ForkJoinPool的使用及基本原理
目录
1.ForkJoinPool是什么
1.1 分治法
1.2 工作窃取(work-stealing,中文又译作偷工减料,也有道理)
2.简单使用
2.1 不带返回值的计算
2.2 带返回值的计算
3.ForkJoin源码注释
3.1 类注释
3.2 关于原理的注释
4.总结
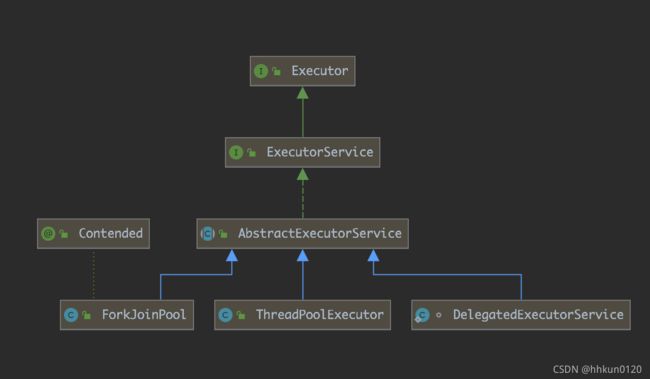
ForkJoinPool是AbstractExecutorService的子类,是ThreadPoolExecutor的兄弟。今天就来简要说下ForkJoinPool这个类。
1.ForkJoinPool是什么
ForkJoinPool是自java7开始,著名java程序员JUC作者Doug Lea写的为jvm提供的一个用于并行执行的任务框架。其主旨是将大任务分成若干小任务,之后再并行对这些小任务进行计算,最终汇总这些任务的结果。得到最终的结果。其广泛用在java8的stream中。
这个描述实际上比较接近于单机版的map-reduce。都是采用了分治算法,将大的任务拆分到可执行的任务,之后并行执行,最终合并结果集。区别就在于ForkJoin机制可能只能在单个jvm上运行,而map-reduce则是在集群上执行。此外,ForkJoinPool采取工作窃取算法,以避免工作线程由于拆分了任务之后的join等待过程。这样处于空闲的工作线程将从其他工作线程的队列中主动去窃取任务来执行。这里涉及到的两个基本知识点是分治法和工作窃取。

1.1 分治法
分治法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题的相互独立且与原问题的性质相同,求出子问题的解之后,将这些解合并,就可以得到原有问题的解。是一种分目标完成的程序算法。简单的问题,可以用二分法来完成。
二分法,就是我们之前在检索的时候经常用到的Binary Search 。这样可以迅速将时间复杂度从O(n)降低到O(log n)。那么对应到ForkJoinPool对问题的处理也如此。基本原理如下图:

分治原理
这只是一个简化版本的Fork-Join,实际上我们在日常工作中的应用可能比这要复杂很多。但是基本原理类似。这样就将一个大的任务,通过fork方法不断拆解,直到能够计算为止,之后,再将这些结果用join合并。这样逐次递归,就得到了我们想要的结果。这就是再ForkJoinPool中的分治法。
1.2 工作窃取(work-stealing,中文又译作偷工减料,也有道理)
工作窃取是指当某个线程的任务队列中没有可执行任务的时候,从其他线程的任务队列中窃取任务来执行,以充分利用工作线程的计算能力,减少线程由于获取不到任务而造成的空闲浪费。在ForkJoinpool中,工作任务的队列都采用双端队列Deque容器。我们知道,在通常使用队列的过程中,我们都在队尾插入,而在队头消费以实现FIFO。而为了实现工作窃取。一般我们会改成工作线程在工作队列上LIFO,而窃取其他线程的任务的时候,从队列头部取获取。示意图如下:
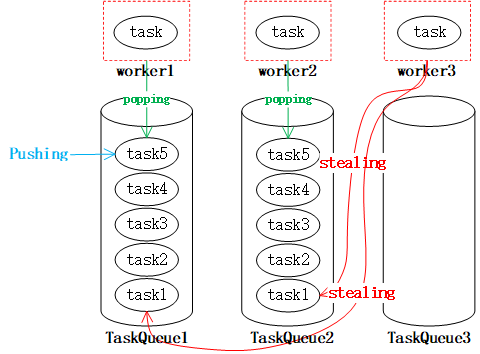
工作窃取
工作线程worker1、worker2以及worker3都从taskQueue的尾部popping获取task,而任务也从尾部Pushing,当worker3队列中没有任务的时候,就会从其他线程的队列中取stealing,这样就使得worker3不会由于没有任务而空闲。这就是工作窃取算法的基本原理。
可以想象,要是不使用工作窃取算法,那么我们在不断fork的过程中,可能某些worker就会一直处于join的等待中。工作窃取的思想,实际实在golang协程的底层处理中也是如此。
2.简单使用
在弄清楚了fork-join是什么了之后,我们来看看JUC中为我们提供的forkjoin是如何工作的。
在juc中,实现Fork-join框架有两个类,分别是ForkJoinPool以及提交的任务抽象类ForkJoinTask。对于ForkJoinTask,虽然有很多子类,但是我们在基本的使用中都是使用了带返回值的RecursiveTask和不带返回值的RecursiveAction类。
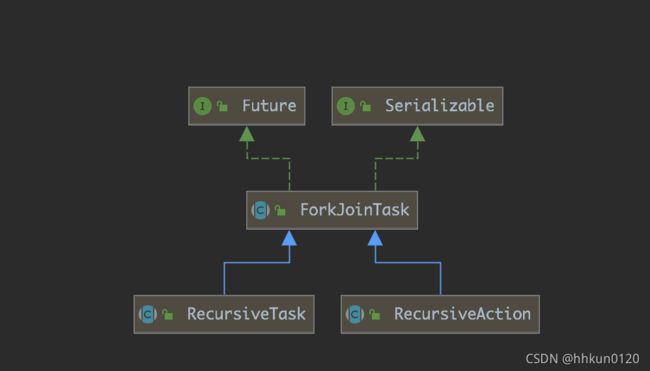
我们通过继承这两个类来实现两种类型的计算。
2.1 不带返回值的计算
RecursiveAction可以实现不带返回值的fork-join计算。实现如下:
package com.thread;
import java.util.concurrent.RecursiveAction;
/**
* @description:
* @author: H.K
* @create: 2021-09-08 13:44
*/
public class PrintTask extends RecursiveAction {
private static final int THRESHOLD = 9;
private int start;
private int end;
public PrintTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if(end - start < THRESHOLD) {
