精华文稿|迈向统一的点云三维物体检测框架
分享嘉宾 | 杨泽同
文稿整理 | William
嘉宾介绍

Introduction
3D检测是在三维世界中去定位和分类不同的物体,与传统2D检测的区别在于它有一个深度信息。目前,大部分的工作是倾向于用点云去做三维检测,点云实际上是通过传感器去扫描出来的一系列点,这些点是分布在物体的表面,所以通过点云可以清楚的观察到一个物体的形状,所以最终做三位检测的准确率也会更高。
点云实际上有三个特点,首先是无序性,其次是稀疏性,第三是无法准确的描述一个物体。所以,现在的基于点云的3D检测框架可以分成两大类:一类是先把点云变成图片似的密集表示,然后再去像图片一样去处理点云,另一类是先处理成有序的、密集的表示,叫做基于体素的检测器。它的思路是把点云转换成均匀分布的体素,然后采用CNN的方式去处理,使用的特征提取的网络用的是类似于稀疏卷积网络。
介绍一下基于体素检测一个相关的工作,它叫做pointpillars,速度很快,如图1所示。在得到稀疏点云之后去做体素化,跟一般的体素化的区别在于它是把三维点云分成无数个pillars,即无限高的体素,但是忽略高度这一维,在这之后,可以用2DCNN去提取特征,然后再用图片上常用的2D检测器的头部去做最后的预测。
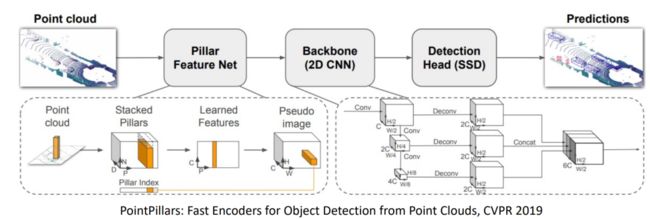
图1 PointPillars结构
Point-based Detector:3DSSD
对于在点云中为什么需要上采样层,是因为原先点云在特征提取网络之后只剩下少量的点,那少量的点不一定会出现在物体的框里。如果最后选到的少量点不出现在物体的框里,那对于检测器来讲,是一个很不好的情况,因为很难去回归出此框。
假如检测器没有上采样层,实际上只可以回归出来两个红色框,对于其他的黄色框来讲,由于它们内部不存在选到的点,所以,这些框就相当于直接被检测器给Miss掉,如图2所示。图1右边是统计了一些数据,发现看在取4096个点时,有99.7%的物体是属于红色框,即存在内部点被选中。取1024个点时,只有65.9%的内部点被选中。到512个点时,就只有51.8%了。所以,实际上如果是用这种方式来去设计检测器,光从选点角度来看,就已经有48.2%的框完全没有机会检测到。

图2 上采样与框
但目标是建立一个非常简单的检测器,所以希望删掉上采样层。那么考虑一种方式在选点只有512或更少的情况下,也能召回这些框,这里是提出Feature Furthest Point Sampling(F-FPS)。实际上,它是基于特征的选点策略,还是图1所示的场景,绝大多数的背景点实际上都是地面,特征具有一定的类似。前景点是属于车或人或一些其他的前景物体,特征与背景是有一定的区别。因为它们之间特征存在区别,然后再加上最远点采样,就可以直接根据特征去做采样,这样可以尽可能的去采到特征不同的点。所以,它的优势在于可以去删掉大量的背景点,另外是可以为前景去拿到它的内部点。
