图像数据增强算法汇总(Python)
一、数据增强概述
数据增强是一种通过使用已有的训练样本数据来生成更多训练数据的方法,可以应用于解决数据不足的问题。数据增强技术可以用来提高模型的泛化能力,减少过拟合现象。比如在狗猫识别项目中,通过随机旋转、翻转和裁剪等数据增强方法,可以使模型具有对不同角度和尺寸的狗猫图像的识别能力。其主要作用包括:
- 增加训练样本数量:通过生成新样本,可以扩充训练集,提供更多样本供模型学习,从而减轻过拟合问题。
- 提升模型的泛化能力:通过引入随机性,数据增强可以帮助模型学习到更多的通用特征,使其对新样本的泛化能力更强。
- 增强模型的鲁棒性:经过数据增强处理的模型对于输入数据的变化、噪声等具有一定的抗干扰能力。
- 解决数据不平衡问题:在分类任务中,数据增强可以使各类别样本的数量更加平衡,有助于提升模型对于少数类别的识别能力
在医疗图像中,由于拍摄条件、器械位置等因素的影响,数据可能具有不同的旋转、缩放和翻转。通过数据增强,模型能够适应不同条件下的医疗图像,提高了疾病诊断的准确性。交通标志的图像可能会因为角度、光照等因素变化。数据增强可以帮助模型识别旋转或变形后的交通标志。不止是图像处理中用到了数据增强,在情感分析任务中,通过对文本进行随机替换、删除、插入等操作,可以生成多样化的训练样本,提升模型的泛化能力。
总的来说,这些项目中的数据增强技术有效地提升了模型的鲁棒性,使其能够在不同场景和条件下取得更好的性能。同时,数据增强也有助于防止模型的过拟合现象。
二、数据增强方法
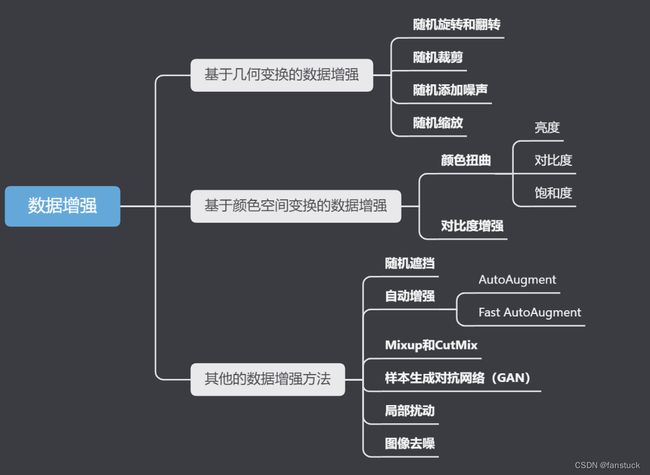
常用的数据增强手段可以分为以下几类:
- 基于几何变换的数据增强,如翻转、旋转、裁剪、平移和添加噪声等,可以消除训练集和测试集的尺度、位置和视角差异。
- 基于颜色空间变换的数据增强,如调整亮度、对比度、饱和度、通道分离和灰度图转换等,可以消除训练集和测试集的光照、色彩和亮度差异。
- 其他的数据增强方法,如多样本数据增强、Cut Mix数据增强和 Mosaic 数据增强等。
常用的数据增强方法包括:
- 随机旋转和翻转:对图像进行随机角度的旋转和水平/垂直翻转,以增加模型对旋转和镜像变换的鲁棒性。
- 随机裁剪:随机选取图像中的一部分作为训练样本,使模型对不同裁剪位置的变化具有适应能力。
- 随机缩放:对图像进行随机大小的缩放,以增加模型对尺度变化的适应性。
- 颜色扭曲:对图像进行随机的色彩变换,如亮度、对比度、饱和度的调整,以增加模型对色彩变化的鲁棒性。
- 随机添加噪声:向图像中添加随机噪声,以增加模型对噪声的鲁棒性。
- 随机遮挡:随机遮挡图像的一部分,模拟遮挡情况下的目标识别。
- 自动增强:使用自动增强算法,如AutoAugment或Fast AutoAugment,通过搜索策略来找到一组优秀的数据增强策略。
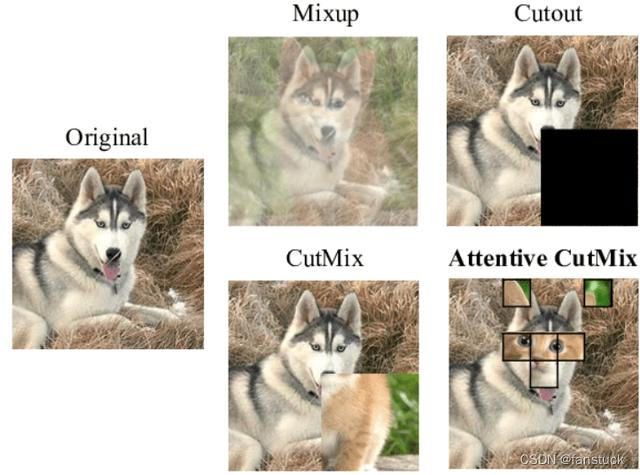
- Mixup和CutMix:将两个或多个图像进行混合,以生成新的训练样本,促进模型对类别之间的平滑过渡。
- 样本生成对抗网络(GAN):使用生成对抗网络来生成与原始样本具有一定相似性的新样本。
- 局部扰动:对图像的局部区域进行微小扰动,以增加模型对小物体的识别能力。
- 对比度增强:调整图像的对比度,使得图像中的特征更加清晰。
- 图像去噪:使用去噪算法对图像进行处理,以提升模型对噪声的鲁棒性。
选择合适的数据增强算法需要根据具体任务、数据集和模型来决定,通常需要进行实验和评估以找到最适合的方法。同时,可以结合多种数据增强方法以获得更好的效果。
三、图像数据增强
一般来说收集到特定的目标会有点困难,这需要根据我们工作中识别目标的种类而定,如果是车牌、安全帽、人这种显而易见的目标就很容易收集数据集,如果是球状闪电、雪山雪豹这类目标数据收集就比较难。这时候我们可以使用图像数据增强技术去尽可能的填充目标识别数据集,接下来我们先拿到一张图片,用这张图片进行处理展示,我们需要用到OpneCV库:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图片
image = cv2.imread('planck.jpg')
# 显示原始图片和增强后的图片
plt.figure(figsize=(10, 5))
plt.subplot(2, 3, 1)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title('Original Image')

