链表-----单向链表详解
文章目录
- 链表的概念
-
- 链表有头和无头的区别
-
-
- 头结点
- 头指针
-
- 链表的不同结构
-
- 无头单向不循环链表
-
- 举例:链表的增删查改
- 无头单向循环链表
-
- 举例:单链表的带环问题
- 有头单向不循环链表
-
- 举例:链表分割
- 有头单向循环链表
-
- 举例:有头单向循环链表的增删查改
- 总结
链表的概念
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的;简单来说,线性表的链式存储结构生成的表,称作“链表”。
链表是由结点之间相互链接而成,结点由数据域和指针域构成,每个结点都是一个结构体类型的变量,各节点的指针域将每个结点链接起来形成了链表。

链表有头和无头的区别
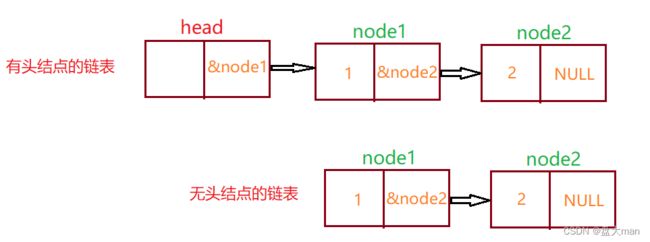
链表有头和无头,这个头指的是头结点,不是头指针。
头结点
头结点 是为了操作方便而设立的,放在第一个元素结点之前,其数据一般无意义(但也可以用来存放链表长度)。
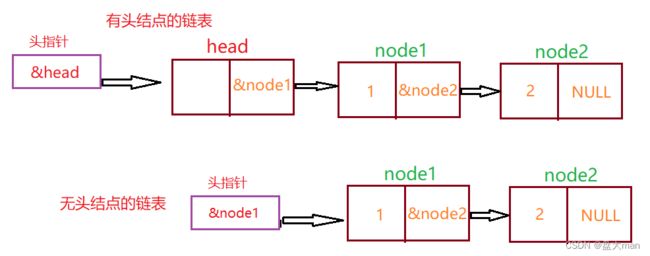
头指针
1.若链表无头,指向链表第一个结点的指针,若链表有头,则是指向头结点的指针。
2.无论链表是否为空,头指针均不为空;
3.头指针针是链表的必要元素
链表的不同结构
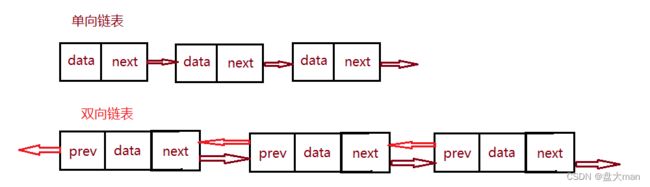
链表分为单向和双向,带头和不带头,循环和不循环,组合在一起可分为8种不同类型的结构。
单向和双向:
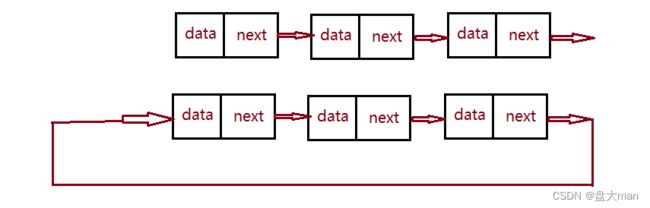
带头和不带头

循环和不循环
无头单向不循环链表

举例:链表的增删查改
创建和初始化链表
思路:先在头文件中定义一个包含数据域和指针域的结构体类型,再在测试文件中用它创建变量。
typedef struct SListnode
{
SLTdatatype data;//创建数据域
struct SListnode* next;//创建指针域,保存下一个节点的地址
//对结构体类型重命名后,不能用重新命名的名字对结构体进行自引用
}SLnode;
void test01()
{
//为一个结点分配内存空间
SLnode* n1 = (SLnode*)malloc(sizeof(SLnode));
//断言n1 的空间 防止n1开辟空间失败,返回空指针
assert(n1);
SLnode* n2 = (SLnode*)malloc(sizeof(SLnode));
assert(n2);
SLnode* n3 = (SLnode*)malloc(sizeof(SLnode));
assert(n3);
SLnode* n4 = (SLnode*)malloc(sizeof(SLnode));
assert(n4);
//给每个结点的数据域赋值
// -> 和 '.'的作用都是对结构体成员进行访问
// n1->data 等价于 (*n1).data
//n1 到n4 这些都是指的单个结点的地址(也就是指针变量)
n1->data = 1;
n2->data = 2;
n3->data = 3;
n4->data = 4;
//给每个结点的指针域赋值
n1->next = n2;
n2->next = n3;
n3->next = n4;
//n4为最后一个结点,在单链表中,最后一个结点赋NULL
n4->next = NULL;
增加结点
思路:增加结点分为头插,尾插,和在指定位置之前插入,头插需要改变头指针的指向,所以需要传头指针的地址, 形参的类型为二级指针类型。
注意:不在指定结点插入是因为需要再用一个指针来记录指定结点前一个结点,比较麻烦。偷懒
//尾插
void SListpushback(SLnode** head,SLTdatatype x)
{
SLnode* node = (SLnode*)malloc(sizeof(SLnode));
assert(node);
SLnode* tem = *head;
node->data = x;
//将插入的结点的指针域赋值NULL,这样新插入的结点就变成了尾结点了
node->next = NULL;
if (*head==NULL)
{
//判断头结点是否为NULL
//若不判断,当头结点为NULL时,不满足下面进入循环的条件,插入失败
//
//若为NULL,则直接将新创建的结点赋值给头结点
*head = node;
}
else
{
//尾结点的特征为 指针域的值为NULL
//所以 只要找到指针域为NULL的结点就是尾结点
while (tem->next != NULL)
{
tem = tem->next;
}
//将插入的结点的地址赋值给尾结点的指针域
tem->next = node;