下面来介绍3DSSD框架,如图3所示。它最主要的改进点在于之前提到的F-FPS,然后加上D-FPS去做采样,采样完成之后,里面的每个模块都用类似于pointnet去对采样到的点做特征提取。特征提取层最终采的点处于物体边界上的点,对回归不太友好,这里目标是采样点在物体中心。所以,提出了一个Kennedy generation layer,这个layer的目的是把一个个在边界的采样点给移动到物体的中心,再这之后去进行最后的检测。最后生成预测框或生成分类分数去产生最后的结果。

图3 3DSSD框架
Voxel-based Dector:3D-MAN
3D-MAN是为了解决单帧点云不能正确描述物体形状的特点而设计出来的,框架如图4所示。拿到单帧点云之后,经过一个检测器,得到检测结果并存到memory bank里面。这个memory bank里面存的是这一帧和这一帧之前的前N帧所有对应的内部物体和对应的物体特征。需要这些物体和物体特征是希望拿到同一个物体在不同帧的特征,然后进行融合,从而去解决单帧的问题,融合之后去做检测。
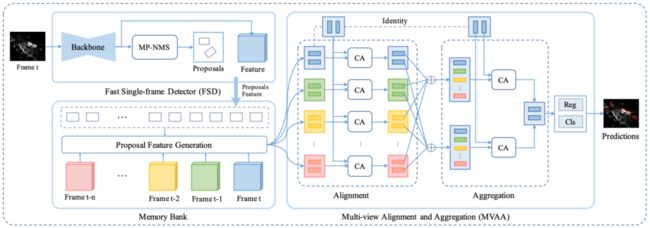
图4 3D-MAN框架
对于生成物体的特征,首先是采用pillar检测器,所以实际上拿到了一个经过backbone的2D特征图。在拿到物体后,先把物体平均分成2乘3的网格,且均匀分布在物体内部。在拿到great center之后,去计算它在feature map上的位置,然后通过双线性插值去获得它在featuremap上的位置和特征,在拿到六个网格的特征之后,去做平均池化,得到所对应的proposal,将proposal对应的特征去存到memory bank里。
当产生完一个个proposal的feature之后,就能拿到当前帧proposal的feature和存在memory bank里面不同帧proposal的feature,接着使用cross attention去计算相似度,然后利用相似度去组合当前帧所对应的proposal和特征。最后使用不同帧的特征进行融合,生成最后的预测结果。
图5是同一个物体在不同帧feature的attention map,因为cross attention实际上是基于相似度进行的,然后把相似度就暂时简称为attention map。然后测试attention map可以发现它的对角线相比于其他位都是有更加大的亮度,也就是表示它的相似度很高。所以,实际上这个模块是在做隐式的track,也就是可以从其他具有相似角度和大小的物体上找一些信息,理论上就可能会得到更好的效果
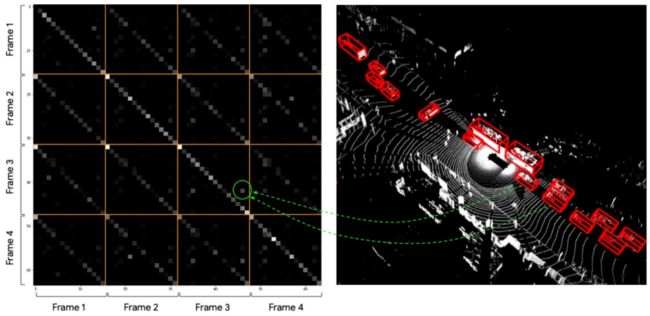
图5 attention map
Unified Paradigm
现在3D检测里面是存在基于体素和基于点的方法,这是两个完全分开的研究领域,而实际上是希望提出一个统一的框架来进行3D检测,所以来介绍下这篇《A Unified Query-based Paradigm for Point Cloud Understanding》简称为EQ-paradigm。
