操作系统-浅谈CPU与内存
目录
- 计算机的基本组成
- CPU
- 内存
-
- 虚拟内存
-
- 内存分段
- 内存分页
- CPU与内存的交互过程
- 高速缓存cache
所有图片均来自:小林coding
计算机的基本组成
计算机由软件和硬件组成
硬件由CPU(中央处理器)存储器(内存+外存)外部设备组成。
软件由应用软件和系统软件组成(操作系统,编译器).
CPU
CPU也叫中央处理器
分为运算器 ,控制器 ,寄存器组三部分
其中运算器和控制器又分别有好多小的单元组成
运算器,主要处理所有的算术运算和逻辑运算
算数逻辑单元ALU
累加寄存器AC
数据缓冲寄存器DR
状态条件寄存器PSW
控制器,控制整个CPU的工作,决定计算机运行过程的自动化
程序计数器PC
指令寄存器IR
指令编码器ID
地址寄存器AR
寄存器组
寄存器组可以分为两类,一类是专用寄存器,另外一类是通用寄存器。运算器和控制器里面的寄存器都是专用寄存器组,而通用寄存器的用途广泛可以由程序员规定其用途
内存
内存是用来直接跟CPU进行交互的
虚拟内存
为什么要引入虚拟内存?
:如果所有的程序都是直接操作物理内存,那么当多个程序同时运行时,就可能会对同一个物理地址进行操作,这样就可能会出现错误,所以为了避免这种情况,引入了虚拟内存的概念,程序直接访问的是虚拟内存,虚拟内存经过CPU中的内存管理单元(MMU) 可以转化成对应且不同的物理地址,这样就规避掉了多个程序运行访问同一个物理地址的情况.
CPU将虚拟地址交给MMU,经由MMU转化成物理地址.
虚拟地址和物理地址主要有两种转化关系,分别是内存分段和内存分页.
内存分段
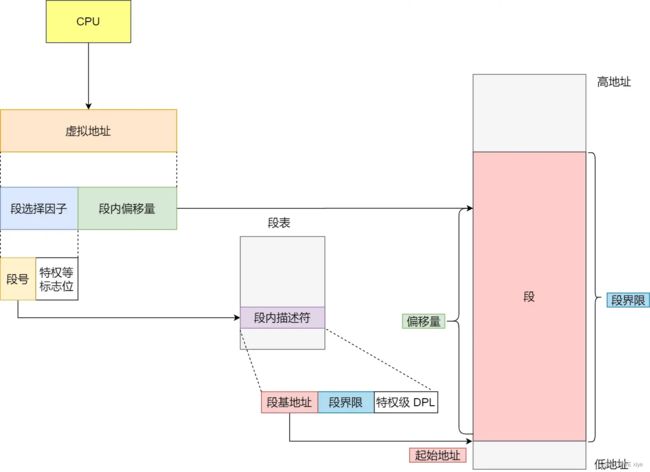
内存分段的情况下,虚拟内存分成两部分,分别是段选择因子和段内偏移量
段选择因子里边最重要的是段号,段号是段表的索引,如下图:
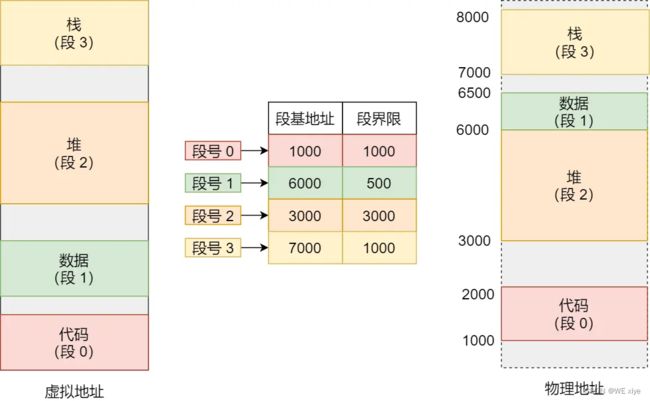
段表由基地址,段界限,特权等级组成
段的基地址+段内偏移量 = 物理地址
内存分段的缺点:
1.会产生大量的外部内存碎片,虽然空闲的内存很多,但都是不连续的,这样就会导致即使空闲内存大小 > 所需要占用的内存大小,但是因为内存不连续就无法使用.
2.内存交换效率低,当交换一大段连续的内存时(将内存数据写入外存),会非常占用时间.
内存分页
内存分页主要解决了内存分段情况下产生的外部内存碎片以及内存交换效率低两个问题.
