Flink OLAP 在资源管理和运行时的优化
本文整理自字节跳动基础架构工程师曹帝胄在 Flink Forward Asia 2022 核心技术专场的分享。Flink OLAP 作业 QPS 和资源隔离是 Flink OLAP 计算面临的最大难题,也是字节跳动内部业务使用 Flink 执行 OLAP 计算需要解决的最大痛点。本次分享将围绕 Flink OLAP 难点和瓶颈分析、作业调度、Runtime 执行、收益以及未来规划五个方面展开介绍。
Flink OLAP in ByteDance
针对内部许多混合计算的需求场景,字节跳动提出了整合 AP 和 TP 计算的 ByteHTAP 系统,同时将 Flink OLAP 作为ByteHTAP 的 AP 计算引擎。在字节跳动一年多的发展中, Flink OLAP 已经部署支持了 20+的 ByteHTAP 线上集群,集群规模达到 16000+Cores,每天承担 50w Query 的AP流量。
上图是 Flink OLAP 在字节跳动的服务架构,Flink OLAP 通过 SQL Gateway 提供 Restfull 接口,用户可以通过 Client 向 SQL Gateway 集群提交 Query,SQL Gateway 负责 SQL 解析并生成执行计划后提交给 Flink 集群。Flink 集群接收到请求后,由 Dispatcher 创建 JobMaster,根据集群内的 TM 按照一定的调度规则将 Task 部署到对应的 TaskManager 上,最后 Task 将结果推回 Dispatcher,并且最终由 Dispatcher 推给 Client。
挑战

Flink OLAP 在发展期间也遇到了很多挑战。不同于流式计算任务,OLAP 任务大部分都是秒级、毫秒级的小作业,具有 QPS 高、时延小的特点。以内部业务为例,业务方要求在高峰期支持大于 200 的 QPS,并且 Lantency p99 < 2s,而优化前的 Flink 调度性能还不能满足业务方需求,因此我们针对 Flink 的调度性能全链路进行了瓶颈分析。
首先通过设计针对调度性能的一系列 Benchmark,从业务出发根据复杂度构建 3 组测试作业。每个 Source 节点只会产生一条数据,数据量可以忽略不计。测试环境使用 了5 台物理机启动了一个 Flink Serssion 集群,总共约 500 Cores CPU,大约 1.25w 个 Slot,实现了一个 Benchamrk 的 Client 可以根据不同的并发度批量提交作业。我们在benchmark结果中统计了 10min 内完成的作业数量,并计算作业完成的平均 Latency。
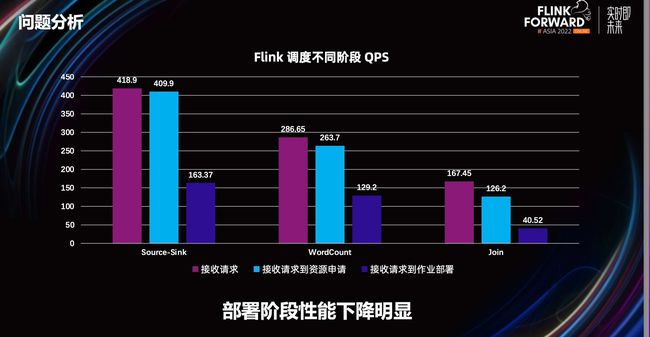
为了更好的分析 Flink 调度阶段的性能瓶颈,将调度阶段分成了三个阶段。第一个阶段是集群 Dispatcher 收到作业请求后直接完成作业并返回结果;第二阶段是作业在 JobMaster 中申请完资源后直接完成并返回结果。第三个阶段是 JobMaster 将 Task 部署到 TaskManager 后,TaskManager 不执行逻辑直接将 Task 置为完成并返回,jobMaster接收所有Task完成的消息后,将作业置为结束。在实践中发现从资源申请到作业部署的过程中 QPS 性能下降明显。

在 E2E 的测试场景中,可以看到在 WordCount 作业中 Client 并发度从 16 提升到 32 后 Latency 上升明显,Join 作业更是在 4 并发到 16 并发时 Latency 明显上涨。
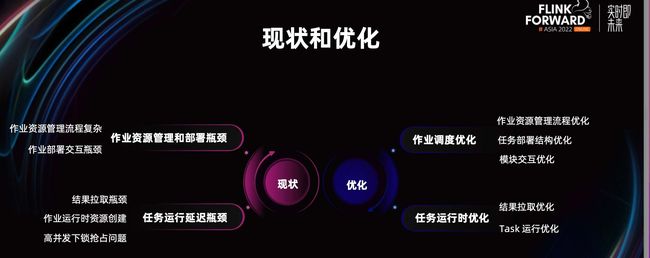
通过上面的 Benchmark 和 Flink 部署的全流程分析可以发现主要有两个问题,一块是作业在资源管理和部署上的瓶颈,一块是任务在运行时延迟瓶颈。