真实场景中我们不可能仅从一个角度拍摄目标,这样收集到的数据集会造成目标识别模型过拟合,也就是只能从拍摄的角度去识别该物体,目标换个形态或者是拍摄角度更换,模型就识别不出来了。我们可以通过图片处理技术进行一定的泛化操作:
1.随机旋转和翻转
cv2.getRotationMatrix2D 是 OpenCV 中的一个函数,用于生成一个二维旋转矩阵,可以将图像围绕指定点进行旋转。
它接受三个参数:
center:旋转的中心点,一个元组(x, y)表示图像的中心坐标。angle:旋转的角度,以度为单位,正值表示逆时针旋转。scale:缩放因子,可选参数,默认为 1。
该函数会返回一个形如:
| cos(angle) -sin(angle) center_x * (1 - cos(angle)) - center_y * sin(angle) |
| sin(angle) cos(angle) center_x * sin(angle) + center_y * (1 - cos(angle)) |
的旋转矩阵。通常情况下,我们会将旋转矩阵传递给 cv2.warpAffine 函数,来实际地应用旋转到图像上。这样可以得到一个围绕指定点旋转了一定角度的图像。
# 随机旋转
angle = np.random.randint(0, 360)
rows, cols = image.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), angle, 1)
rotated_image = cv2.warpAffine(image, M, (cols, rows))

cv2.flip() 函数用于翻转图片,它接受两个参数,一个是要翻转的图片,另一个是翻转的方向:
flip_direction
参数可以取以下三个值:
0:垂直翻转(沿x轴翻转)1:水平翻转(沿y轴翻转)-1:同时在水平和垂直方向翻转
# 随机翻转
flip_direction = np.random.randint(-1, 2) # 随机选择水平、垂直或不翻转
flipped_image = cv2.flip(image, flip_direction)

2.随机裁剪
随机裁剪可以根据设定randint来随机生成裁剪的起始坐标,image.shape[1] 表示图像的宽度,image.shape[0] 表示图像的高度。
通过以下代码:
# 随机裁剪
crop_x = np.random.randint(0, image.shape[1] - 100)
crop_y = np.random.randint(0, image.shape[0] - 100)
cropped_image = image[crop_y:crop_y+100, crop_x:crop_x+100]
np.random.randint(0, image.shape[1] - 100) 会在图像的宽度范围内随机生成一个起始点横坐标,保证裁剪后剩余的宽度至少为 100 像素。同理,np.random.randint(0, image.shape[0] - 100) 会在图像的高度范围内随机生成一个起始点纵坐标,保证裁剪后剩余的高度至少为 100 像素。
image[crop_y:crop_y+100, crop_x:crop_x+100] 表示在图像上从 crop_y 到 crop_y+100 行,从 crop_x 到 crop_x+100 列的区域,即裁剪了一个 100x100 大小的区域。

3.随机缩放
np.random.uniform 函数,可以在指定范围内随机生成一个浮点数作为缩放因子 scale_factor。
cv2.resize 函数可以用来对图像进行缩放,其参数:
image是要被缩放的原始图像。None表示输出图像的大小由后面的缩放因子决定。fx=scale_factor, fy=scale_factor表示在水平和垂直方向上的缩放比例,即将图像
# 随机缩放
scale_factor = np.random.uniform(0.7, 1.3)
scaled_image = cv2.resize(image, None, fx=scale_factor, fy=scale_factor)
np.random.uniform(0.7, 1.3) 会在 0.7 到 1.3 之间随机生成一个浮点数,这个数就是缩放因子。
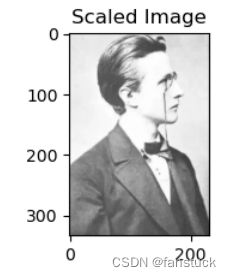
和原图像相比图像的刻度会有明显变化:

