WOE编码与IV值
1.woe又叫证据权重,用来衡量对先验认识修正的增量
2.woe的实质是表示当前分箱中好坏客户的各自占总体好坏客户比例的差异
3.woe可以将非线性变量线性处理化,提高业务解释性
4.woe能消除异常值的影响,增加模型鲁棒性
5.小概率事件导致woe对比较不同变量预测能力失效
6.IV值实质来源于KL散度,衡量坏人与好人分布的差异
7.woe描述了预测变量与目标变量之间的关系;IV值衡量了这种关系的强度
woe也称证据权重(Weight of Evidence),这是评分卡里重要的特征转换方法。我们会循序渐进介绍它的来源、定义、优点和用处。
![]()
![]()
1.从贝叶斯理论到证据权重WOE
在金融风控中,我们尽可能希望发放的贷款能够全部收回来,也就是放贷的对象是好的。在没有任何信息的条件下,我们只能通过事先随机放贷,最后看看放贷的资产最后有多少人是逾期的(我们称之为坏人,Bad),有多少人是正常还款的(我们称之为好人,Good)。由此,我们可以得到关于好人坏人的先验认知:
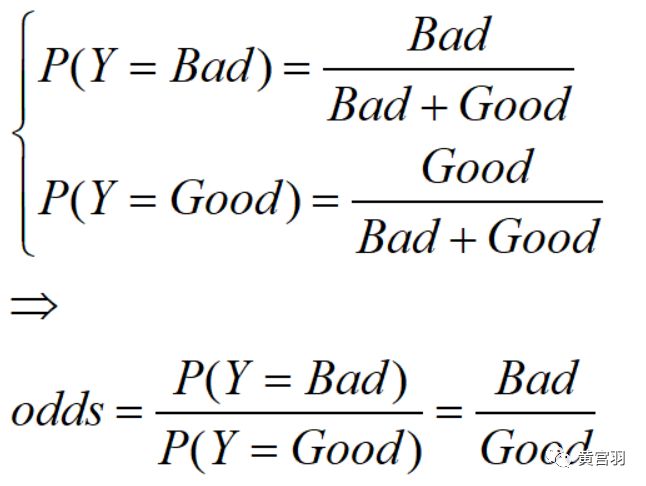
当odds小于1时,预测为好人概率更高,此时我们一般情况都是好人;反之若odds大于1,则当作为坏人。
但是,实际业务复杂多变,每个人很可能会因为别的因素而导致其资质发生改变。因此,我们通过搜集各种特征,希望通过分析把这些特征转化为证据,帮助我们提高辨别好人和坏人的能力。因此,贝叶斯思维就彰显了:观点随事实发生改变。当有新证据进来时,会更新对某件事的先验概率。
根据贝叶斯公式有:
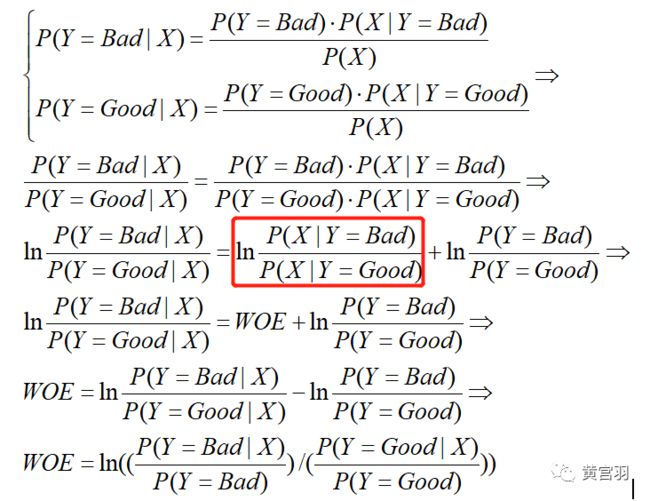
公式中的红色框部分表示,根据观测数据更新信息,也就是当有新证据进来,先验概率就更新为后验概率。
如果搜集到的数据与先验认知的差距不大,我们就认为这个数据中得到的证据价值不大,反之则认为带来的信息越多。因此,WOE用来衡量对先验认识修正的增量,这就是WOE被取名为“证据权重”的原因
![]()
![]()
2.WOE计算与优势
上一节我们知道了WOE的含义与表达式,可以看到,首先,构建WOE相当于一种监督学习方法,需要知道Bad和Good的标签;
其次,观察表达式,要有新的证据进来才能进行更新,这个新信息是关于自变量的,而一个自变量取值有时候会很不一样,有时候不同取值间可能带来的证据是一样的;有时候变量的缺失也是一种信息;此外,一些不稳定的Outlier点可能带来噪声。因此,为了增加自变量这种证据的可信度(预测能力),提高模型的鲁棒性,我们对这些变量做信息分类与规整——也就是分箱处理。
举一个例子,
比如研究年龄对还贷能力的影响,对不同年龄段进行如下分箱:
| Age |
Bad(Y=1) |
Good(Y=0) |
WOE |
| [18-25] |
2 | 200 |
-2.78 |
| [26-35] |
5 |
180 |
-1.75 |
| [36-45] |
15 | 123 |
-0.28 |
| [46-55] |
34 |
80 |
0.97 |
| [56-70] |
50 |
77 |
1.39 |
| All |
106 |
660 |
- |
注:数据随机捏造,如有雷同,纯属巧合
对于第一个年龄箱子【18-25】,代表年龄在18~25岁之间,于是我们计算得到该新证据对应的证据权重:
woe = ln((2/200)/(106/660))=-2.78
