【Linux】IP协议
文章目录
- 前言
- 1. 网络层
- 2. IP协议格式
- 3. IP报文分片和组装
-
- 3.1 如何分片和组装:
- 3.2 组装的衍生问题:
- 4. 网段划分(重点)
-
- 4.1 子网掩码:
- 4.2 IP地址的数量限制:
- 4.3 私有IP地址和公网IP地址:
- 4.4 私有IP是如何解决IP不足的问题的:
- 4.5 NAT技术(出去的问题):
- 4.6 NAT技术(回来的问题):
- 5. 其他
前言
前两章我们学习了整个网络协议中最重要的协议TCP协议,也结束了传输层协议栈的学习。本章我们继续向下沉一层,进入到网络层的学习。本章我们来学习网络层的IP协议,也是网络协议栈中最重要的一个协议之一。和前几章一样,先学习了解其协议格式和报头中每个字段的含义,再理解数据经过IP层的传输过程。
还是那句话:
整个网络协议栈就叫做TCP/IP协议栈,可想而知TCP/IP协议的重要性!!
1. 网络层
我们之前学习了应用层,传输层:
传输层解决的是相隔千里之外可靠性的问题。应用层解决序列与反序列化的问题,读取完整报文的问题,协议处理的问题。应用层是将数据提出来,然后我们就可以在上层使用多进程,多线程,和其他常见的方案来对数据做业务。
TCP的数据要传输到千里之外,中间还有各种各样的设备,诸如路由器交换机这样的设备。现在要将数据送到千里之外的传输层,再向上交给对方的应用层,这是之前在逻辑上是这么理解的。
TCP要保证可靠性将数据送到远端主机,前提是,得能先将数据从本地网络层,送到对方主机的网络层!!
- 传输层解决的是可靠性的问题,但是并不传数据,(是传输层将数据向下交付给网络层)。
- 传输层提供更多的是策略,TCP和UDP。只有底下的网络层才是帮我们办事的。
- 而将数据从
A主机远距离传输到B主机要具有这样的能力的话,是要由IP层去解决的。
- 网络层IP:让主机具有一种能力,将数据从A主机送到B主机的能力!
- 网络层提供的是:将数据从A主机,跨网络从到B主机的能力,并没有说是可靠的。
- TCP/IP:可靠的将数据从A主机,跨网络送到B主机。
一旦底层将数据送到了对方还好,如果没送到,就要通知传输层没有发送成功,然后传输层才识别到是不是超时了,或者判断是不是丢包了,然后才做相关的重传。
所以
TCP + IP就能可靠的将数据从A主机发送到B主机。TCP/IP协议栈属于操作系统内部实现的网络通信策略,就是为了可靠的将数据从主机传送到主机,这就解决了长距离网络通信。
在网络当中流动的报文叫做,IP报文,传输层的数据段叫做TCP数据段。
IP地址 + 端口号,可以标定,公网中指定主机的指定进程。
基本概念:
- 主机:配有IP地址,但是不进行路由控制的设备。
- 路由器:既配有IP地址,又能进行路由控制(对数据包进行转发的主机)。
- 节点:主机和路由器的统称。
主机一般都是配有IP地址的,不进行路由控制,不过单个主机只要有网络层,就会有路由控制的能力。
2. IP协议格式
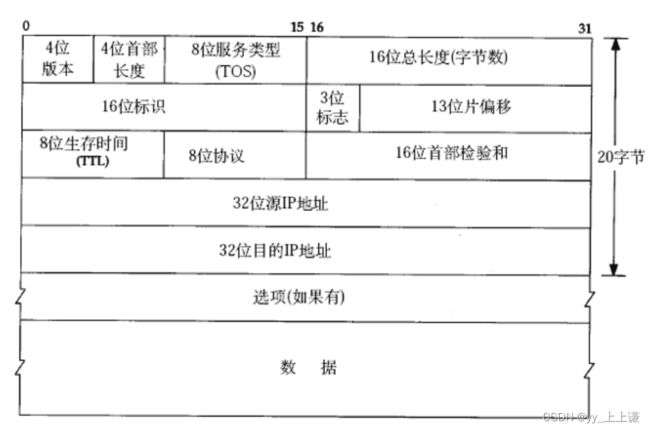
4位版本: 一般都是IPv4。
8位服务类型(TOS): 很少用。
4位首部长度: 和TCP报文的4位首部功能一样, TCP协议复习传送门 。
16位首部校验和: 对IP报头进行校验。