for(int i=start;i<=end;i++) {
System.out.println(Thread.currentThread().getName()+",i="+i);
}
}else {
int middle = (start + end) / 2;
PrintTask firstTask = new PrintTask(start,middle);
PrintTask secondTask = new PrintTask(middle+1,end);
invokeAll(firstTask,secondTask);
}
}
}
测试代码如下:
package com.thread;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.TimeUnit;
/**
* @description:
* @author: H.K
* @create: 2021-09-08 13:50
*/
public class ForkJoinPoolTest {
public static void main(String[] args) throws Exception{
// testNoResultTask();
testHasResultTask();
}
private static void testNoResultTask() throws InterruptedException{
ForkJoinPool pool = new ForkJoinPool();
pool.submit(new PrintTask(1,50));
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
public static void testHasResultTask() throws Exception {
int result1 = 0;
for (int i = 1; i <= 1000000; i++) {
result1 += i;
}
System.out.println("循环计算 1-1000000 累加值:" + result1);
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask task = pool.submit(new CalculateTask(1, 1000000));
int result2 = task.get();
System.out.println("并行计算 1-1000000 累加值:" + result2);
pool.awaitTermination(200, TimeUnit.MILLISECONDS);
pool.shutdown();
}
}
可以看到结果,把1-50都打印了出来,用的线程是forkjoinpool的 工作线程。
ForkJoinPool-1-worker-1,i=1
ForkJoinPool-1-worker-1,i=2
ForkJoinPool-1-worker-1,i=3
ForkJoinPool-1-worker-1,i=4
ForkJoinPool-1-worker-1,i=5
ForkJoinPool-1-worker-1,i=6
ForkJoinPool-1-worker-1,i=7
ForkJoinPool-1-worker-6,i=20
ForkJoinPool-1-worker-6,i=21
ForkJoinPool-1-worker-6,i=22
ForkJoinPool-1-worker-6,i=23
ForkJoinPool-1-worker-6,i=24
ForkJoinPool-1-worker-6,i=25
ForkJoinPool-1-worker-5,i=8
ForkJoinPool-1-worker-5,i=9
ForkJoinPool-1-worker-5,i=10
ForkJoinPool-1-worker-5,i=11
ForkJoinPool-1-worker-5,i=12
ForkJoinPool-1-worker-5,i=13
ForkJoinPool-1-worker-6,i=33
ForkJoinPool-1-worker-6,i=34
ForkJoinPool-1-worker-6,i=35
ForkJoinPool-1-worker-6,i=36
ForkJoinPool-1-worker-6,i=37
ForkJoinPool-1-worker-6,i=38
ForkJoinPool-1-worker-6,i=45
ForkJoinPool-1-worker-6,i=46
ForkJoinPool-1-worker-6,i=47
ForkJoinPool-1-worker-6,i=48
ForkJoinPool-1-worker-6,i=49
ForkJoinPool-1-worker-2,i=26
ForkJoinPool-1-worker-2,i=27
ForkJoinPool-1-worker-2,i=28
ForkJoinPool-1-worker-6,i=50
ForkJoinPool-1-worker-3,i=14