EQ-paradigm的整个流程如图6所示。首先是输入点云,然后经过特征提取网络,这个特征提取网络既可以是基于体素的,也可以是基于点的,最后通过查询去连接不同的head,即可以任意切换head去做分类、分割、基于体素的检测或是基于点的检测等等。
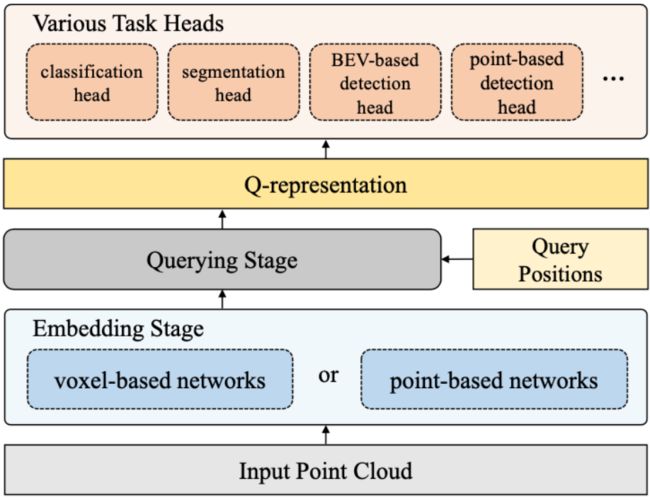
图6 EQ-paradigm框架
流程中首先是Embedding Stage,这个希望它可以是任何一个存在的、顶尖的、基于体素或基于点的特征提取网络,也就是不管head和task,这个地方可以随意选择。而EQ-paradigm里最重要的设计是Query Stage,它的目标是为一些query position提取特征,那这些query position实际上是连接特征提取网络和对应的头部的重要组件。query stage的作用是为query position去提取它对应的特征,这里简称为representation。然后,不同的头部去根据representation生成所对应的最后检测结果。
Quary position的选取是根据任务和所需要的head,比方如图7所示,橙色的点是点云里面的一些点,如果希望去做语义分割, query position是这个点云场景下所有的点,因为语义分割是需要对所有的点做一个分类。如果要做分类,那position是物体所对应的中心点。
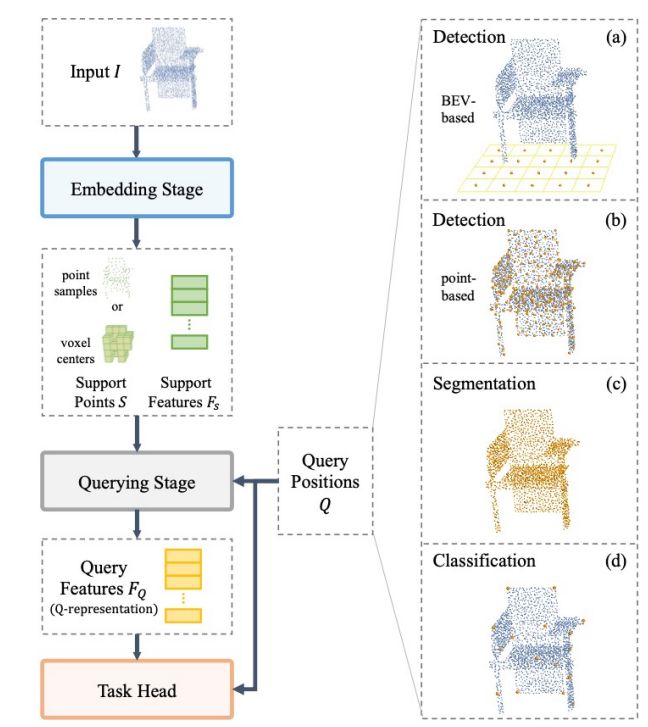
图7 Quary position
那如何为query position生成特征,这里所用的方式其实是transform,因为transform实际上非常好去做query。具体如图7所示,拿到一些query position后,初始化它们的特征为零,然后用query position和它对应的初始化特征去从support features和support point里面去拿到它所对应的特征,这些support实际上是前面选择网络所生成得一些特征。之后,会通过Q-decode layer将support feature和support point作为K和V,然后把这些query作为Q,输入到里面去生成它所对应attention的特征,然后会多叠几层qblock,这里是有6层,然后不断迭代式的更新它所对应的query feature。然后,拿到了最后的query feature之后,就会经过一些MLP层完成任务。
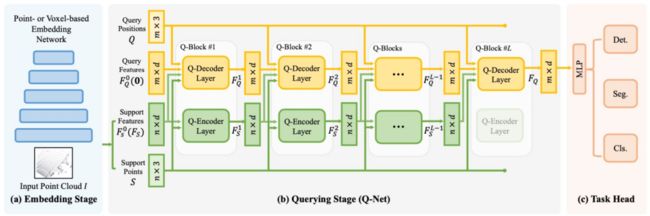
图7 Q-Net结构
Future Works
在EQ-paradigm之后,可以把不同的模型及不同的backbone统一到同一个框架里面,所以在有了这个框架之后,可以像2D一样去真正的做一个类似于2D里面的restnet等所有检测器都可以去用的特征提取网络,这个现在其实还没有文章去做这件事情。第二个是当有了一个统一的特征提取网络之后,实际上就可以去真正的做一个对于所有基于点云模型统一的pretraining网络,无论是基于体素还是基于点。最后一个是可以去用基于图片的特征网路去提取特征,这些都是未来可以做的一些方面。