OpenGL-面试
试描述现代OpenGL渲染管线。
- 首先输入的模型顶点数据会进入vertex shader
tess shader,gemtry shader 会对顶点坐标进行图元装配 将顶点着色器的所有顶点装配成指定图元的样子 图元装配给我的感觉更像是只要是决定顶点的顺序和组合数量 再
模型变换 就是左乘上model矩阵 将顶点移动到目标的位置
视口变换 就是再左乘视口矩阵 将顶点推到相对于假想中摄像机的位置 例如摄像机的位置是0 -1 0的位置 而顶点世界坐标是 0 0 0 那么乘上这个坐标变换的逆矩阵 会将物体推到0 1 0的位置这样就会 如果所有对摄像机的移动实际上都是对顶点坐标的你逆向移动
投影变换 坐标左乘上投影矩阵 要么是正射投影 要么是透视投影 对于透视矩阵吧 形象点的理解 就是通过他创建的那个视景体的参数 将所有坐标都按比例进行压缩进行一个压缩 直观点就是离近平面越远的压的越厉害 然后再将压缩的顶点都规范化到一个-1,1的立方体里 前面可以看做透视转成正射的情况 后面可以看做是做一个正射投影
从下面开始就是不在我们代码掌控的范围内 我们传顶点给gl_Position之后发生的事情
做完上面一步所有顶点是在一个齐次裁剪空间里 应该是cvv空间 这个时候就很方便进行裁剪 也就是如果不在-1,1这个立方体空间内的都裁剪掉 他裁剪主要还是就是去计算交点 然后生成新的三角形或者相应图元 如果是整个剔除就会导致模型残缺
裁剪完成之后就通过齐次除法 就是/w降维度 到NDS标准设备坐标空间 这个空间是主要是方便转化为屏幕坐标
最后就根据NDC坐标 将3维的点就被映射在了屏幕上
然后进行光栅化,将图元映射为屏幕上相应的像素,(屏幕上就是一个个的像素格 而光栅化只是将图元映射为相应的像素 也就是告诉opengl哪些像素格需要被绘制 然后这些像素格会有相应的像素信息 这个时候应该也会做相应的插值操作 比如我们在(1,0)设置颜色为(1,0,0) 在(2,0)设置的颜色是(0,1,0) 我们知道这个都是从顶点着色器那边通过out vec3 color这样传过来的 看起来我们是在片元着色器中直接使用了这个变量 但是实际上是在光栅化时发送了改变 进行了差值)
如果在片元着色器中没有进行混溶 透明或者discard 深度值的改变 则会在光栅化之后进行深度测试和模板测试 这是early-z 如果不是early-z则是在片元着色器之后 将数据写入颜色纹理附件之前进行
生成fragment给片段着色器使用,这一步还会裁减掉视图以外的像素 OpenGL中的一个片段是OpenGL渲染一个像素所需的所有数据 - 第五阶段在fragment shader中,计算每个像素的着色信息,包括光照、阴影、光的颜色等 生成最终的颜色 alpha测试和混合也是在这个阶段完成
遮挡剔除怎么做.
最简单就是面剔除 如果所有面环绕方式都是顺时针绘制 则剔除那些从视角看过去逆时针的 或者 z_buffer 判断像素深度值 或者用画家算法 如果这个物体A的全部顶点都在另一个物体B之前就先画B再画A
沃诺克算法
分治 不断的将屏幕细分 直到屏幕能出现画家算法满足的条件 就是空间只存在简单的前后关系 或者只有像素点那么大
深度测试,模板测试。
深度测试就是将每个片段的深度值都和深度缓冲中的内容做对比 如果通过(也就是小于这个内容)深度缓冲就更新这个深度值 一般深度测试是在片元着色器之前 减少有些片远没必要的渲染
怎么优化drawCall
drawCall是CPU调用图形接口 也就是CPU调用opengl 为了CPU和GPU可以并行工作 需要一个命令缓冲区 CPU向里面添加命令 GPU从里面读取数据 这样很影响帧率 每次调用drawcall CPU都需要向GPU发送很多数据 例如顶点什么的 所以我们就建立缓冲区存储这些数据 只调用少次数drawcall 一次发送大量数据过去 GPU需要绘制的时候从里面取就行了
解决方法是批处理
动态合批,静态合批
Batch是啥?