ForkJoinPool-1-worker-2,i=29
ForkJoinPool-1-worker-4,i=39
ForkJoinPool-1-worker-4,i=40
ForkJoinPool-1-worker-4,i=41
ForkJoinPool-1-worker-4,i=42
ForkJoinPool-1-worker-4,i=43
ForkJoinPool-1-worker-4,i=44
ForkJoinPool-1-worker-2,i=30
ForkJoinPool-1-worker-2,i=31
ForkJoinPool-1-worker-3,i=15
ForkJoinPool-1-worker-3,i=16
ForkJoinPool-1-worker-2,i=32
ForkJoinPool-1-worker-3,i=17
ForkJoinPool-1-worker-3,i=18
ForkJoinPool-1-worker-3,i=19
2.2 带返回值的计算
通过实现RecursiveTask来进行带有返回值的计算。如我们需要计算1-1000000的累加结果。实现如下:
package com.thread;
/**
* @description:
* @author: H.K
* @create: 2021-09-08 14:18
*/
import java.util.concurrent.RecursiveTask;
public class CalculateTask extends RecursiveTask {
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 49;
private int start;
private int end;
public CalculateTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= THRESHOLD) {
int result = 0;
for (int i = start; i <= end; i++) {
result += i;
}
return result;
} else {
int middle = (start + end) / 2;
CalculateTask firstTask = new CalculateTask(start, middle);
CalculateTask secondTask = new CalculateTask(middle + 1, end);
invokeAll(firstTask,secondTask);
return firstTask.join() + secondTask.join();
}
}
} 3.ForkJoin源码注释
在我们看源码的过程种,前面也对Doug Lea 的论文《A Java Fork/Join Framework(Doug Lea 关于java Fork/Join框架的论文翻译)》进行了翻译。在论文中作者详细阐述了java中Fork/join的基本原理。而且这些原理在实现的过程中,还在源码中写了大段的注释。这些注释翻译如下:
3.1 类注释
ForkJoinPool是一个用于运行ForkJoinTask的ExecutorService。提供了一个非ForkJoinTask客户端的提交点,以及执行管理和监控操作。
ForkJoinPool不同于其他种类的ExecutorService,其主要是通过工作窃取来进行:ForkJoinPool中的所有线程都会尝试查找并执行提交到线程池中由其他活动创建的任务,如果不存在这些任务,则进行阻塞。当大多数任务派生其他子任务的时候,以及从外部客户端向pool中提交诸多小任务的时候,这可以实现高效处理,尤其是在构造函数中将asyncMode 设置为true的时候。ForkJoinPool也可能适用于从未加入的事件样式任务。
静态的commonPool方法可以适用于大多数应用程序,任何未显示提交到指定pool的ForkJoinTask都将使用公共的pool,这样会减少资源的使用,在不使用期间缓慢回收线程,并在后续使用时将其恢复。
对于需要单独或者自定义的pool,可以使用给定目标并行度来创建ForkJoinPool。默认情况下,并行度等于处理器的数量,pool尝试通过动态添加,暂停或恢复内部工作线程来维护足够的活动(或可用)线程,即使某些任务因等待加入其他任务而停滞不前。但是,面对阻塞的I/O或其他非托管同步,无法保证此类调整。嵌套的ManagedBlocker接口可扩展可容纳的同步类型。
除了执行线程和生命周期的控制方法之外,此类还提供了状态检查方法,getStealCount。旨在帮助开发、调整和监控fork / join应用程序。同样,方法toString以方便的形式返回池的状态指示,以进行非正式监控。
与其他ExecutorService一样,下表总结了三种主要的任务执行方法。这些被设计为主要供尚未在当前池中进行派生/联接计算的客户端使用。这些方法的主要形式接受ForkJoinTask的实例,但是重载形式还允许混合执行基于普通Runnable和Callable的活动。但是,已经在池中执行的任务通常应改为使用表中列出的内部计算形式,除非使用通常不联接的异步事件样式任务,在这种情况下,方法选择之间几乎没有区别。