IP层如何进行封装解包:
- 读取报头时,先读取一个字节,提取出4为首部长度,算出报头长度,再将总长度提出来。
- 用
总长度 - 报头长度,剩下的就是有效载荷。 - 所以能在IP这里做到报头的封装和解包。
8位生存时间(TTL):
- IP报文在路由器转发的时候,如果网络有bug,或者目标主机不可达(距离特别远,网络有bug等)。
- 因为特定的原因导致IP报文在网络中长时间游离(网内环回流动),而不消失。
- 如果没有对ip做生命周期的约束,那么就极有可能导致网络当中。
- 游离报文越来越多,再怎么转发也到不了目标主机,反而要占用路由器相关的资源,网络带宽的资源。
所以IP报文得设置生命周期:
- 每经过一个路由器转发,该报文的TTL生存时间进行减减。
- 当下一个路由器发现该IP报文的TTL小于等于0。
- 就没有必要进行再转发这个报文了,此时直接将该报文丢弃。
32位源IP地址,32位目的IP地址: 这个我们都清楚,在网络中用来标定两个主机的地址。
选项字段: 和TCP报文类似,就是为了扩展因子准备的。
3. IP报文分片和组装
数据链路层有规定,单次转发的数据的有效载荷是有上限的,这主要是因为一些电器特征。
MTU(Maximum Transmission Unit)最大传送单元:
- 在局域网中通信,是基于碰撞域的。
- 在数据链路层,数据在局域网通信时,为了尽量减少冲突,有一个硬性的规定。
- 数据链路层所能承担的数据,最大能够发送的单个数据大小有效载荷称之为MTU。
- 数据链路层有发送单个数据帧的最大值约束,所以我们不能发送太大的IP报文。
- 因为底层规定数据包有上限,所以IP报文不能太大,所以要对IP报文进行拆包,所以要花点时间将数据包拆成若干个报文。
- 但是在拆包的时候还要考虑未来组装的问题。
协议栈当中,数据层和数据层之间的功能要进行解耦,网络层进行分片和组装和传输层没有关系!!
衍生问题:
- 因为拆分以后,以前只需要发送一个报文,现在因为一些链路层规定,导致网络层要将报文拆分。
- 如果将来网络层收到了若干个报文,要组合起来,就有可能出现组装不起来的问题。
- 也就是说经过分片,完整的IP报文,有一部分报文丢失了,那么网络层就不会将这些数据交给对方的传输层。
- 只要分片的IP报文只要有一片丢了,就认为IP报文整体丢包了,无法向上层交付。
- 网络层进行分片,不是主流!!未来争取网络层尽量不要分片,一旦分片很容易出现丢包问题,丢包概率增加了。
分片对UDP和TCP有影响吗?当然有影响,TCP有可靠性(重传),IP报文分片会直接影响到UDP。
- 当然有影响,对上层的传输层而言统一的影响都是增加了丢包的概率。
- 对于TCP而言倒影响不大,因为TCP有可靠性,丢包了不影响,大不了重传一下。
- 对于UDP影响就大了,因为UDP是不可靠的,它把数据交给IP层它就不管了。
- 如果IP分片了出现了丢包,那么就会直接影响到UDP。
分片是不利于网络进行可靠传输的,所以一般不建议分片,不是主流。无论是TCP还是UDP都不建议分片。
- 如何做到尽量不要分片 —— 传输层来决定。
- 传输层单个报文的大小一般设置成为多少合适呢?
- 一般在三次握手的时候,就会协商单次传输数据的报文大小!
怎么做到尽量减少分片呢?
如何做到减少分片呢?网络层是否分片,是否由网络层决定?