4.添加噪声
4.1高斯噪声
一般来说噪声是模拟实际数据采集情况,比如随机环境因素影响,大雾、水雾、大雨情况导致的摄像头传感器的不完美性、光照变化等。高斯噪声是一种常见的图像噪声类型,在图像数据增强中,通过添加高斯噪声,可以使模型更具鲁棒性,提高其对噪声环境的适应能力。
# 生成高斯噪声
mean = 0
var = 0.5
sigma = var ** 0.5
gaussian = np.random.normal(mean, sigma, image.shape).astype('uint8')
noisy_image = cv2.add(image, gaussian)
# 显示带噪声的图像
cv2.imshow('Noisy Image', noisy_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

4.2椒盐噪声
椒盐噪声是一种常见的图像噪声类型,它主要体现为图像中出现了随机的黑白像素点,这些像素点模拟了背景中的颗粒物或损坏的像素。
def salt_pepper_noise(image, salt_prob, pepper_prob):
noisy_image = np.copy(image)
total_pixels = image.shape[0] * image.shape[1] #计算图像的总像素数
num_salt = int(total_pixels * salt_prob) #通过将总像素数与指定的椒盐噪声比例相乘,得到要添加的椒盐噪声的数量。
salt_coords = [np.random.randint(0, i-1, num_salt) for i in image.shape]
noisy_image[salt_coords[0], salt_coords[1]] = 255
num_pepper = int(total_pixels * pepper_prob)
pepper_coords = [np.random.randint(0, i-1, num_pepper) for i in image.shape]
noisy_image[pepper_coords[0], pepper_coords[1]] = 0
return noisy_image

5.颜色扭曲
对图像进行随机的色彩变换,需要将图像从BGR颜色空间转换为HSV颜色空间,再对Hue通道进行扭曲,然后从HSV颜色空间转换回BGR颜色空间就可以完成:
# 读取图片
image = cv2.imread('clickhouse-logo.jpg')
# 转换为HSV颜色空间
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 扭曲Hue通道
hsv_image[:,:,0] = (hsv_image[:,:,0] + 30) % 180 # 在Hue通道上增加30
# 转回BGR颜色空间
result_image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR)
# 显示原始图像和扭曲后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Distorted Image', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
这里我们用一张彩色图片更好展示:

下面那张是原图片,上面那张是颜色扭曲后的图片,通过对Hue通道进行扭曲,将Hue通道的值增加30,同时使用模运算确保值在0到180之间,再将图像从HSV颜色空间转换回BGR颜色空间。
6.随机遮挡
在图像上随机生成一个矩形遮挡,遮挡的位置和大小都是随机生成的。遮挡的颜色也是随机选择的。
# 生成随机遮挡位置和大小
mask_x = np.random.randint(0, image.shape[1] - 100)
mask_y = np.random.randint(0, image.shape[0] - 100)
mask_width = np.random.randint(50, 100)
mask_height = np.random.randint(50, 100)
# 生成随机颜色的遮挡
mask_color = np.random.randint(0, 256, (1, 1, 3))
image[mask_y:mask_y+mask_height, mask_x:mask_x+mask_width] = mask_color
# 显示带遮挡的图像
cv2.imshow('Image with Random Mask', image)
cv2.waitKey(0)
cv2.destroyAllWindows()

代码将随机生成的颜色mask_color应用到图像的指定位置上,形成一个矩形遮挡,实际操作过程中一般有限定规则,比如GridMask:

7.多样本数据增强方法
Mosaic 数据增强是一种通过将多张图像拼接在一起来创建新的训练样本的方法。以具体实例来看, mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。其中我们熟悉的目标识别算法Yolo就是mosaic数据增强方式。
实现过程主要分为3步:
1)从数据集中每次随机取出四张图片

2)分别对四张图片进行翻转(对原始图片进行左右的翻转)、缩放(对原始图片进行大小的缩放)、色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作。
操作完成之后然后再将原始图片按照 第一张图片摆放在左上,第二张图片摆放在左下,第三张图片摆放在右下,第四张图片摆放在右上四个方向位置摆好。
3)进行图片的组合和框的组合。
完成四张图片的摆放之后,我们利用矩阵的方式将四张图片它固定的区域截取下来,然后将它们拼接起来,拼接成一张新的图片,新的图片上含有框框等一系列的内容。

这些方法可以单独或结合使用,具体选择取决于应用场景和数据集特点。通过数据增强,可以提升模型的性能,尤其在训练样本有限的情况下,它是一个非常有效的策略。