Go和C++通用性能优化黑魔法——PGO!

导读
我们在进行性能优化的时候,往往会应用各种花式的优化手段:优化算法复杂度(从 O(N) 优化到 O(logN) ),优化锁的粒度或者无锁化,应用各种池化技术:内存池、连接池、线程池、协程池等。压缩技术、预拉取、缓存、批量处理、SIMD,内存对齐等等手段后,其实还有一种手段就是 Profile-Guided Optimization (PGO)。本文会介绍 PGO 的原理,以及 Go/C++ 语言进行 PGO 的实践。
目录
1 Profile-Guided Optimization (PGO)原理
2 Go 的 PGO 实践
3 C++的 PGO 时间
4 总体实践和规划
通常情况下,核心系统的性能优化往往是一个研发毕生所学,十八班武艺全管上的持久性项目。但老板从来不管质量、速度、成本只能三选其二的真理,老板永远是全都要。在穷尽性能优化的种种方式以后,老板问:性能还能不能再快一点时,你怎么办?别急,PGO 可以帮你。
Profile-guided optimization (PGO)又称 feedback-directed optimization (FDO) 是指利用程序运行过程中采集到的 profile 数据,来重新编译程序以达到优化效果的 post-link 优化技术。它是一种通用技术,不局限于某种语言。
01
Profile-Guided Optimization (PGO)原理
PGO 首先要对程序进行剖分(Profile),收集程序实际运行的数据生成 profiling 文件,根据此文件来进行性能优化:通过缩小代码大小,减少错误分支预测,重新组织代码布局减少指令缓存问题等方法。PGO 向编译器提供最常执行代码区域,编译器知道这些区域后可以对这些区域进行针对性和具体的优化。
PGO 大体都可以由如下3个步骤,具体细节可能稍微有点差异,后面会讲:
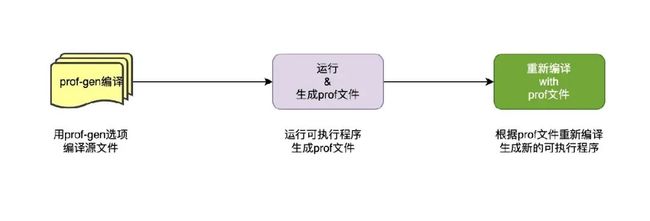
步骤1:
编译的时候添加编译或者链接选项以便在步骤二运行的时候可以生成 prof 文件。例如 clang 的-fprofile-instr-generate、-fdebug-info-for-profiling、-funique-internal-linkage-names 选项等。
步骤2:
该步骤是根据步骤1生成的可执行程序,运行生成 prof 文件。这种通常有两种方法,第一种方法是如上面 clang 的-fprofile-instr-generate 选项,该参数相当于在编译时插桩,运行时自动生成 prof 文件。另外一种称之为 AutoFDO,才运行时候动态采集,C++等可以用 perf,Go 的话更方便 runtime/pprof or net/http/pprof 都可以采集到。
步骤3:
步骤3是根据步骤2的 prof 重新编译,同时有必要的话去掉步骤1中添加的编译参数,重新编译生成新的可执行文件。
1.1 错误分支预测优化
下面用简单的一个 if 判断语句来说明为什么减少错误分支预测可以实现正优化。看下面示例代码:
if condition {
// 执行逻辑1
} else {
// 执行逻辑2
}在编译时,由于编译器并不能假设 condition 为 true 或者 false 的概率,所以按照定义的顺序:如果 condition 为 true 执行逻辑1,如果条件不满足跳跃至 else 执行逻辑2。在 CPU 的实际执行中,由于指令顺序执行以及 pipeline 预执行等机制,因此,会优先执行当前指令紧接着的下一条指令。上面的指令如果 condition 为 true 那么整个流水线便一气呵成,没有跳转的开销。相反的,如果 condition 为 false,那么 pipeline 中先前预执行的逻辑1 计算则会被作废,转而需要从 else 处的重新加载指令,并重新执行逻辑2,这些消耗会显著降低指令的执行性能。
如果在实际运行中,condition 为 true 的概率比较大,那么该代码片段会比较高效,反之则低效。借助对程序运行期的 pprof profile 数据进行采集,则可以得到上面的分支判断中,实际走 if 分支和走 else 分支的次数。借助该统计数据,在 PGO 编译中,若走 else 分支的概率较大(相差越大效果越明显),编译器便可以对输出的机器指令进行调整,使其生成的指令从而对 执行逻辑2更加有利。其实很简单比如汇编指令 je (等于就跳转) 等价替换成 jne(不等于就跳转)。
02
Go 的 PGO 实践
