字符串在C和C++中需要注意的问题
目录
前言
一、字符串长度问题
二、字符串与读写文件
首先给出两种语言分别写文件的基本操作:
C语言:
C++:
下面来到读文件的范畴:
C语言:
C++:
字符串与读写文件小结:
三、C语言风格字符串与内存分配
四、字符串和宽字符串之间的转换 (string <-->wstring)
总结
前言
我始终认为发文慢并不代表创作力低下,好的文章经得起推敲,能够给用到这类知识的朋友铺路,更能够引起像我一样遇到多次此类问题的朋友产生共鸣,当一个问题反复困扰你时,说明这个问题的价值越高,下面我将谈谈我所遇到的字符串方面相关当时困扰过我或者总结想来有价值的知识点,希望能帮到的不止自己,还有更多编程热爱者。
一、字符串长度问题
已知
另外提一句字符串头文件的异同:
是c++ 的头文件,其内包含了一个string类,string s1就是建立一个string类的对象
是旧的C 头文件,对应的是基于char*的字符串处理函数,c语言的东西并无类,所以不能 string s1
文件实际上只是在一个命名空间std中include了
由于字符串结尾都会增加'\0'作为结束标识符,但是strlen()函数(或者C++中的string类的.size函数)反映字符串真实长度并不会包含‘\0’字符
char s1[] = "jfsdhf";
string s2 = "jfsdhf";
cout <<"s1.size = " << strlen(s1) << endl;
cout << "s2.size = " << strlen(s2.c_str()) << endl;
cout << "s2.size() = " << s2.size() << endl; 运行结果:
下面调试观察s1、s2两字符串的具体组成:
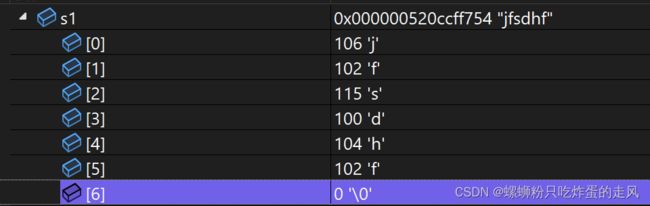
s1共占7个字符空间,但是大小为6表明并未包含'\0'字符格。

看起来好像没有'\0'作为字符串结尾,不要急接着打开监视中s2的原始视图:
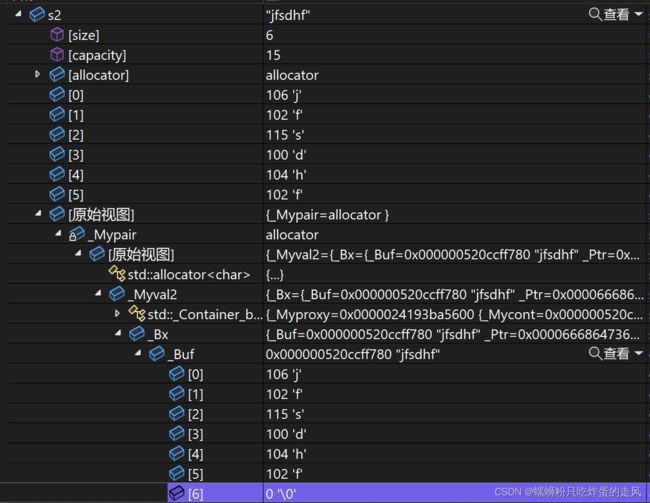
可以看出只是为了便于调试,vs将string类对象s2的监视呈现优化,隐藏了后序'\0'和后序自动扩容出额外空间用于初始化的'\0'。
上面的问题解决,那如果把char数组初始化方式变化所得字符串长度为多少呢?