针对OLAP场景,在作业资源管理和部署方面,目前 Flink 资源管理流程和部署交互流程过于复杂。在运行方面,Flink 的作业拉取结果流程存在较多限制,另外大量的小查询会导致资源频繁的创建销毁。针对上面这些问题,我们分别从作业调度和运行时两个大方向进行优化。
作业调度
资源管理流程优化
目前字节 OLAP 的改造是基于 Flink-1.11 版本,因此先介绍下 Flink-1.11 的集群资源申请和释放流程。首先TaskManager 在部署完成后向 ResourceMananger 注册,JobMaster 向 RM 进行资源申请,RM 根据申请的 Slot 对 TM 进行部署。TM 收到部署请求后与 JobMaster 建立连接并提供 Slot 资源。最后由 JobMaster 对 Slot 的资源进行分配并向 TM 进行部署。资源释放流程同样,在任务结束后,JobMaster 会释放对应的 Slot 的资源,并释放 TaskManager 连接,TM 也会通知 RM Slot 资源释放。
从以上流程可以看到作业申请和释放 Slot 资源分别需要 JobMaster、ResourceManager 以及 TaskManager 进行 2 次网络交互。这些耗时在单查询情况下虽然可能只增加了几十到几百毫秒,但在多查询情况下,会将这部分的耗时放大,甚至使查询作业的资源申请耗时增加为秒级。
同时在这个流程中可以看到 ResourceManager、JobMaster 以及 TaskManager 三个核心功能模块在资源申请和释放上的功能划分不够清晰,ResourceManager 管理计算资源存活,另一方面又管理作业的资源分配,造成查询资源申请的单点问题;另一方面,TaskManager 不仅执行计算任务,同时还参与计算资源的申请和分配流程,申请和释放流程过长。
此外资源分配中 SlotPool 处理 Slot 申请和分配比较复杂,每个 Task 需要获取上游 Task 的分配位置,同时 Share Group 分配资源有多次排序和遍历,增加了 Slot 分配的耗时,这个随着作业复杂度上升,耗时也会增加。
在原流程中 ResourceManager 分配 Slot 时需要确保 TaskManager 中指定的 Slot 是空闲可用的,这会增加申请和释放流程的复杂度。同时 TaskManager 通过在资源申请流程中根据 Slot 初始化对应的 TaskSlot 以及 MemoryManager,确保每个 Slot 只被一个作业的多个计算任务使用。通过分析可以发现,多个计算任务在共享 Slot 过程中,主要是共享 MemoryManager 管理 Batch 算子的 Aggregate、Join、Sort 等算子的临时状态以及流计算任务中的 Rocksdb 堆外内存申请和释放,这部分内存共享的实现跟作业没有强绑定关系,所以多个作业的多个计算任务也可以共享 MemoryManager。因此在为了简化资源申请流程,及作业的资源共享上,通过去除 Slot 的感念,在 TaskMananger 中使用全局共享的 MemoryManager。
在优化后的流程中,TaskManager 启动后会向 ResourceManager 进行注册,ResourceManager 向 Dispatcher 同步 TM 信息。这里的 Dispatcher 会同时维护一份集群 TM 的列表,并在作业提交时提供给 Jobmasger。JobMaster 根据集群的 TM 根据指定的部署策略选择部署的 TM 并向 TM 发送部署请求。优化后的各组件分工如下:
ResourceManager:管理计算节点的存活以及节点的资源信息汇总,不再执行 OLAP 类型查询计算的资源分配;
TaskManager:支持计算任务的执行,在将资源信息汇报给 ResourceManager 后,不参与作业资源申请和释放流程。
JobMaster:支持和实现查询计算的资源分配。
在资源流程改造中,因为去除了 Slot 限制,因此在作业部署上可以以 TM 为粒度批量进行作业部署,通过对部署请求进行打包,大大减少了 JobMaster 与 TaskManager 之间的请求次数。
