决策树工程化
决策树工程化
- 决策树工程化
-
- 基本决策树
-
- 1.决策树关键变量说明
- 2.工程化代码(这里以python代码作为示例)
- 随机森林
-
- 1.决策树关键变量说明
- 2.工程化代码(这里以python代码作为示例)
决策树工程化
基本决策树
1.决策树关键变量说明
import m2cgen as m2c
from io import StringIO
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
g_fw = open('log.txt','w')
clf = DecisionTreeClassifier(criterion='gini', random_state=0, max_depth=3)
iris = load_iris()
clf.fit(iris.data, iris.target)
print(clf.feature_importances_, file=g_fw)
code = m2c.export_to_python(clf)
print(code, file=g_fw)
g_fw.close()
print(clf.tree_.feature)
print(clf.tree_.n_node_samples)
print(clf.tree_.threshold)
print(clf.tree_.value)
tree.plot_tree(clf)
#plt.savefig("clf.png")
plt.show()
输出结果为
// print(clf.tree_.feature) 对应树的示意图(树一共有9个节点),3表示特征x[3],-2表示业主节点,前序遍历的方式
[ 3 -2 3 2 -2 -2 2 -2 -2]
//print(clf.tree_.n_node_samples) 对应树的示意图(树一共有9个节点)每个节点上的样本数目
[150 50 100 54 48 6 46 3 43]
//print(clf.tree_.threshold)对应树的示意图(树一共有9个节点)每个节点上的决策阈值
[ 0.80000001 -2. 1.75 4.95000005 -2. -2.
4.85000014 -2. -2. ]
//print(clf.tree_.value) 对应树的示意图(树一共有9个节点)每个节点上的决策阈值之后的每个类别的样本个数(这里一共3个类别)
[[[50. 50. 50.]]
[[50. 0. 0.]]
[[ 0. 50. 50.]]
[[ 0. 49. 5.]]
[[ 0. 47. 1.]]
[[ 0. 2. 4.]]
[[ 0. 1. 45.]]
[[ 0. 1. 2.]]
[[ 0. 0. 43.]]]
对应的示意图

2.工程化代码(这里以python代码作为示例)
def score(input):
if (input[3]) <= (0.800000011920929):
var0 = [1.0, 0.0, 0.0]
else:
if (input[3]) <= (1.75):
if (input[2]) <= (4.950000047683716):
var0 = [0.0, 0.9791666666666666, 0.020833333333333332]
else:
var0 = [0.0, 0.3333333333333333, 0.6666666666666666]
else:
if (input[2]) <= (4.8500001430511475):
var0 = [0.0, 0.3333333333333333, 0.6666666666666666]
else:
var0 = [0.0, 0.0, 1.0]
return var0
以上结果依赖:阈值;特征索引;每个节点的每个类别占比
随机森林
1.决策树关键变量说明
import m2cgen as m2c
from io import StringIO
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
import matplotlib.pyplot as plt
g_fw = open('log.txt','w')
#clf = DecisionTreeClassifier(criterion='gini', random_state=0, max_depth=3)
clf = RandomForestClassifier(n_estimators=3, criterion='gini', random_state=0, max_depth=3)
iris = load_iris()
#每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征
clf.fit(iris.data, iris.target)
print(clf.feature_importances_, file=g_fw)
code = m2c.export_to_python(clf)
print(code, file=g_fw)
g_fw.close()
print("===============000============")
clf0 = clf.estimators_[0]
print(clf0.tree_.feature)
print(clf0.tree_.n_node_samples)
print(clf0.tree_.threshold)
print(clf0.tree_.value)
tree.plot_tree(clf0)
plt.show()
print("===============111============")
clf1 = clf.estimators_[1]
print(clf1.tree_.feature)
print(clf1.tree_.n_node_samples)
print(clf1.tree_.threshold)
print(clf1.tree_.value)
tree.plot_tree(clf1)
plt.show()
print("===============222============")
clf2 = clf.estimators_[2]
print(clf2.tree_.feature)
print(clf2.tree_.n_node_samples)
print(clf2.tree_.threshold)
print(clf2.tree_.value)
tree.plot_tree(clf2)
#plt.savefig("clf.png")
plt.show()
输出结果
===============000============
[ 3 -2 2 3 -2 -2 2 -2 -2]
[94 31 63 32 29 3 31 3 28]
[ 0.75 -2. 4.85000014 1.65000004 -2. -2.
5.04999995 -2. -2. ]
[[[47. 44. 59.]]
[[47. 0. 0.]]
[[ 0. 44. 59.]]
[[ 0. 43. 3.]]
[[ 0. 42. 0.]]
[[ 0. 1. 3.]]
[[ 0. 1. 56.]]
[[ 0. 1. 3.]]
[[ 0. 0. 53.]]]
===============111============
[ 3 -2 3 2 -2 -2 2 -2 -2]
[100 33 67 39 35 4 28 2 26]
[ 0.80000001 -2. 1.75 4.95000005 -2. -2.
4.85000014 -2. -2. ]
[[[46. 62. 42.]]
[[46. 0. 0.]]
[[ 0. 62. 42.]]
[[ 0. 61. 5.]]
[[ 0. 58. 0.]]
[[ 0. 3. 5.]]
[[ 0. 1. 37.]]
[[ 0. 1. 2.]]
[[ 0. 0. 35.]]]
===============222============
[ 0 3 -2 3 -2 -2 3 3 -2 -2 2 -2 -2]
[98 40 29 11 10 1 58 24 2 22 34 1 33]
[ 5.54999995 0.80000001 -2. 1.60000002 -2. -2.
1.55000001 0.75000001 -2. -2. 4.6500001 -2.
-2. ]
[[ 0. 2. 51.]]
[[ 0. 1. 0.]]
[[ 0. 1. 51.]]]
每棵树的图示
(1)