我们把上一节最后woe表达式改成为如下形式:

因此,WOE的实质是表示当前分箱中好坏客户的各自占总体好坏客户比例的差异;
当前分箱的比例小于样本整体比例时,WOE<0;当前分箱的比例大于整体比例时,WOE>0,当前分组的比例和整体比例相等时,WOE=0;woe越大,表明箱子的bad%越大,这种差异也就越大。
通过上面的分析,我们已经给出了woe编码的优势:
反应自变量的证据权重(对因变量的贡献度)
可以有效处理缺失值(可当一个箱子)
可以有效处理异常值(Outlier)
增强模型的鲁棒性
无需对变量进行独热编码
对非线性变量线性处理化,提高业务解释性
注:
1.实际中为了提高可解释性,一般要求woe呈单调趋势。
2.若某个分箱中没有响应样本或全部为响应样本(bad为0或good为0),woe是一个无穷值。可以用下面公式修正:
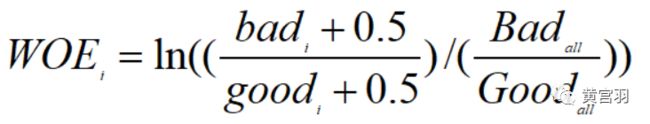
![]()
![]()
3.从证据权重(woe)到信息价值(IV)
计算woe只考虑落入每个箱子的好坏客户数,它描述的是同一变量下不同箱子与目标变量之间的关系;但我们还要比较不同变量之间对目标变量的关系大小,因此需要构造一个指标,来衡量特征与目标变量之间关系的强度。
一个自然而然的想法就是,把同一变量下所有箱子woe求和,然后比较不同变量的总WOE就可以了。但是这样会有一个问题,就是没有考虑箱子的权重。如果一个箱子发生的概率原本就很低,即使它的woe值很大,但我们知道它未来基本不可能发生,或者发生的概率很小,那么这样的变量对预测其实并没多大的意义。
举一个例子说明,对于特征F1和F2,都只有两种取值1和0,它们对同一目标变量响应如下:
| F1 |
Bad(Y=1) | Good(Y=0) | rate | woe |
| 1 | 90 | 10 |
0.1% |
4.394 |
| 0 |
9910 |
89990 |
99.9% |
-0.009 |
| All |
10000 |
90000 | - | - |
| F2 |
Bad(Y=1) | Good(Y=0) | rate | woe |
| 1 | 6000 |
600 |
6.6% |
4.500 |
| 0 |
4000 |
89400 |
93.4% |
-0.910 |
| All |
10000 |
90000 | - |
- |
注:rate表示落入该箱子的总客户数占总体客户数的比例
可以看到,
对于F1特征,WOE1 = 4.394 - 0.009 = 4.386;
对于F2特征,WOE2 = 4.500 - 0.910 =3.590
woe越大,代表好坏比例占总体比例的差异越大。F1比F2好,但是我们发现,F1特征的取值为1的箱子发生的概率太低了,这是一个小概率事件,很难保证未来的业务中也会出现这样的情况。因此,考虑模型适用性,F2比F1更适合。
出现这样的情况是因为没有考虑箱子出现的概率,只要我们考虑进去,就可以在woe基础上构造一个合适的指标。这就引出了本节的主人公:IV值(informaton value),也叫信息价值。

其实转化一下可以看出,这个就是KL散度(交叉熵-熵)的变形,回顾这篇文章:机器学习之模型评估(损失函数)
下面我们对IV值公式展开:

KL散度公式为:
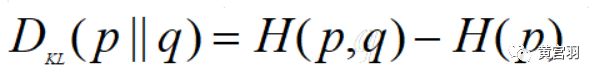
H(p,q)表示交叉熵,H(p)表示熵,KL散度衡量了两个分布的差异,差异越大,散度越大。
