【C# 学习笔记 ①】C# 程序结构和基本语法(VSCode工具配置、数据类型、修饰符、构造函数)
由于在自己的工作和学习过程中,只查看某个大佬的教程或文章无法满足自己的学习需求和解决遇到的问题,所以自己在追赶大佬们步伐的基础上,又自己总结、整理、汇总了一些资料,方便自己理解和后续回顾,同时也希望给大家带来帮助,所以才写下该篇文章。在本文中,所有参考或引用大佬们文章内容的位置,都附上了原文章链接,您可以直接前往查阅观看。在原文章内容的基础上,若无任何补充内容,同时避免直接大段摘抄大佬们的文章,该情况下也只附上了原文章链接供大家学习。本文旨在总结归纳,并希望给大家提供帮助,未用作任何商用用途。文章内容如有错误之处,望各位大佬指出。如果涉及侵权行为,将会第一时间对文章进行删除。
个人博客主页
一个努力学习的程序猿
本文所在专栏: C# 专栏,欢迎大家前往查看更多内容
专栏内目前所有文章:
不定期持续更新中
C# 学习笔记 ①
- 专栏前言
- VSCode开发工具配置
- C#程序结构
-
- 前言
- 命名空间 namespace 声明和 using 引入
- Main 方法和 Class 类
- C#基本语法(数据类型、变量、常量、函数)
-
- 前言
- 值类型 和 类型转换
- 引用类型
- 变量、常量
- 可空类型
- 值类型 和 引用类型区别
- 成员变量、修饰符
- 运算符、成员函数
- 方法
- 构造函数、析构函数、静态成员
- 命名规则和书写规范
专栏前言
笔者的本专栏不建议零基础初学者查看,因为笔者记录 C# 基础用法,主要是用于之后更好的使用 Unity 游戏引擎做查阅和回顾。且笔者已经接触过很多语言,所以会有很多不同语言中共通的基础词汇概念,但是在文中不会做详细说明,所以对初学者来说可能无法理解。除此以外,笔者对 C# 也没有较深层面的了解,所以很多用法笔者也不会完全总结到。所以如果您想更全面的学习 C#,建议找其他更系统的教学文章。
如果您依然选择学习 C#,但对 C# 不太了解的话,笔者在这里就不进行大篇幅复制粘贴了,网上全都是使用说明和介绍,您可以自行搜索或前往以下文章查阅:C#语言 百度百科
以下为本专栏所有参考教程。但由于原教程很多说明仍不够全面,需要多方面寻找资源和自行测试才能满足学习需求,所以笔者才会有本专栏文章,从中总结相关用法。在本专栏的所有参考文章处,都会有原文章链接,且保证本专栏的所有文章不会进行大篇幅引用。专栏内所有文章没有用于商用用途,如果涉及侵权行为,将会第一时间对文章进行删除。
感谢前辈大佬们的付出:
菜鸟C# 教程
C#教程
php中文网C#教程
VSCode开发工具配置
对于 C# 的开发工具,您可以选择 Visual Studio Code、Visual Studio Community 或其他工具。笔者使用的是 VSCode(Visual Studio Code)。
由于笔者参考了以下文章,其中的方法完全可行,因此为了避免大篇幅引用,尊重原创,需要您自行前往查看配置:如何使用VSCode书写C#代码
如果使用别的开发工具,相关用法和问题就需要麻烦各位自行搜索解决了。
而在创建项目的过程中,可以发现用到了 dotnet 命令。对于这个命令,笔者就不进行详细说明了,从基础使用上来说,至少请记住以下用法。
| 命令 | 说明 |
|---|---|
| dotnet --help | 打印出有关如何使用命令的说明 |
| dotnet --version | 显示使用中的.NET Core SDK版本 |
| dotnet new console -o xxx | 创建项目 |
| dotnet run | 无需任何显式编译或启动命令即可运行源代码 |
如果对更多内容感兴趣,建议您前往以下文章查阅:
微软官方dotnet 命令
什么是C#?什么是DOTNET?
DotNet就是C#?
C#程序结构
前言
(使用 VSCode 创建 C# 项目已经在上文有所表述,C# 文件的后缀为 .cs)
在创建好一个 C# 项目后,最首要的还是先看一下 C# 的程序结构。以下为一个最基础的程序结构。如果学习过 Java,那么对该程序结构肯定不陌生。
using System;
namespace C_
{
class Program
{
static void Main(string[] args)
{
/* 注释 */
Console.WriteLine("Hello World!");
Console.ReadKey();
}
}
}
整体来说,一个 C# 程序,必须包含以下两个部分:
(1)命名空间的声明和引入;
(2)一个拥有 Main 方法的 Class 类。
接下来对上述两个部分进行说明。
命名空间 namespace 声明和 using 引入
using System;
namespace C_
{
class Program
{
static void Main(string[] args)
{
/* 注释 */
Console.WriteLine("Hello World!");
Console.ReadKey();
}
}
}
命名空间可以短浅的理解为,这是对一部分代码内容的命名,且它在整个 C# 程序中都是独一无二的。它的使用方式就可以像代码第 3 行一样,使用 namespace 进行声明。这个 namespace 中就可以包含一系列的类。就比如例子中,C_ 命名空间包含了一个类(Class)Program。
需要注意:命名空间不能重复,但在不同命名空间里声明的不同类、常量名等名称是可以重复的。
命名空间的作用就是:在代码量较大时,不同的功能模块就可以放在不同的命名空间中,此时不同模块的开发人员就不会因为和其他开发者的代码使用相同的类名、接口名、函数或常量名而造成冲突。
在代码第一行中的 using System; ,其中的 using 关键字就是用于在当前文件中引入命名空间,也就是引入其中的变量名、函数等用法,从而允许我们在当前文件中使用。而这个 System 命名空间中,就有着所有 .net 基础类型和通用类型,也就是我们要使用的一些基础用法。当然,一个程序中可以有多个 using 语句,想使用更多用法就需要去引入其他命名空间。