(2)
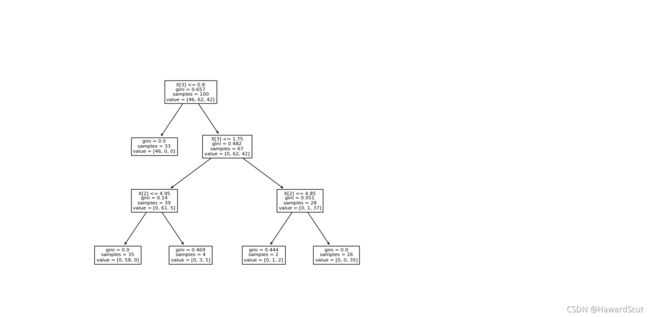
(3)

2.工程化代码(这里以python代码作为示例)
def add_vectors(v1, v2):
return [sum(i) for i in zip(v1, v2)]
def mul_vector_number(v1, num):
return [i * num for i in v1]
def score(input):
# 第1棵树
if (input[3]) <= (0.75):
var0 = [1.0, 0.0, 0.0]
else:
if (input[2]) <= (4.8500001430511475):
if (input[3]) <= (1.6500000357627869):
var0 = [0.0, 1.0, 0.0]
else:
var0 = [0.0, 0.25, 0.75]
else:
if (input[2]) <= (5.049999952316284):
var0 = [0.0, 0.25, 0.75]
else:
var0 = [0.0, 0.0, 1.0]
# 第2棵树
if (input[3]) <= (0.800000011920929):
var1 = [1.0, 0.0, 0.0]
else:
if (input[3]) <= (1.75):
if (input[2]) <= (4.950000047683716):
var1 = [0.0, 1.0, 0.0]
else:
var1 = [0.0, 0.375, 0.625]
else:
if (input[2]) <= (4.8500001430511475):
var1 = [0.0, 0.3333333333333333, 0.6666666666666666]
else:
var1 = [0.0, 0.0, 1.0]
# 第3棵树
if (input[0]) <= (5.549999952316284):
if (input[3]) <= (0.800000011920929):
var2 = [1.0, 0.0, 0.0]
else:
if (input[3]) <= (1.600000023841858):
var2 = [0.0, 1.0, 0.0]
else:
var2 = [0.0, 0.0, 1.0]
else:
if (input[3]) <= (1.550000011920929):
if (input[3]) <= (0.7500000149011612):
var2 = [1.0, 0.0, 0.0]
else:
var2 = [0.0, 0.9696969696969697, 0.030303030303030304]
else:
if (input[2]) <= (4.650000095367432):
var2 = [0.0, 1.0, 0.0]
else:
var2 = [0.0, 0.019230769230769232, 0.9807692307692307]
return mul_vector_number(add_vectors(add_vectors(var0, var1), var2), 0.3333333333333333)
以上结果表明:随机森林将每棵树在叶子节点的输出相加,然后除以1/3(一共3棵树)权重作为最终的输出结果