Storm流式数据计算架构工作机制
目录
- 摘 要
- 前 言
- 第1章 背景
-
- 1.1 Storm的由来
- 1.2 开源Storm
- 1.3 抛弃Twitter,移情Apache
- 第2章 Storm简介
-
- 2.1 简介
- 2.2 开发语言
- 2.3 应用场景
- 第3章 Storm组成与架构
-
- 3.1 核心技术和基本组成
- 3.2 相关概念
-
- 3.2.1 Tuple(元组)
- 3.2.2 Stream(流)
- 3.2.3 Topology(拓扑)
- 3.2.4 Spout(喷口)
- 3.2.5 Bolt(螺栓)
- 3.2.6 Stream grouping(流分组)
- 3.2.7 Worker(工作进程)
- 3.2.8 Task(任务)
- 3.2.9 Executor(执行器)
- 3.2.10 Reliability(可靠性)
- 3.3 Storm的集群架构
-
- 3.3.1 架构组成与工作内容
- 3.3.2 举例说明
- 第4章 Storm的编程模型
- 第5章 Topology的运行
- 结语
- 参考文献
摘 要
Storm是一套目前最为主流的免费的、开源的分布式实时计算系统,主要应用在流处理、连续计算、分布式RPC这三个方面。自Storm开源发布后,在许多著名企业中得到了广泛地应用。Storm是如何产生的、采用了什么样的架构以及它的工作原理是怎么样的。本文将主要讲解Storm的基本组成以及其集群架构和编程模型。
关键词:Storm,分布式,实时计算,集群架构
前 言
随着科学技术的不断发展,互联网普及到了家家户户,越来越多的人成为了互联网中的一份子。随之而生的物联网、云计算、人工智能等新兴技术也在各个领域得到了广泛地应用,海量的数据由此不断地产生,人们渐渐踏进了大数据时代。对于这些海量的数据,需要有一个特定的系统进行处理,这样才能让这些数据产生价值。这仅仅是解决了数据“大”的问题,很显然这已不满足了现实的需求。实时计算、快速处理成为了另一种趋势,这便是Storm面世的主要原因。
第1章 背景
1.1 Storm的由来
随着IT服务的全球化,作为微博的始祖——Twitter,对高度动态的实时数据处理要求越来越高。而Hadoop MapReduce虽然对海量数据处理应用发挥了重要作用,但其架构模式决定了其批处理的计算模型。这对于需要处理大批实时性要求高的大数据业务来说,存在着及时性和响应速度等方面的限制。
2011年7月,Twitter出于业务需要,收购了BackType公司。BackType是一家专注于社交媒体数据进行实时处理分析的公司,而Storm的前身则是BackType。BackType公司被收购后,Twitter公司将项目交给了原来的首席工程师Nathan Marz负责产品的研发和管理。
最初,BackType采用的是标准队列和线程(Worker)的方法,但这种方法相对来说过于冗长。很多逻辑处理都用于进行收发和序列/反序列消息,一个应用的某个逻辑将会遍及所有线程。于是,在2010年12月,Nathan Marz想到了“流(Stream)”的分布式抽取方法,最后演变为“喷口(Spout)”和“螺栓(Bolt)”的思想。经过五个月后,Storm诞生了第一个版本。
1.2 开源Storm
加入Twitter后,同年的八月份Twitter将Storm正式开源。Storm的实时、快速处理海量大数据能力,成功帮助Twitter和其他有相关需求的企业解决了实时大数据处理的问题,获得了许多企业和专家的赞誉。
1.3 抛弃Twitter,移情Apache
在2013年,Nathan Marz抛弃了Twitter,并投入到了Apache的怀抱。借助于Apache的品牌影响力,Storm最大程度地过渡到了共识驱动模式。随着Storm开发社区更多新想法新思路的提出,Storm在2014年9月成为了官方的顶级项目。
第2章 Storm简介
2.1 简介