引擎每帧提交的Batch数量就是衡量渲染压力的指标
Batch就是调用一次API的绘制接口向GPU提交相同渲染状态的一定数量的三角形的行为
接口:OpenGL的glDrawArrays/glDrawElements 应该是glDrawArrays这些函数的出现次数
Batch等于一堆打包后的Draw call
如何做到静态合批
就是先获取要合批的这些模型对象的VBO EBO
将这些数据都转换到世界坐标系中
重新用个更大的VBO EBO去包含他们
记录每一个子模型的EBO数据在构建大的EBO的起始以及结束位置
静态合批就是将静态物体不会动的 获取他们的顶点缓存和索引缓存 将他们变换到世界坐标系中合成一个更大的顶点缓存 索引缓存 但是会增大内存消耗 因为这些新合成的顶点缓存和索引缓存都将占用额外内存
动态合批就是将会动的 可以平移旋转的合批 仅支持900个顶点以内的物体 缩放不同的物体不能一起进行动态合批
动态合批是拿CPU给GPU降低压力
静态合批是拿内存给GPU降低压力
骨骼动画原理,mesh有什么要求.
骨架
具有层次结构的关节和关节链组成 一个作为根关节 其他为根关节的子孙
OpenGL, VAO,VBO EBO 代表什么。
VAO是顶点数组对象 VBO是顶点缓冲对象 EBO是索引缓存对象
VBO就是显存中的一个存储区域,可以保持大量的顶点属性信息 比如坐标 法线 颜色 纹理坐标等。并且可以开辟很多个VBO,每个VBO在OpenGL中有它的唯一标识ID,这个ID对应着具体的VBO的显存地址,通过这个ID可以对特定的VBO内的数据进行存取操作。
VAO 顶点数组对象
存储了顶点数据的格式 这个格式就例如 几个数据代表坐标 几个数据代表颜色等 就是告诉opengl怎么理解VBO中的这一堆数据 顶点数据所需的VBO对象的引用 也就是用哪块VBO 还要EBO的对象引用 用哪块EBO 这样就把以前繁琐的工作都集中处理 不需要每绘制一个对象都要调用全部再调用一次。
EBO
显存中的一块内存缓冲器 就是告诉opengl该怎么选择顶点坐标
shadowMap原理。
我觉得就是类似于将摄像机变换到光源的位置 以光源为视原点 进行深度测试
然后将通过测试的深度值存储在纹理中 这些纹理就是shadowMap 也就是在这个视角下能看见的片段 没有被遮挡裁剪的片段就是可以被照亮的 被裁剪了的不在纹理中的就是在阴影中的
然后就是点光源用透视投影矩阵 这个投影矩阵就因为他是非线性的深度值 他在近平面附近的精确值就会很大 我做拾取emmm忘了啥函数了 就是glReadPixels还是啥函数就是获取深度值的那个函数也发现 基本都是0.9xxx 离得特别近的时候就会降的特别快 所以就会导致大片的白色
view矩阵也是需要设置六个方向的矩阵数组
而且还要用几何着色器去生成多个纹理图。。。反正就麻烦很多
方向光用正射投影
然后这个纹理的大小也一般设置成1024 视口也要变到1024去 一般就这个吧 然后这个纹理的大小就会很容易产生锯齿问题
上面就制作完了一个depthmap
在绘制过程中就需要传入光空间的视图矩阵和投影矩阵 主要是方便在顶点着色器时获取到这个顶点在光空间的坐标 方便和depthmap中的深度值做比较
其实这几个都基本类似 什么延迟渲染 ssao的 都是将顶点转换为纹理坐标 然后和纹理坐标的值作比较