| Call from non-fork/join clients | Call from within fork/join computations | |
| Arrange async execution | {@link #execute(ForkJoinTask)} | {@link ForkJoinTask#fork} |
| Await and obtain result | {@link #invoke(ForkJoinTask)} | {@link ForkJoinTask#invoke} |
| Arrange exec and obtain Future | {@link #submit(ForkJoinTask)} | {@link ForkJoinTask#fork} (ForkJoinTasks are Futures) |
默认情况下,共的池是使用默认构造函数构造的,但是可以通过三个参数来设置和控制这些参数。( System#getProperty)。
| 参数 | 说明 |
|---|---|
| java.util.concurrent.ForkJoinPool.common.parallelism | 并行度级别,非负整数 |
| java.util.concurrent.ForkJoinPool.common.threadFactory | 线程产生的工厂类 |
| java.util.concurrent.ForkJoinPool.common.exceptionHandler | 拒绝策略 |
如果存在SecurityManager且没有指定工厂类,那么默认的池将使用一个工厂类提供的线程。改线程没有启动Permissions。系统的类加载器用于加载这些类。在建立这些设置的时候出现任何错误,将使用默认参数,通过将parallelism属性设置为零和/或使用可能返回{@code null}的工厂,可以禁用或限制公共池中线程的使用。但是这样做可能会导致未连接的任务永远无法执行。
实现注意:
ForkJoinPool将运行线程的最大数量限制为32767。尝试创建大于最大数目的池会导致{@code IllegalArgumentException}。
这个实现只在池关闭或者内部资源耗尽的时候才拒绝提交任务。通过抛出RejectedExecutionException异常。
3.2 关于原理的注释
在代码中也存在大段注释,大意为:
3.2.1 ForkJoinPool实现概述
此类及其内部的嵌套类为一组工作线程提供了主要的功能和控制,来自非ForkJoin线程的提交进入提交队列,之后通常将这些提交拆分为子任务,这些子任务可能会被其他线程窃取。优先规则优先处理其自身队列按照LIFO或者FIFO(取决于模式定义)的任务。然后处理其他队列中的随机FIFO窃取任务。该框架最初是实现工作窃取来支持树形并行性工具的。随着时间的流逝,其可伸缩性优势导致了扩展和更改。以更好的支持更多不同使用的上下文。由于大部分内部方法和嵌套类是相互关联的,因此此处介绍他们的主要原理和描述。单个方法和嵌套类仅仅包含有关详细信息的简短注释。
3.2.2 WorkQueues
大多数操作发生在工作窃取队列中,(在内嵌的workQeue中)。这个队列是Deques的特殊形式。仅支持四种可能的最终操作中的三种,push、pop和poll(也称为窃取)。在进一步的约束下,push和pop仅从其所有线程处或者扩展线程调用,此时处于锁定状态,而poll可以从其他线程调用,如果你不熟悉他们,则在继续阅读之前Herlihy和Shavit的著作《The Art of Multiprocessor programming》第十六章对此进行了更加详细的描述。主要的工作窃取队列的设计大致与Chase和Lev的论文 《Dynamic Circular Work-Stealing Deque》和Michael,Saraswat和Vechev撰写的《Idempotent work stealing》。与之最大的不同在于由于GC的要求,即使在生成大量的任务的程序中,我们也需要尽快清空已占用的空间。为了实现这一点,我们将CAS与pull窃取操作从索引的base和top移动到slots本身。
添加任务则采用经典的数组push(task)操作:
q.array[q.top] = task; ++q.top;
实际的代码需要对数组进行非空检查和大小检查。需要正确的屏蔽访问,并可能的等待worker开始扫描的信号。见下文,成功的pop和poll都需要通过cas操作实现从非null到null。
pop操作的过程为(始终由任务所有者执行) :
if ((base != top) and
(the task at top slot is not null) and
(CAS slot to null))
decrement top and return task;
而而poll操作(通常由窃取者执行)是:
if ((base != top) and
(the task at base slot is not null) and
(base has not changed) and
(CAS slot to null))
increment base and return task;