char s1[] = "jfsdhf";
char s1_2[] = { 'j', 'f', 's', 'd', 'h', 'f' }
cout << "s1.size = " << strlen(s1) << endl;
cout << "s1_2.size = " << strlen(s1_2) << endl;运行结果:
这个结果属实离谱,再来调试看看:

有什么不同?发现s1_2即用第二种形式命名的字符串没有'\0'字符结尾。对没有‘\0’结尾的字符串求长度结果是随机值,原因是strlen()函数原理是检索到'\0'字符即为字符串结束,所以在对s1_2求长度时会在内存内部随机索引以找到'\0'才算结束。
由于C语言类型字符串没有像C++一样方便的重载==运算符用于字符串之间的相互比较,所以选择将s1和s1_2转换为C++的string类型进行比较:
char s1[] = "jfsdhf";
char s1_2[] = { 'j', 'f', 's', 'd', 'h', 'f','\0'};
string s11(s1);
string s12(s1_2);
if (s11 == s12) { cout << "same" << endl; } 运行结果:![]()
调试窗口: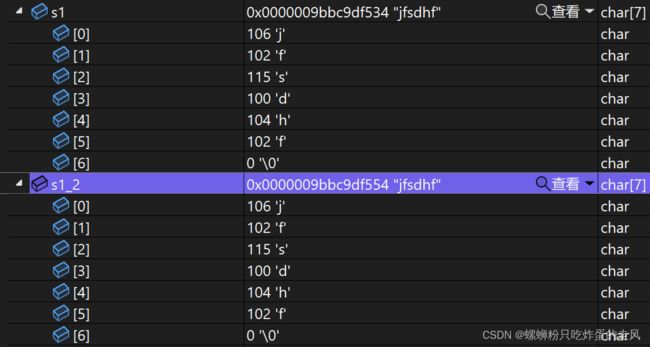
所以,这才真正看懂字符串大小的奥秘。
二、字符串与读写文件
常见的,当我们在读写txt文件时,有些时候必要地进行文件和控制台程序的交互,为了避免自己和后人反复踩坑,所以给出必要的基本格式以及雷点说明。
-
首先给出两种语言分别写文件的基本操作:
C语言:
void InFile_1()
{
//FILE* fpout = fopen("article.txt", "w"); // 清空重新写入(相当于C++中的ios::out)
FILE* fpout = fopen("article.txt", "a"); // fopen("文件名","a")可以实现追加写入 相当于C++中的ios::app
if (!fpout) { printf("wrong\n"); return; }
for (int i = 1; i <= 10; i++)
{
fprintf(fpout, "%d\t", i);
}
fprintf(fpout, "\n");
printf("输入成功\n");
fclose(fpout);
}C中是通过文件指针(FILE *fpin)和相应的库函数(fopen、close)来实现的,其中fopen也包含写操作文件的名称和文件操作方式(“r”)(另有”w“应用于清空重新写入)这两大参数。
C++:
void InFile_2()
{
ofstream ofs;
//ofs.open("article.txt", ios::out); // ios::out会隐式调用ios::trunc清空文件
ofs.open("article.txt", ios::out | ios::app); // ios::app可实现追加写入操作
if (!ofs.is_open()) { cout << "wrong" << endl; return; }
for (int i = 10; i >= 1; i--)
{
ofs << i << '\t';
}
ofs << endl;
cout << "输入成功" << endl;
ofs.close();
}C++的操作是对对象的操作,因此首先应该创建写文件流的对象,即ofstream outfile,(其中ofstream是头文件fstream中的一个类),对对象outfile的初始化主要包括:写操作文件的名称(如article.txt)和文件操作的方式(ios::out表示清空写)
需要补充的是:
① 无论读文件还是写文件C++都是通过创建对象,对象调用成员函数实现的;而C则是通过文件指针,对库函数的调用实现的。
② 注意两种语言都要对操作后的对象(或指针)进行判断,若为空,则退出,以此来保证程序的有效执行。判空操作在C语言中通过对文件操作指针判空来判断文件是否成功打开,C++中则是调用流对象的类内file.is_open()函数来实现。
-
下面来到读文件的范畴:
首先请看已有包含在工程中的txt文件:

(请特别注意,上面文件内容最后还有个换行符,正如所见第三行亮起的光标)
接下来我首先用C语言给出读文件的基本操作样式(逐字符):
C语言:
void InFile_1()
{
FILE* fpin = fopen("article.txt", "r"); // "r"表示将文件以读文件形式打开