然后他出现的问题就是一个是超出视景体范围 本来是默认剔除了的 也就是他的纹理坐标值如果按那个远近平面那个除法就会大于1 就会默认为是照射不到的地方 但是这里就需要做更改 默认他是能着色到的地方 要不然这些地方就全是黑的 也就是该纹理的缠绕方式什么的 设置纹理坐标值如果大于1的话就为固定值
还有个就是上面那个锯齿问题 就需要通过PCF或者
还有一个就是需要进行正面剔除 防止自我遮挡 就是在第一次绘制(写depthmap)的时候需要将正面剔除
透明物体和不透明物体渲染顺序,什么时候关闭深度写入,关闭深度写入做了什么操作。
半透明的物体从远到进画; 不透明的物体从近到远画; 先画不透明物体, 再画透明物体 渲染透明物体时关闭 渲染不透明时开启
首先不透明物体为什么要从近到远画 因为避免不必要的纹理数据写入 如果从远到近因为开启了深度测试 所以先绘制远的他会被写入颜色和深度纹理附件中 因为此时无论是最开始绘制(最开始绘制纹理中都没有值 一定能通过深度测试) 而后面绘制 因为是从远的近 所以近的一定会覆盖住远的 就会导致每次都会覆盖掉上一次写入的遮挡的部分数据 这样会产生大量无意义绘制 而从近往远处绘制就可以避免这个问题
第二个是为什么要先画不透明的物体 因为先把不透明的物体绘制到颜色纹理附件中 这个时候颜色纹理附件中就会有值 此时再绘制半透明或者透明的物体 因为不开深度测试 他就会获取该透明位置的已经有的颜色纹理值 然后再和半透明或者透明片段的颜色数据进行计算得到最终的数据值 覆盖掉原来该位置的颜色纹理附件的值
第三个是为什么透明物体为什么从远到近画 因为关闭了深度测试 越后绘制的就越容易
关闭深度测试主要是防止透明的物体z-buffer在深度缓冲中替换掉不透明物体的深度值
不透明物体从远到近绘制主要是 因为关闭了深度测试 所以防止远处的物体后绘制覆盖近处的透明物体
但是其实按这样绘制还是有问题 就是在
图的数据怎么表示。
用邻接矩阵进行表示 表示有向图和无向图的区别主要就是 无向图是一个对称的邻接矩阵 而有向图不是

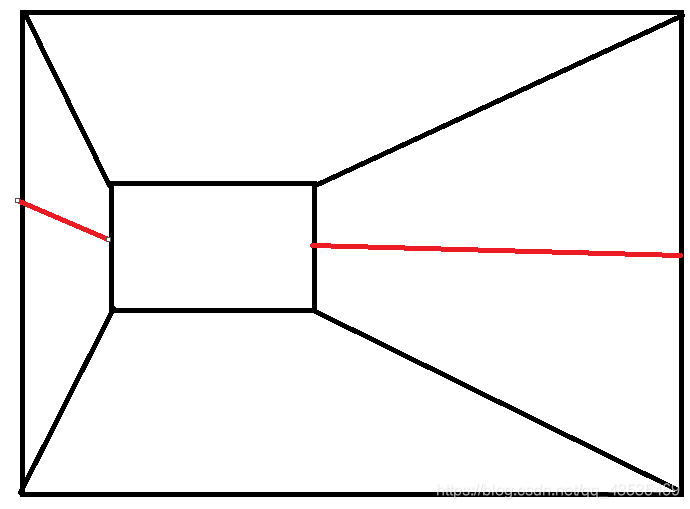
投影矩阵的理解
就是一个方形的视锥体里面的物体要被显示出来 而我们的相机就想象成在无限远的位置 这样视锥体点的z轴 远近平面之间的距离就可以接近忽略 所以就是主要区别就是物体的大小和摄像机的位置无关了 而正交矩阵要做的就是把物体移动到中心点的位置然后再将其映射到标准立方体中
18.关于透视投影
他要做的事情主要是
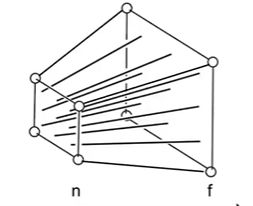
把n近平面后面的东西全部挤到n近平面上面去 理解起来就是把后面多的那部分往里面挤 挤成一个和近平面相同大小 这样就会导致越远的物体 被挤的就越明显 比如 我们就有一条不平行的线
我们通过把后面挤压一下 就会发现这条线平行了 就是这个道理
齐次坐标的作用
实现平移 主要是克服线性变换不能实现平移的问题 因为线性变换就类似于F(x) = Ax 从这个特点来看 原点无论如何变换都还是原点 所以没办法实现平移
还和后面的投影矩阵有关
旋转矩阵
写出二维旋转矩阵(最好也知道三维的旋转缩放平移矩阵,面试会问)
·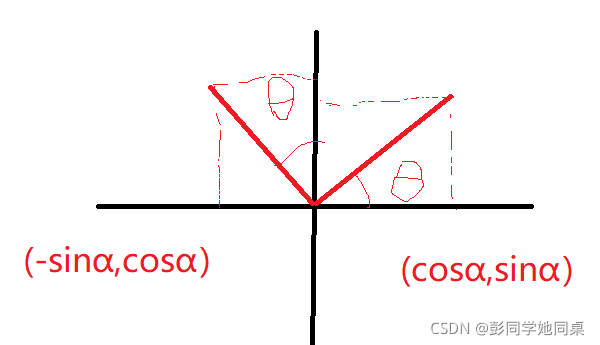
我们旋转的目的是将i帽和j帽变成图中这样 i帽变成(cosα,sinα) j帽变成(-sinα,cosα)
那么就是
矩阵 向量
a b × i
c d j