- 数据什么时候发,发多少是传输层决定的,网络层只是一个办事的。
- 所以是由传输层决定。
- 传输层交付下来的数据尽量不要太大。
所以传输层不仅仅要考虑对方的接收能力,也不仅仅要考虑网络拥塞的问题,传输层还要考虑尽可能的减少丢包,所以传输层在传输数据时也有自己的基本大小。从而不让网络层和数据链路层太难堪了。基本上在传输的时候,尽量不要出现分片问题。
最后达成共识:
- TCP提供策略,IP提供能力,进而
TCP/IP就能提供可靠的将数据从主机A送到主机B。 - 硬件规定了数据链路层一-次传多少的数据。
3.1 如何分片和组装:
上述对IP报头的讲解中,我们始终没有提及第二行的字段,因为这需要我们来重点理解。
首先我们要来达成几项共识:
- 需要对P进行分片,由谁来做?
-
- 发送方的网络层来进行分片。
- 全部收到之后,由谁来组装?
-
- 接收方的网络层进行组装。
- 无论是对发送方还是接受方,分片和组装行为,双方的传输层知道吗?
-
- 不需要知道,也不关心!

16为标识:
- IP报文也有自己的序号,当做标识来使用。
- 假如一个报文拆被之后,每一份都要携带IP报头,因为每一份都是独立的IP报文。
- 每一份报文报头中的16位标识里都是填充的相同的。
对方网络层拿到IP报文要组合:
先要识别该报文是被分片的!
- 将标识相同序号的报文先得收集在一起。
- 如何正确的组装成一个报文。
1. 将标识相同序号的报文先得收集在一起。
- 这里是有坑的,接收方的网络层,还有其他的主机都在给这台主机发消息。
- 换言之,接收方的网络层,会收到来自各个主机发来的消息,有的是分片的,有的是没分片的。
- 所以要将相同的标识号的分片放在一起,前提条件是,该报文是被分片的。
假如未来要收三个IP报文,假如收第一个的时候,如何知道这个报文曾经是被分片过的呢?
- 所以就有了三位标志,其中有两个重点标志位,有一位是被保留的。
- 第一位是保留的,第二位表示禁止分片,第三位表示的是更多分片。
- 如果不知道是被分片过的,那么就该将报文直接向上交付了。
3位标志字段:
- 第一位: 保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。
- 第二位: 置为1表示 “禁止分片”,这时候如果报文长度超过MTU,IP模块就会丢弃报文。
- 第三位: 表示 “更多分片”,如果分片了的话,最后一个分片置为0,其他是1,类似于一个结束标记。
下面来解释一下:
- 当要识别该报文是否被分片了,当收到每一个报文时,都去检测该报文报头当中的三位标志里面的
更多分片标志位是否被置1。 - 如果
更多分片标志位被置为1,代表该报文是被分片过的,最后一个报文更多分片标志位为0,类似于字符串的结束\0。 - 如果IP报文交给数据链路层数据的时候,其中如果设置了
禁止分片,意味着,不想让网络层做分片,该报文就会被对应的主机直接丢弃,也就是说关闭了分片的功能。
如果报文大小大于MTU且禁止分片标志设置为1:
- 发送方主机会根据报文大小和MTU的关系进行处理。
- 一般而言发送方主机会丢弃该报文,并返回一个 “报文太大” 的错误信息给上层应用。
- 这样做是为了确保报文能够被网络正常传输,因为禁止分片的设置意味着报文不能被分割成更小的片段进行传输。
举个例子(重点):
如果分了三片,第一片3位标志位的更多分片标志位就被置1,第二片3位标志位的更多分片标志位就被置1,在三片当中最后一个报文的更多分片标志位是0。
所以三位标志位,值得学习的标志位就一个,表示的是更多分片,凡是设置为1的,代表的含义必是后面还有分片,只要更多分片标志位置为0,就代表后面没有分片了。
2. 如何正确的组装成一个报文。
我们一般情况下,如果是一个独立的报文,三位标志位都是0。16位标识也是自己的标识,13位片偏移也是0。
13位片偏移(framegament offset):
- 是分片相对于原始IP报文开始处的偏移。
- 其实就是在表示当前分片在原报文中处在哪个位置。
- 实际偏移的字节数是偏移量乘8得到的。
- 因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)。
举个例子:
- 如果分片了,每一片都是一个独立IP报文。
- 其也有报头,也需要设置它们的13位片偏移的。
- 假设有3000个字节的IP报文,被分成三份,每一份1000个字节(当然不太准确,因为每一片都有自己对应的报头)。
- 第一片报文当中13位片偏移为0,第二片报文当中13位片偏移为1000,第二片报文当中13位片偏移为2000。
具体分片过程:
- 假设MTU为1500
Byte,IP报文长为3000Byte,报头长为20Byte。 - 那么我们就需要将这个IP报文拆分成三个IP报文片。
-
- 第一片:20 + 1480 —— 1500
-
- 第二片:20 + 1480 —— 1500
-
- 弟三片:20 + 20 —— 40
组装:
- 13位片偏移量乘8,代表的是该报文在原始报文当中,距离最开始的起始偏移量。
- 只需要将所收集到的所有报文,根据片偏移,从小到大排序,那么就可以将所有的数据包组合起来了。
3.2 组装的衍生问题:
识别报文是被分片的,通过更多分片标志位来识别。
网络在传送数据时是乱序的,只有传输层能保证按序到达,网络层收到的三个报文是乱序的(4以 上面为例)。
如果先收到了最后一片报文,更多分片标志位是0,那么如何保证识别该报文时认为它是分片的呢?