由于我们依赖于引用的情况,因此不需要在base和top上做标记,他们是在任何基于循环数组队列中使用的简单整数。请参见ArrayDeque。对索引的更新保证top==base意味着队列是空的。如果没有完全提交push、pop或者poll则可能会出错,使队列看起来不空,方法isEmpty()用来检查最后一个元素不空的情况。因此,单独考虑的轮询操作不是无等待的,一个窃取线程无法成功的继续直到另外一个正在进行的窃取线程完成。(或者如果先前是空的则这是一次push操作。)然而,总的来说,我们至少保证了概率的非阻塞性,如果一次窃取微能成功,窃取线程总是会随机选择下一个不同的队列进行下一次尝试。因此,为了让一次窃取继续,任何正在进行的轮询或者对任何空队列的新推送都可以完成。这就是为什么我们通常使用方法pollAt及其变量,在base索引处尝试一次,否则就考虑其他操作,而不是执行方法poll,后者会重试。
这种方法还支持用户模式,在这种模式下,本地任务采用FIFO而不是LIFO,只需要使用poll而不是pop。这在从不连接任务的消息传递框架中非常有用。然而,这两种模式都不考虑亲和力、负载、缓存位置等。因此很少在给定的机器上提供最佳性能,但通过平均这些因素,可移植地提供良好的吞吐量。此外,即使我们试图使用这些信息,我们通常也没有利用这些信息的基础,例如,某些任务集从缓存亲和力中获利,但其他任务集则受到缓存污染效应的损害。因此,即使他需要扫描,长期吞吐量通常最好使用随机选择策略,而不是定向选择策略,因此只要适用,就可以使用足够质量的廉价随机化。各种Marsaglia xorshift(有些具有不同的移位常数)在使用点内联。
工作队列也可以用类似的方法处理提交到pool的任务。我们不能将这些任务混合在worker使用的同一个队列中。相反我们使用散列的形式将提交队列与提交线程随机关联起来,ThreadLocalRandom probe 的值用作选择现有队列的hashcode。并且可以在与其他提交者发生竞争的时候随机重新定位。从本质上讲,提交者的行为类似于worker,只不过他们被限制在执行他们被提交的本地任务或者在countedcompleter的情况下与其他具有相同根任务的任务。在共享模式下插入任务需要一个锁,主要是为了在调整大小的情况下进行保护,但是我们只使用了一个简单的spinlock,使用字段qlock。因为遇到繁忙队列的提交者会继续尝试或者创建其他队列,他们仅在创建和注册新队列的时候才会阻塞。另外,qlock在关闭时饱和到不可锁定值-1,在成功的情况下,解锁任然可以并且通过更便宜的顺序写入qlock来执行,但是在不成功的情况下使用cas。
3.2.3 管理
工作窃取机制的主要吞吐量的优势来自于分散控制。worker大多从自己或者彼此手中接任务,速度可以超过每秒10亿次,pool自身创建、激活、阻塞、停用和终止线程。所有的这些都只需要最少的中心信息。只有少数的属性可以全局跟踪和维护,因为我们将它们打包到少数变量中。通常在不阻塞或者锁定的情况下保持原子性。几乎所有的基本的原子控制状态都保存在两个volatile变量中。这两个变量最常被读取,而不是写入,做为状态和一致性检查。另外,字段config保持不变性的配置状态。
字段ctl包含64位信息,这些信息用于原子的添加,停用、入队(在事件队列上)。出队或重新激活worker所需要的信息,为了实现将这些内容都打包到一个字段上。我们将最大并行度设置为(1<<15)-1,这个值已经远远超出了现实中的工作范围。以允许对这个值进行id、计数、以及取反操作。适用于16位的子字段。
字段runState保存可锁定状态位,STARTED、STOP等。还保护对workQueues的更新。当用作锁的时候,它通常仅保留几条指令。唯一的例外是一次性数组的初始化和不常见的调整大小。因此几乎总是在经过短暂的自旋之后才可用。自旋之后,方法awaitRunStateLock(仅在初始化cas失败的时候才调用)在内置Monitor上的使用wait/notify的机制来进行阻塞。对于高度竞争的锁,这将是一个很糟糕的主意。但是大多数pool在自旋之后没有竞争的情况下运行,因此,做为更保守的替代方法,它可以很好地工作,因为我们没有内部对象的monitor,因此可以使用stealCounter(这个方法是原子的,但是它也必须延迟初始化,请参阅externalSubmit)。
runState和ctl仅在一种情况下交互,决定添加一个工作线程(请参阅tryAddWorker)在这种情况下,ctl 的CAS是在持有锁的情况下进行的。
- 记录工作队列
工作队列记录在工作队列数组中。该数组在首次使用的时候创建(请参阅externalSubmit)。并在必要的时候进行扩展。在记录新工作线程和取消记录终止工作线程时对数组的更新受到runState锁的保护,但彼此并发可读,并且可以直接访问该数组。我们还确保对数组引用本身的读取永远不会过时。为了简化基于索引的操作,数组大小始终为2的幂,并且所有读取器都必须允许空槽位。worker队列处于奇数的索引处,共享的(提交)队列处于偶数索引。最多64个槽位。以限制增长。即便队列需要扩展以增加更多的worker也如此。以这种方式将它们分组在一起可简化并加速对任务的scan操作。