将i帽变成(a,c) j帽变成(b,d) 那就知道怎么填了
纹理的几种采样方式
一个是当出现被贴物体分辨率高于纹理图片分辨率时
也就是物体的像素多于纹理的纹素时 此时一个像素取值会为小数 那么他没办法确定去哪一个纹素 最简单的办法就是四舍五入 但是很明显容易产生锯齿 就是一块像素颜色都一样
那么优化的方法就是双线性差值 也就是去该像素周围的四个纹素 然后进行二维的线性差值 就是类似于重心坐标那种嘛 再优化点就是多取几个点吧
另一种情况就是被贴物体分辨率低于纹理图片 就很容易出现在透视投影的远处 也就是一个像素可能覆盖有多个纹素 这个时候就没办法去选择 就会产生摩尔纹 而解决办法最容易想到的就是多重采用 增加采样点 但是这样开销太大 所以可以采用mipmap
mipmap
缺点就是不准确 但是省空间 省时间 而且只能做方形的范围查询
mipmap就是通过原来的纹理图片建立一个金字塔 也就是每一层都是上一层的一半纹素 做了一个平均 然后我们使用mipmap是因为一个像素覆盖了多个纹素 那么我们就通过临近三个像素映射到纹理空间中范围 然后就可以在金字塔中找到相应适合的层数进行纹理映射 或者层面差值 但是他原理就是平均四个纹素 那么很明显就是只能对方形的范围进行查询 所以就衍生出了各向异性过滤 他也有缺点 就是开销是原来的三倍
编写shader要注意的
shader是GPU上运行的小程序 在opengl里面就是用glsl写的
所以GPU的特点是高度并行的 拥有更多的算术运算单元 更适合做连续同质的运算 GPU因为是SIMD的特性 也就是同一条运算指令 多个数据同时执行 所以会执行shader里面的所有if分支为了保证所有指令相同的数据并行处理 所以尽量在shader里面少写if语句
.gpu是以向量计算为基础设计的,也就是说在gpu上执行一个向量乘法和执行一个float的乘法的效率是一样的,
并不向cpu那样要多执行几次
Color Mask和Alpha Test相对昂贵 尽量别用
剔除
裁减算法主要包括:视域剔除、背面剔除、遮挡剔除和视口裁减等。
就是视域剔除不知道
点积和叉积的几何意义和代数形式
点积几何意义就是一个向量在另一个向量上投影的长度
代数意义应该是求夹角 a·b = |a||b|cos
他还有个几何意义就是可以将一个函数倒下来作为一个变换过程 降维度 将二维向量降到一维上
经常用来判断是否同向反向和垂直 0是垂直 负数反向 正数同向
叉积主要是用来计算法向量的吧 二维的叉积虽然结果是一个值 也就是所围平行四边形的面积 但是还是看做一个向量 因为他还是有正负区别
如何判断一个点是否在三角形内部
叉乘
例如点X(1,0,0)和三角形ABC 我们就连接XA,XB,XC分别和AB BC CA进行叉乘XA叉乘AB XB叉乘BC XC叉乘CA 这个向量方向不能反 如果全为正或者全为负 则表示在三角形内部
重心坐标
如果发现最终值加起来大于一就在外面
重心坐标法,ABC平面内任意一点可以用ABC坐标表示,O = αA + βB + γC, α + β + γ = 1;如果α、β、γ均大于零,说明O在ABC之内。
二维平面判断一个点在多边形的内部
好多方法吧 什么弧长法
射线法 就是向负无穷方向射一条线奇数就在内部 偶数在外部
SSAO的实现
屏幕环境光遮蔽