Go 语言从 Go1.20 开始就支持 PGO 优化,不过默认是关闭的 -pgo=off,从 Go1.21 开始 -pgo=auto 默认打开。从我测试的几个 case 来看 Go.1.20 的优化效果并不明显,Go1.21 的优化效果更明显,现在 Go1.21 已经发布建议大家用 Go1.21 及其以上版本。
2.1 Profile 文件采集
Go 的 PGO 需要一个 cpu pprof profile 文件作为一个输入,可喜的是 Go profile 文件的生成已经集成到了运行时:( runtime/pprof and net/http/pprof)可以直接采集获取。当然其他的格式的文件比如上述 Linux perf 的满足一天基本的前提条件可以可以转换成 pprof format 为 Go PGO 所用。最简单的方法是:curl -o cpu.pprof "http://localhost:8080/debug/pprof/profile?seconds=30" 从服务的任意实例获取 30s 的数据。由于下述的原因 30s 的数据可能不具有代表性:
该实例在执行分析时候比较空闲,尽管它平时可能比较忙。
该实例的流量某天发生了变化导致实例行为也发生了变化。
在不同的时间段执行不同的操作类型,可能该 30s 的采样间隔只能覆盖单一的操作类型。
该实例有异常流量。
其他。
比较稳健的做法是不同时间收集不同实例的 profile 文件,然后合并成一个文件给 PGO 使用,以限制单个 profile 文件的影响。
go tool pprof -proto a.pprof b.pprof > merged.pprof需要注意的是,profile 文件的收集都是要从生成环境获得实际最真实的运行情况,这样的优化效果才最好。单元测试或者部分的基准测试不适合 PGO 优化,因为它支持程序的一小部分收效甚微。
2.2 PGO 的迭代构建
正如上面所说,建议采用 Go 1.21 以上版本,标准的构建方法是将 default.pgo 文件放在 main package 所在的目录,Go 编译器探测到 default.pgo 自动开启 PGO 优化。除了这种方式外,也可以指定 profile 文件路径。
go build -pgo=/pprof/main.pprof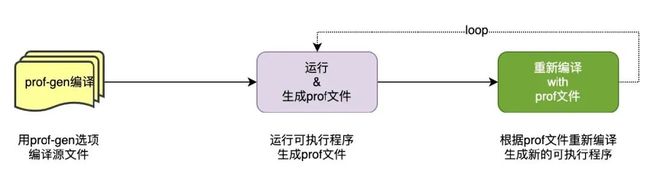
由于程序一直在开发迭代,所以步骤2和步骤3是一个循环过程。步骤2中的 profile 文件对应的源代码跟最新的源代码可能是不一样的,Go PGO 的实现对此具有鲁棒性,称之为源稳定性。同样在经过一次迭代后,二进制的版本也是使用上次 profile 文件已经优化后的版本,Go PGO 的实现同样对此具有鲁棒性,称为迭代鲁棒性。
2.2.1 PGO 源鲁棒性
源稳定性是通过使用启发式方法将配置文件中的示例与编译源进行匹配来实现的。因此,对源代码的许多更改(例如添加新功能)对匹配现有代码没有影响。当编译器无法匹配更改的代码时,一些优化会丢失,但请注意,这是一种优雅的降级。单个函数未能匹配可能会失去优化机会,但总体 PGO 收益通常会分布在多个函数中。
Go 的 PGO 尽最大努力继续将旧配置文件中的样本与当前源代码进行匹配。具体来说,Go 在函数内使用行偏移(例如:调用函数的第10行),总的来说存在两种情况:一种是破坏匹配,另外一种没有破坏匹配。
许多常见的修改不会破坏匹配:
在热函数之外更改文件(在函数上方或下方添加/更改代码)。
将函数移动到同一包中的另一个文件(编译器完全忽略源文件名)。
还有一些修改会破坏匹配:
热函数内的更改(可能会影响行偏移)。
重命名函数(和/或方法的类型)(更改符号名称)。
将函数移动到另一个包(更改符号名称)。
如果 profile 相对较新,则差异可能只会影响少数热门函数,从而限制了无法匹配的函数中错过优化的影响。尽管如此,随着时间的推移,profile 慢慢变旧,性能下降会慢慢累积,因为代码很少被重构回旧的形式,因此定期收集新的 profile 以限制生产中的源偏差非常重要。
profile 文件匹配度可能显著降低的一种情况是大规模重构,即重命名许多函数或在包之间移动它们。在这种情况下,您可能会受到短期性能影响,直到新的 profile 文件构建生效。
2.2.2 迭代鲁棒性
迭代稳定性是为了防止连续 PGO 构建中的可变性能循环(例如,构建 1 快,构建 2 慢,构建 3 快,等等)。我们使用 CPU profile文件来识别要优化的热门函数调用。理论上,PGO 可以大大加快热函数的速度,使其在下一个 profile 中不再显示为热函数,并且不会得到优化,从而使其再次变慢。Go 编译器对 PGO 优化采取保守的方法,他们认为这可以防止出现重大差异。
2.2.3 总结