- 其实是能做到的,如果识别到
更多分片标志位是0。 - 假如分片了,那么一定是分片报文的最后一个,那么该报文的13位片偏移一定不为0。
如何判断分片了:
(更多分片标志位 == 1)|| (更多分片标志位 == 0 && 13位片偏移 != 0)
如何保证收集完了呢?
在收集的所有的报文中,只要有一个报文的更多分片标志位是0,就代表收集完了。
如何保证收集全了?
- 收完并不代表收集全了,如果中间有报文丢失了呢?也是能保证的!
- 我们经过排序(通过片偏移排序) ,排序之后片偏移最小的报文,片偏移量不是0,证明前面丢了报文。
- 如果一直没有收到,
更多分片标志位是0的报文的话,就说明最后一个分片丢了。
中间丢了能识别出来吗?
- 经过排序,前一个报文的偏移量加上自身的长度。
- 如果不等于下一个报文的片偏移量,说明中间报文丢了。
- 中间开头结尾都丢了的话,还是按照上述办法判断。
这样就能保证,既能把报文收完,又能把报文收全,所以就能通过上述三步将报文正确组装起来。合并好之后可以通过16位首部校验和,校验数据尤其是报头字段有没有问题。
4. 网段划分(重点)
IP地址提供了一种从A主机跨网络将数据送到B主机的能力,真正的数据包在转发时就是IP报文,后面再带一个MAC帧。传输层中的那些策略并不在网络层中体现,真正在网络里跑的是IP报文。
IP地址分为两个部分,网络号和主机号:
IP的构成:ip = 目的网络 + 目的主机
- 网络号: 保证相互连接的两个网段具有不同的标识。
- 主机号: 同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号。
IP是如何找到对方的主机的呢?
- 根据对应ip地址当中的目的网络,定位到主机所在的网段(或者局域网)当中。
- 一旦定位到在哪个网段,在网段里找到某台机器就可以进行数据转发了。
- 这既是ip进行路由的基本原则。
在同一个网络里,网络标识必须一样,但是主机标识一定不一样。
路由器要负责在不同网段之间进行数据转发。前提是一定是要集联两个不同的网络,所以路由器至少要有两个不同的网络接口,配上不同的IP地址。
在全网当中找到目的网络找到网段,再根据目的主机找到某一个网段内找到某个主机。
前提条件是,曾经有人将全球的网络进行一定程度的划分。
过去曾经提出一种划分网络号和主机号的方案,把所有IP地址分为五类,如下图所示:
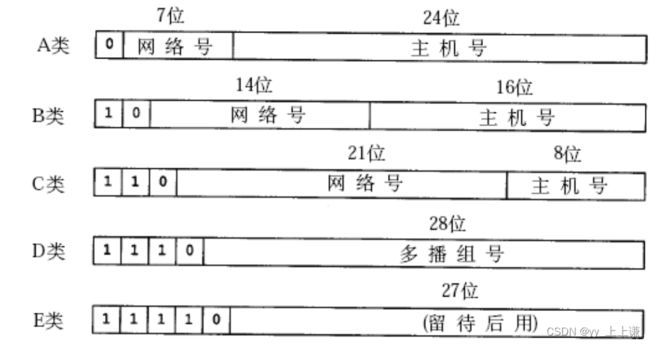
因为IP标定全网唯一的主机,所以IP也是资源,按照这个分法一共只有2^32次方个。
- 不同国家不同机构就可以在这五类中进行认领不同的ip地址,认领不同的网络。
- 如果一个机构申请了一个B类网络,局域网主机号,主机可能就用不完,最多是
65535台主机可以用, 会造成大量的IP地址浪费。 - 大部分组织或者机构申请B类网络,导致B类网络很快被分配完了。
- 一个组织或机构申请了一个网段,就不能被其他机构再用了。
4.1 子网掩码:
针对上述情况提出了新的划分方案,称为CIDR(Classless Interdomain Routing):
- 引入一个额外的子网掩码(subnet mask)来区分网络号和主机号。
- 子网掩码也是一个32位的正整数,通常用一串 “0” 来结尾。
- 将IP地址和子网掩码进行 “按位与” 操作,得到的结果就是网络号。
- 一旦有了子网掩码,网络号和主机号的划分与这个IP地址是A类、B类还是C类无关。
子网掩码的长度决定了网络号和主机号的划分方式,而与IP地址的类别无关。无论是A类、B类还是C类的IP地址,只要使用合适的子网掩码,就可以灵活地划分网络号和主机号,以满足网络规模和需求的要求。
