机器学习-监督学习之分类算法:K近邻法 (K-Nearest Neighbor,KNN)
目录
- KNN概述
-
- 举个例子:
- K值选取
- 距离计算
-
- 曼哈顿距离,切比雪夫距离关系(相互转化)
- k-近邻(KNN)算法步骤
- 相关代码实现
-
- 简单实例:判断电影类别
-
- 创建数据集
- 数据可视化
- 分类测试
- 运行结果
- K值选取(iris鸢尾花数据集测试)
-
- 运行结果
- sklearn的相关函数简介
-
- train_test_split
- cross_val_score 交叉验证
- 传送门
-
- 绘图相关:Matplotlib
- sklearn相关
- 小函数
- 小问题
KNN概述
k近邻法(k-nearest neighbor, k-NN)是一种基本分类方法。
它的 工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据 都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后通过算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
简单来说,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别
KNN算法主要考虑两个问题:K值的选取和点距离的计算
举个例子:


K值选取
通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值
通过交叉验证计算方差后你大致会得到下面这样的图:

这个图其实很好理解,当 你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。
距离计算
度量 空间中 点的距离,有好几种度量方式,比如常见的欧式距离,曼哈顿距离,切比雪夫距离、马氏距离、巴氏距离等等。不过通常 KNN算法中使用的是欧式距离

欧式距离:

曼哈顿距离
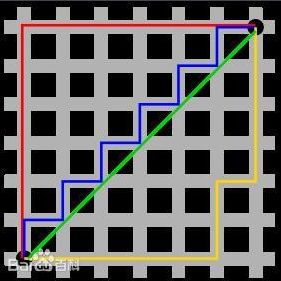
图中 红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。曼哈顿距离——两点在南北方向上的距离加上在东西方向上的距离,即d(i,j)=|xi-xj|+|yi-yj|

曼哈顿距离,切比雪夫距离关系(相互转化)


切比雪夫距离在计算的时候需要取max,往往不是很好优化,对于一个点,计算其他点到该的距离的复杂度为O(n)。而曼哈顿距离只有求和以及取绝对值两种运算,我们把坐标排序后可以去掉绝对值的影响,进而用前缀和优化,可以把复杂度降为 O(1)
k-近邻(KNN)算法步骤
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点所出现频率最高的类别作为当前点的预测分类
相关代码实现
简单实例:判断电影类别
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
import operator
import time
创建数据集
""" CreatDataset
函数说明:创建数据集
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
Modify:
2020-07-9
"""
def CreatDataset():
# 四组二维特征
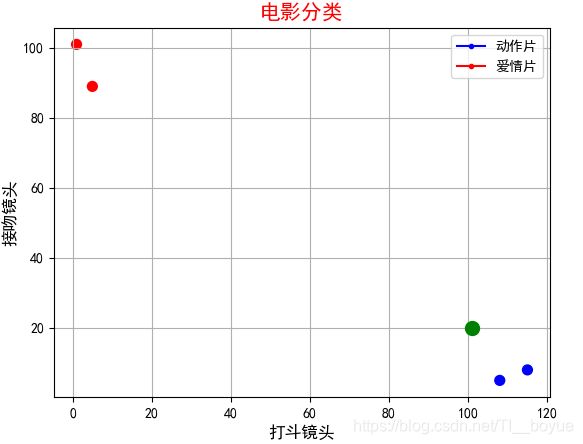
dataMap=np.array([[1,101],[5,89],[108,5],[115,8]])
# 四组特征的标签
labels=['爱情片','爱情片','动作片','动作片']
return dataMap,labels
数据可视化
"""
函数说明:可视化数据
Parameters:
DataMat - 特征矩阵
Labels - 分类Label
Returns:
无
Modify:
2020-07-09
"""
def Visualizaton(DataMat, Labels,test):
# 用于显示正常中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8),figsize=(13,8)
#当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig, axs = plt.subplots(nrows=1, ncols=1)
# 不同标签颜色设置
numberOfLabels = len(Labels)
LabelsColors = []
for i in Labels:
if i == '爱情片':
LabelsColors.append('red')
if i == '动作片':
LabelsColors.append('blue')
# print(LabelsColors)
# 绘制散点图 ,散点大小为15,透明度为1
axs.scatter(x=DataMat[:,0], y=DataMat[:,1], color=LabelsColors,s=50, alpha=1)
#设置标题,x轴label,y轴label
axs0_title_text = axs.set_title(u'电影分类')
axs0_xlabel_text = axs.set_xlabel(u'打斗镜头')
axs0_ylabel_text = axs.set_ylabel(u'接吻镜头')
# 设置横纵及标题字体颜色,大小
plt.setp(axs0_title_text, size=15, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=12, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=12, weight='bold', color='black')
#设置图例
fight = mlines.Line2D([], [], color='blue', marker='.',
markersize=6, label='动作片')
kiss = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='爱情片')
#添加图例
axs.legend(handles=[fight,kiss])
plt.plot(test[0],test[1],color='green',marker = 'o',markersize=10)
# 显示网格线
plt.grid()
#显示图片
plt.show()
分类测试
"""
函数说明:kNN算法,分类器,距离采用欧式距离
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labels - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
Modify:
2020-07-9
"""
def Classification_KNN(inX,dataSet,labels,k):
# 获取样本[4,2]行数,用于重构输入数据[1,2],便于后续运算
dataSetSize=np.shape(dataSet)[0]
# 重构输入数据 inX,并构建差分矩阵
diffMat=np.tile(inX,(dataSetSize,1))- dataSet
sqDiffMat = diffMat**2
# sum()所有元素相加,sum(0)列相加,sum(1)行相加,并降维
sqDistances = sqDiffMat.sum(axis=1)
# 计算数据与每个样本间的距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
# .argsort()方法是将distances中的元素从小到大排列后,提取其原对应的index(索引),然后输出
sortedDistIndices = distances.argsort()
# 统计距离最小的k个点对应类别,及相同类别次数
# 定一个记录类别次数的字典 : {类别,次数}
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
# 统计完成,根据value对字典进行排序
# dict.items() :将字典转换成字典列表,返回形式如下:[(key1,value1),(key2,value2)]
# key=operator.itemgetter(0)根据字典的键进行排序
# key=operator.itemgetter(1)根据字典的值进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
# print(sortedClassCount)
return sortedClassCount[0][0]
def main():
# 创建数据集
group,labels=CreatDataset()
# 创建测试集
test = [101,20]
# 可视化演示
Visualizaton(group,labels,test)
# 分类测试
test_class=Classification_KNN(test, group, labels, 3)
#打印分类结果
print(test_class)
if __name__ == "__main__":
start =time.clock()
main()
end = time.clock()
print('Running time: %f Seconds' %(end-start))
运行结果
![]()
K值选取(iris鸢尾花数据集测试)
from sklearn import datasets #自带数据集
from sklearn.model_selection import train_test_split,cross_val_score #划分数据 交叉验证
from sklearn.neighbors import KNeighborsClassifier #一个简单的模型,只有K一个参数,类似K-means
import matplotlib.pyplot as plt
iris = datasets.load_iris() #加载sklearn自带的数据集
X = iris.data #这是数据 (150,4)
y = iris.target #这是每个数据所对应的标签 (150,)
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=1/3,random_state=4) #这里划分数据以1/3的来划分 训练集训练结果 测试集测试结果
k_range = range(1,31)
cv_scores = [] #用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) #knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
scores = cross_val_score(knn,train_X,train_y,cv=10,scoring='accuracy') #cv:选择每次测试折数 accuracy:评价指标是准确度,可以省略使用默认值,具体使用参考下面。
cv_scores.append(scores.mean())
plt.plot(k_range,cv_scores,'-*')
plt.xlabel('K')
plt.ylabel('Accuracy') #通过图像选择最好的参数
plt.grid()
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=6) # 选择最优的K=6传入模型
best_knn.fit(train_X,train_y) #训练模型
print(best_knn.score(test_X,test_y)) #看看评分
''' 测试评分:98 % '''
运行结果