假如 Go PGO 不能保证源稳定性和迭代稳定性,那我们就需要采样二阶段构建的方式发布我们的服务。第一阶段构建一个未启用 PGO 优化的版本,灰度发布到生产环境,然后采集对应的 profile 文件。第二阶段根据采集的 profile 文件启用 PGO 优化,再次全量发布到生成环境。
2.3 实践结果
在我们的辅助 sidecar 程序采用 Go 1.21 开启 PGO 优化后,大概有5%性能提升,Go 官方给的数据大概是2~7%提升。业务程序也部分开始应用 PGO 进行优化。Go 未来 PGO 会继续迭代优化,我们可以持续关注下。
2.4 Go PGO 未来
关于这个问题 Go 语言 member @aclements 在 PGO 的一个 issue 里有提到过 PGO 可以优化的非完全列表:
内联(这个已经很常规了)。
函数块排序,对函数块进行排序,聚焦热块改进分支预测。
寄存器分配,目前寄存器分配采用启发式确定热路径和移除,PGO 可以告知真正的热路径。
函数排序,在整个二进制的级别对函数进行排序和聚集,以后更好的局部性。
全局块排序,超越函数排序的一步,其集中形式可能是冷热分离,也有可能比这更激进。
间接调用去虚拟化,这里后面跟 C++ 的类似(后面 C++ 会详细讲下这里)。
模版化,基于 profile 将模版化热通用函数。
map/slice 的预分配。
生命周期分配,将具有相似生命周期的分配放在一起。
03
C++ 的 PGO 实践
根据 profile 可以优化寄存器的分配,优化循环的矢量化(针对只有少数几个迭代的循环不做 vectorize,vecrorize 会增加而外的运行成本),提升分支预测的准确性等。C++ 中虚函数的 Speculative devirtualization 优化技术就依赖于分支预测的准确性,下面会重点讲下。
3.1 虚函数优化
C++的虚函数使用起来非常方便,代码的抽象层次也非常好,但是他还是有一定的开销相比普通函数,如果大量使用虚函数在性能要求非常高的场景对性能还是有一定的影响,主要体现在如下的方面:
空间开销:由于需要为每一个包含虚函数的类生成一个虚函数表,所以程序的二进制文件大小会相应的增大。其次,对于包含虚函数的类的实例来说,每个实例都包含一个虚函数表指针用于指向对应的虚函数表,所以每个实例的空间占用都增加一个指针大小(32位系统4字节,64位系统8字节)。这些空间开销可能会造成缓存的不友好,在一定程度上影响程序性能。
虚函数表查找:虚函数增加了一次内存寻址,通过虚函数指针找到虚函数表,有一点点开销但是还好。
间接调用(indirect call)开销:由于运行期的实际函数(或接口)代码地址是动态赋值的,机器指令无法做更多优化,只能直接执行 call 指令(间接调用)。对于直接调用而言,是不存在分支跳转的,因为跳转地址是编译器确定的,CPU 直接去跳转地址取后面的指令即可,不存在分支预测,这样可以保证 CPU 流水线不被打断。而对于间接寻址,由于跳转地址不确定,所以此处会有多个分支可能,这个时候需要分支预测器进行预测,如果分支预测失败,则会导致流水线冲刷,重新进行取指、译码等操作,对程序性能有很大的影响。
无法内联优化:由于 virtual 函数的实现本身是多态的,编译中无法得出实际运行期会执行的实现,因此也无法进行内联优化。同时在很多场景下,调用一个函数只是为了得到部分返回值或作用,但函数实现通常还执行了某些额外计算,这些计算本可以通过内联优化消除,由于无法内联,indirect call 会执行更多无效的计算。
阻碍进一步的编译优化:indirect call 相当于是指令中的一个屏障,由于其本身是一个运行期才能确定的调用,它在编译期会使各种控制流判断以及代码展开失效,从而限制进一步编译及链接的优化空间。
3.2 Basic devirtualization
我们通过下面一个例子来简单说明编译器是如何去虚拟化的:
class A {
public:
virtual int foo() { return ; }
};
class B : public A {
public:
int foo() { return 2; }
};
int test(B* b) {
return b->foo() + ; }当调用 test(B *b) 里面的 b->foo() 函数时,编译器并不知道 b 是一个真正的 B 类型,还是 B 的子类型,所以编译生成的代码会包含间接调用(indirect call 行:19)针对虚函数调用(b->foo())。gcc 9 生成的汇编代码如下(裁剪后):
12 subq $16, %rsp
13 movq %rdi, -8(%rbp)