目前已经不再采用分类划分法了,这是历史的产物。现在全部采用的都是子网掩码的方案。

引入相同位数的于网掩码,用这样的数据就可以动态的去调整,网络和主机号。
子网掩码一般会被配置进对应特定的路由器当中,会根据子网掩码不断进行按位与运算,来确认要去的目的主机是谁。
IP地址和子网掩码还有一种更简洁的表示方法:
例如140.252.20.68/24,表示IP地址为140.252.20.68,子网掩码的高24位是1,也就是255.255.255.0。

特殊的IP地址:
- 将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网。
- 将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包。
127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1。
以C类网为例,这个子网最多允许有2^8台主机,但是如果主机号为全0,那么该ip地址就是网络号。主机号为全1,代表在局域网内的厂播地址,所以全1也不能被使用,所以最终一共有2 ^ 8 - 2台主机。
网段(Subnet):
- 是指通过子网掩码对一个大的网络进行划分后得到的一个子集,它包括了该子集内所有主机的IP地址。
- 网段一般是以网络号来命名的,例如:
- 如果将
192.168.1.0/24网段划分为4个子网,则可以得到192.168.1.0/26、192.168.1.64/26、192.168.1.128/26和192.168.1.192/26四个子网。
具体划分过程:
在将192.168.1.0/24网段划分为4个子网时,我们需要使用子网掩码对IP地址进行划分。由于需要划分成4个子网,我们需要使用一个能够支持至少4个子网的子网掩码。最小的能够支持4个子网的子网掩码是255.255.255.192,也就是/26。
因此,我们可以将192.168.1.0/24网段划分为4个子网,每个子网的子网掩码都是255.255.255.192(/26)。每个网段内的主机个数都是:62个(去掉全0和全1)。
具体划分如下:
我们在每一段分析开头加上ip地址最后一个字节的前两个比特位,方便分析。
- 子网1
(00):192.168.1.0/26,可以使用的主机地址范围为192.168.1.1 ~ 192.168.1.62。 - 子网2
(01):192.168.1.64/26,可以使用的主机地址范围为192.168.1.65 ~ 192.168.1.126。 - 子网3
(10):192.168.1.128/26,可以使用的主机地址范围为192.168.1.129 ~ 192.168.1.190。 - 子网4
(11):192.168.1.192/26,可以使用的主机地址范围为192.168.1.193 ~ 192.168.1.254。
网段划分就是分配IP资源的一种策略。
为什么要进行网段划分?
- 经过网段划分,可以大大的提高查找的效率。
- 发送到某个国家,某个省份的数据,可以根据前面若干个指定的比特位来确定是某一个地区的数据,就意味着将其他地区全部排除。
- 一次就可以排除一大批数据从而提高查找效率,这就是子网划分的原因。
根据ip地址的划分,就是能定位到这个ip主机来自哪个区域的。
4.2 IP地址的数量限制:
IP就是一直划分下去吗,从国家划分到省,再划分到市,再划分到区,再划分到镇,村,到家庭,个体用户。
是这样划分的吗??不是的!!