任务部署结构优化
在完成上面的优化后,通过对 Source、WordCount 以及 Join 等三类不同复杂度的作业计算任务部署性能测试,我们发现不同作业复杂度对于计算任务部署的性能影响非常大。
Source 作业,只包含 Source 节点,共 1 个节点,128 并发,共 128 个计算任务,按照 TM 部署策略会使用 10 个 TM,每个 TM 部署 13 个计算任务。
WordCount 作业,包含 Source 节点和 Aggregate 节点,共 2 个节点,128 并发,共 256 个计算任务,使用 10 个 TM,每个 TM 部署 26 计算任务。
Join 作业,包含 3 个 Source 节点,2 个 Join 节点以及 1 个 Aggregate 节点,共 6 个节点,128 并发,共 768 个计算任务,使用 25 个 TM,每个 TM 部署 30 计算任务。
从上面的数据可以看到,随着任务复杂度的提升,序列化的总耗时增加明显,WordCount 的序列化总耗时约 122s,而 Source 作业的耗时在 5s 左右。Join 作业的序列化耗时更是在 200s 以上。针对这一现象,可以从两个维度进行优化:
数据量大小:通过分析作业的部署结构发现每个 Task 的部署结构包括作业信息、作业配置等信息,同时包含该 Task 的信息,包含 Task 名称,上下游信息,上下游的位置信息等。这其中同一个作业不同 Task 的作业维度信息都是相同的,同时如果作业是 All To All 的连接方式,他们的上下游信息也是可以共享。因此可以对部署结构的冗余信息进行提取,比如将作业维度信息、相同 Task 信息、上下游位置信息等。
序列化流程:原有的序列化是由 TM 的 Actor 负责的,高并发下存在单线程瓶颈,所以将部署请求抽出为单独的链路,通过配置多 Netty Thread,并发处理,再将序列完的结构交由 TM 的 Acotr 处理。
经过以上两个维度的优化,Source 作业的序列化大小由 63kb 降为 5.6kb,耗时由 5462kb 降为 644kb,复杂作业的优化更为明显,WordCount 作业的序列化大小由 317.3kb 降为 11.1kb,耗时由 122546ms 降为 940ms,Join 作业的序列化大小由 557.5ms 降为 28.3ms,耗时由 219189ms 降为 2830ms。
模块交互优化
在完成资源流程申请和释放优化后,剩下的模块交互主要是 JobMaster 和 TaskManager 的交互。一部分主要是在 JobMaster 初始化完成后,会与所有的 TM 建立网络连接,同时在作业运行时两者之间会维持心跳连接;另一部分主要的交互是 TM 会上报 Task 的运行状态,包括部署完成进入 running 的状态以及任务结束的终态上报。这里的交互在高并发情况下规模也是比较可观的,以 Task 数为 128 的测试作业在 QPS 100、TM 100 的环境下为例,JM 每秒创建 10000 左右的链接,收到 Task 的更新请求 256w 次。
在之前的资源管理优化中,Dispatcher 已经维护了集群内 TaskManager 的所有节点信息,因此可以在 TaskMananger 初始化完成后与 Dispatcher 建立连接和心跳。所有的 JobMaster 复用该连接,而不单独维护连接及心跳。同时之前的心跳连接中 TM 需要上报 Slot 使用快照等信息,这一部分在资源管理优化后也不需要。这里有个问题是之前 JobMaster 需要通过心跳感知 TM 的状态,而改造后由 Dispatcher 负责维护与 TM 的心跳,因此当 Dispatcher 感知到 TM 异常 后,会通知相关的 JobMaster 进行 Failover 处理。