Storm是一套目前最为主流的免费的、开源的分布实时计算系统,其具有健壮的分布式集群管理、简便的面向流式数据的编程模型、高容错非功能保障,能够依据用户的设置要求保证数据被恰当处理。对于处理无界数据流,Storm具有可靠、容易、实时的特点。Storm能够实时地处理海量的数据,其每个节点每秒钟处理的数据量可达到100万条。
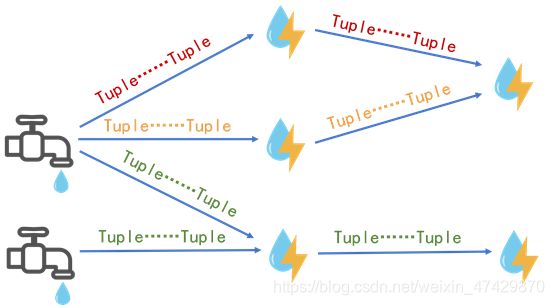
Storm的抽象示意如图2-1所示,其中Tuple相当于水滴,源源不断的水滴形成了Stream,因此水龙头相当于Stream的来源。只要水龙头一经打开,就会有Stream以Tuple的形式流经Bolt而被处理。图中共有四条数据流三种颜色,每条数据流都是由无限个Tuple组成,Tuple里面装载着具体的数据。Tuple将经过多个不同的Bolt,并被转换实体进行相应的处理。
2.2 开发语言
为了能够提高Storm的工作效率以及产生强大的软件生产力,Nathan Marz主要采用Java和Clojure语言开发Storm。其中,Java进行Storm API的编写,而部署端使用Clojure。此外,采用Java和Clojure这两种开发语言,也是考虑到兼容性和便利性,使掌握Storm变得十分简单,只要有兴趣,程序员就能根据自己喜好的编程语言进行操作,无需担心编程语言的不适配问题。
2.3 应用场景
Storm的应用场景非常广泛,可用于连续计算、机器在线学习、实时分析统计、分布式远程调用和数据仓库技术等多个领域。例如推荐系统中,对搜索过的商品推荐相关商品;网站统计中,实时统计用户访问量、商品销售额等。在Storm官网,也能看到不少国内外著名大公司将Storm使用在产品级应用中,例如Twitter(数据发现、实时分析、个性化搜索等)、阿里巴巴(实现业务日志处理和应用中数据记录的实时交换)、百度(用于处理搜索日志和提供实时的PV及AR-time分析)等。
第3章 Storm组成与架构
3.1 核心技术和基本组成
Storm的核心框架由七个部分组成,如图3-1所示。同时,它们也是Storm的基本组成部分。

3.2 相关概念
3.2.1 Tuple(元组)
Tuple是消息进行传送的基本单元。Tuple是一个类似值列表的东西,其中的字段可以是任意类型的对象。一般情况下,Tuple支持所有的基本类型、字符串和字节数组作为字段值,如果使用其他类型,只需要将该类型序列化就可以了。
3.2.2 Stream(流)
Stream是由Tuple组成的,一个没有界限、持续不断的Tuple序列就形成了Stream。Storm以一种可靠的方式将原语(由若干条指令组成的程序段)转换成一个新的分布式的Stream,而执行Stream转换的基本元素是Spout和Bolt。
下面用一个具体例子说明,如图,Stream就相当于一列火车,而Tuple就是车厢里面的乘客,Spout为火车的始发站,Bolt为中间站点。

3.2.3 Topology(拓扑)
Topology是Storm的一个实时应用程序。Topology类似于Hadoop中MapReduce的Job(作业),其主要区别在于MapReduce的Job最终会结束,而Topology就如同一个死循环,一直处于运行状态直至它被杀死。
3.2.4 Spout(喷口)
Spout是Topology消息的生产者。Spout组件主要是在Topology中产生数据流。Spout负责从外部数据源(例如Kestrel队列)中读取数据,并将读取的数据传输至Topology。一个Spout可能是靠谱的,也可能是不靠谱的。一个靠谱的Spout会重新发射一个处理失败的Tuple,而不靠谱的Spout则会置之不理。
3.2.5 Bolt(螺栓)
Bolt是Topology消息的处理者。Bolt负责Topology中所有的处理工作,其可以完成过滤、业务处理、连接计算、连接与访问数据库等任何操作。对于简单的Stream处理Bolt一个就足够了,而对于复杂的Stream处理,则需要很多个Bolt,第一级的Bolt就可以将处理结果传递给下一级Bolt。