内存分页情况下,虚拟内存和物理内存之前是通过页表来映射的,而页表也是存放在内存管理单元(MMU)里的. 如果想要访问的虚拟内存在页表中查不到,那么便会返回一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
如何解决产生的外部内存碎片:
页和页之间是紧密排列的,只会产生内部内存碎片(即使程序大小不足一页,也至少需要分配一页内存),而不会产生外部内存碎片
如何解决内存交换速度慢:
当内存不够时或者说是缺页中断时(所需要的页面不在物理内存中),会触发内存交换,把不常用的内存页面释放掉(换出,写入磁盘)然后把需要的内存页面从磁盘写入内存(换入),所以内存分页下的内存交换只需要交换一个或少数几个页就行了,内存交换的效率就比较高.
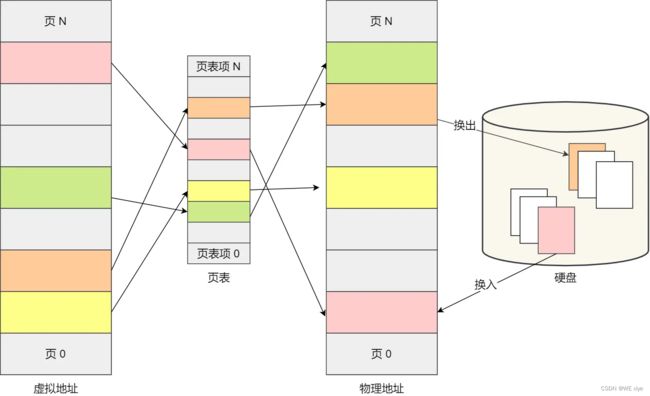
这里涉及到5中内存页面置换算法,分别是:
1.最佳页面置换算法
2.先进先出页面置换算法
3.最近最久未使用页面置换算法
4.时钟页面置换算法
5.最不常用页面置换算法
这里就不多讲解了,但是这部分也是比较重点的内容,
虚拟内存是怎么通过页表跟物理内存映射的?

虚拟内存分为页号和页内偏移量两部分
页号是页表的索引,通过查找页表可以获得物理页号,物理页号+页内偏移量就可以得到物理地址了!
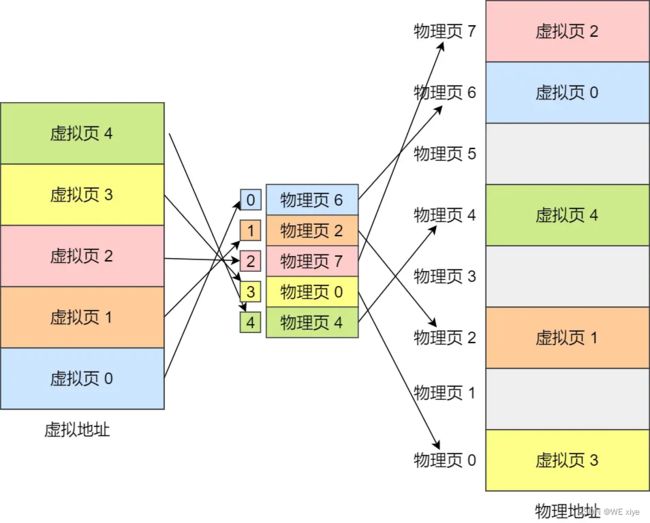
多级页表:
为什么要出现多级页表(摘自小林)
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
所以说引入了多级页表,如图:
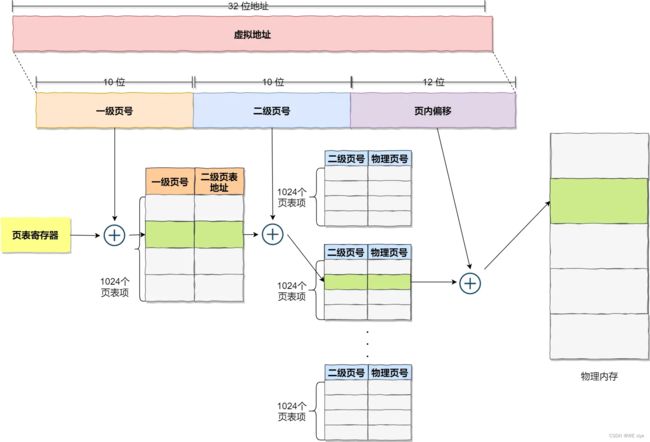
如图,一级页表有1024个页表项,每一个页表项对应着一个二级页表,每一个二级页表又有1024个页表项,一级页表和二级做乘法10241024(2的10次方2的10次方)所以刚好可以覆盖掉4G的虚拟内存
疑问点:
如果一个页表项占用4个字节,那么一级页表此时占(1024*4)=4K
二级页表占用 (1024 * 1024 * 4)=4M
4K + 4M > 4M
所以说如果所有的页表项都被使用的话,二级页表比一级页表还要耗内存
但是计算机存在局部性原理,如果一级页表没有被用到的话,就不会创建对应的二级页表,这也是二级页表省内存的原因.