这样的话IP资源永远都不够,光中国网民就8亿,再加上每个人都有几台设备,那就更多了。
- 路由器这样的设备,有些交换机要配置多种ip地址。
- 还有一些IP是不能出现在公网上的。
特殊的IP消耗一部分,一台主机配多个IP,网卡消耗一部分,一个人还可以具有多态设备,那么IP资源肯定是不够的。
子网掩码解决了,分类划分法造成的IP资源浪费的问题,仅仅只是让利用率提高了,但是绝对上限没有增加。
这时候有三种方式来解决:
- 动态分配IP地址: 只给接入网络的设备分配IP地址,因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的。
-
- 但是在公网上,不是路由器就是服务器,哪个设备都要24小时一直工作的。其实也并不能解决问题。
- NAT技术: (后面会重点介绍)。
-
- NAT技术将局域网和公网通的技术经过一定的转化方式,让我们能够让我们在使用IP地址不足的情况下,依旧能够凭空变出很多IP,能够在子网当中工作。
- IPv6: IPv6并不是IPv4的简单升级版,这是互不相干的两个协议,彼此并不兼容。
-
- IPv6用16字节128位来表示一个IP地址,但是目前IPv6还没有普及。
-
- 128个比特位来表示一个IP地址,目前来看
2 ^ 128,已经可以将地球上的每一个砂砾编上一个IP地址了。
- 128个比特位来表示一个IP地址,目前来看
4.3 私有IP地址和公网IP地址:
IP地址除了在自身构成被上分成了网络地址和主机地址,在整体结构上,IP也被拆分成了一个叫做私有IP,一个叫做公网IP。
私有IP和公网IP:
- RFC互联网标准化组织,规定有一些IP地址,是不能放在公网上的,只能用来组件局域网,或者组件子网。
- 这样的IP称作私有IP,除了这批私有IP之外,剩下的才能出现在公网上,叫公网IP。
RFC 1918规定了三个私有IP地址范围,如下所示:
10.*,前8位是网络号,共16,777,216个地址。172.16.到172.31.,前12位是网络号,共1,048,576个地址。192.168.*,前16位是网络号,共65,536个地址。- 包含在这个范围中的,都成为私有IP,其余的则称为全局IP(或公网IP)。
4.4 私有IP是如何解决IP不足的问题的:
- 因为家用路由器构建的是局域网,两个家庭构建的局域网,只能用私有IP,但是可以相同。
- 不同的子网,不同的家庭,但是路由器虚拟出来的IP地址是完全一样的,这种IP因为不会出现在公网上,是私有IP。
- 在局域网的主机是可以直接通信的。
- 对外上网时(夸局域网),家庭的路由器,私有IP并不会通过家用路由器直接到达公网了,它做不到。
- 而是家庭路由器将数据推送给运营商的路由器,运营商再把数据交给公网,在公网当中帮我们请求了对应的服务。
为什么家用路由器不能直接访问公网呢而是要先访问运营商呢?
- 因为家庭的网是运营商拉的,顺着网线找就能找到运营商的机房,集群,基站之类的。
- 换言之运营商将网线拉到家里面,数据出去的时候一定要走过运营商。
- 所以不能绕过运营商直接到公网,在物理上就不能。
一般家用路由器有两套密码:
- 第一套是自己设置的wifi密码,将路由器名称选中,设置一下密码就可以。
- 第二套密码是家用路由器内部,可以通过浏览器去访问,它有IP地址。
- 因为局域网内的主机可以直接访问,所以可以直接访问路由器的IP地址,有一个网页会配置路由器的。
- 限制连接路由器的手机,电脑的个数,包括限制一些上行或下行的速度。
- 还有配置路由器的内部的账号和密码。
运营商会通过账号来认证,如果网费余额不足,运营商路由器直接将发送的报文丢弃掉。
但是可以给运营商发消息,这就是为什么手机欠费了上不了网了,但是依旧能够打通10086的原因。
4.5 NAT技术(出去的问题):
局域网中的数据,发送到公网,是需要不断替换原IP来完成的 —— NAT
先来提出几个问题:
- 在我们平时上网时,给服务端发送报文,服务端给我们响应,难道服务端给我们响应时,目的IP填的是我们的私有IP吗?
