awk学习笔记1-常用awk操作
(一)awk简介
linux 三剑客之awk,AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。grep,sed和awk都是读一行处理一行,直到处理完成。
grep : 过滤文本
sed : 修改文本
awk : 处理文本(主要用来格式化,将文本按照指定的格式输出)
(二)awk语法
常见的三种形式
awk [选项] '[pattern] action' 处理对象
标准输出 | awk [选项] '[pattern] action'
awk [选项] 'BEGIN{ commands } /pattern/ { commands } END{ commands }' 处理对象1.常用选项
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令
2.常用pattern
这是一个正则表达式,用于匹配文件中的行 //
^匹配行首
$匹配行尾
.匹配任意1个字符
*匹配前面的字符出现0次或多次
+匹配前面的字符出现1次或多次
?匹配前面的字符出现0次或1次
[]匹配方括号中任意一个字符
[^]匹配不在方括号中的任意一个字符
3.常用action
这是一个命令序列,对常见的行进行处理
print 打印匹配的行或者指定的字段
printf 格式化输出 注意这个不换行的哦
printf : 格式化打印
%s : 字符串
%d : 数字
- : 左对齐
+ : 右对齐
15 : 至少占用15字符
if-else 条件判断
for 循环处理
while 循环处理
getline 从文件中处理一行
next 跳过当前行
exit 结束awk命令
4.处理对象
这个就是我们要处理的文本,没啥特别的
5.awk语句中的BEGIN和END
awk中可以有多个pattern{action},只需要直接连用即可,这里的BEGIN和END就是pattern的一种特殊形式,BEGIN携带的action是在开始处理文本数据之前先要执行的,而END携带的action则是在处理文本数据结束后才执行的。
(三)awk内置变量
NF 当前行的字段数量
NR 当前行的行号,从1开始
FNR 各文件分别计数的行号,输入多个文件时,NR越来越大,FNR在换到另一个文件里就从1开始了,很好理解吧
$0 完整的输入记录,也就是当前行的全部内容
$n 当前记录的第n个字段,字段间由FS分隔
FS 字段分隔符(默认是任何空格)
RS 记录分隔符(默认是一个换行符)
OFS 输出字段分隔符,默认值与输入字段分隔符一致。
ORS 输出记录分隔符(默认值是一个换行符)
FILENAME 当前文件名
IGNORECASE 如果为真,则进行忽略大小写的匹配
(四)awk执行流程
BEGIN{} : 最开始执行
// : 正则
{} : 循环体
END{} : 最后执行
这里面最少有一个,最多有四个
1、通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。
2、完成 BEGIN 块的执行,开始执行body块。
3、读入有 \n 换行符分割的记录。
4、将记录按指定的域分隔符划分域,填充域,$0 则表示所有域(即一行内容),$1 表示第一个域,$n 表示第 n 个域。
5、依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。
6、循环读取并执行各行直到文件结束,完成body块执行。
7、开始 END 块执行,END 块可以输出最终结果。
(五)常用操作
1.截取文档中的某个段
-- F指定域分割符号,输出第一列和第二列
cat /etc/passwd |awk -F ':' '{print $1,$2}'
2.匹配字符或者字符串
--print也可以不用直接用,默认输出行
cat /etc/passwd |awk '/bash/'
-- 只匹配有/bin/bash的行的用户,nologin的用户不显示
cat /etc/passwd |awk -F ':' '/\/bin\/bash/ {print $1}'
-- 匹配以n结尾,包含ftp文本的用户, 打印的是后可以用双引号打印自己想要的数
cat /etc/passwd |awk -F ':' '/.*ftp.*n$/ {print "用户:" $1}'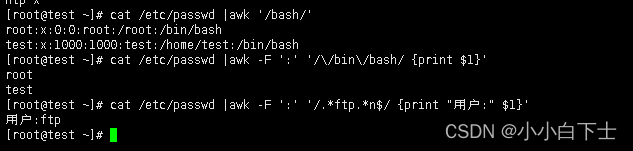
3.条件操作符
运算符 描述
~ : 使用正则匹配
!~ : 不匹配正则匹配|| 逻辑或
&& 逻辑与
< <= > >= != == 关系运算符
空格 连接
+ - 加,减
* / % 乘,除与求余
+ - ! 一元加,减和逻辑非
$ 字段引用
awk中同时提供了print和printf两种打印输出的函数。其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂
--匹配uid>1000的用户全部信息
cat /etc/passwd |awk -F ':' '$3>=1000'
--匹配test开头,输出当前文件名,行号,uid+1000
awk -F ':' '/^test/ {print FILENAME,NR,$3+1000}' /etc/passwd
--使用正则表达式,正则表达式匹配test
-- ~ 表示模式开始。// 里面是模式。 !~表示模式取反
awk -F ':' '$1 ~ /test/ {print $1}' /etc/passwd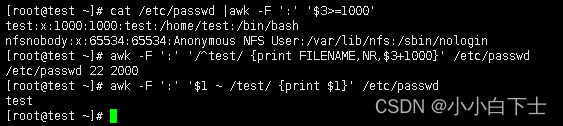
4.设置变量
-- 输出test用户 组名+2000
awk -F ':' -va=2000 '/^test/ {print $1,$3+a}' /etc/passwd
5.忽略大小写
cat /etc/passwd | awk 'BEGIN{IGNORECASE=1} /ROOT/ {print $1}' 
6.剔除空行显示
cat 1.txt | awk '!/^$/'