192.168.112.122: no org.apache.spark.deploy.worker.Worker to stop
stopping org.apache.spark.deploy.master.Master
4.5 运行Spark提供的计算圆周率的示例程序
目前Apache Spark支持四种模式,分别是:
- local:开发模式使用
- Standalone:Spark自带模式,即独立模式,自带完整服务,可以单独部署到一个集群中。目前Spark在standalone模式下是没有单点故障问题,通过 zookeeper 实现的,架构和 MapReduce 是完全一样的。
- Spark On Mesos:官方推荐这种模式。目前而言,Spark运行在Mesos上比运行在 YARN 上更加灵活
- Spark On YARN:目前很有前景的部署模式,支持两种模式:a) yarn-cluster:适用于生产环境;b) yarn-client:适用于交互、调试、希望立即看到app的输出
上面涉及到Spark的许多部署模式,究竟哪种模式好这个很难说,需要根据你的需求,如果你只是测试Spark Application,你可以选择local模式;而如果你数据量不是很多,Standalone是个不错的选择。当你需要统一管理集群资源(Hadoop、Spark等),那么你可以选择Yarn或者mesos,但是这样维护成本就会变高。从对比上看,mesos似乎是Spark更好的选择,也是被官方推荐的;但如果你同时运行hadoop和Spark,从兼容性上考虑,Yarn是更好的选择;如果你不仅运行了hadoop、spark,还在资源管理上运行了docker,Mesos更加通用Standalone对于小规模计算集群更适合
4.5.1 使用单机local模式提交任务
local模式也就是本地模式,即在本地机器上单机执行程序。使用这个模式,并不需要启动Hadoop集群、也不需要启动Spark集群,只要机器上安装了JDK、Scala、Spark即可运行。
这里只是简单的用local模式运行一个计算圆周率的Demo。按照下面的步骤来操作。
1)进入Spark的根目录,调用Spark自带的计算圆周率的Demo,执行以下的命令:
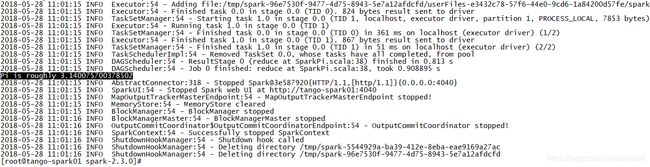
[root@tango-spark01 spark-2.3.0]# spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.3.0.jar
2)检查执行结果,执行结果如图所示:
4.5.2 使用Spark集群+Hadoop集群模式提交任务
这种模式也叫On-Yarn模式,主要包括Yarn-Client和Yarn-Cluster两种模式,在这种模式下提交任务,需要先启动Hadoop集群,然后在启动Spark集群。Yarn-Cluster和Yarn-Client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container,负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
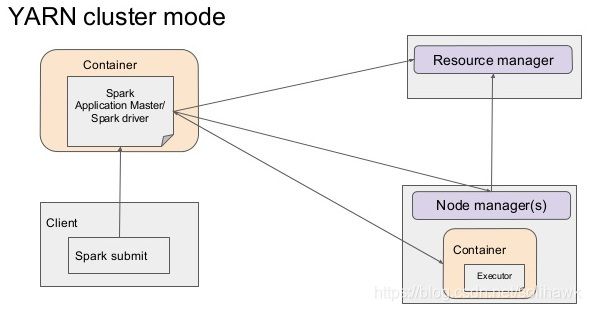
- Yarn Cluster
Spark Driver首选作为一个ApplicationMaster在Yarn集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。
- Yarn Client
在Yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。
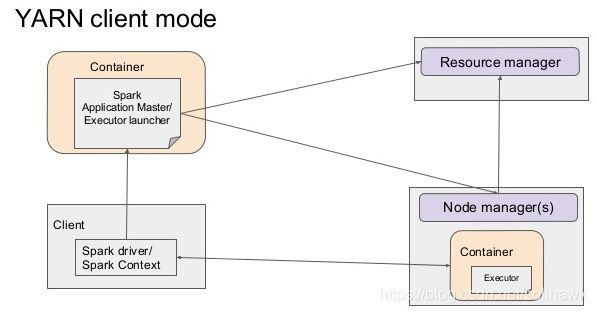
- 用yarn-client模式执行计算程序
进入spark根目录,执行以下命令,用yarn-client模式运行计算圆周率的Demo:
[root@tango-spark01 spark-2.3.0]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client examples/jars/spark-examples_2.11-2.3.0.jar
计算结果如下:
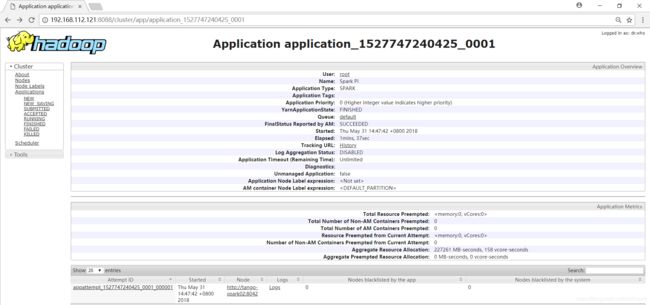
在WEBUI上可看到任务信息:

- 用yarn-cluster模式执行计算程序
进入spark根目录,执行以下命令,用yarn-cluster模式运行计算圆周率的Demo:
[root@tango-spark01 spark-2.3.0]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.3.0.jar
注意,使用yarn-cluster模式计算,结果没有输出在控制台,结果写在了Hadoop集群的日志中,查看输出日志信息。

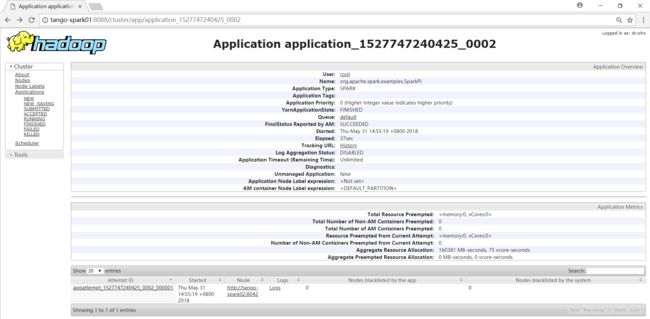
作业信息如下:

参考资料
- Apache官方网站,“https://spark.apache.org/docs/latest/”
转载请注明原文地址:https://blog.csdn.net/solihawk/article/details/115949935
文章会同步在公众号“牧羊人的方向”更新,感兴趣的可以关注公众号,谢谢!