Spout和Bolt的区别在于前者是针对数据源的编程单元,后者是针对处理过程的编程单元。
3.2.6 Stream grouping(流分组)
Stream grouping定义了一个Stream应该如何分配给Bolt上面的多个Task。Storm内置了7个Stream grouping方式。
3.2.7 Worker(工作进程)
Worker是Spout/Bolt中运行具体程序代码的进程。Topology使用一个或多个Worker的方式执行,每个Worker是一个物理Java虚拟机和Topology所需要执行所有任务的一个子集,执行Topology的一部分任务。
3.2.8 Task(任务)
Worker中每一个Spout/Bolt的线程称为一个Task。每个Spout和Bolt会以多个Task的形式在集群上运行。
3.2.9 Executor(执行器)
同一个Spout/Bolt的Task共享一个物理线程,该线程称为Executor。
3.2.10 Reliability(可靠性)
Storm保证了Topology中Spout产生的每个元组都会被处理。
3.3 Storm的集群架构
3.3.1 架构组成与工作内容
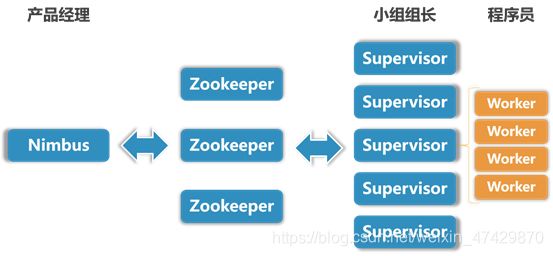
Storm采用主从架构的方式,主节点是Nimbus,从节点是Supervisor,主节点和从节点通过Zookeeper进行通信,有关调度的相关信息都存储在Zookeeper集群中,如图3-3为Storm的架构图。

Nimbus是Storm集群的主控节点,负责接受客户端的Topology代码并进行分发,指派给具体的Supervisor节点上的Worker节点,让Worker去运行Topology对应的组件(Spout/Bolt)的Task。Nimbus将这些分配的映射关系存储到Zookeeper里面,并对它们进行故障监测。
Supervisor是Storm集群地从节点,负责监听主机所分配的Task,并管理运行每一个Worker进程的启动和终止。
Worker是负责运行具体程序代码的进程。它的运行任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Zookeeper用来协调Nimbus和Supervisor,是Nimbus与Supervisor进行通信的桥梁。如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其他可用的Supervisor上运行。
3.3.2 举例说明
为了便于理解,这里举一个具体的例子。如图Nimbus相当于产品经理,Supervisor相当于小组组长,而Worker则是程序员。当产品经理接收到上级的任务需求后,就将需求拆分成多个任务并指派给对应的程序员完成,分配完成后就将这些内容写到Zookeeper里面。除此之外,产品经理还需要对整个任务的执行过程进行监视。
在每个小组组长接收到产品经理分配的任务后,就将产品经理指派的任务分发给程序员,并让他们执行。而程序员的任务相对来说比较简单,只需要完成两种类型的任务,即Spout任务和Bolt任务。
Zookeeper相当于企业内部的一个智能办公平台,企业里的产品经理、小组组长等人可以在上面分配、接收任务,是一种交流的渠道。除此之外,如果有一天小组组长突然离职的话,平台上会收到小组组长离职的相关信息,并在第一时间通知产品经理,产品经理则会立即将任务重新分配给其他小组完成,确保工作能够有效、持续地进行。
第4章 Storm的编程模型
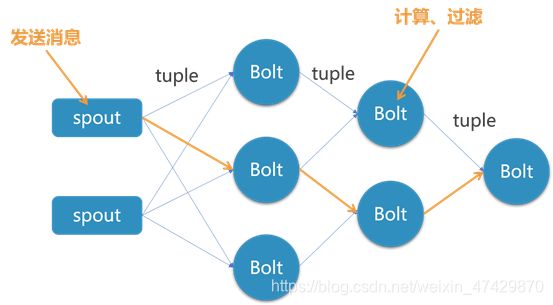