除此以外,我们也可以引入我们自己创建的 C# 文件中的命名空间。不过下例中有些用法目前还没提及,先有所了解就好,在这里先不做说明。简单演示如下:
Program.cs
using System;
using Test;
namespace C_
{
class Program
{
static void Main(string[] args)
{
TestMain A = new TestMain();
A.classTest();
Console.WriteLine("Hello World!");
Console.ReadKey();
}
}
}
test.cs
using System;
namespace Test
{
class TestMain
{
public void classTest()
{
Console.WriteLine("Hello T!");
}
}
}
如果您想知道其他常用命名空间或其他内容,建议您前往以下文章查阅:
常用命名空间
C# 10 的基于文件的命名空间声明语句
C#命名空间详解namespace
Main 方法和 Class 类
using System;
namespace C_
{
class Program
{
static void Main(string[] args)
{
/* 注释 */
Console.WriteLine("Hello World!");
Console.ReadKey();
}
}
}
在代码的第 5 行可以看到一个 class 声明,第 7 行可以看到 Main 方法。
这个 class 就被称作类,在类中可以定义多个方法、多个变量或者其他数据(后续提及)。比如上述代码中,类 Program 里包含一个 Main 方法。通常我们会说这些方法将会定义该类的行为。而 Main 方法比较特殊,它在程序中是必须要定义的,它是 C# 程序的入口点。它的写法必须像第 7 行那样。如果不写,程序将报错。在 Main 方法中,就可以写一些程序要执行的内容。对于类的更多说明,将在专栏后续说明。目前先记住这样的基本使用。
需要注意的是:类名不要和命名空间名称相同,否则就会出现这样的报错:
![]()
接下来看一下在 Main 方法中写的内容:
第 9 行的 /*...*/ 是 C# 的多行注释,被它包裹的部分将会被编译器忽略,从而允许我们在程序上做一些标注和说明。单行注释可以用 // 。
第 10 行的 Console.WriteLine("Hello World"); 是 C# 控制台的输出,您可以直接这样记忆。能这样用的依据是:WriteLine 是一个定义在 System 命名空间中的 Console 类的一个方法。该语句执行后,会在屏幕上显示消息 “Hello World”。
第 11 行的 Console.ReadKey(); 是针对 VS.NET 用户的。这使得程序会等待一个按键的动作,防止程序从 Visual Studio .NET 启动时屏幕会快速运行并关闭。除了 ReadKey,也还可以使用 Console.ReadLine(); ,它将使得程序等待按下回车的操作。
关于它们的更多用法将在文章下方用到时说明。
在最初的学习中,最常问的问题就是:既然已经有命名空间了,那么类还有必要使用吗?命名空间和类有什么区别?
刚才其实有说到,命名空间更多的作用是区分不同的代码块,而在命名空间中可以写很多类,类是对数据和方法的封装。在调用时因为表明了具体的命名空间,所以使用就不会导致命名冲突。这些内容就需要在不断的开发中体会这些含义。
通过以上对程序基本结构的了解,在这里我们还需要注意以下内容:
① C# 是大小写敏感的。也就是说 Test 不能写作 test;
② 如果您学习过 Java,那么千万不要与 Java 混淆。与 Java 不同的是,C# 文件名可以不同于类的名称;
③ 所有的语句和表达式必须以分号(;)结尾;
④ 程序的执行将会从 Main 方法开始。
目前我们已经知道命名空间的声明和引入,了解到类和 Main 函数的存在,在引入自定义命名空间的时候还看到了类的实例化的用法(虽然在上文中未进行详细说明)。接下来将详细总结一下类和数据的使用。
C#基本语法(数据类型、变量、常量、函数)
前言
C# 是一种面向对象的编程语言,在面向对象的程序设计方法中,程序由各种相互交互的对象组成。相同种类的对象通常具有相同的类型,或者说,是在相同的 class 中。
接下来将会先展示一段代码,随后根据这个完整的样例,说明 C# 的基本用法。如果您对程序结构有所了解,您可以直接跳到对应用法部分。
例如,在下面的代码里,有一个 Pet 类,将该类实例化后得到了 pet、pet2 对象。以 pet 对象为例。它具有 name、age 属性(成员变量),拥有 1 个有参和 1 个无参构造函数,还有 4 个方法(函数 / 成员函数)。根据设计,它会通过调用方法,实现对 age 的修改和获取,最后显示结果。代码中有些基础注释,方便有其他语言基础的朋友查看,在经过查看后,肯定对相关使用有所了解;如果您不太了解,那么也请在大致了解程序结构后,再去查看后文的具体用法表述。
using System; // 命名空间引入
namespace AnimalTest // 声明命名空间
{
// 类 Pet:简单来说就是存储对象的属性和方法
class Pet
{
// 成员变量
// 对象标识符在C#里分为private、public、protected、internal、protected internal,如果不标注默认为 internal。
// 被public标注的是公有变量,可以在类外使用
// 被private标注的是私有变量,只能在类里使用
// 注意:在C#里,数据类型一定要指明。
public string name = "狗";
public int age = 1;
// private int age = 1; // 测试 private
// 构造函数:创建给定类型的对象时执行的类方法
// C#里的构造函数和类名是相同的
// 就算不手动创建,C#也一定会创建这个无参的构造函数
// 所以无参构造函数也被称为默认构造函数
// 那既然它会自动创建,那为什么要手动创建?
