python web自动化测试元素定位_基于python3的selenium3的web自动化测试之元素定位——小白进阶之路(一)...
没名字 是一个块标签 一个容器标签,里面可包含不同的标签
没名字 是一个文本标签 ,一个文本容器标签,里面一把放文本不同的标签
声明的是一个段落
是一个文本框
代表图像
HTML标签的层级关系
爷爷类标签
HTML页面中什么是元素?
在HTML页面中,开始标签和结束标签之间的所有代码,都叫元素,是一个集合的概念。
元素有什么组成呢?元素有属性和属性值
6.元素定位
6.1元素定位方法
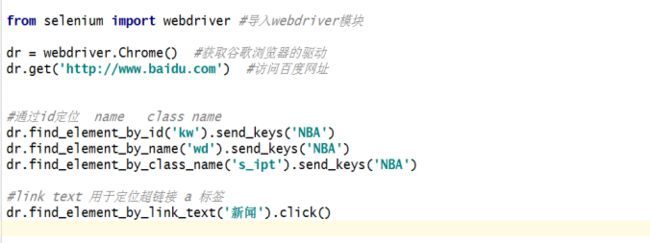
find_element_by_id('id属性值') --通过id定位
find_element_by_name('name属性值') --通过name定位
find_element_by_class_name('class的属性值') --通过class_name定位
find_element_by_link_text(u'文本描述') --通过class属性定位
find_element_by_xpath(‘xpath语法’) --通过xpath语法定位
find_element_by_css_selector('css语法') --通过css语法定位
还有通过tag_name和partial_link_text定位 使用少,了解即可
定位报错
![]()
检查元素的属性值是否唯一
模拟用户点击 click()
模拟用户输入信息send_keys()
6.2元素定位实例
重点1:定位元素技巧——xpath定位
xpath优缺点
优点:定位语法丰富(比如可以通过爷爷类,父类标签定位),功能强大
缺点:定位速度相对css定位速度慢一些,抗变性弱(当元素的路径在html页面中发生改变时需要调整xpath定位的路径)
xpath是通过元素的路径查找元素,一级级的查找从html最外层一直查找到目标元素的所在位置
#通过xpath的绝对路径定位
#dr.find_element_by_xpath('/html/body/div[2]/div/section[2]/div/form/fieldset/div[2]/input')
#通过xpath的属性定位
#dr.find_element_by_xpath("//input[@type='text']").send_keys("selenum自动化")
#dr.find_element_by_xpath("//*[@type='text']").send_keys("selenum自动化") ---1.*表示任意标签位置,但是type的属性值必须唯一2.“//”表示先对路径
xpath定位中用来表示层级关系的符号:“/”

class 属性值带空格的处理办法:
如果直接用class属性对应的廍属性值,一般会报错。
如果报错,选取class属性值中的部分属性去尝试,尝试之前需要验证该部分属性值的唯一性
如果唯一,可能能用!也可能不能用!如果不能用,找他爷爷类的标签和层级去定位
#通过逻辑运算符去定位 and
dr.find_element_by_xpath("//input[@id='kw' and @autocomplete='off']").send_keys('123')
6.3验证属性唯一值得方法:
1.将你的鼠标放到html页面中,随意的一个位置
2.按快捷键:ctrl+f键,此时下面会出现一个文本框
3.在文本框中输入我们要验证的属性值
4.验证的目的是保证元素的属性是唯一的
5.如果页面中发现属性值的个数不是只有一个,那就说明我们不可以使用这个属性值去定位
6.4
重点2:定位元素技巧——css定位
css是层叠样式表,用于美化web页面的一种技术,我们主要使用css中的选择器作为我们元素定位的一种策略
css定位的优缺点
优点:1.语法简洁 2.定位速度快 3.抗变性强
缺点:不支持多个索引
css的层级关系表示方法:>
css简写说明:
id ————>"#"
class ————>"."
1.css定位 id class (百度文本框)
dr.find_element_by_css_selector('#kw').send_keys('NBA')
dr.find_element_by_css_selector('.s_ipt').send_keys('selenium')
2.css定位 属性定位
dr.find_element_by_css_selector("#search-button").click()
dr.find_element_by_css_selector('input[name="wd"]').send_keys('NBA')

3.通过标签名定位
dr.find_element_by_css_selector("input").send_keys("selenium自动化")
4.通过层级的父子关系定位
dr.find_element_by_css_selector("div > input").send_keys("selenium自动化")
5.通过层级与属性组合定位
dr.find_element_by_css_selector("div > input.placeholder#input").send_keys("selenium自动化")
dr.find_element_by_css_selector("div.skin-search-input.hover > input.placeholder#input").send_keys("selenium自动化")
6.css定位 爷爷类标签 层级和属性结合 针对于id class
dr.find_element_by_css_selector("form#form>span>input").send_keys('NBA')

总结:
1.元素定位时,如果有id,name,直接使用id,name定位,没有id,name属性的元素优先考虑css定位
2.在自动化测试项目,定位优先使用css定位,除非在css定位无法解决定位问时,这时候可以考虑xpath的路径定位
因为在自动化测试脚本元素定位使用xpath定位过多,当元素的位置或者路径发生改变时,使用xpath定位的脚本需要大批量的改动,这样的结果是劳民伤财的,所以要避免!