if(!fpin){ printf("wrong\n"); return; } // 判断文件是否成功打开
char c;
while(!feof(fpin)) // 循环逐字符读取直到文件结尾
{
fscanf(fpin, "%c", &c); // 将读到的单个字符赋值给c
printf("%c", c);
}
/*while (!feof(fpin))
{
c = fgetc(fpin); // 同样的逐字符读取 然后将值赋给字符c
printf("%c", c);
}*/
fclose(fpin); // 切记有始有终最后关闭文件
}试着调试运行:

第一眼没问题,细看不是为啥下面空那么大块,谁家一次换行以后下一排空这么大,于是寻思总不能给我整出来两次换行吧,猜对了,下面那个迷人的小白块就是意外输出的字符,接下来找出现这种多余换行符的原因:
找问题为了方便,选择取用了C++中便利的string对象来存储每次读取的字符,同时也是为了后续调试更可观,代码如下:
string s;
while(!feof(fpin))
{
fscanf(fpin, "%c", &c);
printf("%c", c);
s.push_back(c); // 将c用字符串串联保存
}调试窗口(上面正常的部分省略):
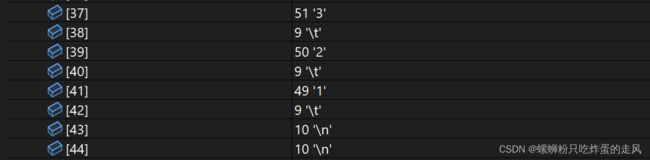
可以看出字符串大小为45,最后两次执行读取字符循环时确实都是'\n'换行符,为什么多出来的不是其他符号,恰恰是换行符呢? 通过查阅资料得知:
在Windows操作系统中,文本文件的换行符通常是由回车符(\r)和换行符(\n)组成 (\r\n)。而在Unix/Linux系统中,换行符通常只是一个换行符 (\n)。这两种系统的换行符表示方式不同。
同样地,C语言中按行读取只需要用fgets()库函数读取即可(注意其函数参数):
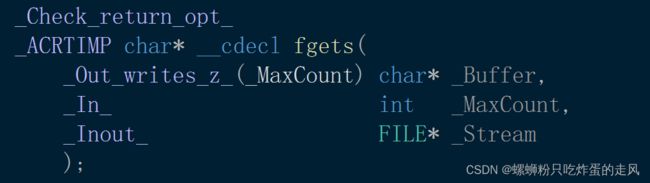
代码如下:
string s; // 用于保存所有字符
string temp_s; // 读取每行所有字符
while (!feof(fpin))
{
fgets(const_cast(temp_s.c_str()), MAXLEN, fpin); // 按行读取
s += temp_s;
printf("%s", temp_s.c_str());
} (以上为了方便用了部分C++的内容,当然纯C语言也是可以实现同样操作的,只是过于繁琐)
这里MAXLEN为宏定义,需要大于要读取文件中最大行的字符数,以保证行读取完整
运行和调试结果:

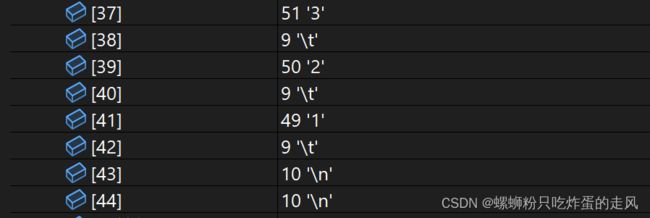
可以见得,使用按行读取方式仍然不能解决结尾多读换行符的问题,只是换种读取方式,减少循环执行次数,仅此而已。
接下来的读文件算法用C++语言给出:
C++:
- 方法一:
void InFile_2()
{
ifstream ifs;
ifs.open("article.txt", ios::in);
char c;
while((c = ifs.get())!=EOF)
{
cout << c;
}
ifs.close();
}以上算法使用流对象的类内函数ifs.get(),逐字符读取文件内容,出于探究原因,在上面代码基础上加上string变量实现对逐字符读取到的结果进行存储:
char c;
string s;
while((c = ifs.get())!=EOF)
{
cout << c;
s.push_back(c);
}观察字符串内容:
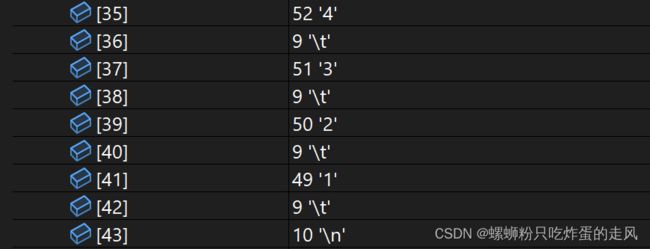
惊喜地发现同样的Windows系统同样的编译器,但是使用C++中流对象的get()类内函数时,没有出现读文件结尾误读成两个'\n'的情况,避免了因操作系统引起的错误可能对后续操作造成重大无厘头错误,所以ifs.get()函数实用性很高。
- 方法二:
string s;
string line_s;
while(getline(ifs,line_s))
{
s += line_s;
s += "\n";
}
cout << s;可能会疑问为什么字符串s已经对每行字符统计字符串line_s做了保存工作,另加的字符串形式换行符是为什么?原因是getline()作为string库函数,每次读文件读一行,但是结尾的'\n'换行符没有录入操作,所以想要正常读取包括换行符在内的文件内容,需要对每行读取后加一个'\n'实现原样读取。(值得注意的是,如果被读取文件最后一行没有换行符,需要对以上代码略作修改,使得读取最后一行时取消延续之前行的后加换行符操作)