SSAO的实现和延迟渲染那边有点类似吧 应该说基于延迟渲染吧 他主要是通过在屏幕空间下逐像素的去计算遮蔽因子 也就是从这个片段的坐标随机生成前面半圆的随机点 然后和几何体进行比较深度值 越多在几何体前面 就说明这个片段的环境光应该越亮 这个深度值主要是在视空间的情况下 (也就是在几何阶段要多传一个没有左乘projection矩阵的坐标)
计算的 主要是还没具体实现过这个 所以我感觉他应该在几何渲染之后 光照渲染之前 (需要多一次渲染 主要是渲染到一个屏幕大小的长方形上 然后再这里进行判断) 同样是写到颜色附件中取 在几何渲染的时候也需要多存储一个视坐标(这个视坐标应该是以摄像机为视角的)的纹理 方便后面计算 下面就是在另一个阶段 上面这一小部分是几何渲染阶段
下面应该叫SSAO渲染
生成随机点就是通过uniform传入随机向量数组然后逐像素的和该像素的坐标相加
然后那个比较的问题 一个点肯定没办法和一个几何体去比较 然后网上说是什么连根线 求交点的也就是去计算这个随机点投影到近平面上求得xy 也就类似于练了一条线求交点了 也就是随机点最开始是视坐标 然后左乘projection 得到在齐次裁剪空间的坐标 然后再进行齐次除法 得到DNS空间的 然后再将这个坐标从-1 1转化到0 1也就是纹理坐标 就可以在视空间纹理中获取到几何体同直线在视空间下的坐标了 也就是z值获取到了 然后进行一个对比就行了 然后为了防止这个值差值过大就限制他在一定范围内就行了 比较就用step因为尽量不用if gpu的性质
优化好像就是用深度测试的数据计算就行了
Defer Rendering(延迟渲染)
前向渲染
前向渲染就是正常的 OpenGL默认的一种渲染方式 常规的渲染流水线
什么是延迟渲染
他与前向渲染最大的区别就是减少了大量关于光照的计算 增加了光照范围 忽略了未被光照影响的片元计算 虽然他在第一次绘制的时候 应该叫几何阶段吧 那个时候就实现了一个深度测试和模板测试 但是我觉得这个并不是重点 因为这个其实通过early-z也能实现
延迟渲染的过程
延迟渲染的过程:
几何阶段:
几何阶段的任务是创建一个帧缓冲 然后绑定多个颜色缓冲也就是gbuffer 存储一些需要的信息 比如说世界坐标 法线 还有些纹理 然后就顶点处理就按正常的处理吧 然后经过了一系列 什么坐标转化 光栅化 对数据也进行了插值什么的 就到了片元着色器 这里并不输出颜色值给flagColor 这个并不是一个真正的绘制 就是为了把这些要绘制的数据存起来 因为是从fs输出的嘛 我们也没有使用混合什么的 就已经经过了深度测试 绘制在纹理附件上的就是最终需要显示在屏幕上的片段 最后就使用 OpenGL 中的 Multiple Render Targets (MRT) 能力将不同的顶点属性一次性输出到不同的纹理中 这个阶段目的就是剔除掉没必要的片段 但是我觉得这个early-z也能做到 所以重点应该是下面这部分
光照阶段
遍历 G buffer 中的每一个像素,对不同的纹理进行采样以获得像素属性 然后我们就有了计算光照需要的数据了 但是这个并没有达到效果 我们要建个和光照能辐射到范围一样大的球体 模拟他们影响到的像素 然后通过模板测试就能知道哪些像素会受到影响 这样就可以防止像素和多个光源无效的计算
延迟渲染的缺点
不能使用混色的原因
因为在几何阶段就将完成了深度测试的像素存储了 这就导致在真正渲染的时候就只有一层了 也就是后面没有坐标点了 例如透明物体就没办法获取他后面的颜色
不能使用MSAA?错误的!
