SpanProto: A Two-stage Span-based Prototypical Network forFew-shot Named Entity Recognition
原文链接:
https://aclanthology.org/2022.emnlp-main.227.pdf
EMNLP 2022
介绍
问题
Few-shot ner之前的方法都是基于对token进行分类,忽略了实体边界的信息,同时大量的负样本(non-entity)也会影响模型的性能。
IDEA
作者提出了一个span-based的two-stage原型网络(SpanProto)来解决Few-shot ner问题;在span提取阶段,将序列tag转化为一个全局的边界矩阵,使得模型能够注意到准确的边界信息。在分类阶段,对每个实体类别计算原型(prototype)embedding,并利用原型学习在语义空间中调整span的表征。另外,为了解决false positive问题,作者设计了一种margin-based损失,来增大false positive和所有原型之间的语义距离。
方法
模型的整体结构如下所示:

一个训练步的数据![]() ,分别表示support set、query set和实体类型集合。对于每个样本
,分别表示support set、query set和实体类型集合。对于每个样本![]() ,
,![]() 表示有L个token的输入序列,
表示有L个token的输入序列,![]() 表示句子X中的span set, y表示X中的实体集。
表示句子X中的span set, y表示X中的实体集。
Span Extractor
该模块用于生成所有的候选span,在每个训练步中,使用support 样本对span extractor进行训练。使用BERT来获得上下文embedding H,送入到span extractor中获取边界信息。
具体的,对于每个span (xi,xj),先计算每个token xi的q和k,然后使用分数函数来计算(xi,xj)是实体span的边界概率,最后基于标记的span,对每一个support sentence生成一个全局边界矩阵。



对于该模块,设计了一个基于span的交叉熵损失来学习边界信息(也就是使真实span的分数最大):

对于训练集中的query 样本,获得span extractor生成的预测全局边界矩阵,将高于阈值的候选span作为预测结果。
Mention Classifier
该模块主要包括两部分:原型学习和基于边界的分类;
引入mention classifier 来为query样本中生成的每个span分配预定义好的实体类别,并利用原学习引导模型学习每个span的语义表征,使其能够迁移到新领域,同时提出基于边界的学习目标来解决false positive从而提高模型性能。
Prototypical Learning
计算support数据中同一实体类别所有span表征的平均,作为该类别的原型向量ct,对于后续span的分类就计算该span与哪一个原型向量更近,即将span与原型向量之间的距离作为衡量span属于哪一类别的依据。
给定训练集![]() ,通过求
,通过求![]() 中同一实体类别中所有span表征的平均来得到该类别的原型向量ct:
中同一实体类别中所有span表征的平均来得到该类别的原型向量ct:

其中Kt表示实体类型t的span数量,![]() 表示span边界表征。
表示span边界表征。
该模块的损失为:

Margin-based Learning
span extractor提取的span中不是ground truth的都视为false positive,如图中的“Italian”、“2011”,但这些span并不是非实体,只是在这个数据集中没有对应的标签,也就是说这些span的类别在该数据集中是不知道的,因此就要使这些span在语义空间上尽可能的远离现有的原型类别。
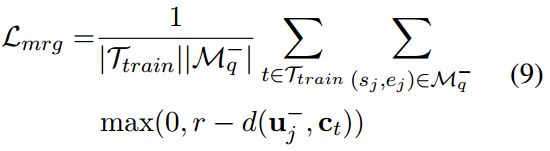
其中u-表示这些span的边界表征。在基于边界的学习中,从所有的原型区域中抽取false positive span,从而获得噪声感知模型。
Training and Evaluation of SpanProto
该框架的训练验证步骤如下所示:

在每个训练步中,从Dtrain中随机抽取一个episode 数据,计算每个support 样本中span的loss(3-8行)训练span etractor,然后每个query 样本进行预测得到候选span,使用原型损失和基于边界损失来训练原型向量(10-15)。整个训练一共包括T步,先对span extractor进行![]() 的预训练,再对span extractor和分类器进行联合训练。
的预训练,再对span extractor和分类器进行联合训练。
进行推理时,计算span extractor提取的所有候选span 与每个原型的距离,选择最近的类别作为预测类别(在预测时,会删掉与原型之间距离大于r的span)。
实验
数据集介绍
首先N-way K-shot表示N种标签,每个类别只有K个样本,作者使用了Few-NERD和CrossNER这两个数据集。
Few-NERD 标注了8种粗粒度实体类型和66种细粒度实体类型(也就是大类别、小类别),包括两种设置:1)Intra:按粗粒度的实体进行分类,也就是训练集、测试集和验证集中包含不同的粗粒度实体类别;2)Inter:按细粒度进行划分,每个粗粒度类中,随机选择60%的细粒度实体作为训练集,随机挑选20%分别作为验证集和测试集。
CrossNER包括4个不同的领域的ner数据集,随机选择两个数据集作为训练集,剩下的分别作为测试集和验证集。
对比实验
作者在不同数据集设置下进行了对比实验,结果如下所示:

消融实验
作者对模型的主要模块进行了消融实验,结果如下:

其中w/o span表示使用传统的token-wise 原型网络框架;w/o Metion classifier表示直接利用k-means对span进行分类(这一块的影响最大);w/o Margin-based learning表示去掉了相关的损失函数。
其他实验
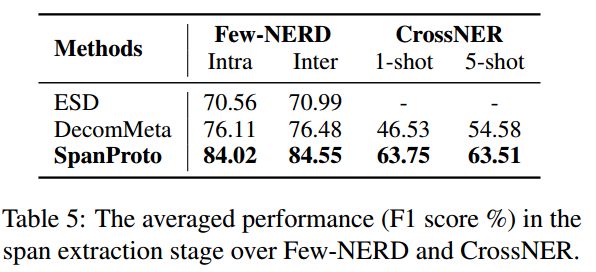
作者对span extractor的效果与其他方法(ESD:利用滑动窗口来获取候选span;DecomMeta:利用BIOE标注方法来检测span)进行了对比实验:
为了探究span extractor是怎么学习span边界,作者对数据集中的某个query sentence的预测全局边界矩阵进行了可视化,如下所示:

作者对预训练步数T和阈值 这两个超参数进行了实验,结果如下所示:
这两个超参数进行了实验,结果如下所示:
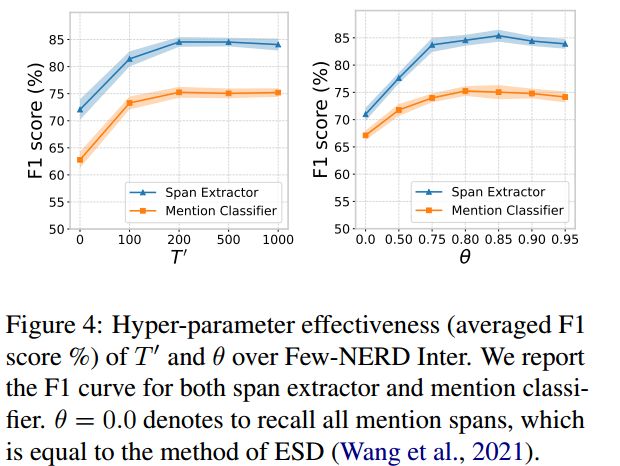
对margin-based learning中的超参数r进行了实验,结果如下所示:

对span 表征在语义空间进行了可视化,如下所示:

可以看出还是能够比较好的分离出false positive样本。
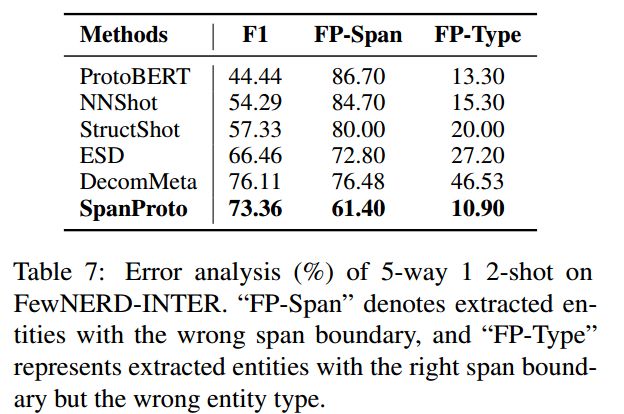
对FP-span(提取出边界错误的实体)和FP-type(表示边界正确,但类别错误)这两种错误进行统计分析,结果如下所示:
总结
不是很懂Few-shot的处理方式,也不是很明白原型学习,而且文中说的margin-based
learning objective这个翻译为基于边界的学习目标,让我有点迷糊,但好像就是使false positive的表征离原型向量尽量远。