所有工作线程的创建都是按需创建的。由任务提交,替换、终止的worker或补偿被阻止的worker触发。但是,所有其他的支持代码已设置为可与其他策略一起使用。为确保不保留会阻止GC的工作程序的引用。对workerQueue的所有访问均通过对workerQueues数组的索引(这是此处某些混乱代码的来源之一)进行。本质上,workQueues数组用作弱引用机制。因此,例如ctl的stack top子字段存储索引,而不是引用。
排队空闲的worker与HPC工作窃取框架不同,我们不能让worker无限制的轮询发现任何任务。并且除非有任务可用。否则我们不能start/resume这些workers。另外一方面,在提交或者新生成的任务的时候,我们必须迅速使它们生效。在许多情况下,激活工作人员的加速时间是整体性能的主要限制因素。在程序启动的时候,通过JIT编译和分配会更加复杂。因为,我们尽可能的简化这个过程。 - ctl字段
原子的维护活动和worker的数量。以及用于放置等待线程的队列,以便可以定位它们发出的信号。主动计数也起着静态的指标作用。因此当工作人员认为没有更多的要执行的任务的时候,主动计数就会减少。队列实际上就是Treiber堆栈的一种形式。堆栈是按最近使用的顺序激活线程的理想选择。这改善了性能和局部性。克服了易于争用和无法释放 工作程序的缺点。(除非其在堆栈上位于顶部)。当worker找不到任务的时候,将他们推入闲置的worker堆栈,由ctl较低的32位字段表示。我们将worker停放。最高堆栈状态保存工作程序的scanState字段值。其索引和状态,以及一个版本计数器。该计数器除了count字段之外,还用作版本标记,用以提供对Treiber堆栈ABA问题的保护。
工作程序和pool都使用scanState来管理和跟踪工作程序是不活动的。(可能处于阻塞,等待信号),这是对任务进行扫描(当两个都不持有它的线程正在忙于运行任务时)。取消激活工作程序之后,将设置其scanState字段。并阻止其执行任务。即使它必须对其进行扫描一次,也可以避免排队。请注意,scanState更新延迟队列CAS释放,因此使用时需要注意。排队时,scanState的低16位必须保持其池的索引。因此我们在初始化的时候将索引放置在此处。请参见(registerWorker)否则将其保留在索引处,或在必要时将其还原。
内存排序,有关分析请参阅Le, Pop, Cohen, and Nardelli撰写的《PPoPP 2013》类似于本文中使用的工作窃取算法中的内存排序要求。我们通常需要比最小顺序更强的命令,因为有时我们必须向worker发出信号。要求像Dekker一样的全屏障以防止信号丢失。要安排足够的排序而又不花费过多的费用,则需要在表示访问限制的受支持方法之间进行权衡。最重要的操作是从队列中获取并更新ctl状态,这需要完整的CAS。使用Unsafe提供的volatile的模拟读取Array的槽位。从其他线程访问WorkQueue的base,top和array需要对这些读取中的任何一个进行volatile加载。我们申明base索引为volatile的约定,并始终在其他字段之前读取,或者线程必须确保有序的更新,因此写操作将使用有序的内部函数。除非他们可以负担其他写操作的内容。其他WorkQueue字段(例如currentSteal)也具有类似的约定和原理,这些字段仅由所有者写入但被其他人观察到。 - 创建woker
要创建一个工作程序,我们预增加总数,用作保留,并尝试通过其工厂构建一个ForkJoinWorkerThread。新线程将调用registerWorker,在此构造一个WorkQueue。并在workQueues数组中分配一个索引。必要时扩展该数组。然后启动线程。如果这些步骤有任何异常。或者worker返回空值,则deregisterWorker会调整计数并进行相应的记录,如果返回空值。则pool将继续以少于目标数的worker状态运行。如果出现异常,则通常将异常传播到某些外部调用的地方。辅助索引的分配避免了在workQueues数组的开头开始依次进行打包时发生的扫描偏差。我们将数组视为简单的2的幂的哈希表。并根据需要进行扩展。seedIndex增量可确保在需要调整大小或注销并替换worker之前不会发生冲突。此后将发生冲突的可能性保持在较低水平,我们不能在这里将ThreadLocalRandom的getProbe()用于类似的目的。因为线程尚未启动。但是这样做是为了实现外部线程创建提交队列。
停用并等待,排队遇到了一些固有的种类,最值得注意的是,产生任务的线程可能会错过看到(和发信号)另一个寻找worker但是尚未进入等待队列的线程。当worker找不到要进行窃取的任务的时候,它会停用并排队,通常,由于GC或者OS调度。缺少任务是短暂的,为了减少错误警报的停用,扫描程序会在扫描期间计算队列的状态和校验和。此处和其他地方使用的稳定性检查是快照技术的概率变体,请参阅Herlihy&Shavit。工作者放弃并尝试仅在两次扫描的总和稳定之后才停用它。此外,为避免丢失信号,它们在成功入队后重复此扫描过程,直到再次稳定。在这种状态下,工作程序无法执行/运行它看到的任务,直到将其从队列中释放为止,因此工作程序本身最终会尝试释放其自身或任何后续任务(请参见tryRelease)。否则,在进行空扫描时,停用的工作人员会在阻塞(通过停车)之前使用自适应本地自旋构造(请参阅awaitWork)。请注意有关Thread.interrupts围绕停放和其他阻塞的不寻常约定:由于中断仅用于提醒线程检查终止(无论如何在阻塞时进行检查),因此我们在调用任何Park之前清除状态(使用Thread.interrupted),以便由于通过其他一些不相关的调用来设置状态以中断用户代码,因此Park不会立即返回。 - 信号和激活