-
- 曾经我们说过,公网IP在公网中出现,私有IP不能在公网中出现。
- 如果我们发送给服务器的报文中,源IP填的是私有IP,最后被发到了公网上,那不就叫做IP地址出现在公网上了吗?
- 因为每一个家用路由器都可以用来构建子网,大家构建的子网IP可以一样,对于服务器响应回来的时候,响应到哪里呢?
为了保证私有IP不要出现在公网上,同时也要保证消息能够推送回来:
- 所以一般路由器至少要有两个网口,一个叫做LAN(Local Area Network)口,一个叫做WAN(Wide Area Network)口。
- 其中路由器一方面连接的是家里的私网,另一方面连接的是运营商(运营商内部自己构建的也是一个私网)。
数据包发送过程(路由):
- 当数据包想转发出去的时候,源IP地址填的是私网IP,目的IP填的是公网IP。
- 当数据包转发到达家用路由器,肯定可以到,因为家用路由器的子网IP和家用设备的IP在同一个网段也叫在同一个局域网。
-
- 家用路由器的子网IP也叫LAN口IP。
- 同一个局域网的主机可以直接通信,所以这个数据包就转给路由器了。
- 路由器会自动做一件事情,将家用路由器收到的LAN口IP,替换成家用路由器的WAN口IP。
紧接着:
- 家用路由器就替我们将对应的数据再进行转发到了运营商对外的路由器上。
- 运营商自己也是个私网,也有自己的子网IP,路由器也有LAN口IP和WAN口IP。
- 运营商对外的路由器用的依旧是私网IP也不能用,那么就继续替换当前报文中的 “源IP”,替换成运营商对外的路由器的WAN口IP。
流程图:

利与弊:
- 所以就可以不断地构建局域网,照样让每个局域网使用公网资源了。
- 因为局域网的IP是大量可以重复的,相当于隐性的增加了IP地址的数量。
- 因为有了NAT的存在也严重阻碍了IPv6的发展。
补充:
- 网划分的时候,我们国家在搭建基础网络时,把公网IP划分成到某个省。
- 在省级别架设一个公网集群, 每个省都有一个代表路由器,然后在省内部搭建大型局域网。
总之可以有多个不同的局域网,但是内部实用的IP地址是完全一样的,因为该IP地址只会在局域网中被使用,不会出现在公网上,当我们在访问外网时,可以不断源IP地址替换的方式,然后再进行所谓的交付到公网。
4.6 NAT技术(回来的问题):
当服务器响应时:
- 因为该运营商的WAN口IP已经属于公网了,那么传送的报文的源IP就是运营商的WAN口IP。
- 然后数据包发送到 “抖音服务端”,然后响应发送报文,目的IP填充的就是运营商对外的路由器的WAN口IP。
虽然我们不同家庭局域网中的源IP一样,但是当我们一旦推送到对应的公网当中,出口路由器用的是不同的。所以一定会再退回来,后续再做内网转发,就可以了。
很多学校,家庭,公司内部采用每个终端设置私有IP,而在路由器或必要的服务器上设置WAN口IP。
公网IP在全球必须唯一,而私有IP在其所属网段内必须唯一。
刚刚讲的是数据如何从内网推到公网的过程,但是如何被推回来呢?
也就是说服务器只能将响应的IP报文推送至发送主机局域网的对外路由器那里,至于如何内网转发,该如何完成?