sklearn的相关函数简介
train_test_split
train_test_split(data,target,test_size, random_state,stratify)
'''
data: 所要划分的样本特征集
target: 所要划分的样本结果
test_size: 如果是浮点数,在0-1之间,表示test set的样本占比;如果是整数的话就表示test set样本数量
random_state:随机数种子——其实就是该组随机数的编号。
比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的;但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子random_state不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数
stratify: 是为了保持split前类的分布;
将stratify=X就是按照X中的比例分配;将stratify=y就是按照y中的比例分配
'''
cross_val_score 交叉验证
cross_val_score((clf, train_data, train_target, cv,scoring='accuracy'))
'''
cv: 设置数据每次折数,即将数据分为 cv 分,一份为测试,其余为训练;
函数返回结果为迭代运行cv次,最后通过 mean 取平均值为训练模型的准确率
设置的折数 cv 需要小于每个类的样本数,否则会报错
'''
传送门
Python3《机器学习实战》学习笔记(一)
深入浅出KNN算法(一) KNN算法原理
机器学习常用的向量距离度量准则
绘图相关:Matplotlib
plt.plot()函数解析(最清晰的解释)
plt.subplots()的使用
python散点图基础—scatter用法
Python中scatter函数参数及用法详解
sklearn相关
sklearn的train_test_split()各函数参数含义解释(非常全)
sklearn的train_test_split的random_state
sklearn.neighbors.KNeighborsClassifier的k-近邻算法使用介绍
使用sklearn的cross_val_score进行交叉验证实例
使用sklearn的cross_val_score进行交叉验证
cross_val_score交叉验证及其用于参数选择、模型选择、特征选择
小函数
浅述python中argsort()函数的用法
字典(Dictionary) items()方法
Python3 sorted() 函数
史上最全关于sorted函数的10条总结
python中的operator.itemgetter函数
小问题
ValueError: n_splits=4 cannot be greater than the number of members in each class