// 这里需要注意:
// 1、如果类里没有构造函数,那么不传参数也不会报错
// 因为它自动创建了无参的构造函数
// 2、但是如果类里存在有参的构造函数,
// 那么这个无参构造函数,如果不手动创建,它是没效果的
// 也就是说,这时不传参数是会报错的
// 3、所以这也就是为什么,虽然我们创建了有参的构造函数
// 习惯上还要创建无参的构造函数
// 手动创建了有参构造函数,之后传递参数时一定需要严格对照
// 这种方式也被称作函数的重载
// 同名函数只要形参不同,那么调用同名函数时,就会根据实参的不同来调用相应函数
// 此时,我们创建实例时,如果传递参数,就会赋值给name
// 如果不赋值,name就会为默认值
public Pet() {}
public Pet(string name)
{
this.name = name;
}
public int GetAge() // 成员函数
{
return age;
}
public double testAge() // 成员函数
{
return age * 5; // 使用运算符
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
public void Display() // 成员函数
{
Console.WriteLine("age: {0}", age);
Console.WriteLine("GetAge: {0}", GetAge());
Console.WriteLine("testAge: {0}", testAge());
}
}
class Program
{
static void Main(string[] args)
{
Pet pet = new Pet(); // 类的实例化:生成一个对象
Console.WriteLine(pet.age);
Pet pet2 = new Pet("猫"); // 可以利用构造函数传参
Console.WriteLine(pet2.name);
Console.WriteLine("Main第一次调用GetAge: {0}", pet.GetAge());
pet.SetAge(3);
Console.WriteLine("Main调用SetAge");
Console.WriteLine("Main第二次调用GetAge: {0}", pet.GetAge());
pet.Display();
const int c1 = 5; // 常量
int d = 3, f = 5; /* 初始化 d 和 f. */
char x = 'x'; /* 变量 x 的值为 'x' */
Console.ReadLine(); // 等待按下回车
}
}
}
以下为输出结果:
1
猫
Main第一次调用GetAge: 1
Main调用SetAge
Main第二次调用GetAge: 3
age: 3
GetAge: 3
testAge: 15
接下来就将整个代码分成几个功能来看待和说明。首先先来说明数据类型。
在样例中,我们可以看到这样的用法:
char x = 'x';
这里的 char 就是一种数据类型(注意这里是单引号,引号的区别在下文说明)。在 C# 中,变量可以分为以下几种类型:
值类型(Value types)
引用类型(Reference types)
指针类型(Pointer types)
本文将只说明前两种类型,指针类型目前将不会在专栏中说明,各位如有需要麻烦自行搜索查阅。
值类型 和 类型转换
C# 2010 可用值类型:
【表格转自菜鸟教程】
| 类型 | 描述 | 范围 | 默认值 |
|---|---|---|---|
| bool | 布尔值 | True 或 False | False |
| byte | 8 位无符号整数 | 0 到 255 | 0 |
| char | 16 位 Unicode 字符 | U +0000 到 U +ffff | ‘\0’ |
| decimal | 128 位精确的十进制值,28-29 有效位数 | (-7.9 x 1028 到 7.9 x 1028) / 100 到 28 | 0.0M |
| double | 64 位双精度浮点型 | (+/-)5.0 x 10-324 到 (+/-)1.7 x 10-308 | 0.0D |
| float | 32 位单精度浮点型 | -3.4 x 10-38 到 + 3.4 x 10-38 | 0.0F |
| int | 32 位有符号整数类型 | -2,147,483,648 到 2,147,483,647 | 0 |
| long | 64 位有符号整数类型 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | 0L |
| sbyte | 8 位有符号整数类型 | -128 到 127 | 0 |
| short | 16 位有符号整数类型 | -32,768 到 32,767 | 0 |
| uint | 32 位无符号整数类型 | 0 到 4,294,967,295 | 0 |
| ulong | 64 位无符号整数类型 | 0 到 18,446,744,073,709,551,615 | 0 |
| ushort | 16 位无符号整数类型 | 0 到 65,535 | 0 |
需要提示的是,平常这些类型的位数和取值范围可以不去记忆,在需要的时候再查看也不迟,但请至少需要记住这3个常用的:int 存储整数,char 存储字符,float 存储浮点数(小数)。这样一来,平常就需要有意识的注意是否可能要存储一个可能超出值类型范围的值,再通过表格确定,从而在使用时小心数据溢出或出现报错。
在这里需要注意的是:
(1)在声明变量、常量时,必须要提供数据类型,否则只会当作一个普通的赋值操作来处理,比如:
x2 = 22;
![]()
(2)如果确定了变量的数据类型,那么在赋值时,必须相对应。比如声明了一个char,那么赋值时必须是字符,不能是数字,且必须遵守该数据类型的范围。演示如下:
char x = 'x';
x = 22;
![]()
char x = 'x';
x = 'xx';
![]()
在第一个报错中,我们将 int 赋值给了一个声明为 char 的变量。此时的报错信息其实提到了解决方案,即类型转换。类型转换就是把数据从一种类型转换为另一种类型。它的实现方式有两种,就是报错中提到的隐式转换和显式转换。
先说显式类型转换。显式类型转换也被称作强制类型转换。它会强制转换运算符,也就导致可能会造成数据的丢失。比如:
double d = 5673.74;
int i;
// 强制转换 double 为 int
i = (int)d;
Console.WriteLine(i);
输出结果为:5673
在这种情况下,如果不使用显式类型转换就会报错。究其原因就是,将一个浮点数转换成整数,可能会导致后面的小数部分被舍弃,即将一个高精度的数值类型变化成了一个低精度的数值类型。同理,将 int 整数转换成 char 字符肯定也会造成差异,显然也需要使用显式类型转换(但是从 char 转换成 int 是隐式类型转换)。而反过来说,隐式类型转换就是 C# 默认的以安全方式进行的转换,不会报错,也不会导致数据丢失。这就是因为,它将一个低精度的数值类型变化成了一个高精度的数值类型。比如:
int e = 100;
double g = e;
Console.WriteLine(g);
输出结果为:100
上述的显式类型转换只是1个简单方法,且这种用法只支持 (int),也就是说没有其他值类型的使用方式,比如 (char)。而其他的显式类型转换方式,为了避免大篇幅引用,建议您在有需要时查询相关方式即可:
C# 类型转换
https://www.runoob.com/csharp/csharp-type-conversion.html
https://blog.csdn.net/chenmo2001/article/details/122361680
C# 内置的类型转换方法
C#类型转换的几种方式