在 Task 任务更新请求的优化中,在 OLAP 的任务场景下默认采用 Pipeline 模式,在这种模式下,所有 Task 会同时开始调度,因此其实并不关心单个 Task 粒度的状态变化,同时 Task 直接也没有状态的相互依赖,所以我们可以将状态更新请求进行打包,在 Task 部署完成后 JobMaster 直接将状态更新为 Running 不进行额外的交互请求。只在作业结束时 TM 以任务粒度进行更新。同时针对一些 Block 连接的场景,比如自 Join,TM 会对这类 Task 进行单独状态更新来防止死锁。
Runtime 执行
Pull VS Push
Flink 计算结果链路基于 Pull 机制,从 Gateway 向 JobManager 发起 Pull 请求,JobManager 再向 TaskManager 节点 Pull 结果数据。Gateway 到 JobManager 之间存在 Pull 轮询请求,存在固定的轮询间隔时间,增加了查询的 Latency,很难满足 OLAP 业务对 Letancy 要求比较高的场景。同时为了支持和实现 Pull 机制,会创建一些临时的网络、线程等资源,例如在 Sink 节点会创建 Socket Server,在 Gateway 节点会创建轮询线程等,浪费了计算节点和 Gateway 节点的资源。此外,Dispatcher 节点是一个 Akka Actor 单点,Pull 数据流程会通过 Dispatcher 节点处理和转发,加大了 Dispatcher 处理消息负担。
因此我们考虑将获取结果链改为 Push 机制,一方面可以解决轮询 Latency 的问题,同时将结果主动 Push 向 Client,也可以避免 Dispatcher 接受请求的单线程瓶颈,Gateway 也不需要创建轮询线程进行轮询。但 Push 机制也存在新的挑战:
Push 模式下数据返回进行流量控制,避免 Client 端数据堆积产生 OOM;
在原先的机制下,Client 会通过 Dispatcher 获取当前任务状态,在 Push 模式下则需要主动将作业状态返回。
作业结果 Push 架构
为保证 Flink 现有功能架构的稳定性,通过在 JobManager 中新增一个独立的 NettyServer 提供 Socket 服务,SocketServer 接收 Gateway 创建连接和提交作业,然后将接收到的 JobGraph 对象通过 DispatcherGateway 提交到 Dispatcher,再由 Dispatcher 将 Task 部署到 TaskMananger 中。其中 Sink 算子会与 JM 的 NettyServer 创建单独的 Channel 连接 Push 结果。JM 的 NettyServer 收到结果后会将结果推给 Gateway。
整个 Push 过程利用 Netty 的 Watermark 机制进行流量控制,发送节点前判断 Channel 是否可写,不可写则进行阻塞操作,形成反压。只有在接收节点消费数据完成并且 Netty Watermark 恢复到正常值后,发送节点才会恢复结果推送。同时 Sink 节点发送的数据会带上当前的结果的状态,用于判断该 Sink 节点是否完成。之后会在 NettyServer 中汇总这些 Task 的结果状态,当所有数据发送完成后,NettyServer 向 Gateway 发送任务结束的状态信息。通知 Gateway 数据已经全部发送完成,该 Query 已经结束。在 50 TM Client 128 并发下空数据测试下,Push 模式将 QPS 从 Pull 模式的 850 提升到 4096,提升了 5 倍左右。
线程优化
通过对 TM CPU 使用的分析发现在高并发情况下,线程的创建能占用 30% 以上的 CPU。因此通过池化线程池减少线程的创建销毁,但是池化线程操作会带来的问题是由于原来的 Cancel 线程只需关心执行线程是否存活,但线程池中线程资源是复用的,因此需要对执行线程进行封装,维护线程当前执行的 Task,Interrupt 线程在进行 Interrupt 操作时也会判断中断的 Task 是否正确,在线程结束后更新状态用于其他 Cancel 线程判断当前执行线程的状态。