14 movq -8(%rbp), %rax
15 movq (%rax), %rax
16 movq (%rax), %rdx
17 movq -8(%rbp), %rax
18 movq %rax, %rdi
19 call *%rdx
20 addl $3, %eax我们把上面 class B 的代码改一下,增加关键词 final :
class B : public A {
public:
int value() final { return 2; }
};这样编译器知道 class B 不可能有子类,可以进行去虚拟化优化(-fdevirtualize ),汇编代码如下:
6 _ZN1B3fooEv:
7 .LFB1:
8 .cfi_startproc
9 pushq %rbp
10 .cfi_def_cfa_offset 16
11 .cfi_offset 6, -16
12 movq %rsp, %rbp
13 .cfi_def_cfa_register 6
14 movq %rdi, -8(%rbp)
15 movl $2, %eax
16 popq %rbp
17 .cfi_def_cfa 7, 8
18 ret
19 .cfi_endproc
20 .LFE1:
21 .size _ZN1B3fooEv, .-_ZN1B3fooEv
22 .text
23 .globl _Z4testP1B
24 .type _Z4testP1B, @function
25 _Z4testP1B:
26 .LFB2:
27 .cfi_startproc
28 pushq %rbp
29 .cfi_def_cfa_offset 16
30 .cfi_offset 6, -16
31 movq %rsp, %rbp
32 .cfi_def_cfa_register 6
33 subq $16, %rsp
34 movq %rdi, -8(%rbp)
35 movq -8(%rbp), %rax
36 movq %rax, %rdi
37 call _ZN1B3fooEv
38 addl $3, %eax
39 leave
40 .cfi_def_cfa 7, 8
41 ret
42 .cfi_endproc可以看到间接调用已经修改成直接调用,当然这里可以进一步优化成一条指令:
6 .LFB2:
7 .cfi_startproc
8 movl $5, %eax
9 ret
10 .cfi_endproc3.3 Basic devirtualization
根据实际运行情况,去推导去虚拟化。还是举一个简单的例子来说明下:A* ptr->foo(),ptr 是一个指针,他可以是 A 也可以是 B,甚至是他们的子类,编译器在编译无法确定其类型。假设在实际的生产环境中的,ptr 大概率是 A 对象,而不是B对象或者其子类对象,speculative devirtualization,gcc 的编译参数(-fdevirtualize-speculatively) 优化就会尝试进行如下的转换:
if (ptr->foo == A::foo)
A::foo ();
else
ptr->foo ();经过此转换后,将间接调用转换成直接调用,就可以进行直接调用优化,比如说 inline 等。
3.4 实践结果
最近正在进行 envoy 的性能优化测试,测试详情如下。
硬件设施为 V8 的虚拟机(母机为 M6 的机器),参数如下:
model name : Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
cpu MHz : 2494.140
cache size : 36608 KBenvoy 版本为 V1.26.0,未开启熔断和限流配置,开启了 tracing 采样率为万分之一,测试数据 playload 1k,rpc 协议为 srf 协议。
编译器为 clang14,具体结果如下:
| 基础参数 | 连接数 | 单核 qps | 平均延时(ms) |
| 未开启 PGO | 100 | 20k | 4.87 |
| 开启 PGO | 100 | 23.7k | 4.28 |
可以看出在开启 PGO 优化的情形下,平均时延减少14%~18%,QPS 提升15%~18%左右。
-End-
原创作者|黄欣欣

关于性能优化你还有什么小妙招?欢迎分享。我们将选取1则最有意义的评论,送出腾讯云开发者-手机支架1个(见下图)。10月26日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)




(PS:后台回复1019获取本期封面表情包)