需要说明的是:平常不推荐使用显式类型转换,因为这真的可能会导致出现意料之外的结果。但如果真的有需要的数据变化,就一定要注意类型转换问题。
不过,有 1 种情况我们是必须考虑显式类型转换的,那就是接收来自用户输入的值。用法如下:
int num;
num = Convert.ToInt32(Console.ReadLine());
Console.WriteLine(num);
Console.ReadLine() 在之前使用时,用来避免程序启动时屏幕会快速运行并关闭。而它之所以能实现避免程序启动时屏幕会快速运行并关闭,就是因为加了这行代码,程序将会等待用户输入一行信息。使用 Console.ReadKey() 也可以,但是它只能接收 1 个按键。
当我们使用 Console.ReadLine() 接收来自用户的输入时,此时任何的输入结果都是一个字符串格式(引用类型)的数据。所以,如果我们要把它存储到一个变量中,就需要把用户输入的数据转换为对应的数据类型,比如在上例是 int。
关于更多信息,为了避免大篇幅引用,您可以查看以下文章查阅:
用户输入类型转换
最后补充一点,在值类型的表格中,其实可以看到某数据类型占据了多少位数。如需得到一个类型或一个变量的准确尺寸,可以使用 sizeof 方法。它将产生以字节为单位存储对象或类型的存储尺寸。比如:
Console.WriteLine("Size of int: {0}", sizeof(int));
输出结果为 Size of int: 4 (4字节,32位,与表格中表述相符)
引用类型
引用类型: 类 class、对象 object、数组 type []、字符串 string、委托 delegate、接口 interface 等等。其中一些内容将在后续具体说明。在这里先只说字符串(String)类型的基本用法。
在这里还需要知道的是,对象(Object)类型是 C# 通用类型系统中所有数据类型的终极基类,也就是对象类型可以被分配任何其他类型(值类型、引用类型、预定义类型或用户自定义类型)的值。
由于值类型中的 char 只能接收 1 个字符,那么更多字符显然需要另一个数据类型存储。而这个类型就是字符串类型,它将允许给变量分配任何字符串值。字符串类型的值可以通过两种形式进行分配:双引号和 @双引号。(注意:char 接收 1 个字符使用单引号,string 接收字符串使用双引号)比如:
string a = "hello, world";
string str = @"C:\Windows";
在具体说 @ 之前,先介绍转义字符 \。我们在输入字符串的过程中,可能会碰到一些特殊字符,比如双引号目前是用来包裹字符串的,那如果我们想在输出结果上展示双引号,那么没有任何操作的情况下,就会出现这样的情况:
string test = "他说:"大家好""
Console.WriteLine(test);

即程序把双引号当成某种用法,而不会把它考虑成字符串中的一个字符。如果想解决这样的问题,就需要使用转义字符 \。比如:
string test = "他说:\"大家好\"";
Console.WriteLine(test);
那再考虑到别的问题,比如让输出结果在特定位置换行,或者输出 \(不让 \ 被识别成转义字符)等等,而想要解决这样的问题,就是使用转义字符,使用如下:
【图片截取自菜鸟教程】

说回到 @,@ 被称作逐字字符串,它会将转义字符 \ 当作普通字符对待,比如上面的:
string str = @"C:\Windows";
其实就等价于:
string str = "C:\\Windows";
除此以外,@ 字符串中可以任意换行,换行符及缩进空格都计算在字符串长度之内。
综合例子如下【代码选自菜鸟教程】:
string a = "hello, world"; // hello, world
string b = @"hello, world"; // hello, world
string c = "hello \t world"; // hello world
string d = @"hello \t world"; // hello \t world
string e = "Joe said \"Hello\" to me"; // Joe said "Hello" to me
string f = @"Joe said ""Hello"" to me"; // Joe said "Hello" to me
string g = "\\\\server\\share\\file.txt"; // \\server\share\file.txt
string h = @"\\server\share\file.txt"; // \\server\share\file.txt
string i = "one\r\ntwo\r\nthree";
string j = @"one
two
three";
需要注意的是:
(1)使用 char 数据类型时,必须使用单引号。如果此时使用双引号会报错:
char x = "x";
![]()
而使用 string 数据类型时,必须使用双引号,否则报错:
string a = 'a';
![]()
(2)要注意转义字符的使用,否则报错:
![]()
如果您想知道更多引用类型的信息,可以前往以下链接查看:
C#引用类型
https://www.runoob.com/csharp/csharp-data-types.html
https://blog.csdn.net/MUZIOHH/article/details/118525177
变量、常量
变量在上文中已经出现过声明方式:数据类型 名称 = 值。比如:
char x = 'x';
这里的变量名称就是 x,该变量的值在这里是 字符 x。我们常说的变量就是指这个供程序操作的存储区的名字。在上文中也提到,每个变量都需要有一个特定的类型,类型将会决定变量的内存大小和存储方式(下文 值类型和引用类型区别 小节中将进行更多补充说明)。随后我们就可以对变量进行一系列操作。
如果我们想声明数据类型相同的多个变量,那么可以这样用,从而避免每次声明变量都要另起一行。
int d = 3, f = 5; /* 初始化 d 和 f. */
如果我们想声明一个常量,只需要加一个 const 关键字。常量就是在程序执行期间,这个值不会改变,同时程序也不会让你改变,否则会报错。常量可以是任何基本数据类型。
const int c1 = 5; // 常量
当然,有些情况下可能不想在声明变量的时候就给它初始值,那么也可以在后续对其赋值。比如:
int c;
c = 5;
但是建议如果能赋予变量初始值,就请在声明变量的时候提供,否则程序的输出结果很有可能会产生意想不到的结果(因为声明的变量会有默认初始值,在上方的数据类型表单中有些到,所以如果先声明,那么在下次赋值之前一定要小心处理数值。而且也要注意声明变量的作用域问题)。
除此以外,变量、常量可以是十进制、八进制或十六进制数、浮点数(小数或指数)。
前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,没有前缀则表示十进制。
也可以有后缀,可以是 U 和 L 的组合。其中,U 和 L 分别表示 unsigned 和 long。后缀可以是大写或者小写,多个后缀也可以以任意顺序进行组合。
85 /* 十进制 */
0213 /* 八进制 */
0x4b /* 十六进制 */
30 /* int */
30u /* 无符号 int */
30l /* long */
30ul /* 无符号 long */
使用浮点形式表示时,必须包含小数点、指数或同时包含两者。使用指数形式表示时,必须包含整数部分、小数部分或同时包含两者。有符号的指数是用 e 或 E 表示的。
3.14159 /* 合法 */
314159E-5L /* 合法 */
510E /* 非法:不完全指数 */
210f /* 非法:没有小数或指数 */
.e55 /* 非法:缺少整数或小数 */
需要注意的是:
(1)声明一个常量时,必须要给与初始值。否则报错:
![]()
(2)在代码中,无法修改常量的值。否则报错:
![]()
(3)在代码中,在同一个变量的作用域内,无法重复声明同名变量、常量。否则报错:
![]()
您可能目前对同一个变量的作用域没有概念,而且这里还会涉及到其他内容,在这里无法全部说明,后续在碰到时会有所提及。简单来说,比如这样声明当然就不行:
const int c1 = 5;
const int c1 = 10;
其实 C# 也存在着一种声明全局变量的方法,即允许变量在不同的作用域之间传递数据。在这里将不做说明。如果您感兴趣,可以前往以下文章查看,用法比较简单:
C#全局变量的定义和使用
可空类型
我们在以上的使用中,已经知道每个数据类型所能存储的数据,比如 int 会存储 32 位有符号整数。但在工作中会存在一种情况,就比如提交表单的时候,总会有些非必填项,这时如果没填写这些非必填项的话,且这些非必填项是 int、double 等数据类型的时候,显然不符合存储要求了。虽然我们可以在接收到为空的数据时,给它一个默认初始值,但在某些情况下,这很有可能会出现歧义,因为用户并没有填写表单,但是却给了它一个值。所以这个时候,就可以使用可空类型(Nullable)。比如:
int i; // 默认值为0
int? ii; // 默认值为null
使用可空类型就相当于在这个值类型取值范围的基础上,再允许加上一个 null 值,只需要在数据类型后加上 ? 问号。
而如果想在接收到为空的数据时,给它一个默认初始值的话,可以使用 Null 合并运算符 ??,比如:
using System;
namespace Test
{
class Program
{
static void Main(string[] args)
{
int? i = new int?();
int result;
result = i ?? 10; // i 如果为空则返回 10,否则返回 i
Console.WriteLine("result 的值:{0}", result);
Console.ReadLine();
}
}
}
输出结果:
result 的值:10
Null 合并运算符 ?? 还可以等价成这样使用:
using System;
namespace Test
{
class Program
{
static void Main(string[] args)
{
int? i = new int?();
int? result;
result = (i == null) ? 10 : i; // i 如果为空则返回 10,否则返回 i
Console.WriteLine("result 的值:{0}", result);
Console.ReadLine();
}
}
}
值类型 和 引用类型区别
常见类型:
引用类型:类 class,对象 object,数组 type [],字符串 string,委托 delegate,接口 interface
值类型:整数 int,浮点数 float double,布尔 bool,字符 char,结构 struct,枚举 enum
对于值类型和引用类型的区别,不仅仅是在使用上数据类型的差异,在这里还有要说明的其他问题。如果对于其他语言(Java、JS)有所了解的话,该问题会很好理解。直接看一个例子:
int a = 3;
int b = a;
b = 5;
Console.WriteLine("a: {0}", a);
Console.WriteLine("b: {0}", b);
char[] c = {'a', 'b', 'c'};
char[] d = c;
d[2] = 'd';
Console.WriteLine("c: {0} {1} {2}", c[0], c[1], c[2]);
Console.WriteLine("d: {0} {1} {2}", d[0], d[1], d[2]);
输出结果:

这里做演示的是引用类型中的数组。数组就可以简单理解成,是一个同一类型变量的集合。在这里先忽略具体的数组使用方法,之后还会介绍。
通过输出结果我们可以发现,如果是值类型,那么将 a 的值赋给 b,再修改 b 的值,输出结果显然没超出我们的预期,也就是 b 的值改变了,而 a 的值没改变。而如果声明的是数组,那么在这里只是想将 c 数组复制一份给 d,然后再修改 d 数组中指定位置上的字符,此时输出结果可以发现,c 数组指定位置上的字符也因为 d 的改变而改变。
出现这个情况的原因是:值类型的变量在分配一个值时,值类型将会直接包含该数据。比如当声明一个 int 类型时,系统分配内存来存储该值。而能这么做也是因为,在上文提到值类型时,提到过需要注意它的位数也就是数值范围。这也就保证了,系统只需要分配固定的内存存储,也就不需要考虑其他因素。但对于引用类型则完全不同,系统无法分配固定的内存存储,且还有可能继续增大存储空间。所以解决办法就是:引用类型不包含存储在变量中的实际数据,而只是包含它对变量的引用,也就是指向一个内存地址。实现的形式就是使用堆栈。也许您对堆栈的概念不了解,在这里简单理解就好:(引用类型在栈内的空间大小相同)
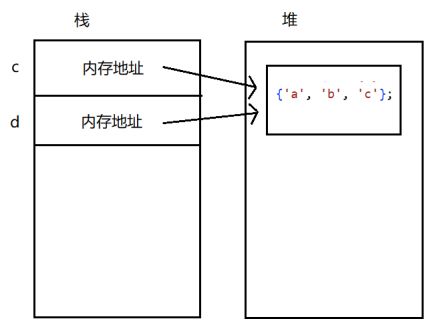
在本专栏将不详细说明数据结构,如果感兴趣可以前往我的专栏查看和数据结构相关的内容(虽然是Java,但道理相同):
Java数据结构与算法
所以根据上图,当把 c 赋值给 d 时,其实是把内存地址给了过去,这也就代表着,此时 c 和 d 指向的是同一个内存地址。这也就造成了当修改 d 的时候,它去到了这个内存地址上,修改了对应值,导致一个变量改变,其他变量也会自动反映这种值的变化。
但经过自己的测试发现,并不是所有引用类型都会出现这样的问题。由于自己对 C# 没有深入了解,只是停留在使用层面,所以更多内容和细节只能麻烦各位自行百度了。不过在这里至少已经知道,引用类型存储的是对变量的引用,也就是一个内存地址。之后就需要注意这样的赋值,从而避免出现一个变量改变导致其他变量也改变的 bug 问题。
那说回来如果真的想复制一份变量到另一个变量上,重复声明是不是有点太麻烦了?是的,所以在其他语言中有着对应的解决办法,那就是深克隆和浅克隆,C# 也不例外。
对于深浅克隆的定义,网上说法不一,笔者也就不瞎说了,但核心道理是一样的。深克隆说白了就是解决引用类型变量赋值给另一个变量时,只传递内存地址的问题,将原有变量中的值,完全新增一份,赋值给另一个变量,从而避免互相影响。而浅克隆看起来就比较无用了,对于一些对象,它只能复制其中的值类型字段,而对于其中的引用类型还会属于原来的引用。具体的使用将不在这里说明,感兴趣可以百度或前往以下文章查阅:
C# - 浅克隆与深克隆(浅拷贝与深拷贝)
C#浅度克隆和深度克隆
c# 深克隆与浅克隆
C# 浅克隆 Object.MemberwiseClone用法及代码示例
成员变量、修饰符
在最开始的样例中,我们可以看到这样的结构:
class Pet
{
// 成员变量
public string name = "狗";
public int age = 1;
// 构造函数
public Pet() {}
public Pet(string name)
{
this.name = name;
}
public int GetAge() // 成员函数
{
return age;
}
public double testAge() // 成员函数
{
return age * 5; // 使用运算符
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
}
这是一种引用类型 class 类。在这个类里,可以声明一些变量和一些 “用法”。变量应该已经熟悉了,而这些可以对变量进行操作的 “用法” 就被称作函数 或 方法。在这个类中,就会存储这些针对于这个类的属性和方法。其中的变量就是成员变量,其中的函数就是成员函数。这里还有一个构造函数,不过函数部分将在下文中说明。而如果我们想具体使用这些内容,就是对该类进行实例化,而经过实例化得到的这个所谓“变量”就是对象。比如:
Pet pet = new Pet(); // 类的实例化:生成了一个对象
在这里使用成员变量时,可以明显看到了一个改变,就是在变量声明的前面出现了一个修饰符 public。比如:
public int age = 1;
在说修饰符之前就需要提到访问权限。其实在上文中有提到作用域,在这里也有类似概念。比如在 Main 中声明了一个变量,那么这个变量只能在它的下文使用,不能在另一段代码区间里使用(比如另一个Class类里的方法)。再比如在一个方法(函数)中,声明了一个变量,那么在其他方法中显然也就不能直接使用。而这样的变量,也被称作局部变量,它有它自己的作用范围。那相对的就是上文中提到的全局变量。
同理的,在 Class 类里声明的成员变量,它肯定也会有自己的作用域。比如它可能只允许在自己的类里使用,又或者允许这个变量在别处使用,而决定这个权限的,就是修饰符。这个修饰符有很多种,可分为:private、public、protected、internal、protected internal。在这里就介绍常用的3个。
public(公开)修饰的成员可以被类的内部或者是外部直接访问;
private(私有)修饰的成员只能被类的内部访问;
protected(受保护的)修饰的成员可以在类的内部或者在派生类中访问,不管该类和派生类是不是在同一程序集中;(其中的概念在后续使用到时说明)
比如我们可以这样用:
using System;
namespace AnimalTest
{
class Pet
{
public string name = "狗";
private int age = 1;
}
class Program
{
static void Main(string[] args)
{
Pet pet = new Pet(); // 类的实例化:生成了一个对象
Console.WriteLine(pet.age);
Console.WriteLine(pet.name);
Console.ReadLine();
}
}
}
(访问类的成员需要使用 . 运算符去链接对象的名称和成员的名称)
那么 pet.name 就可以获取到,而使用 pet.age 就会报错,因为它是 private。
![]()
除此以外,不标注修饰符其实也可以,不过建议还是标注上,避免错误。如果不标注修饰符,那么成员变量和函数会默认成 private。(类的默认访问标识符是internal,它的受保护级别也是很高的,它将只能在同一程序集中访问,在这里将不作说明)如果您对访问权限和更多的使用方法感兴趣,可以百度或前往以下文章查阅:
C# 成员默认访问权限(public、private、protected、internal)
Public、Private以及Protected的区别
运算符、成员函数
依然还是这段代码。在上文提到成员变量需要修饰符调整访问权限,对于函数来说也是一样的,不多做赘述。
class Pet
{
// 成员变量
public string name = "狗";
public int age = 1;
public int GetAge() // 成员函数
{
return age;
}
public double testAge() // 成员函数
{
return age * 5; // 使用运算符
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
}
在代码中可以看到这样的用法:
age * 5
这里就用到了运算符乘号。运算符就是一种告诉编译器执行特定的数学或逻辑操作的符号。由于以下链接中有十分详细的说明和演示,在这里就不再做复制粘贴,建议您去以下文章了解所有运算符。
C# 运算符
对于成员函数,在其中就可以实现对成员变量或者局部变量进行操作。作为类的一个成员,它能在类的任何对象上操作,且能访问该对象的类的所有成员。不过在这里需要考虑是否要返回数据。如下代码:
public int GetAge() // 成员函数
{
return age;
}
public double testAge() // 成员函数
{
return age * 5; // 使用运算符
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
在成员函数上,不仅有修饰符 public,还有个返回的“数据类型”。在这里的3个分别为 int、double、void。它代表着 GetAge 会返回一个 int 类型的值,testAge 会返回一个 double 类型的值。而在这里的 void 它显然不是一个数据类型,它意味着 SetAge 不会有返回值。
需要注意的是:
(1)错误代码:
public testAge()
{
age * 5; // 使用运算符
}
只要是函数,那么就必须要注明返回类型,否则报错。
![]()
有返回数据就标明指定的返回数据类型(无返回就是 void),且在方法中必须使用 return 返回这个指定数据类型的值(隐形类型转换除外)。否则报错。
![]()
同理地,如果标注了为 void,那么写了 return 也会报错。
public void SetAge(int age){
this.age = age;
return 32;
}
![]()
(2)如果方法有入参,那么入参必须要标注数据类型,否则报错。
public void SetAge(age)
{
this.age = age;
}
![]()
(3)在使用方法的时候,我们可以看到有的 age 没有加 this,有的方法中又加了 this。比如,我们想操作的数据是类中的成员变量,那么可以用 this 标识出来。当没有重名问题时,this 是可以省略的,它会默认使用同名的成员变量。如下所示:
public double testAge() // 成员函数
{
return age * 5; // 使用运算符
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
而必须表明 this 的情况就是像 SetAge 这样,出现了同名的情况。此时如果不标注 this,那么在方法中就不知道什么时候使用成员变量,什么时候使用入参,此时就可以用 this 做区分。比如以下代码,因为没用this,所以方法里以为是对入参的操作,所以就不会调整到成员变量:
public void SetAge(int age){
age = age;
}

为了避免问题,建议使用成员变量时,都使用 this.成员变量,而不是省略 this。
方法
方法就是把很多语句组织在一起,从而去实现某个功能,就比如上面的成员函数:
using System;
namespace AnimalTest
{
class Pet
{
public int age = 1;
public int GetAge() // 成员函数
{
return age;
}
public void SetAge(int age) // 成员函数
{
this.age = age;
}
}
class Program
{
static void Main(string[] args)
{
Pet pet = new Pet(); // 类的实例化:生成一个对象
pet.SetAge(3);
Console.WriteLine("Main调用GetAge: {0}", pet.GetAge());
}
}
}
参照成员函数,我们可以知道一个方法必须要有:修饰符、返回类型、函数(方法)名称、参数列表和方法主体。我们也可以把方法放在主类里,比如:
using System;
namespace Test
{
class Program
{
public int addNum(int num1, int num2)
{
return num1 + num2;
}
static void Main(string[] args)
{
Program test = new Program();
int num1 = 1;
int num2 = 2;
int result = test.addNum(num1, num2);
Console.WriteLine("result 的值: {0}", result);
Console.ReadLine();
}
}
}
输出结果:
result 的值: 3