我们想想 使用MSAA要什么条件
第一是他需要一个三角形或者一个图元吧 需要采样 但是这个时候获取的直接就是颜色缓冲 一张纹理了 完全没办法进行采样 感觉就是 缺失了顶点信息了 什么插值那些都做不了了 因为第二次绘制的时候顶点除了坐标信息 其他信息都没了
解决办法
在渲染BaseColor纹理的过程中执行MSAA,即可达到抗锯齿的效果。
MRT要求对每个RT使用相同的Sample,所以我们是没法对BaseColor开小灶的,要么多花一个Pass先画BaseColor再画其他,要么对其他RT也进行多倍采样。对于前者,新增Pass又再一次增大了性能消耗,而后者会对深度和法线进行插值,显然也不可行,除非自定义最后插值的过程。这样一通操作下来,还是消耗了数倍的带宽(不过GBuffer没有变大哦),并且除了BaseColor以外其他RT做的计算全部木大。这样权衡下来,还不如直接上SSAA算了,至少后者效果更好。
事实上现在大家确实是这么做的,TAA等后处理抗锯齿加SSAA的组合成为主流,MSAA的身影反而几乎看不到了。
shadowmap怎么实现的 PCF
PCF主要就是对像素映射到depthmap纹素中对周围的纹素进行多采样取平均值 最大的影响就是对阴影边缘部分进行了模糊
如何确认用哪一层mipmap
在opengl里面就是直接生成mipmap 不需要自己去写 好像是glGenmipmap什么的 然后设置一下就可以用了 然后原理的话
对象池
如何优化内存,实际开发过程中用过什么优化内存的方法
如果有对象要频繁创建和删除,用什么减少开销。(对象池)
对象池的大小通常如何决定
B样条 贝赛尔曲线
如果说他是怎么实现的 就是具体点说就是类似于中心坐标那种 所有控制点都有一个权值 然后两个点合成一个点 然后最后就是合成一个点
然后t从0到1然后就是多个点实现的一条线 然后面就是线形成面
emmm主要就是理解伯恩斯坦多项式 通过带入贝赛尔曲线的递推方程可以得到那个式子 然后发现他那个性质 也就是整个图形是和每一个点都有关系的 所以没办法实现局部移动 然后最开始是先通过多个三次贝塞尔曲线实现 然后 就看到有B样条曲线 但是发现挺难实现的 就打算自己个简单的 就是实现多个贝赛尔曲线的c1连续 就是导数相同 斜率相同的情况来实现分段控制 然后发现也很难 就是我动一个点 就会导致后面全部点都动了
一般是三次贝赛尔曲线 然后通过细分着色器实现
欧拉角 万向节死锁 四元数
关于欧拉角这个问题 他的主要问题就在于将三个角 偏航角 俯仰角和翻转角 其实就是三个轴的旋转吧 他存在一个矩阵乘积顺序问题 前面先乘的旋转矩阵会对后面的模型坐标系发生影响 优化一点的做法就是将翻转角放到中间 第二个乘 这样会尽量避免万向节死锁问题 但是其实还是会发生 然后我就最开始想用四元数 然后网上发现了一下理解不来 太难了 (其实我后面了解了一下 好像调库就行。。。)就用起来不难 但是那个时候我就想了个其他办法 既然会影响 我就每转一度都进行一下矩阵旋转 并不是将角度加起来最后按顺序乘 这样每一次旋转都会对坐标轴发送改变 然后把坐标轴显示出来 就能在操作上实现自己想要的旋转 但是代价就是drawcall。。。哈哈哈计算次数太多 肯定是不可取的
如果对一个模型仅沿X轴缩放,应该如何利用model矩阵正确计算光照?