Storm在运行中可分为Spout与Bolt两个组件。其中,Spout发送信息,负责将Stream以Tuple的形式发送出去;而Bolt则负责将这些Stream进行转换,在Bolt中能够实现完成信息过滤、数据计算等操作,Bolt自身也能够将数据随机地发送给其他的Bolt。简单地说,就是数据源从Spout开始,数据以Tuple的方式发送到Bolt,多个Bolt可以串连起来,一个Bolt也可以接入多个Spout/Bolt。运行原理如图4-1所示。
第5章 Topology的运行
Topology是一种有向无环图,是由不同的Spout和Bolt组成并通过Stream连接起来的。Storm运行一个Topology主要通过调用Worker(进程)、Executor(线程)、Task这3个实体来完成执行工作。
每个Worker的工作都是非常专一的,一个Worker只会对一个Topology的子集执行处理,不会出现为多个Topology服务的情况。Storm在工作时,集群中的一个物理机会运行一个或多个Worker进程,所有的Topology将在Worker进程中被运行。工作进程如图5-1所示。
结语
通过这一次《大数据导论》的学习,我对大数据有了更多的认识。原先以为大数据的“大”只是指数量大,但现在,我认为大数据不仅体现在数量大,也体现在它数据产生地快,需要进行大量的计算处理。而通过本次研修学习,我对Storm有了相对总体的了解和理解,包括Storm的历史渊源、基本组成、工作机制等方面。Storm是一个能够实时计算处理海量数据的分布式系统,现在有着广阔的应用场景,例如金融系统、推荐系统等。我认为,这种实时计算的能力还可用于统计世界人口,形成世界人口的数据库,从而预测世界人口的变化趋势。目前,Storm主要被应用在互联网行业,未来,Storm将渗透到人工智能、物联网等领域。
参考文献
- 梅宏.大数据导论[M].北京:高等教育出版社,2018.11.
- 丁维龙,赵卓峰,韩燕波.Storm:大数据流式计算及应用实践.北京:电子工业出版社,2015.3.
- 赵必厦,程丽明.从零开始学Storm.北京:清华大学出版社,2014.10.
- 张华,王东辉,吴烜.流式计算的分布式框架的应用[J].信息与电脑(理论版),2014(20):142-143.
- 从Apache Storm学到的经验教训[EB/OL].http://www.uml.org.cn/sjjm/2014101510.asp.
- 《Storm入门》中文版[EB/OL].http://ifeve.com/getting-started-with-stom-index/.
- storm简介、原理、概念[EB/OL].https://blog.csdn.net/u011082453/article/details/82417259.
- Storm概念学习系列之Tuple元组(数据载体)[EB/OL].https://www.cnblogs.com/zlslch/p/5989281.html.
- Storm介绍(一)[EB/OL].https://www.cnblogs.com/Jack47/p/storm_intro-1.html.
- 【原】storm源码之理解Storm中Worker、Executor、Task关系[EB/OL].https://www.cnblogs.com/yufengof/p/storm-worker-executor-task.html.
- Storm架构与运行原理[EB/OL].https://blog.csdn.net/weiyongle1996/article/details/77142245.
- Storm之——stream grouping简介[EB/OL].https://blog.csdn.net/l1028386804/article/details/79371876.
- Storm学习10–tuple结构[EB/OL].https://blog.csdn.net/wuxintdrh/article/details/61933004