而在使用方法的时候需要特别注意传参,这主要是因为传参会因为值类型和引用类型的区别而导致差异,它们的的使用区别在上文中已经有过详细说明。在这里简单再说一下就是:值类型变量存储的就是这个值,但是引用类型变量存储的是它的内存地址。
在这里首先先确定一下其他概念。比如在上例中:
test.addNum(num1, num2);
这里传给 addNum 的 num1 和 num2 是两个实参,且此时传递的是值类型数据。
而 addNum 的参数列表中拿到的 num1 和 num2 是两个形参。在方法中,你不仅能拿到实参传递过来的值,其实也能对它进行修改。
public int addNum(int num1, int num2)
{
return num1 + num2;
}
也就是说,如果实参传递的是值类型数据,那么对形参进行修改,肯定不会影响到实参:
using System;
namespace Test
{
class Program
{
public int addNum(int num1, int num2)
{
num1 = 5;
num2 = 6;
return num1 + num2;
}
static void Main(string[] args)
{
Program test = new Program();
int num1 = 1;
int num2 = 2;
int result = test.addNum(num1, num2);
Console.WriteLine("result 的值: {0}", result);
Console.WriteLine("num1 的值: {0}", num1);
Console.WriteLine("num2 的值: {0}", num2);
Console.ReadLine();
}
}
}
输出结果:
result 的值: 11
num1 的值: 1
num2 的值: 2
但是,如果实参传递的是引用数据类型,那么会因为传递的是个内存地址,导致当你对形参进行修改,实参也会进行修改:
using System;
namespace Test
{
class Program
{
public int addNum(int[] list)
{
int result = 0;
list[0] = 5;
list[1] = 6;
foreach(int num in list)
{
result += num;
}
return result;
}
static void Main(string[] args)
{
Program test = new Program();
int[] list = new int[] { 1, 2 };
int result = test.addNum(list);
Console.WriteLine("result 的值: {0}", result);
Console.WriteLine("list[0] 的值: {0}", list[0]);
Console.WriteLine("list[1] 的值: {0}", list[1]);
Console.ReadLine();
}
}
}
输出结果:
result 的值: 11
list[0] 的值: 5
list[1] 的值: 6
所以平常在使用时,一定要注意传参的值的类型。
最后再说明方法的另一个用法。比如之前可能会做这样的操作:
using System;
namespace Test
{
class Program
{
public int addNum(int num)
{
// 其他复杂计算操作
num = 10;
return num;
}
static void Main(string[] args)
{
Program test = new Program();
int num = 5;
num = test.addNum(num);
Console.WriteLine("num 的值: {0}", result);
Console.ReadLine();
}
}
}
为了避免 Main 方法代码量过多,同时也能够实现功能代码复用,把对值要做的操作封装成 addNum 方法,再把通过计算得到的值返回并赋值给 num。
而这个操作其实还能化简成这样:
using System;
namespace Test
{
class Program
{
public void addNum(out int num)
{
// 其他复杂计算操作
num = 10;
}
static void Main(string[] args)
{
Program test = new Program();
int num = 5;
test.addNum(out num);
Console.WriteLine("num 的值: {0}", num);
Console.ReadLine();
}
}
}
也就是使用 out,把对形参做的操作,最后赋值给传递的实参。而这个形参也被称作输出参数。这样就稍微简化了一些。
我们利用输出参数,还可以做这样的操作:
【代码选自菜鸟教程】
using System;
namespace Test
{
class Program
{
public void getValues(out int x, out int y)
{
Console.WriteLine("请输入第一个值: ");
x = Convert.ToInt32(Console.ReadLine());
Console.WriteLine("请输入第二个值: ");
y = Convert.ToInt32(Console.ReadLine());
}
static void Main(string[] args)
{
Program test = new Program();
int a, b;
test.getValues(out a, out b);
Console.WriteLine("在方法调用之后,a 的值: {0}", a);
Console.WriteLine("在方法调用之后,b 的值: {0}", b);
Console.ReadLine();
}
}
}
输出结果:
请输入第一个值:
1
请输入第二个值:
2
在方法调用之后,a 的值: 1
在方法调用之后,b 的值: 2
构造函数、析构函数、静态成员
看一段完整代码:
using System;
namespace AnimalTest
{
public static class GlobalVarAndFunc
{
public static string testString = "abc";
public static int Add(int a, int b)
{
return a + b;
}
}
class Pet
{
public string name = "狗";
public Pet()
{
Console.WriteLine("对象已创建 - 无参构造函数");
}
public Pet(string name)
{
this.name = name;
Console.WriteLine("对象已创建 - 有参构造函数");
}
~Pet() //析构函数
{
Console.WriteLine("对象已删除");
}
}
class Program
{
static void Main(string[] args)
{
Pet pet = new Pet();
Console.WriteLine("第一个pet {0}", pet.name);
Pet pet2 = new Pet("猫"); // 可以利用构造函数
Console.WriteLine("第二个pet {0}", pet2.name);
}
}
}
输出结果:

先说构造函数和析构函数。
类的 构造函数 是类的一个特殊的成员函数,当创建类的新对象时自动执行,就如上例一样。构造函数的名称与类的名称完全相同,它没有任何返回类型。
需要注意的是:其实就算不手动创建,C# 也会默认创建一个无参构造函数,所以无参构造函数也被称为默认构造函数。也就是说如果不需要作初始化赋值处理,那其实构造函数就没必要写。那既然它会自动创建,那为什么还要手动创建?