(注意getline()函数为string库函数,所以使用前记得包含
- 方法三:
string s;
char line_s[1024] = {0};
while (ifs.getline(line_s, MAXLEN)) // MAXLEN为单行读取最大字符数
{
s += line_s;
s += "\n";
}
cout << s;该方法利用流对象的类内函数ifs.getline()对文件进行按行读取,需要注意函数的传入参数中需要char数组类型,既然是数组大小就需要提前定义,而且需要定义MAXLEN的值,对于单行特长的文档就不是那么友好了,定义小了可能存在读入不全;对于单行特短的文档在定义数组时声明空间过大造成空间浪费。总之个人不建议用这种方法,毕竟已经有更好更便捷的方法了。
- 方法四:
char buff[MAXWORDS]; // MAXWORDS表示经buff分离后可能存在的元素数
while(ifs>>buff)
{
// 每一次的buf是空格或回车键(即白色字符)分开的元素
cout << buff << ' '; // 方便观察用空格分开
}运行结果:
![]()
结果表明,利用流直接写入可以忽略所有空白字符(换行符、水平制表符、空格等),只输出非空字符,为文档内容筛选类问题提供了方便的对口解决方案,可以用于快速提取文档内容为密集字符串。
字符串与读写文件小结:
相似的操作往往不止一种方式可以实现,但是无论代码编写复杂度还是运行效率都各有千秋,作为历史悠久绵长的C/C++语言中流传至今的各个算法优劣程度取决于怎么使用、解决什么问题,例如正确的选择读文件操作算法可以帮我们免去很多麻烦,更快地达到目标。
三、C语言风格字符串与内存分配
在C语言中对字符串“abc”有两种定义方法,如下:
const char* c1 = "abc"; // 现在主流的编译器会强制要求给加const关键字修饰("abc"在常量区)
char c2[] = "abc";char *c1="abc"; s在栈区,“123”在常量区,其值不能被修改
char c2[]="abc"; s在栈区,“123”在栈区,其值可以被修改
四、字符串和宽字符串之间的转换 (string <-->wstring)
C++标准库中现C++20都没有提供现成的string和wstring类型互转的函数,现在网上很多代码都已过时,甚至编译都过不了,多数采用std::codecvt 类,但是 C++17 中,std::wstring_convert 已被弃用,并且 std::codecvt 类也已被弃用需要自行实现,话不多说代码如下:
std::string ws2s(const std::wstring& ws) // wstring转string
{
std::string curLocale = setlocale(LC_ALL, NULL); // curLocale = "C";
setlocale(LC_ALL, "chs");
const wchar_t* _Source = ws.c_str();
size_t _Dsize = 2 * ws.size() + 1;
char *_Dest = new char[_Dsize];
memset(_Dest,0,_Dsize);
wcstombs(_Dest,_Source,_Dsize);
std::string result = _Dest;
delete []_Dest;
setlocale(LC_ALL, curLocale.c_str());
return result;
}std::wstring s2ws(const std::string& s) // string转wstring
{
setlocale(LC_ALL, "chs");
const char* _Source = s.c_str();
size_t _Dsize = s.size() + 1;
wchar_t *_Dest = new wchar_t[_Dsize];
wmemset(_Dest, 0, _Dsize);
mbstowcs(_Dest,_Source,_Dsize);
std::wstring result = _Dest;
delete []_Dest;
setlocale(LC_ALL, "C");
return result;
}通过以上代码我们便可以通过函数返回值方便地传回转换后的字符串或宽字符串,进而实现其他项目需求。
总结
以上就是对目前所想到的字符串类型问题剖析,以后有其他价值型的问题会再做后续填充,写出来不仅是为了自己查阅,同时为了帮助更多热爱C和C++语言的编程人员夯实基础、总结和自我提升,感谢您的观看,期待共同进步。