比较IV值公式的展开式与KL散度可以发现,IV值实际上是衡量好人与坏人分布差异。
利用上述公式我们再来计算上例的F1和F2特征的IV值,
| F1 |
woe |
IV |
| 1 |
4.394 |
0.0391 |
| 0 |
-0.009 |
0.0001 |
| 总计 |
4.386 |
0.0391 |
| F2 |
woe |
IV |
| 1 |
4.500 |
2.6699 |
| 0 |
-0.910 |
0.5397 |
| 总计 |
3.590 |
3.2096 |
因此,woe描述了预测变量与目标变量之间的关系;IV值衡量了这种关系的强度
附上业内IV值判断标准
| IV值范围 |
预测力 |
| 小于0.02 |
无预测力 |
| 0.02到0.1 | 弱 |
| 0.1到0.3 |
中等 |
| 大于0.3 |
强 |
利用python很容易完成上述指标编写:
def Calculate_IV(df,goal):
'''
:param df: 要进行计算iv值的数据集
:param goal: 目标变量,取值0和1
:return:所有变量的woe、iv值详情信息
'''
features = list(df.columns)
features.remove(goal) #把目标变量去掉,不参与变量的woe和iv计算
good,bad = df[goal].value_counts() #好坏标签,0代表好,1代表坏
Tab = pd.DataFrame() #接收每个变量的计算结果
for feature in features:
dataset = df[[feature,goal]]
table = pd.pivot_table(dataset,index=[feature],columns=[goal],aggfunc=np.alen, margins=True).fillna(0)
table = pd.DataFrame(table) #每个特征分箱的好坏客户分组计数
table['bad%'] = table[1]/table['All'] #坏客户(标签为1)的占比
table['woe'] = np.log((table[0]*bad)/(table[1]*good)) #计算woe
table['miv'] = table['woe']*(table[0]/good - table[1]/bad) #计算miv
table['IV'] = table['miv'].sum() #计算IV
table.insert(0,column='bining', value=table.index)
table.insert(0,column='variable', value=feature)
Tab = pd.concat([Tab,table])
Tab = Tab.round(decimals=4)
return Tab参考资料:
https://zhuanlan.zhihu.com/p/74165987
https://zhuanlan.zhihu.com/p/79682292
https://www.zhihu.com/question/345907033/answer/823466562
https://multithreaded.stitchfix.com/blog/2015/08/13/weight-of-evidence/