论文分享 |Jumping Knowledge Networks
本周介绍一篇 ICML2018 上关于 graph learning 的文章《Representation Learning on Graphs with Jumping Knowledge Networks》。
本文想探讨的一个问题就是:虽然图卷积神经网络的计算方式能够适应不同结构的 graph,但是其固定的层级结构以及聚合邻居节点的信息传播方式会给不同邻域结构的节点表达带来比较大的偏差。在指出这个问题的同时,作者也提出自己的解决方法——jumping knowledge (JK) networks,JK 机制结合上图卷积模型,在各类实验上都取得了 state-of-art 的效果。
问题
《 Semi-supervised classification with graph convolutional networks》 一文的作者指出,GCN最好的效果是在模型仅有两层深的时候,层数再增多,效果反而下降。这是什么原因呢?本文作者画了下面这幅图来说明这个问题:

我们知道GCN的更新方式是每次都融合来自1阶邻居节点的信息,这样更新k次,就能融合进k-hop 的信息。但是在graph中,不同的节点会有不同的k-hop结构,看一个极端的情况,上图 a, b 中,以方块节点为中心的 4-hop 结构截然不同。
a中的节点本身处在dense core 中,所以更新4次后,基本能融合进整个graph的节点信息,如此则会引发 over-smooth 的问题:GCN中,每多一次卷积操作,节点的表达都更global,但是表达更平滑了,这样导致很多节点,特别是处于dense core一带的节点表达最后都没有什么区分性了,所以对于这样的节点我们不能使用太多的GCN层数;
b中的节点处在 bounded part中,即使更新4次,融合进的节点也寥寥无几,这样就会导致 less information 的问题,对于这样的节点我们希望增加GCN的层数,让其获得更充分的信息进行学习。如此,由于节点不同的邻域结构,GCN建模的时候,我们到底该怎样选取模型的层数呢?
解决方案
说到底,这个问题的本质是有的节点需要多一些local信息,有的需要多一些global信息。本文作者以 layer aggregation 的方式,使得节点最后的表达能够自适应地融合进不同层的信息,local or global?让模型自行学习。其方法如下图所示:

底层信息更加 local,高层信息更加 global,JK网络会将所有layer做一次融合操作得到最终的表达,具体融合的方式有 Concatenation、Max-pooling、 LSTM-attention 三种方式:
Concatenation:将各层表达拼接在一起,送入 linear 层分类;
Max-pooling:将各层表达聚到一起做一个 element-wise 的 max-pooling 操作,这个方式不会引入任何新的参数;
LSTM-attention:这是最复杂的一种聚合方式,为每一层学习一个 attention score
![]()
,同时

,这个score代表了各个层的重要系数。attention score 的学习是将各个层的表达依次送入一个双向LSTM,这样每个层都有一个前向表达
![]()
和后向表达
![]()
,然后将这两个表达拼接到一起送进一个 linear 层拟合出一个score,然后将这个score进行softmax 归一化操作就得到了 attention score
![]()
,最后对各层表达依据重要系数进行加权求和得到最终表达。
可以看到如果加入这个机制后,GCN就同时存在两种 aggregation 方式,横向的 neighbor aggregation 是学习结构信息,纵向的 layer aggregation 是让模型有选择性地学习结构信息。这样就再也不会存在GCN模型不能设置很深层数的问题了。
实验
与其他论文一样,本文也是在一下数据集上进行了实验:
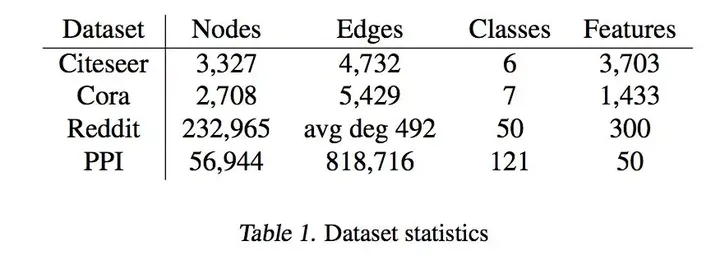
其中,Citeseer、Cora 是论文引用的两个数据集,依据词袋和论文之间的引用关系对论文进行分类。Reddit 是网络帖子数据集,依据词向量和帖子的发帖者关系对帖子进行分类。PPI是蛋白分子交互protein-protein interaction networks,对 protein functions 进行分类。

上图是在Citeseer 和 Cora 上的实验结果。相比传统GCN只能使用2-3层的结构,本文的方法可以使GCN加深到6层,并且效果也有提升。当然LSTM的聚合方式效果并不好,这是因为这两个数据集都比较小,复杂的聚合方式很容易过拟合。

一样在Reddit上有提升。
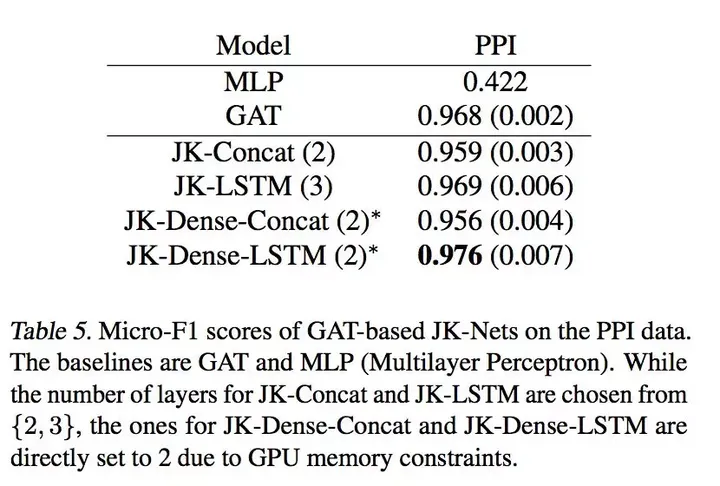
最后在PPI数据上的效果,由于PPI数据量大,所以LSTM这种复杂的聚合方式就发挥出了最好的效果。
结论
针对GCN的问题,其实我们自己在实验中的做法是对每层增加 auxiliary classifer 的机制进行解决, 而本文使用 layer aggregation 的方式,算得上是一种更加优雅的解决方式,值得我们后续实验验证。
论文连接:
http://proceedings.mlr.press/v80/xu18c/xu18c.pdfproceedings.mlr.press
更多内容,欢迎关注我们的微信公众号geetest_jy