当且仅当至少可以找到并执行一个线程的时候,才创建或者激活工作程序。在由worker或外部提交者将其推送到之前(可能是)的空队列的时候,会在空闲状态向worker发出信号。或者工作量小于给定的并行度,则会创建工作线程。每当其他线程从工作中删除任务并注意到那里还有其他任务时,这些主要信号就会被其他人支持。在大多数平台上,发信号(释放)的开销时间非常长,发信号的线程与线程实际取得进展之间的时间可能非常长,因此值得从关键路径上分担这些延迟。另外,由于不活动的工作人员通常是在重新扫描或旋转而不是阻塞,所以我们设置并清除了WorkQueues的“ parker”字段,以减少不必要的unpark的调用。这需要进行二次重新检查,以避免信号遗漏。
Trimming workers.需要在不使用的一段时间之后释放资源,如果pool在IDLE_TIMEOUT期间保持静止,则在处于静止状态时开始等待的工作程序将超时并终止,(请参阅awaitWork)随着线程数的减少,该时间段将增加,最终遣散所有worker。同样,当存在两个以上的备用线程时,多余的线程会在下一个静态点立即终止。 (两次填充可避免滞后现象。)
Shutdown and Termination,调用shutdownNow会使用tryTerminate以原子的方式设置runState位。调用线程以及此后终止的所有其他工作线程,通过设置其(qlock)状态。取消其未处理的任务并唤醒它们,反复执行直到稳定为止,以帮助终止其他线程(但循环受工作线程数量限制) )。调用non-abrupt shutdown()通过检查是否应该终止终止来开始此操作。这主要取决于维持共识的“ ctl”的活动计数位-每当静态时,trywaiter从awaitWork调用。但是,外部提交者不参与该共识。因此,tryTerminate会扫描队列(直到稳定),以确保缺少正在进行中的提交,并且工作人员将在触发终止的“停止”阶段之前对其进行处理。(注意:启用关闭功能后,如果调用helphelpQuiescePool会发生内在冲突。两者都等待静止,但是tryTerminate偏向于在helpQuiescePool完成之前不会触发。)
3.2.4 Joining Tasks
当一个worker正在等待join另外一个呗窃取的任务的时候,可以采取任何行动。因为我们将许多任务复制到一个工作的pool上,所以我们不能仅仅让他阻塞,如如Thread.join中一样。我们也不能仅仅将joiner的运行时堆栈重新分配给另一个,然后在以后替换它,这将是“ continuation”的一种形式,即使可能,也不一定是一个好主意,因为我们既需要无阻塞的任务,又需要继续执行进展。相反,我们结合了两种策略:
- Helping: 安排加入者执行一些如果没有发生窃取将要运行的任务。
- Compensating: 除非已有足够的活动线程,否则方法tryCompensate()可能会创建或重新激活备用线程以补偿阻塞的连接器,直到它们解除阻塞为止。
- 第三种形式(在tryRemoveAndExec中实现)相当于帮助了一个假设的补偿器:如果我们可以很容易地看出补偿器的可能动作是窃取并执行要加入的任务,则加入线程可以直接这样做,而无需执行任何操作。补偿线程(尽管以较大的运行时堆栈为代价,但通常值得进行权衡)。
ManagedBlocker扩展API不能使用Helping,因此仅依赖于方法awaitBlocker中的补偿。
helpStealer中的算法需要一种“线性帮助”形式。每个worker(在currentSteal字段中)记录它从其他worker(或提交)中窃取的最新任务。它还记录(在currentJoin字段中)它当前正在主动加入的任务。 helpStealer方法使用这些标记来尝试寻找可以帮助完成主动加入的任务的工作人员(即从中窃取任务并执行该任务)。因此,如果要加入的任务没有被窃取,则连接器执行的任务将由其自己的本地双端队列执行。这是Wagner&Calder的 《Leapfrogging: a portable technique for implementing efficient futures》SIGPLAN Notices, 1993 它的不同之处在于:
- (1)我们仅在窃取时在工人之间维护依赖关系链接,而不使用按任务记帐。有时这需要对workQueues数组进行线性扫描以找到盗窃者,但是通常不需要这样做,因为盗窃者会留下提示(可能会变得陈旧/错误),以查找盗窃者的位置。这只是一个提示,因为一个工人可能曾多次偷窃,而提示仅记录了其中一个(通常是最新的)。提示将成本隔离到需要的时间,而不是增加每个任务的开销。
- (2)它是“浅”的,忽略了嵌套和潜在的周期性相互窃取。
- (3)这是故意的:字段currentJoin仅在主动加入时更新,这意味着我们在长期任务,GC停顿等过程中会错过链中的链接(这是正常的,因为在这种情况下进行阻塞通常是个好主意) 。