TLB
把最常访问的几个页表项存放入CPU中的Cache高速缓存里,这个Cache就叫TLB
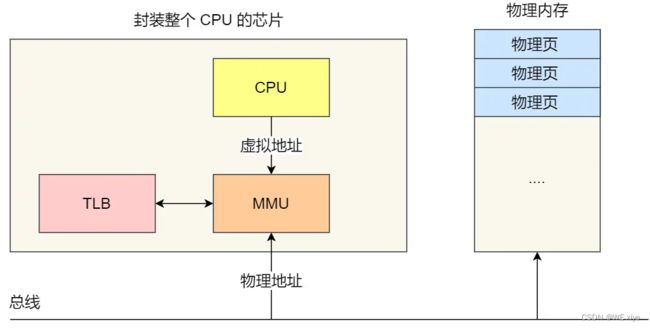
下文会详细说一下CPU中的Cache.
CPU与内存的交互过程
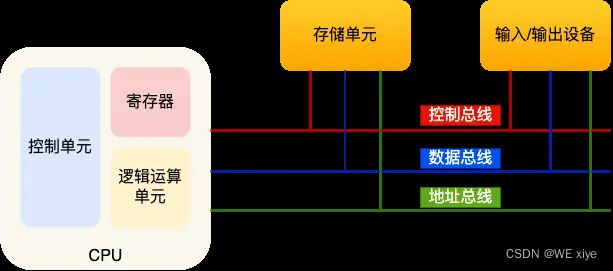
CPU无论是跟内存交换数据,还是跟外设交换数据,都是依赖总线
分别是,控制总线,数据总线,地址总线
地址总线,用于指定 CPU 将要操作的内存地址;
数据总线,用于读写内存的数据;
控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;

执行程序的过程就是执行一条一条指令的过程
-
首先CPU会访问自己的【程序计数器(PC)】,程序计数器里存放的是指令的地址,然后它会通过【控制器】操作【地址总线】来访问内存地址,通知内存要访问的地址,并等待内存把数据准备好,然后接受内存的数据,然后将指令数据存放入【指令寄存器(IR)里】
-
程序计数器(PC)自增,自增的程度取决于CPU的位宽,如果是32位CPU,代表一次能处理4个字节的数据,所以PC自增4
-
检查【指令寄存器(IR)】中指令的类型,如果是运算类型,则交给算术逻辑单元(ALU)如果是存储类型则交给控制单元
高速缓存cache
Cache是位于CPU和内存之间的临时存储器,它的容量比内存小但数据交换速率却快很多。
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
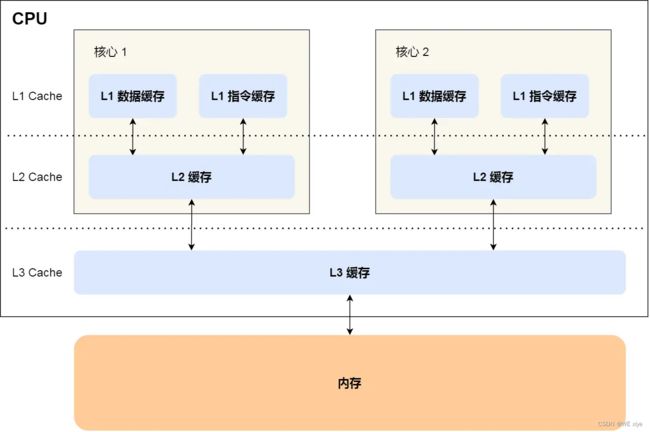
当CPU需要读取数据时,它会首先从Cache中查找。如果数据已经在Cache中(即高速缓存命中),CPU可以直接从Cache中读取数据并处理。这大大减少了从内存中读取数据的延迟,提高了CPU的执行效率。
如果数据不在Cache中(即高速缓存未命中),CPU会从内存中读取数据,并同时把这个数据所在的数据块调入Cache中。这样,如果CPU后续还要读取这个数据块中的其他数据,就可以直接从Cache中获取,而不需要再次访问内存。这种方式有效地减少了CPU访问内存的次数,提高了程序的执行效率。
此外,除了读取本次要访问的数据,CPU还会预取本次数据的周边数据到Cache中。这是基于程序运行的局部性和时间局部性原理,即当一条指令正在被执行时,在很短的时间内,这条指令周围的指令也会有很大的概率被执行。因此,预取周边数据到Cache中可以使得以后对整块数据的读取都从Cache中进行,不必再调用内存。
总之,Cache的出现是为了解决CPU处理速率和主存访问速率差异过大的问题。通过把数据暂时存放在Cache中,CPU可以更快地获取需要的数据,减少了访问内存的延迟,提高了程序的执行效率。