}
}
//头插
void SListpushfront(SLnode** head, SLTdatatype x)
{
SLnode* node = (SLnode*)malloc(sizeof(SLnode));
assert(node);
node->data = x;
node->next = *head;
*head = node;
//头插不需要判断头结点是否为NULL,因为最后头指针会移动到新的头结点上
}
//在pos位置之前插入
void SListpushpos(SLnode** head,SLnode*pos,SLTdatatype x)
{
assert(pos);
assert(head);
//创建新结点,数据域为x,指针域为NULL
SLnode* node = (SLnode*)malloc(sizeof(SLnode));
assert(node);
node->data = x;
node->next = NULL;
SLnode* tem = *head;
if (pos==*head)
{
//若pos是头结点,则是头插,直接调用头插函数
SListpushfront(head, x);
}
else
{ //遍历找到pos的前一个结点
while (tem->next!=pos)
{
tem = tem->next;
}
node->next = tem->next;
tem->next = node;
}
}
删除结点
思路:分为头删,尾删,删除指定结点的前一个结点,同样需要移动头指针,需传二级指针
//尾删
void SListdelback(SLnode** head)
{
assert(*head);
if ((*head)->next==NULL)
{ //只有一个结点
free(*head);
*head = NULL;
}
else
{ //有多个结点
SLnode* tempre = NULL;
SLnode* tem = *head;
while (tem->next != NULL)
{
tempre = tem;
tem = tem->next;
}
free(tem);
tempre->next = NULL;
}
}
//头删
void SListdelfront(SLnode** head)
{
assert(*head);
SLnode* delnode = (*head)->next;
free(*head);
*head = delnode;
}
//在pos位置之前删除
void SListdelpos(SLnode**head,SLnode* pos)
{
assert(pos);
assert(head);
SLnode* tem = *head;
SLnode* temprev = NULL;
if (pos==*head)
{ //若满足条件,则pos为头结点,头结点前面无结点,返回空
return;
}
else
{
while (tem->next!=pos)
{
temprev = tem;
tem = tem->next;
}
temprev->next = pos;
free(tem);
tem = NULL;
}
}
修改和查询结点,打印
思路:返回查询到的结点,然后修改。根据单链表尾结点的next为NULL的特点,遍历输出。
//查找
SLnode* SListfind(SLnode* head,SLTdatatype x)
{
while (head)
{
if (head->data==x)
{
return head;
}
head = head->next;
}
return NULL;
}
//修改
void test()
{
SLnode* pos2 = SListfind(n1, 3);
if (pos2)
{
pos2->data = 9;
}
}
//打印
void SLprint(SLnode* head)
{
assert(head);
SLnode* cur = head;
while (cur!=NULL)
{
//输出当前指针cur指向的结点的数据域
printf("%d", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
无头单向循环链表
概念:单链表尾结点的next不指向NULL,而是指向第一个结点或者链表中的其他结点。
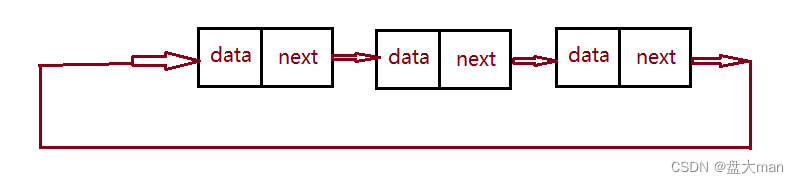
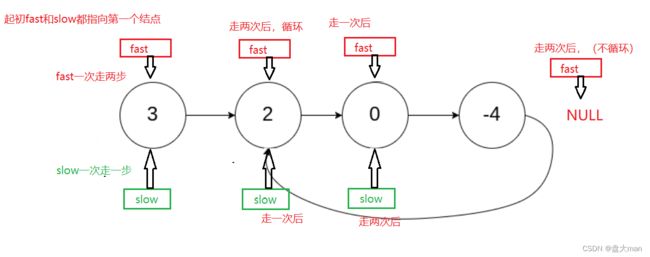
举例:单链表的带环问题
https://leetcode.cn/problems/linked-list-cycle/
bool hasCycle(struct ListNode *head) {
//思路:快慢指针,若是快指针为NULL,则不带环