锁优化
在对 Thread 的 Profier 分析中发现存在高并发下 Task 频繁的抢锁操作。其中 NetworkBufferPool 用于提供数据传输的内存,MemoryPool 为算子计算时提供堆外内存。以 NetworkBufferPool 为例,Task 初始化完成后,LocalBufferPool 为空,所有的网络内存都需要向 NetworkBufferPool 申请,而 NetworkBufferPool 是整个 TM 唯一的,为了保证一致性,所有的内存申请和释放都需要申请锁。以 100 并发, Task 100,TM 为 1 为例,每秒会产生 1w 次的锁请求。而在 NetworkBufferPool 内存足够的情况下,可以通过将内存打包进行申请以减少内存申请的次数从而减少锁抢占的开销。
Task 在向内存池申请内存会以 BatchSegment 为单位申请,一个 BatchSegment 封装了 10 个 Segment。通过批量内存申请将锁抢占的次数减少为原来的十分之一。在 10 并发,Task 100,TM 为 1,BatchSegment size 为 10 的情况下,申请 Segment 的锁占用请求由 1000/s 变为 100/s,模拟申请 10w 个 Segment 的总耗时由 4353ms,缩短为 793 ms。
内存优化
另外在高 QPS 测试中发现当 JM 运行的作业数量比较多时,JM 会频繁的触发 Fullgc,导致作业 Latency 上涨。这种情况通过对 JM 的内存分析可以发现大部分的内存都是用在保存作业的 Metric 信息中,包括作业维度以及 Task 维度的信息。而在 OLAP 的场景下字节内部有单独的 MetricrePorter,很多 Metric 信息并不需要同步到 JM 端。因此通过 TM 端的 Metric 中加入白名单对 Metric 上报进行过滤 ,只保留需要使用的 Metric,比如TM资源信息、Task io 信息等。在对 Metric 进行过滤后,JM 的 Full GC 频率降低了 88%,对作业 Latency 的影响显著减少。
收益

完成作业调度和执行优化后,通过对优化后的 Flink 集群进行 Benchmark 测试。测试结果显示,QPS 提升显著。单节点作业 QPS,从原先的 17 提升到现在的 33。WordCount 两节点作业最高 QPS,从 7.5 提升到 20 左右。Join 作业的 QPS 从 2 提升至 11,Latency 在 32 个线程下,下降明显。单节点作业的 Latency,从 1.8 秒降低到 200 毫秒左右。WordCount 两节点作业从 4 秒降低到 1 秒多。Join 作业的 QPS 从原先的 15 秒降为 2.5 秒左右。
在业务收益方面,ByteHTAP 受到了公司核心业务的广泛认可。目前,已经接入 User Growth、电商、幸福里、飞书等 12 个核心业务。线上汲取能支持业务复杂查询高峰期 200 左右的 QPS,Latency P99 控制在 5 秒以下。
未来规划
在公司内部,需要支持多租户的业务场景,该业务场景包含了少量重要租户,冷租户多,租户数量大的特点,存在 Noisy Neghbor,资源利用率低的问题。
针对这类业务会主要在下面几个维度提高 Serverless 能力:
通过支持 TaskManager 资源隔离和单节点维度支持计算任务优先级调度解决 Noisy Neghbor 的问题;
通过支持弹性扩缩容解决资源利用率问题。
在性能提升方面,主要分为三个部分:
集群负载性能:JobManager 支持水平扩展、集群资源利用率优化、Task 调度性能优化;
Flink OLAP 运行时优化:运行时网络消息优化、资源申请流程优化;
冷启动优化:Gateway 冷启动优化、网络初始化优化、内存申请流程优化。