在公网访问的时候呢,路由器要维护一张转化表:
- 在进行源IP地址替换的时候,不仅仅只能是将源IP替换,源端口想替换也可以替换,最后能恢复出来就行了。
- 所以访问外网,在出路由器的时候,不仅仅把源IP做了转换,还在路由器的内部维护了一张,外部请求和内部主机之间的映射关系。
- 除了转化之外,在转化表中新建了KV的映射关系。
如图所示:
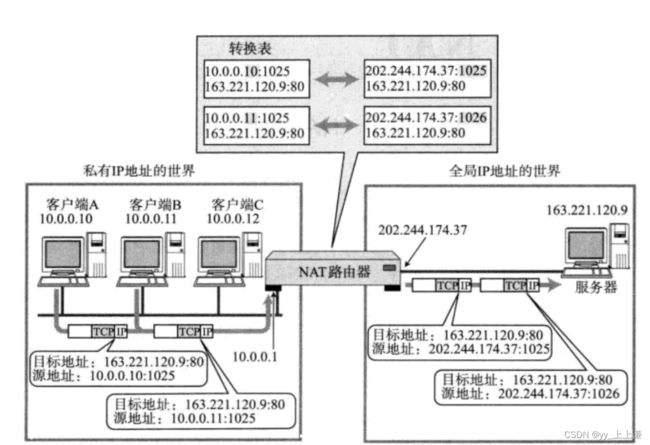
服务器收到请求当它响应回来的时候,一定是在表中从右向左去查的:
- 虽然WAN口IP地址一样,但是WAN口IP的端口号是不一样的。
- 就可以找到该信息曾经是被哪个内网IP地址转化过来的。
- 再把报文当中的被替换的IP地址(WAN口IP)再更换成转化表左侧的目的IP地址。
- 进而让路由器将报文交给正确的内网主机。
小结:
- 因为源IP源端口,目的IP目的端口,它是在全网当中能够标定唯一的一条连接。
- 所以这四元组(对应表中的四个 ip + port ):
-
- 私有IP能标定局域网内客户端A到路由器的唯一性。
-
- 路由器的WAN口IP能够标定路由器到服务器的唯一性。
-
- 发送和响应就能实现互为Key值的效果。
当报文进局域网或出局域网就可以快速地进行转化,这种技术就叫做NAT,这种技术就叫做NAPT。
5. 其他
运营商会对请求的内容做审核,有非法直接就把报文丢了,访问就失败了。
我们不禁有个疑问:
- 我们之前不是学过https对报文进行加密了吗,那么中间人运营商是怎么知道我的报文内容的呢?
-
- https是在握手成功之后才加密的,握手之前要获取目标主机的证书和公钥。
-
- 然后客户端才能够加密对称密钥X,服务用自己的私钥端解密出对称密钥才能够通信。
-
- 在加密之前,服务端响应的明文证书中有域名,运营商是知道的!!
国内IP资源的划分:
- 全球的国家都要对IP资源争夺,32位的比特序列。
- 按照国家分,前9个比特位用来划分国家和一些特殊的地区,在国家内部在剩下的比特位中,拿几个来划分省。
- 其中省和省之间构建了公网,就可以在省之间进行报文转发了。
- 那么某个省用的IP划分市区就是,将再剩下的几个比特位中再划分。
- 当然划分到一定程度,就可以构建局域网,用NAT技术源IP的替换。
路由的过程:
- 报文在数据路由的时候,因为IP地址被分成两块,一部分叫做目标网络,一部分叫做目标主机。
- 所以报文在路上传送的时候,先要根据目的网络将数据先送到目的网络。
- 然后在目的网络内根据IP的目标主机进行内网转发,将数据发送到目标主机,这就是路由的过程。
路由表:
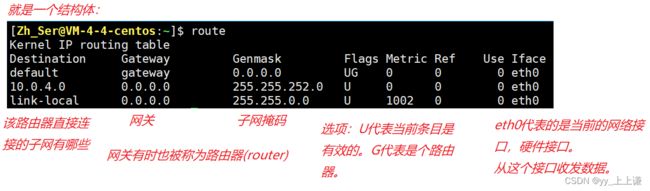
每一个主机,只要能在网络层工作,系统都要维护一个路由表。
- 当IP数据包到达路由器时,路由器会先查看目的IP。
- 路由器内部配置了子网掩码的,拿着IP报文提取出目的IP,将二者按位与,就得到了目标网络号。
- 在自己路由器内的路由表中进行查找,路由器会决定将报文转发给下一跳或者是默认路由,或者是目标主机。
在Linux下查看路由表:
数据包必须一跳一跳的去转发,而从一个主机跳到下一个主机,但是有一个前提条件:
- 相邻的两个主机一定在同一个局域网!!
- 两个主机之间的转发数据,本质是将数据在一个个的子网中进行转发。
- 而路由器就是属于两个局域网的设备。