如果类里没有构造函数,那么不传参数也不会报错,因为它自动创建了无参的构造函数。但是如果类里存在有参的构造函数,那么这个无参构造函数,如果不手动创建,它就不会被创建出来。也就是说,这时不传参数是会报错的。所以这也就是为什么,虽然我们创建了有参的构造函数习惯上还要创建无参的构造函数。
那需要注意的是:手动创建了有参构造函数,之后传递参数时就一定要严格对照。而这种出现了同名函数的情况也被称作函数的重载。同名函数只要形参不同,那么调用同名函数时,就会根据实参的不同来调用相应函数。也就是说,在上例中,如果传递参数,就会赋值给 name。如果不赋值,name 就会为默认值。
除此以外,析构函数必须要和类名同名,否则会报错。
![]()
如果感兴趣可以前往以下文章查看更多内容:
构造函数
析构函数
重载
重写
重载重写区别
重写覆盖区别
命名规则和书写规范
我们已经知道了很基础的使用方法,可以自己进行命名。但是对它的命名也是有一些规则的。在之后将不再说明。
最常规的命名方法有两种,一种是 Pascal 命名法(帕斯卡命名法),另一种是 Camel 命名法(驼峰命名法)。
Pascal 命名法是指每个单词的首字母大写;
Camel 命名法是指第一个单词小写,从第二个单词开始每个单词的首字母大写。
而我们在具体使用时,通常需要根据项目的规定来遵守。那如果我们自己写程序,您可以像下面这样,遵守这些很基本的命名规则(当然具体还是看个人习惯):
- 变量的命名规则
变量的命名规则遵循 Camel 命名法,并尽量使用能描述变量作用的英文单词。例如存放学生姓名的变量可以定义成 name 或者 studentName 等。另外,变量名字也不建议过长, 最好是 1 个单词,最多不超过 3 个单词。 - 常量的命名规则
为了与变量有所区分,通常将定义常量的单词的所有字母大写。例如定义求圆面积的 n 的值,可以将其定义成一个常量以保证在整个程序中使用的值是统一的,直接定义成 PI 即可。 - 类的命名规则
类的命名规则遵循 Pascal 命名法,即每个单词的首字母大写。例如定义一个存放学生信息的类,可以定义成 Student。 - 方法的命名规则
方法的命名遵循 Pascal 命名法,一般采用动词来命名。例如实现添加用户信息操作的方法,可以将其命名为 AddUser。
标识符是用来识别类、变量、函数或任何其它用户定义的项目。在 C# 中,类的命名必须遵循如下基本规则:
1、标识符必须以字母、下划线或 @ 开头,后面可以跟一系列的字母、数字( 0 - 9 )、下划线( _ )、@。
2、标识符中的第一个字符不能是数字。
3、标识符必须不包含任何嵌入的空格或符号,比如 ? - +! # % ^ & * ( ) [ ] { } . ; : " ' / \。
4、标识符不能是 C# 关键字。除非它们有一个 @ 前缀。 例如,@if 是有效的标识符,但 if 不是,因为 if 是关键字。
5、标识符必须区分大小写。大写字母和小写字母被认为是不同的字母。
6、不能与C#的类库名称相同。
关键字是 C# 编译器预定义的保留字。这些关键字不能用作标识符,但是,如果您想使用这些关键字作为标识符,可以在关键字前面加上 @ 字符作为前缀。
在 C# 中,有些关键字在代码的上下文中有特殊的意义,如 get 和 set,这些被称为上下文关键字。
下表列出了 C# 中的保留关键字(Reserved Keywords)和上下文关键字(Contextual Keywords):
【表格转自菜鸟教程】


由于在自己的工作和学习过程中,只查看某个大佬的教程或文章无法满足自己的学习需求和解决遇到的问题,所以自己在追赶大佬们步伐的基础上,又自己总结、整理、汇总了一些资料,方便自己理解和后续回顾,同时也希望给大家带来帮助,所以才写下该篇文章。在本文中,所有参考或引用大佬们文章内容的位置,都附上了原文章链接,您可以直接前往查阅观看。在原文章内容的基础上,若无任何补充内容,同时避免直接大段摘抄大佬们的文章,该情况下也只附上了原文章链接供大家学习。本文旨在总结归纳,并希望给大家提供帮助,未用作任何商用用途。文章内容如有错误之处,望各位大佬指出。如果涉及侵权行为,将会第一时间对文章进行删除。
个人博客主页
一个努力学习的程序猿
本文所在专栏: C# 专栏,欢迎大家前往查看更多内容
专栏内目前所有文章:
不定期持续更新中