//快指针一次走两步,慢指针一次走一步
//若快指针等于慢指针,说明带环
if(head==NULL)
return false;
struct ListNode*slow,*fast;
slow=fast=head;
while(fast&&fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(fast==slow)
return true;
}
return false;
}
图解:
延申:环形链表||
有头单向不循环链表
概念:存在头结点head的链表,head中不存储数据,但存储第一个结点的地址。

举例:链表分割
例题:链表分割
class Partition {
public://这道题没有c的环境,只能在c++环境中写
//由于函数的形参为一级指针,采用无头做法会很麻烦,所以自己定义一个头结点
ListNode* partition(ListNode* pHead, int x) {
//思路:将比x小的放在一个链表,比x大或等于x的放在另外一个链表
//然后再将两个链表链接起来
//最后,将链接起来的链表的尾结点的next置为NULL;
struct ListNode*lesshead,*lesstail,*greathead,*greattail,*cur;
cur=pHead;
//为小于x的结点定义lesshead为头结点,然后在头结点后面尾插就行了
lesshead=lesstail=(struct ListNode*)malloc(sizeof(strugreact ListNode));
lesstail->next=NULL;
//为大于x的结点定义greahead为头结点,然后在头结点后面尾插就行了
greathead=greattail=(struct ListNode*)malloc(sizeof(struct ListNode));
greattail->next=NULL;
//遍历比大小,根据不同条件,尾插到各自的头结点后面
while(cur)
{
if (cur->val<x) {
lesstail->next=cur;
lesstail=lesstail->next;
}
else {
greattail->next=cur;
greattail=greattail->next;
}
cur=cur->next;
}
lesstail->next=greathead->next;
struct ListNode* newhead=lesshead->next;
greattail->next=NULL;
//最后记得释放定义的头结点,这里可以不用置为NULL,
//函数调用完后会自动lesshead和greathead会自动销毁
free(lesshead);
free(greathead);
return newhead;
}
};
有头单向循环链表
概念:存在头结点head,且尾结点的next指向头结点或者其他结点。
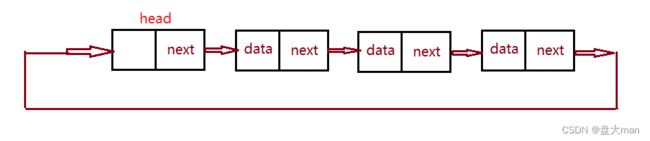
举例:有头单向循环链表的增删查改
void test()
{
//创建头结点
DList* phead = (DList*)malloc(sizeof(DList));
assert(phead);
//循环链表的尾结点指向头结点,这里只有一个头结点,头节点的next就要指向自己
phead->next = phead;
//插入--尾插
DList* newnode = (DList*)malloc(sizeof(DList));
assert(newnode);
newnode->data = 5;
//新结点的next指向头节点,头结点的next指向新结点
newnode->next=phead;
phead->next=newnode;
//删除--尾删
DList*tail=phead;
assert(tail->next!=NULL)
//找到尾结点的前一个结点
while(tail->next->next!=phead)
tail=tail->next;
tail->next=phead;
//释放尾结点
free(tail->next->next);
//打印
DList*tail=phead;
//尾结点的下一个结点为phead,根据这一条件来终止循环
while(tail->next!=phead)
{
tail=tail->next;
printf("%d ",tail->data);
}
//这段代码可能有点问题,为实现这个场景直接写的
}
总结
玩单链表的时候一定要注意区分头指针和头结点,在链表的初阶学习时,老师可能会对第一个结点直接取地址传过去,在无头单链表中,头指针和第一个结点重名,这就导致了当时学链表的时候很疑惑为啥一会儿传第一个结点的地址,一会儿传第一个结点的地址的地址。