- (4)我们使用校验和来限制找到工作的尝试的次数,然后回退到暂停该工作程序,并在必要时将其替换为另一个。
CountedCompleters的helping操作不需要跟踪currentJoins:方法helpComplete可以执行和执行与正在等待的任务具有相同根目录的任何任务(优先于本地polls而不是非本地轮询)。但是,这仍然需要完成程序链的遍历,因此效率不如使用没有显式联接的CountedCompleters。
补偿的目的并不是要确保在任何给定时间都运行无阻塞线程的目标并行度。此类的某些先前版本对任何阻塞的连接立即采用补偿。但是,实际上,绝大多数阻塞是GC和其他JVM或OS活动的暂时性副产品,这些副产品由于更换而变得更糟。当前,仅在通过检查字段WorkQueue.scanState确认所有据称活动的线程正在处理任务之后才尝试进行补偿,从而消除了大多数误报。同样,在最不常见的情况下,绕过补偿(允许更少的线程)是很少有好处的:当队列为空的工人(因此没有继续任务)在联接上阻塞时,仍然有足够的线程来确保活动。
补偿机制可能是有界的。 commonPool的界限(请参阅commonMaxSpares)可以使JVM在耗尽资源之前更好地应对编程错误和滥用。在其他情况下,用户可能会提供限制线程构造的工厂。与其他所有池一样,此池中的边界影响不精确。当线程注销时,总的工作人员计数会减少,而不是在线程退出并且JVM和OS回收资源时减少。因此,同时处于活动状态的线程数可能会暂时超出限制。
3.2.5 Common Pool
静态的公共的pool在静态初始化之后始终存在。由于不需要使用它,或者任何其他创建的pool,因此我们将初始构造开销和占用空间最小化到大约十二个字段的设置,而没有嵌套分配。在第一次提交到pool期间,大多数引导发生在externalSubmit方法中。
当外部线程提交到公共的pool的时候,他们可以在join的时候执行子任务的处理,(请参阅externalHelpComplete和相关方法)通过此呼叫者帮助策略,可以明智地将公共池并行度级别设置为比可用核心总数少一个(或多个),对于纯呼叫者运行,甚至可以设置为零。我们不需要记录是否将外部的提交提交到公共pool中-否则,外部helping方法会迅速返回。否则,这些提交者将被阻止等待完成,因此在不适用的情况下,额外的工作量(使用大量的任务状态检查)在限制ForkJoinTask.join之前是有限的轮换等待的一种奇怪形式。
作为托管环境中更合适的默认值,除非存在系统属性覆盖,否则当存在SecurityManager时,我们将使用子类InnocuousForkJoinWorkerThread的工作程序。这些工作程序没有权限设置,不属于任何用户定义的ThreadGroup,并且在执行任何顶级任务后请擦除所有ThreadLocals(请参阅WorkQueue.runTask)。关联的机制(主要在ForkJoinWorkerThread中)可能取决于JVM,并且必须访问特定的Thread类字段才能实现此效果。
3.2.6 Style notes
内存排序主要依赖于Unsafe内部函数,这些内部函数承担进一步的责任,即明确执行空检查和边界检查,否则将由JVM隐式执行。这样写代码可能会非常丑陋,但也反映了需要控制非常活跃的代码中很少有不变量的异常情况下的结果。因此,这些显式检查无论如何都会以某种形式存在。使用之前,所有字段都被读入本地,如果它们是引用,则进行空检查。通常以“ C”类样式在方法或块的开头列出声明,并在首次遇到时使用内联分配来完成。数组边界检查通常是通过用array.length-1进行掩码来执行的,array.length-1依赖于不变的条件,即这些数组是用正长度创建的,而该长度正好是自相矛盾地检查的。几乎所有显式检查都会导致绕过/返回,而不是引发异常,因为它们可能由于关机期间的取消/吊销而合法地出现。
在类ForkJoinPool,ForkJoinWorkerThread和ForkJoinTask之间,有很多表示层级的耦合。WorkQueue的字段维护由ForkJoinPool管理的数据结构,因此可以直接访问。减少这种情况几乎没有意义,因为无论如何表示形式的任何相关的将来更改都将需要伴随算法更改。几种方法本质上无处不在,因为它们必须累积对局部变量中保存的字段的一致读取集。还有其他编码异常(包括一些看上去不必要的悬挂式空检查),即使在解释(未编译)时也可以帮助某些方法合理地执行。
该文件中的声明顺序为(除少数例外):
- (1)静态实用程序函数
- (2)嵌套(静态)类
- (3)静态字段
- (4)字段以及在解压缩某些字段时使用的常量
- (5)内部控制方法
- (6)对ForkJoinTask方法的回调和其他支持
- (7)导出的方法
- (8)以最小相关顺序进行初始化的静态代码块
4.总结
本文介绍了ForkJoin的基本使用,及其基本的工作原理,虽然ForkJoin实际的代码非常复杂,但是通过本文我们应该了解到ForkJoinPool底层的分治算法和工作窃取原理。此外本文也介绍了ForkJoinPool的一些实现原理,这将在后续源码介绍中,逐步详细说明。ForkJoin不仅在java8之后的stream中广泛使用。golang等其他语言的协程机制,也是采用类似的原理来实现的。我们需要重点掌握Fork-Join的本质。
参考作者:冬天里的懒喵