对法线乘上model的逆矩阵
阴影图的改进
A: 渲染较大场景的级联阴影图(CSM),把场景点云化的不完美阴影图(ISM), 渲染半球面空间的抛物面阴影图(PSM)。
光照渲染模型有哪些
主要是看pbr光照模型 不灵冯和冯的光照模型区别 也就是那个半程向量
冯光照模型
环境光
光线经过多次反射后已经无法得知其方向(可以看作来自所有方向)
漫反射
就是光线和该片段法线的夹角
当一束平行的入射光线射到粗糙的表面时,因面上凹凸不平,所以入射线虽然互相平行,由于各点的法线方向不一致,造成反射光线向不同的方向无规则地反射
镜面反射
就是反射向量和摄像机与片段的向量之间的夹角
一般指物体被光源直射的高亮区域,也可以成为镜面反射区,如金属
不灵冯
主要是观察的向量和反射向量角度大于90的时候会使镜面反射的突然消失 然后如果在光比较暗的情况下 这样突然消失就很明显
半程向量
入射光线与视线夹角一半方向上的一个单位向量。当半程向量与法线向量越接近时,镜面光分量就越大。 因为如果反射光线等于视线的时候 半程向量就正好和法线相同
抗锯齿
锯齿就是采样点不足出现的问题
高通滤波和低通滤波
高通滤波:将低频信息滤除,高频信息保留
低通滤波:将高频信息滤除,低频信息保留
应用:
高通:锐化边缘,提高对比度
低通:去除噪声,平滑边缘
三种样条我们为什么需要这么多种
有理样条
beta样条
有理样条
固定管线和可编程管线的区别和优势
固定管线主要是OpenGL3.3之前 应该是glut那个版本以前用过一段时间 他的绘制主要是glbegin和glend开始的 就很像一个机器吧 能做的就是摆动开关 然后大多数东西就像一个模具 通过函数可以直接构建一个例如二次曲面什么的 最多就修改一下参数 大多数东西都是写好了的 更像一个黑盒
而可编程管线就是将里面的细节都变成可以操控的了 但是带来的影响就是上手难度增大了很多 整个渲染也变得复杂了起来 以前只需要调整参数 例如以前画个球 直接调函数就行了 最大的感触就是坐标转换吧 以前一个函数就能将屏幕坐标转换到世界坐标 现在需要自己去实现 优势就是上限变高了
这个可编程主要是对着色器编程 而着色器就是运行在GPU上的小程序
三种差值类型
拉格朗日插值、分段线性插值与三次样条插值
为什么矩阵用4*4而不用3*3
主要是添加了齐次坐标 防止平移和其他的线性变换分隔开 旧如故不加到4*4每次平移都需要额外进行一次运算 线性变换里在原点的坐标一定不会发生改变
几何图形的显示表示和隐式表示
隐式表示:给你几何的关系 不给你具体的点 例如给球的式子 x2+y2+z2 = 1
显式表示:就是给你具体的点 直接可以用图元的方式表示出来
还有个CSG几何构造法 就是两个基础物体做布尔运算 就是用模板掩码来做 绘制两次 取共同覆盖的顶点坐标或者啥的
什么是走样(aliasing)?它产生的原因?列出两种走样表现(类型)
硬阴影和软阴影
点光源造成只有本影区的硬阴影
现实中的光毕竟本身有体积,例如灯泡 他实际上是有一个体积的 并不是一个点 所以他灯泡上下边界会产生出不同范围的阴影 会形成拥有半影区的软阴影
实现方法应该就是CSM
自碰撞
什么是粒子系统 列举两种应用
什么是分形几何 难点在哪
什么是自发光?什么是透射?
透射:当光入射到透明或半透明材料表面时,一部分被反射,一部分被吸收
自发光:给我的感觉就是他的亮度不会受到环境光源的影响 也就是他那里的像素颜色基本就不会改变 然后他也可以自己作为一个光源
凹凸贴图和高度贴图的区别
凹凸贴图存储的是高度差信息,8bit灰度图。
法线贴图存储的是法线信息,24bit彩色图。
2、凹凸贴图影响三角面的法线相对光影方向的偏移量(
越凹偏移量越大,计算出的颜色越暗,给人凹陷的感觉;
反之偏移量越小,颜色越亮,给人凸起的感觉)
法线贴图是直接记录三角面的法线相对光影方向的偏移量在x,y,z三个轴上的分量。
典型的用存储空间换运行时的计算时间策略。
总之,两种贴图最终达到的效果是一样的(都是影响渲染流水线中法线和入射光线的夹角),只是存储信息的方式不同
列举两种着色技术
如何渲染半透明物体?
A: BSDF,内表面散射。
模型矩阵问题
平移矩阵 * 旋转矩阵 * 缩放矩阵 * E
水是怎么实现的呢
(扭曲一下,半透明处理然后混合一下),怎么扭曲的呢(通过贴图信息uv变换了一下),有没有了解其他水是怎么实现的(看过知乎大佬的一篇技术文章),还有哪些实现呢(印象比较深的就是fft),fft咋实现的